
サーバーログでAIクローラーを特定する方法:完全検出ガイド
GPTBot、PerplexityBot、ClaudeBotなどのAIクローラーをサーバーログで特定・監視する方法を解説。ユーザーエージェント文字列やIP検証手法、AIトラフィック追跡のベストプラクティスもご紹介。...
2 分で読める

GPTBotやClaudeBotなどのAIクローラーがどのように機能し、従来の検索クローラーとどう異なるか、AI検索でサイトの可視性を高める方法を解説します。
AIクローラーは、ウェブサイトを体系的に巡回しデータを収集するために設計された自動プログラムで、人工知能モデルの学習・改善を主な目的としています。Googlebotのような従来型検索エンジンクローラーが検索結果のためにコンテンツをインデックスするのに対し、AIクローラーはChatGPT・Claudeなどの大規模言語モデル(LLM)に投入する生のウェブデータを収集します。これらのボットは何百万ものウェブサイトを継続的にクロールし、ページをダウンロード・内容を解析・情報を抽出して、AIプラットフォームが言語パターンや事実情報、多様な文体を理解できるよう支援しています。主なプレーヤーはOpenAIのGPTBot、AnthropicのClaudeBot、MetaのMeta-ExternalAgent、AmazonのAmazonbot、Perplexity.aiのPerplexityBotなどで、それぞれのAIプラットフォームの学習や運用ニーズに応じて稼働しています。これらクローラーの仕組みを理解することは、AI検索でのブランド可視性が直接ビジネス成果に影響する現代において、ウェブサイト運営者・コンテンツ制作者にとって不可欠となっています。
ここ1年でウェブクローリングの状況は劇的に変化し、AIクローラーが爆発的な成長を遂げる一方で、従来型検索クローラーは安定した動きを維持しています。2024年5月~2025年5月の間にクローラートラフィック全体は18%増加しましたが、その内訳は大きくシフトしました。GPTBotは生リクエスト数で305%増と急伸し、ClaudeBotは46%減、Bytespiderは85%減と減少傾向に。これはAI企業間での学習データ獲得競争が激化していることを反映しています。主要クローラーの現状は以下の通りです。
| クローラー名 | 企業 | 月間リクエスト数 | 前年比成長率 | 主な目的 |
|---|---|---|---|---|
| Googlebot | 45億 | 96% | 検索インデックス・AI概要 | |
| GPTBot | OpenAI | 5.69億 | 305% | ChatGPT学習・検索 |
| Claude | Anthropic | 3.7億 | -46% | Claude学習・検索 |
| Bingbot | Microsoft | 約4.5億 | 2% | 検索インデックス |
| PerplexityBot | Perplexity.ai | 2,440万 | 157,490% | AI検索インデックス |
| Meta-ExternalAgent | Meta | 約3.8億 | 新規 | Meta AI学習 |
| Amazonbot | Amazon | 約2.1億 | -35% | 検索・AI用途 |
このデータから、Googlebotが月間45億リクエストで依然トップを維持しつつも、AIクローラー全体では**Googlebotの約28%**のボリュームに達し、無視できない勢力となっています。PerplexityBotの(157,490%増)のような急拡大や、既存AIクローラーのシェア低下は、市場がより成功したプラットフォームに集約しつつあることを示唆しています。
