Dati Strutturati
I dati strutturati sono markup standardizzati che aiutano i motori di ricerca a comprendere il contenuto delle pagine web. Scopri come JSON-LD, schema.org e mic...
11 min di lettura

Markup di schema progettato specificamente per aiutare i sistemi di intelligenza artificiale a comprendere e citare accuratamente i contenuti. I dati strutturati utilizzano formati standardizzati come JSON-LD per fornire un contesto esplicito sul contenuto della pagina, consentendo ai grandi modelli linguistici di analizzare le informazioni in modo più affidabile e citare le fonti con maggiore sicurezza.
Markup di schema progettato specificamente per aiutare i sistemi di intelligenza artificiale a comprendere e citare accuratamente i contenuti. I dati strutturati utilizzano formati standardizzati come JSON-LD per fornire un contesto esplicito sul contenuto della pagina, consentendo ai grandi modelli linguistici di analizzare le informazioni in modo più affidabile e citare le fonti con maggiore sicurezza.
I dati strutturati per l’IA si riferiscono a informazioni organizzate e leggibili dalla macchina, formattate secondo schemi standardizzati che permettono ai sistemi di intelligenza artificiale di comprendere, interpretare e utilizzare i contenuti con precisione. A differenza del testo non strutturato, che richiede complessi processi di elaborazione del linguaggio naturale per decifrarne il significato, i dati strutturati forniscono un contesto esplicito su ciò che rappresentano le informazioni. Questa chiarezza è essenziale perché i sistemi di intelligenza artificiale—soprattutto i grandi modelli linguistici e i motori di ricerca—elaborano miliardi di dati ogni giorno. Quando i contenuti sono strutturati secondo standard come schema.org, JSON-LD o microdata, l’IA può riconoscere immediatamente entità, relazioni e attributi senza ambiguità. Questo approccio strutturato offre una precisione superiore del 300% nella comprensione AI rispetto alle alternative non strutturate. Per le organizzazioni che vogliono essere visibili negli AI Overviews e in altri risultati generati dall’IA, i dati strutturati sono diventati un’infrastruttura irrinunciabile. Trasformano il contenuto grezzo in intelligenza che i sistemi AI possono citare, referenziare e incorporare nelle loro risposte, cambiando radicalmente il modo in cui i contenuti digitali raggiungono la scoperta in un mondo guidato dall’intelligenza artificiale.

I sistemi di intelligenza artificiale elaborano i dati strutturati tramite una pipeline sofisticata che trasforma i contenuti marcati in informazioni azionabili. Quando un’IA incontra dati strutturati formattati correttamente, può estrarre immediatamente le informazioni chiave senza il carico computazionale richiesto dall’interpretazione del linguaggio naturale. Il meccanismo tecnico segue questi passaggi essenziali:
Questo processo consente all’IA di offrire una visibilità superiore del 30%+ negli AI Overviews per i contenuti correttamente strutturati. L’approccio strutturato riduce i rischi di allucinazione ancorando le risposte AI a dati espliciti e verificabili invece che alla generazione probabilistica di testo. Le organizzazioni che implementano strategie complete di dati strutturati vedono miglioramenti misurabili nel modo in cui i sistemi AI scoprono, comprendono e promuovono i loro contenuti su più piattaforme e applicazioni.
