
AIクローラーの活動を追跡する:完全監視ガイド
サーバーログ、ツール、ベストプラクティスを用いて、ウェブサイト上のAIクローラーの活動を追跡・監視する方法を学びましょう。GPTBot、ClaudeBot、その他AIボットの特定方法も紹介します。...
2 分で読める

AIクローラーがあなたのウェブサイトにアクセスできているかを監査する方法を学びましょう。どのボットがあなたのコンテンツを見ているのかを確認し、ChatGPT・Perplexity・その他AI検索エンジンでAIによる可視性を妨げている要因を修正しましょう。
検索とコンテンツ発見の環境は劇的に変化しています。 ChatGPT、Perplexity、Google AI OverviewsなどのAI搭載検索ツールが急速に拡大する中、AIクローラーからの可視性は従来の検索エンジン最適化と同じくらい重要になっています。もしAIボットがあなたのコンテンツにアクセスできなければ、これらのプラットフォームを頼りにする何百万人ものユーザーに対してあなたのサイトは“見えない”存在になってしまいます。 リスクはかつてないほど高くなっています。Googleは何か問題が起きても再訪問してくれるかもしれませんが、AIクローラーは全く異なるパラダイムで動作しており、最初の重要なクロールを逃すと、何ヶ月も可視性や引用、トラフィック、ブランド権威の機会を失うことになりかねません。
AIクローラーは、長年最適化してきたGoogleやBingのボットとは根本的に異なるルールで動作します。最も重要な違いは、AIクローラーはJavaScriptをレンダリングしないことです。つまり、クライアントサイドスクリプトで動的に読み込まれるコンテンツは彼らには見えません(Googleの高度なレンダリング機能とは対照的)。さらに、AIクローラーは従来の検索エンジンよりも100倍以上の頻度でサイトを訪れることもあり、サーバーリソース面での機会と課題の両方を生み出します。Googleのインデックスモデルとは異なり、AIクローラーは永続的なインデックスを持たず、ユーザーがシステムにクエリを投げたときにオンデマンドでクロールします。つまり、再インデックスのキューも、Search Consoleでの再クロール申請もなく、最初の印象で失敗した場合にやり直しの機会もありません。これらの違いを理解することが、コンテンツ戦略最適化の鍵となります。
| 機能 | AIクローラー | 従来ボット |
|---|---|---|
| JavaScriptレンダリング | なし(静的HTMLのみ) | あり(完全レンダリング) |
| クロール頻度 | 非常に高い(100倍以上) | 中程度(週次・月次) |
| 再インデックス機能 | なし(オンデマンドのみ) | あり(継続的更新) |
| コンテンツ要件 | プレーンHTML、スキーママークアップ | 柔軟(動的コンテンツ対応) |
| User-Agentブロック | ボットごとに指定(GPTBot、ClaudeBot等) | 一般的(Googlebot、Bingbot) |
| キャッシュ戦略 | 短期スナップショット | 長期インデックス維持 |
あなたのコンテンツがAIクローラーから見えなくなる理由は、意外なところに潜んでいます。AIボットによるアクセス・理解を妨げる主な障害は以下の通りです:
robots.txtファイルは、どのAIボットがあなたのコンテンツにアクセスできるかを制御する主な仕組みで、個別のクローラーをターゲットとするUser-Agentルールで動作します。各AIプラットフォームは独自のUser-Agent文字列を使用しています(OpenAIのGPTBot、AnthropicのClaudeBot、PerplexityのPerplexityBotなど)。それぞれを独立して許可・拒否できるため、どのAIシステムにコンテンツの学習や引用を許すかを細かく決められます。これは独自情報の保護や競争上の管理で非常に重要です。しかし、多くのサイトは古いボット向けの広範なルールでAIクローラーを意図せずブロックしていたり、適切なルール自体を実装していなかったりします。