GPTBotはOpenAIが開発したウェブクローラーで、ChatGPTや他のOpenAIモデルの学習・改善のためのデータ収集を目的としています。2024年5月時点では市場シェア5%の小規模プレーヤーでしたが、2025年5月には全AIクローラートラフィックの30%を占めるまでに急成長し、生リクエスト数で305%増という驚異的な伸びを記録しました。この成長は、OpenAIがChatGPTの学習とリアルタイム検索機能強化のため、常に新鮮で多様なウェブコンテンツへのアクセスを重視している戦略を反映しています。GPTBotはHTMLコンテンツを優先(57.70%の取得)しつつ、JavaScriptファイルや画像もダウンロードしますが、JavaScriptを実行して動的コンテンツを描画することはありません。また、全リクエストの34.82%で404エラーに遭遇しており、これは古いリンクや既に存在しないリソースを辿っている可能性があることを示します。サイト運営者にとって、GPTBotへの対応はChatGPT検索での可視性や今後のモデル学習への組み込みに不可欠な要素となっています。
ClaudeBotはAnthropicが開発した、Claude AIアシスタントの学習・更新、ならびに検索・根拠付け機能を担う主要クローラーです。2024年5月にはAIクローラーの中で2位(シェア27%)でしたが、2025年5月には21%まで低下し、生リクエスト数も前年比46%減となりました。これはAnthropicの戦略の問題というより、OpenAIの台頭やMeta-ExternalAgentの新規参入など、市場環境の変化が要因です。ClaudeBotはGPTBot同様HTMLを優先しますが、画像へのリクエスト割合が高く(35.17%)、Anthropicがテキストだけでなく画像理解にも注力していることが伺えます。ClaudeBotもJavaScriptはレンダリングせず、生のHTMLのみを解析します。ClaudeBotへの可視性を維持することは、Claudeによるコンテンツ引用やAI検索での露出を確保する上で今後も重要です。
GPTBot・ClaudeBot以外にも、各社プラットフォーム向けに活発なAIクローラーが存在します:
Meta-ExternalAgent(Meta):Metaのクローラーは新規参入ながら2025年5月時点で19%のシェアを獲得。Meta AIの学習やInstagram・FacebookのAI機能統合など、AI分野への本格進出が伺えます。
PerplexityBot(Perplexity.ai):シェア0.2%ながら前年比**157,490%**の成長率で急拡大。リアルタイムウェブ検索によるAI回答を特徴とし、訪問時に引用されるチャンスがあります。
Amazonbot(Amazon):シェア21%→11%に低下し、リクエスト数も35%減。Amazonの検索・AI用途向けですが、AI戦略やクローリングの再編が進んでいる可能性があります。
Applebot(Apple):リクエスト数が26%減少し、シェアは1.9%→1.2%に。主にSiri・Spotlight検索向けですが、新たなAI機能もサポートする可能性があります。Applebotは他のAIクローラーと異なり、JavaScriptレンダリングも可能でGooglebotに近い能力を持ちます。
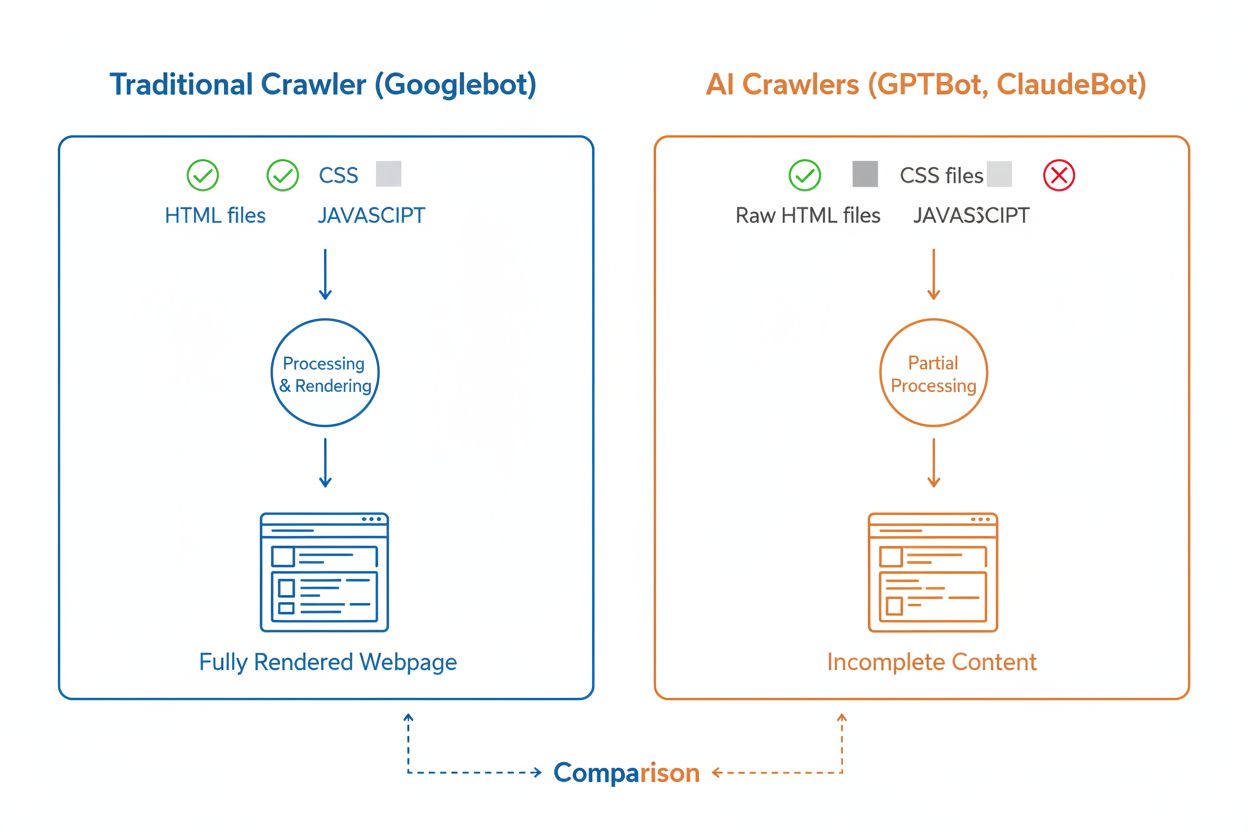
AIクローラーもGooglebotのような従来型検索クローラーも体系的にウェブを巡回しますが、技術的能力や挙動は大きく異なり、それがコンテンツの検索・理解方法に直接影響します。最も重要な違いはJavaScriptレンダリングで、Googlebotはページをダウンロード後にJavaScriptを実行し、動的に読み込まれる内容も把握できますが、GPTBot・ClaudeBot・Meta-ExternalAgent・Bytespiderなど大半のAIクローラーは生のHTMLのみを解析し、JavaScript依存のコンテンツは無視します。そのため、クライアントサイドレンダリングで重要情報を表示していると、AIクローラーには不完全なページしか見えません。また、Googlebotが効率的にクロールするのに対し、AIクローラーは404ページ(34.82%)やリダイレクト(14.36%)にも多くのリクエストを費やし、Googlebotの404率8.22%、リダイレクト1.49%より非効率的です。クロール頻度も異なり、Googlebotはクロールバジェットに基づいて規則的に訪問する一方、AIクローラーはより頻繁かつ不規則にクロールし、場合によってはGoogleの100倍以上の頻度でページを訪れることも。これらの違いから、従来のSEO最適化だけではAIクローラビリティを十分に確保できず、サーバーサイドレンダリングやクリーンなURL構造など独自の対応が必要になります。