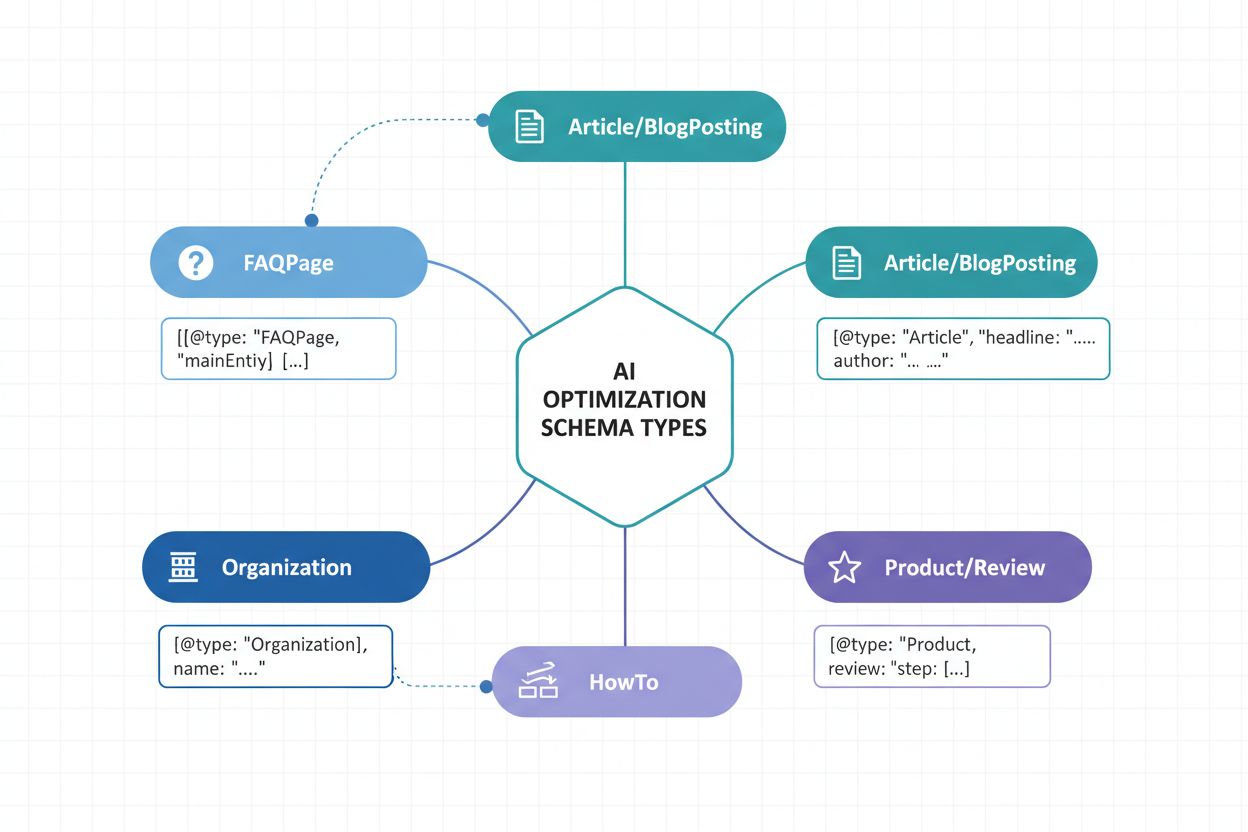
Implementare i giusti tipi di schema è fondamentale per la strategia di visibilità AI. Tipi diversi di contenuti richiedono markup specifici di dati strutturati per comunicare la loro natura e il loro valore ai sistemi AI. Ecco i tipi di schema essenziali per massimizzare il riconoscimento AI:
Article Schema - Marca articoli di notizie, post di blog e contenuti lunghi con titolo, autore, data di pubblicazione e corpo del testo. Fondamentale per i sistemi AI che identificano fonti autorevoli e stabiliscono la credibilità della pubblicazione.
Organization Schema - Definisce l’identità dell’azienda, inclusi nome, logo, informazioni di contatto e profili social. Permette all’IA di riconoscere e attribuire correttamente i contenuti organizzativi in vari contesti.
Product Schema - Struttura le informazioni sui prodotti tra cui nome, descrizione, prezzo, disponibilità e recensioni. Essenziale per la visibilità e-commerce negli assistenti AI per lo shopping e nei sistemi di raccomandazione prodotto.
LocalBusiness Schema - Marca la posizione aziendale, orari, dettagli di contatto e servizi. Cruciale per le query AI locali e per le AI Overviews basate sulla posizione che dominano sempre più i risultati di ricerca.