異なるAIボット向けにrobots.txtを設定する例:
# OpenAIのGPTBotを許可
User-agent: GPTBot
Allow: /
# AnthropicのClaudeBotをブロック
User-agent: ClaudeBot
Disallow: /
# Perplexityは許可するが特定ディレクトリは制限
User-agent: PerplexityBot
Allow: /
Disallow: /private/
Disallow: /admin/
# 他すべてのボットへのデフォルトルール
User-agent: *
Allow: /
Googleのように継続的にクロール・再インデックスされるのとは異なり、**AIクローラーは「一発勝負」**です。ユーザーがシステムにクエリを投げたそのタイミングで訪れるため、その瞬間にコンテンツへアクセスできなければチャンスを逃します。この根本的な違いにより、サイトは初日から技術的に準備万端でなければなりません。猶予期間もなければ、可視性が損なわれる前に修正できる「やり直し」もありません。JavaScriptレンダリング失敗やスキーママークアップ不足、サーバーエラー等で最初のクロール体験が悪いと、あなたのコンテンツは何週間・何ヶ月もAI生成回答から除外されることがあります。手動での再インデックス申請やコンソールの「インデックス登録リクエスト」ボタンもありません。だからこそ、監視と最適化を事前に徹底することが不可欠です。最初から正しく動作させるためのプレッシャーは、かつてなく高まっています。
AIクローラーアクセスの監視を定期クロールに頼るのは、月に一度だけ自宅の火災チェックをするようなものです—問題が起きた「その瞬間」を逃してしまいます。リアルタイム監視なら、問題発生と同時に検知でき、あなたのコンテンツがAIシステムから見えなくなる前に対応できます。週次や月次で実施される定期監査だけでは、何日もAIクローラーの問題に気付かず可視性を損なうリスクがあります。リアルタイム監視はクローラーの挙動を常に追跡し、JavaScriptレンダリング失敗、スキーママークアップエラー、ファイアウォールブロック、サーバー障害などを即時にアラートします。この能動的なアプローチにより、監査は受動的なコンプライアンスチェックから、積極的な可視性管理戦略へと進化します。AIクローラーのトラフィックが従来検索エンジンの100倍にもなる今、たった数時間のアクセス不良でも大きな損失につながりかねません。
現在、AIクローラーアクセスの監視・最適化に特化したプラットフォームがいくつか登場しています。Cloudflare AI Crawl Controlは、AIボットトラフィックのインフラレベル管理を提供し、レート制限やアクセス制御を設定可能です。Conductorは、各種AIクローラーがあなたのコンテンツとどうやり取りしているかを監視するダッシュボードを提供します。Elementiveは、AIクローラー要件に特化した技術SEO監査に強みがあります。AdAmigoやMRS Digitalは、AI可視性のための専門コンサルティングや監視サービスを提供しています。しかし、AIクローラーアクセスのパターンをリアルタイムに追跡し、可視性に影響が出る前に問題を通知するという点で特化しているのがAmICitedです。AmICitedは、どのAIシステムがどれだけ頻繁にコンテンツにアクセスしているか、技術的な障壁に遭遇しているかを監視する専門サービスであり、従来のSEO指標ではなくAIクローラーの挙動に特化しているため、AI可視性を本気で高めたい組織にとって必須のツールとなっています。
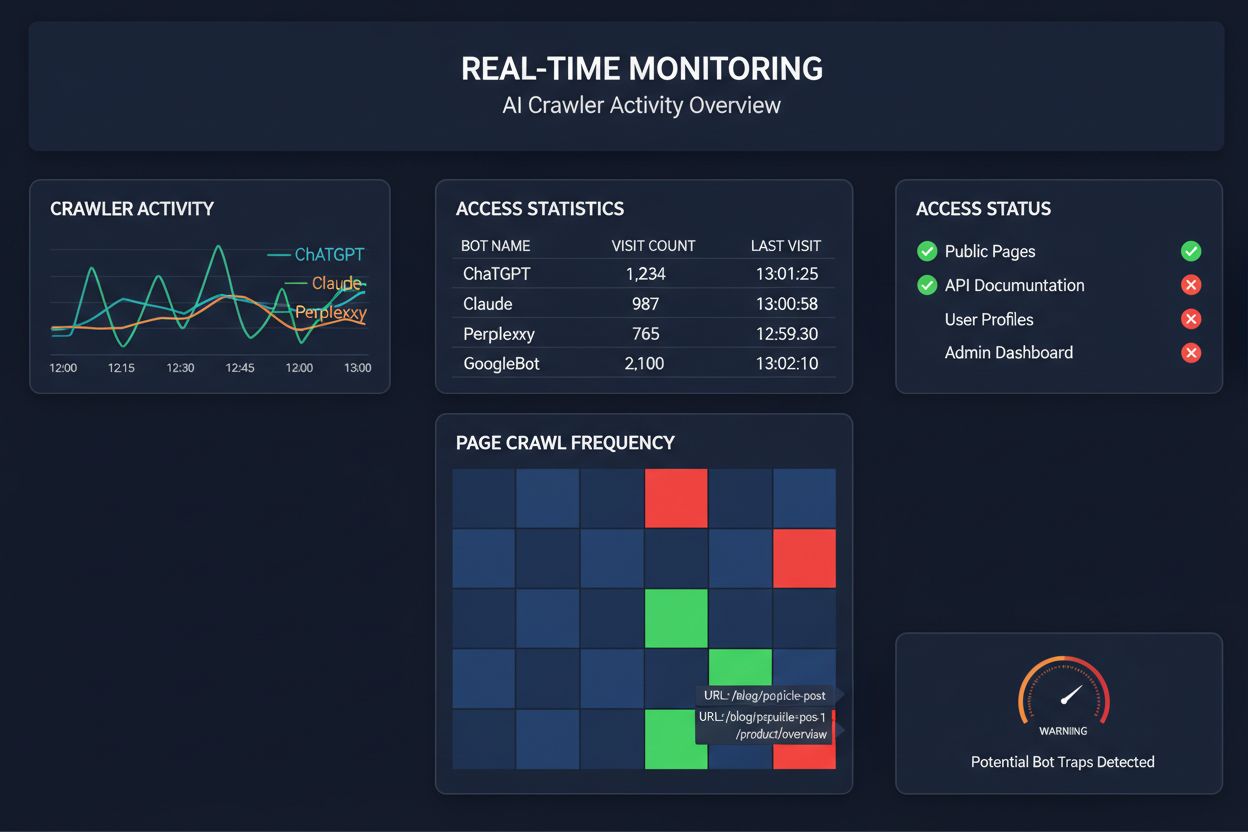