AIクローラーの大きな技術的課題の一つがJavaScriptをレンダリングできないことであり、これは大規模言語モデル学習で膨大なウェブページを処理する際の計算コストが主な要因です。クローラーがページをダウンロードすると、初期HTMLは取得しますが、JavaScriptで動的に読み込まれる商品情報・価格・口コミ・ナビゲーション要素などは認識できません。React、Vue、Angularなどクライアントサイドレンダリングに依存したモダンサイトは、サーバーサイドレンダリング(SSR)や静的サイト生成(SSG)なしではAIクローラーから中身が空のページと見なされてしまいます。たとえば、ECサイトの商品情報がJavaScript経由で表示されていれば、AIクローラーには商品詳細が認識されず、AIによる引用や理解が不可能となります。解決策は、サーバーサイドレンダリングで全ての重要コンテンツを初期HTMLで出力し、人間にもAIクローラーにも同じコンテンツを提供することです。Next.js(SSR)、HugoやGatsby(静的サイトジェネレーター)、WordPressなどはAIクローラーにとってフレンドリーですが、クライアントサイドレンダリング中心のサイトはAI検索で大きな不利となります。
AIクローラーのクロール頻度やパターンはGooglebotとは大きく異なり、コンテンツがAIシステムに素早く取り込まれるかどうかに直結します。調査によれば、ChatGPTやPerplexityなどのAIクローラーはコンテンツ公開直後、短期間でGoogleよりも高頻度にクロールする傾向があり、初日~数日間だけでGooglebotの8倍アクセスすることもあります。これはAIプラットフォームが常に最新情報を素早く取得し、モデルや検索機能の精度を保つためと考えられます。一方で、この初期クロールが過ぎると、コンテンツの品質が基準に満たない場合は再訪しないことも多く、初回の印象が極めて重要です。Googlebotはクロールバジェットで定期的に再訪しますが、AIクローラーは「再訪する価値があるか」をその場で判断する傾向があり、コンテンツが薄い・技術エラー・ユーザー体験が悪い場合は長期間再訪しない可能性も。つまりAIクローラー向けには、一度きりのチャンスで最適化する前提で品質管理が求められます。
ウェブサイト運営者はrobots.txtファイルでAIクローラーへのアクセス許可・拒否を設定できますが、その有効性や遵守状況はクローラーごとに大きく異なります。最近のデータによると、上位10,000サイトのうち約14%がAIボット専用のallow/disallowルールを明記しています。GPTBotは最も多くブロックされており、312ドメイン(うち250が完全拒否、62が一部拒否)が明示的にアクセスを禁止、逆に61ドメインが明示的に許可しています。その他、CCBot(Common Crawl)、Google-Extended(GoogleのAI学習用トークン)もよくブロックされています。robots.txtの問題は、遵守が任意であり、運営者が対応しない限り守られない点と、新興クローラーや透明性の低いボットは無視する場合があることです。また、“Google-Extended"のようなトークンは実際のユーザーエージェント文字列とは異なり、ログだけで遵守を確認できません。より確実な制御のため、近年はファイアウォールやWebアプリケーションファイアウォール(WAF)で特定のクローラーを積極的にブロックする動きが拡大しています。これは、コンテンツ権利に対する意識の高まりや、より実効性の高いクローラー制御を求める傾向の表れです。