BreadcrumbList Schema - Definisce la gerarchia di navigazione del sito, aiutando l’IA a comprendere la struttura dei contenuti e le relazioni tra le pagine all’interno della tua architettura informativa.
FAQPage Schema - Struttura domande frequenti con risposte, permettendo ai sistemi AI di estrarre e citare direttamente contenuti specifici di domande e risposte nelle risposte generate.
NewsArticle e BlogPosting Schemas - Tipi di articoli specializzati che segnalano la categoria del contenuto ai sistemi AI, migliorando l’accuratezza della categorizzazione e la pertinenza delle corrispondenze.
Event Schema - Marca i dettagli di eventi inclusi data, luogo, descrizione e informazioni di registrazione, essenziali per la scoperta di eventi da parte dell’IA e per l’integrazione nei calendari.
Attualmente, 45 milioni di domini utilizzano il markup schema.org, rappresentando il 12,4% di tutti i domini a livello globale. Le organizzazioni che implementano più tipi di schema contemporaneamente vedono benefici di visibilità composti, poiché i sistemi AI acquisiscono una comprensione contestuale più ricca del loro ecosistema di contenuti.
Una corretta implementazione dei dati strutturati richiede pianificazione strategica e precisione tecnica. Le organizzazioni dovrebbero seguire queste best practice consolidate per massimizzare la visibilità AI e garantire l’accuratezza dei dati:
Ecco un esempio pratico di JSON-LD per un articolo:
{
"@context": "https://schema.org",
"@type": "Article",
"headline": "Dati strutturati per l'IA: Guida all'implementazione strategica",
"author": {
"@type": "Person",
"name": "Autore del contenuto"
},
"datePublished": "2024-01-15",
"image": "https://example.com/image.jpg",
"articleBody": "Testo completo dell'articolo qui...",
"publisher": {
"@type": "Organization",
"name": "La tua organizzazione",
"logo": "https://example.com/logo.png"
}
}
Una corretta implementazione offre un miglioramento del CTR del 35% dai rich result nella ricerca tradizionale, con ulteriori benefici che emergono man mano che gli AI Overviews diventano i principali canali di scoperta. Le organizzazioni che monitorano le prestazioni dei dati strutturati tramite soluzioni come AmICited.com ottengono un vantaggio competitivo identificando quali tipi di contenuto e implementazioni schema generano la massima visibilità AI.
Sia i dati strutturati che llms.txt servono la scoperta AI ma operano attraverso meccanismi fondamentalmente diversi. I dati strutturati utilizzano schemi standardizzati (schema.org, JSON-LD) incorporati nell’HTML per marcare elementi specifici del contenuto con significato semantico esplicito. Questo approccio si integra direttamente nelle pagine web, rendendo le informazioni immediatamente disponibili sia ai motori di ricerca che ai sistemi AI durante il crawling dei contenuti. I dati strutturati consentono una marcatura granulare di articoli, prodotti, eventi e organizzazioni, permettendo all’IA di comprendere relazioni e attributi precisi.
llms.txt, invece, è un file di testo posizionato nella directory principale di un sito contenente istruzioni e linee guida per i grandi modelli linguistici. Funziona come file manifest che comunica preferenze su come i sistemi AI dovrebbero interagire e citare i tuoi contenuti. Sebbene llms.txt fornisca linee guida di alto livello sui diritti d’uso dei contenuti e sulle preferenze di attribuzione, manca della precisione semantica dei dati strutturati. I dati strutturati rispondono alla domanda “che cos’è questo contenuto?” con risposte leggibili dalla macchina, mentre llms.txt risponde a “come dovresti usare questo contenuto?” come guida.