包括的なAIクローラー監査には体系的なアプローチが必要です。ステップ1:現状把握—robots.txtファイルを確認し、どのAIボットを許可・ブロックしているか洗い出します。ステップ2:技術インフラの監査—非JavaScriptクローラーからのサイトアクセス性、サーバー応答速度、重要コンテンツが静的HTMLで配信されているかをテストします。ステップ3:スキーママークアップの実装・検証—著者、公開日、コンテンツタイプなどのメタデータがJSON-LD形式で適切に構造化されているかを確認します。ステップ4:クローラー行動の監視—AmICitedのようなツールで、どのAIボットがどの頻度でアクセスし、エラーが出ていないかを追跡します。ステップ5:結果分析—クロールログを確認し、失敗のパターンを特定、優先度の高い修正点を整理します。ステップ6:修正の実施—JavaScriptレンダリング問題やスキーマ不足など影響が大きい項目から修正し、次に二次的な最適化に移ります。ステップ7:継続的監視の体制化—新たな問題が可視性に影響を及ぼす前に検知できるよう、クロール失敗やアクセスブロックのアラートを設定します。
AIクローラーアクセスを改善するためにサイト全体を作り直す必要はありません。重要なコンテンツはJavaScriptに頼らずプレーンHTMLで提供し、どうしてもJavaScriptを使う場合は重要なテキストやメタデータも初期HTMLに含めましょう。JSON-LD形式の包括的なスキーママークアップを追加し、記事スキーマ、著者情報、公開日、コンテンツ間の関係も網羅してください—これによりAIクローラーが文脈や正しい帰属を理解しやすくなります。著者情報の明示もスキーマや署名で強化しましょう。AIシステムは今後さらに権威あるソースの引用を重視する傾向です。Core Web Vitals(LCP、FID、CLS)を最適化し、遅いページは途中でクロール離脱されるリスクを減らします。robots.txtを見直して、意図せずAIボットをブロックしていないか確認しましょう。リダイレクトチェーンやリンク切れ、サーバーエラーといった技術的問題も修正し、クロール途中離脱を防ぎます。
すべてのAIクローラーが同じ目的で動いているわけではありません。これらの違いを把握することで、アクセス制御の判断がより的確になります。GPTBot(OpenAI)は主にトレーニングデータ収集とモデル能力強化に使われ、ChatGPTの回答にあなたのコンテンツを反映したい場合に重要です。OAI-SearchBot(OpenAI)は検索引用向けにクロールし、ChatGPTの検索統合回答であなたのコンテンツが参照されるためのボットです。ClaudeBot(Anthropic)はClaude向けの同様の役割を担っています。PerplexityBot(Perplexity)はPerplexityのAI検索エンジンへの引用用にクロールしており、多くのパブリッシャーにとって重要なトラフィック源となっています。各ボットはクロールパターンや頻度、目的が異なり、トレーニングデータ収集重視のものもあれば、リアルタイム検索引用のものもあります。どのボットを許可・ブロックするかはコンテンツ戦略に合わせて決定しましょう。AI検索結果での引用を望むなら検索用ボットを許可し、トレーニングデータ利用が気になる場合はデータ収集ボットのみブロックするといった柔軟な管理が、従来の「すべて許可」や「すべてブロック」よりもはるかに洗練された方法となります。
AIクローラー監査とは、ChatGPT、Claude、PerplexityなどのAIボットに対するあなたのウェブサイトのアクセス性を総合的に評価するものです。技術的なブロッカー、JavaScriptレンダリングの問題、スキーママークアップの欠落、その他AIクローラーがコンテンツにアクセス・理解するのを妨げる要因を特定します。監査結果は、AI搭載の検索エンジンおよび回答エンジンでの可視性を高めるための実践的な改善提案を提供します。