AIクローラーの活動を追跡することは、AI検索での可視性を把握する上で不可欠ですが、従来型クローラーの監視とは異なる課題があります。Google Analyticsなどの一般的な解析ツールはJavaScriptトラッキングを前提としているため、AIクローラーのアクセスは検知できません。ピクセルトラッキングも画像を無視するAIクローラーには無意味です。唯一確実なのはサーバーサイド監視で、HTTPリクエストヘッダーやサーバーログからクローラーユーザーエージェントを特定・記録する方法です。これは手動のログ解析か、AIクローラー専用の監視ツール導入が必要です。AIクローラーは不規則なスケジュールで動き、問題があれば再訪しない場合もあるため、リアルタイム監視が特に重要です。AIクローラーが404エラーやページ速度低下、スキーママークアップ欠如などに遭遇した際に即座にアラートを受け取り、問題を迅速に修正できる体制が新たな標準となりつつあります。これは従来のSEO監視とは異なり、AIクローラーの速度と予測不能な行動に対応したモニタリング手法です。
AIクローラー向け最適化は、従来のSEOとは異なる技術的観点を重視する必要があります。最優先はサーバーサイドレンダリングで、重要なコンテンツ(見出し・本文・メタデータ・構造化データ)を初期HTMLで出力し、JavaScript経由で動的に読み込ませないこと。これはトップページ、主要ランディングページ、AIによる引用を期待する全てのページに適用しましょう。次に、構造化データマークアップ(Schema.org)を高重要度ページに実装し、記事スキーマ(ブログ)、商品スキーマ(EC)、著者スキーマ(専門性・権威性)などを活用します。AIクローラーは構造化データで内容や階層を容易に理解し、引用や参照もしやすくなります。さらに、全ページでコンテンツ品質基準を高く保ち、オリジナルで信頼性が高く、読者に価値をもたらす内容を提供します。Core Web Vitalsやページパフォーマンスも最適化し、表示速度の遅いページはAIクローラーの再訪を妨げるリスクがあるため注意が必要です。最後に、URL構造の整理、XMLサイトマップの最新化、robots.txtの適切な設定で、AIクローラーが重要コンテンツに効率よくアクセスできる土台を作りましょう。これらの技術的最適化によって、AIシステムによる発見・理解・引用のハードルが大きく下がります。
AIクローラーの勢力図は今後も急速に変化し続け、AI企業間の競争激化と技術進化によって新たなステージを迎えようとしています。明らかな傾向は、OpenAIのGPTBotが圧倒的なシェアを獲得し、Meta-ExternalAgentのような新規参入も急速に拡大するなど、業界が少数の主要プレーヤーに集約されつつあることです。今後は、JavaScriptレンダリングや404ページ・古いコンテンツへの無駄クロール削減など、技術的能力がさらに向上していくでしょう。また、llms.txtのような新たな標準プロトコルが登場し、ウェブサイト側からAIシステムにコンテンツ構造やクロール方針を明示できる仕組みも普及が進みます。加えて、CloudflareなどのサービスではAI学習ボットの自動ブロックが標準化されるなど、コンテンツ制御手段も高度化しています。コンテンツ制作者・ウェブサイト運営者は、AIクローラーの活動を継続的に監視し、技術基盤の最適化・AI可視性を維持しつつ、AIトラフィックがブランド露出の大きなチャネルとなる現実に対応したコンテンツ戦略を採ることが求められます。新たなクローラーエコシステムを理解し、最適化した者が今後の成功を手にする時代です。
AIクローラーは、ChatGPTやClaudeのような人工知能モデルの学習・改善のためにウェブデータを収集する自動プログラムです。Googlebotのような従来型検索エンジンクローラーが検索結果のためにコンテンツをインデックスするのに対し、AIクローラーは大規模言語モデルに投入するための生データを集めます。どちらも体系的にウェブを巡回しますが、目的や技術的な能力は異なります。
AIクローラーは、AIモデルの学習や検索機能の向上、AIの回答に最新情報を根拠づけるためにデータを収集します。ChatGPTやPerplexityのようなAIシステムは、ユーザーの質問に答える際に、正確な引用情報をリアルタイムで取得する必要があります。AIクローラーへのアクセスを許可することで、ブランドがAIの回答で言及・引用される可能性が高まります。