La strategia più efficace combina entrambi gli approcci: i dati strutturati assicurano che i sistemi AI comprendano e possano citare accuratamente i tuoi contenuti, mentre llms.txt stabilisce politiche d’uso e requisiti di attribuzione chiari. Le organizzazioni che implementano entrambi vedono una probabilità di apparire negli AI-generated summaries superiore del 36% rispetto a chi non utilizza nessuno dei due. I dati strutturati forniscono la base per la comprensione AI, mentre llms.txt offre il quadro di governance che assicura attribuzione e utilizzo corretto.
Misurare l’efficacia dei dati strutturati richiede il tracciamento di metriche specifiche che rivelano come i sistemi AI scoprono, comprendono e citano i tuoi contenuti. Le organizzazioni dovrebbero monitorare questi indicatori chiave di performance:
AmICited.com offre un monitoraggio specializzato delle performance delle citazioni AI, consentendo alle organizzazioni di tracciare come i loro investimenti in dati strutturati si traducono in reale visibilità e attribuzione AI. La piattaforma rivela quali contenuti ricevono citazioni AI, quali query attivano i tuoi contenuti e come la tua frequenza di citazione si confronta con quella dei concorrenti. Questo approccio data-driven trasforma l’implementazione dei dati strutturati da best practice teorica a impatto aziendale misurabile.
Le organizzazioni che implementano strategie complete di dati strutturati riportano che il 93% delle query riceve risposta dall’IA senza clic, rendendo la visibilità delle citazioni sempre più critica per generare traffico. Misurare la performance delle citazioni garantisce che gli investimenti in dati strutturati generino ritorni quantificabili tramite una migliore scoperta AI e attribuzione del brand.
Una corretta implementazione dei dati strutturati segue un approccio a fasi che costruisce capacità progressivamente e offre valore misurabile ad ogni stadio. Le organizzazioni dovrebbero strutturare la timeline di implementazione come segue:
Fase 1: Fondazione (Mesi 1-2)
Fase 2: Espansione (Mesi 3-4)
Fase 3: Ottimizzazione (Mesi 5-6)
Fase 4: Integrazione strategica (Mesi 7+)
Questa timeline permette alle organizzazioni di ottenere miglioramenti significativi della visibilità AI in 2-3 mesi, costruendo nel tempo un’infrastruttura di dati strutturati completa a livello enterprise. Gli early adopter che implementano questa roadmap ottengono vantaggi competitivi man mano che gli AI Overview diventano i principali canali di scoperta.
I dati strutturati sono passati da semplice miglioramento SEO a infrastruttura strategica essenziale in uno scenario digitale dominato dall’IA. Poiché i sistemi AI mediano sempre più il modo in cui gli utenti scoprono le informazioni, le organizzazioni senza un markup dati strutturati completo affrontano svantaggi sistematici di visibilità. Il cambiamento riflette una trasformazione fondamentale nel flusso delle informazioni: la ricerca tradizionale richiedeva agli utenti di cliccare sui siti web, ma gli AI Overview rispondono direttamente alle domande, rendendo la visibilità delle citazioni il nuovo terreno competitivo.
Le organizzazioni che implementano i dati strutturati in modo strategico si posizionano per il successo a lungo termine su più piattaforme AI e nuovi canali di scoperta. L’investimento infrastrutturale paga dividendi che vanno oltre la visibilità immediata sull’IA—i dati strutturati migliorano la gestione interna dei contenuti, abilitano una migliore personalizzazione, supportano l’ottimizzazione per la ricerca vocale e creano asset dati preziosi per future applicazioni AI. Gli early adopter che stabiliscono solide basi di dati strutturati ottengono vantaggi composti man mano che i sistemi AI privilegiano contenuti ben marcati.
Il vantaggio competitivo dell’adozione anticipata non può essere sottovalutato. Con la crescente consapevolezza dell’importanza dei dati strutturati, l’implementazione diventerà un prerequisito per la visibilità. Le organizzazioni che ora creano un’infrastruttura robusta di dati strutturati domineranno i risultati generati dall’IA man mano che questi canali maturano. Al contrario, chi ritarda l’implementazione avrà sempre più difficoltà a ottenere visibilità, poiché i sistemi AI impareranno a preferire contenuti completamente marcati. I dati strutturati non rappresentano solo un’implementazione tecnica, ma un impegno strategico fondamentale per rimanere scopribili e citabili nell’ecosistema informativo mediato dall’IA.