ウェブサイトの技術的インフラ、コンテンツ構造、robots.txtファイルに大きな変更を加えたとき、または少なくとも四半期ごとに包括的な監査を行うことを推奨します。ただし、リアルタイムでの継続的な監視が理想的で、問題が発生した際に即座にキャッチできます。多くの組織はリアルタイムでクロール失敗を通知する自動監視ツールを活用し、四半期ごとの詳細な監査で補完しています。
AIクローラーを許可すると、あなたのコンテンツがAIシステムにアクセス・分析され、引用される可能性があり、AIによる回答や推奨での可視性が高まります。一方、AIクローラーをブロックすると、独自情報を保護できますが、AI検索結果での可視性が低下する可能性があります。どちらを選択するかは、ビジネス目標やコンテンツの重要度、競合状況によって異なります。
はい、可能です。robots.txtファイルではUser-Agentルールによって詳細な制御ができます。例えば、GPTBotはブロックし、PerplexityBotは許可することや、OAI-SearchBotのような検索向けボットのみ許可し、GPTBotなどのデータ収集ボットはブロックすることも可能です。このような細かな管理により、ビジネスにとって重要なAIプラットフォームに合わせてコンテンツ戦略を最適化できます。
AIクローラーがあなたのコンテンツにアクセスできない場合、AI搭載の検索エンジンや回答プラットフォームから事実上見えなくなります。たとえ内容が非常に関連していても、引用・推奨・AI生成回答への掲載がされなくなり、トラフィックの損失やブランド可視性の低下、AI検索で権威を築く機会を逃すことになります。
サーバーログでGPTBot、ClaudeBot、PerplexityBotなど既知のAIクローラーのUser-Agent文字列を確認するか、AmICitedのようなAIクローラーの活動をリアルタイムで追跡する専門ツールを利用できます。これらのツールは、どのボットがどの頻度でどのページをクロールし、エラーやブロックに遭遇しているかを可視化します。
これは状況によります。コンテンツが機密性や独自性を持ち、トレーニングデータの利用が懸念される場合はブロックも一案です。しかし、AI検索結果での可視性やAIシステムからの引用を望むなら、クローラーの許可が不可欠です。多くの組織は、引用につながる検索向けボットは許可し、データ収集ボットはブロックする中間策を取っています。
AIクローラーはJavaScriptをレンダリングしないため、クライアントサイドのスクリプトで動的に読み込まれるコンテンツはすべて見えません。重要なコンテンツやナビゲーション、構造化データがJavaScriptに依存している場合、AIクローラーは生のHTMLしか認識できず、重要な情報を見逃します。これにより、AI回答でのコンテンツ理解や掲載に大きな影響を及ぼす可能性があります。AI対応には、重要なコンテンツを静的HTMLで提供することが必須です。
サーバーログ、ツール、ベストプラクティスを用いて、ウェブサイト上のAIクローラーの活動を追跡・監視する方法を学びましょう。GPTBot、ClaudeBot、その他AIボットの特定方法も紹介します。...

GPTBot、PerplexityBot、ClaudeBotなどのAIボットによるサイトクロールの許可方法を解説します。robots.txt・llms.txtの設定やAI向け最適化の方法もわかります。...

GPTBotやClaudeBotなどのAIクローラーをrobots.txt、サーバーレベルブロック、高度な保護方法でブロックまたは許可する方法を学びます。事例付きの完全な技術ガイド。...
クッキーの同意
閲覧体験を向上させ、トラフィックを分析するためにクッキーを使用します。 See our privacy policy.