はい、robots.txtファイルで特定のAIクローラーのユーザーエージェント名を指定し、アクセスを拒否できます。ただし、robots.txtの遵守は任意であり、すべてのクローラーが従うわけではありません。より強力な制御には、ファイアウォールやWebアプリケーションファイアウォール(WAF)を活用し、特定のクローラーユーザーエージェントを積極的にブロックできます。これにより、どのAIクローラーがコンテンツにアクセス可能かをより確実に制御できます。
いいえ、ほとんどのAIクローラー(GPTBot、ClaudeBot、Meta-ExternalAgentなど)はJavaScriptを実行しません。ページの生のHTMLのみを読み取っており、JavaScriptで動的に読み込まれるコンテンツは認識できません。そのため、AIクローラビリティにはサーバーサイドレンダリングが重要です。クライアントサイドレンダリングに依存したサイトは、AIクローラーからは不完全なページに見えます。
AIクローラーは、コンテンツ公開直後の短期間において、従来の検索エンジンよりも頻繁に訪問します。調査によれば、公開後数日間でGoogleの8~100倍の頻度でアクセスすることもあります。ただし、コンテンツが基準に満たない場合は再訪しないこともあり、初回の印象が非常に重要です。AIクローラー向けにコンテンツを最適化するチャンスは一度きりかもしれません。
主な最適化は以下の通りです:(1) サーバーサイドレンダリングで重要なコンテンツを初期HTMLに含める、(2) 構造化データマークアップ(Schema)を追加してAIが内容を理解しやすくする、(3) コンテンツの品質と鮮度を維持する、(4) Core Web Vitalsを監視して良好なユーザー体験を保つ、(5) URL構造をシンプルにし、最新のサイトマップを維持する。これらの技術的最適化が、AIシステムによる発見・引用の基盤となります。
現在、OpenAIのGPTBotがAIクローラーの中で圧倒的なシェア(全AIクローラートラフィックの30%)を占め、前年比で305%成長しています。ただし、ClaudeBot(Anthropic)、Meta-ExternalAgent(Meta)、PerplexityBot(Perplexity)など主要なクローラー全てへの最適化が推奨されます。AIプラットフォームごとにユーザー層が異なるため、複数クローラーへの可視性を高めることでブランド露出を最大化できます。
Google Analyticsなどの従来の解析ツールはJavaScriptトラッキングに依存しているため、AIクローラーの活動は捕捉できません。代わりに、HTTPリクエストヘッダーやサーバーログを用いたサーバー側の監視が必要です。AIクローラー専用の追跡ツールを使えば、どのページがどのくらいの頻度でクロールされているか、技術的な問題が発生していないかなどをリアルタイムで可視化できます。
GPTBotやClaudeBotなどのAIクローラーがあなたのコンテンツにどのようにアクセスし、引用しているかを追跡。AmICitedでAI検索の可視性をリアルタイムで把握しましょう。
GPTBot、PerplexityBot、ClaudeBotなどのAIクローラーをサーバーログで特定・監視する方法を解説。ユーザーエージェント文字列やIP検証手法、AIトラフィック追跡のベストプラクティスもご紹介。...

2025年のAIクローラーに関する包括的ガイド。GPTBot、ClaudeBot、PerplexityBotやその他20以上のAIボットを特定。robots.txtや高度な技術でクローラーのブロック、許可、監視方法を学びましょう。...

AIクローラーをブロックするかどうかの戦略的判断方法を解説します。コンテンツタイプ、トラフィックソース、収益モデル、競争状況を評価するための包括的な意思決定フレームワークをご紹介。...
クッキーの同意
閲覧体験を向上させ、トラフィックを分析するためにクッキーを使用します。 See our privacy policy.