I dati strutturati non influenzano direttamente il posizionamento su Google, ma migliorano significativamente l'aspetto dei risultati di ricerca tramite i rich snippet, aumentando il tasso di clic fino al 35%. Per i sistemi di intelligenza artificiale, i dati strutturati hanno un impatto più diretto sulla probabilità che i tuoi contenuti vengano citati nelle risposte generate dall'IA.
Sì, i sistemi di intelligenza artificiale elaborano i dati strutturati sia durante l'addestramento che nelle query in tempo reale. Sebbene OpenAI non abbia rilasciato dichiarazioni pubbliche, le evidenze suggeriscono che GPTBot e altri crawler AI analizzano il markup JSON-LD. Microsoft ha ufficialmente confermato che i sistemi AI di Bing utilizzano lo schema markup per comprendere meglio i contenuti.
JSON-LD è il formato consigliato perché separa lo schema dal contenuto HTML, rendendolo più facile da implementare e mantenere su larga scala. Google raccomanda esplicitamente JSON-LD, ed è meno soggetto a errori di implementazione rispetto a Microdata o RDFa.
I rich snippet possono comparire entro 1-4 settimane dall'implementazione. I miglioramenti nel CTR sono spesso misurabili entro 2 settimane. Per migliorare le citazioni AI, aspettati 4-8 settimane affinché il lavoro di base abbia effetto, con benefici di autorevolezza che si accumulano in 3-6 mesi.
Dai priorità prima allo schema markup—è comprovato e ampiamente supportato. llms.txt è ancora uno standard emergente con adozione limitata da parte dei crawler AI. Se sei un'azienda orientata agli sviluppatori con molta documentazione, il minimo sforzo per creare llms.txt potrebbe essere utile per il futuro.
Inizia con lo schema Organization sulla homepage (con proprietà sameAs), poi schema Article sulle principali pagine di contenuto. Lo schema FAQPage dovrebbe essere il prossimo—è il più utile per l'estrazione AI. Dopo di che, aggiungi schema HowTo alle guide e schema SoftwareApplication alle pagine prodotto.
Solo un markup implementato in modo errato danneggia le prestazioni. Le linee guida di Google sono chiare: usa tipi di schema pertinenti che corrispondano al contenuto visibile, mantieni prezzi e date accurati e non segnare contenuti che gli utenti non possono vedere. Valida sempre con il Rich Results Test di Google prima della pubblicazione.
I dati strutturati forniscono un contesto esplicito che aiuta i sistemi AI a comprendere cosa rappresentano le informazioni—entità, relazioni, attributi. Questa chiarezza consente all'IA di estrarre e citare i tuoi contenuti con sicurezza. Gli LLM basati su knowledge graph raggiungono un'accuratezza superiore del 300% rispetto a quelli che si affidano esclusivamente a dati non strutturati.
Traccia come i sistemi di intelligenza artificiale citano i tuoi contenuti su ChatGPT, Perplexity, Google AI Overviews e altre piattaforme. Ottieni visibilità in tempo reale sulla tua presenza AI.
I dati strutturati sono markup standardizzati che aiutano i motori di ricerca a comprendere il contenuto delle pagine web. Scopri come JSON-LD, schema.org e mic...
Scopri come implementare il markup Schema Organization per la visibilità nell'IA. Guida passo passo per aggiungere dati strutturati JSON-LD, migliorare le citaz...
Scopri come i crawler AI elaborano i dati strutturati. Scopri perché il metodo di implementazione JSON-LD è importante per la visibilità su ChatGPT, Perplexity,...
Consenso Cookie
Usiamo i cookie per migliorare la tua esperienza di navigazione e analizzare il nostro traffico. See our privacy policy.