トレーニングデータ vs ライブ検索:AIシステムはどのように情報へアクセスするか
AIのトレーニングデータとライブ検索の違いを理解しましょう。知識カットオフ、RAG、リアルタイムリトリーバルがAIの可視性やコンテンツ戦略にどう影響するかを学びます。...
1 分で読める

ChatGPTがどこから学習データを得ているのか、引用元の仕組み、ナレッジカットオフ日、そしてAI引用を監視することがブランドにとってなぜ重要なのかを解説します。
ChatGPTの知識ベースは、多様な公開インターネットデータに加え、ライセンスデータセットや人間のフィードバックによって構築されています。 モデルは主に3つのソースで学習されています:公開インターネットデータ(ウェブサイト、記事、オンラインコンテンツ)、ライセンスデータセット(書籍や学術出版物など)、そして人間のトレーナーによるフィードバックです。学習データには、ニュースサイト、学術誌、書籍、技術ドキュメント、RedditやStack Overflowのようなフォーラム、Wikipediaの記事、そして無数の公開ウェブページが含まれます。これらのソースは多言語・多分野・多様な視点を網羅しており、ChatGPTが量子物理学から中世史、現代のポップカルチャーまで幅広く議論できる包括的な知識ベースとなっています。ただし、ChatGPTがリアルタイムの情報や専用データベースにアクセスできないこと、学習期間中に利用可能だった情報のみを参照していることを理解することが重要です。
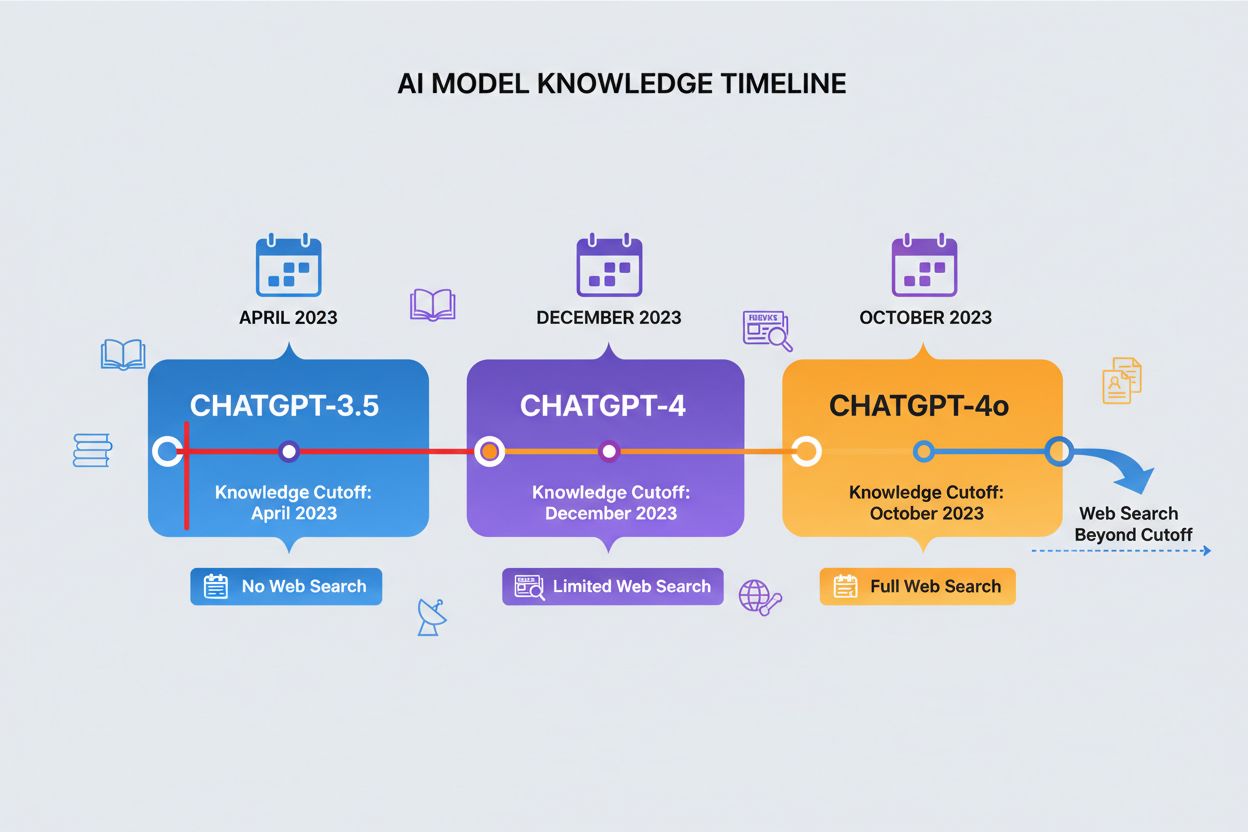
ナレッジカットオフ日とは、ChatGPTがそれ以降新たな学習データを持たない時点のことであり、アクセスできる情報の明確な境界線となります。ChatGPTのバージョンごとにカットオフ日は異なり、ChatGPT-4は2023年12月までのデータで学習、ChatGPT-4o(最適化版)は2023年10月がカットオフです。これにより、特に直近の出来事や新たに発表された研究、最新の統計など、学習データ収集以降に発生した内容への回答の正確性や妥当性に大きな影響があります。新しいChatGPTの一部バージョンではウェブ検索機能によりカットオフ日以降の情報も取得できますが、この機能は全てのバージョンや状況で利用できるわけではありません。モデルのカットオフ日を理解することは、最新情報が必要なユーザーにとって不可欠であり、ChatGPTは学習期間終了後に発生した出来事や進展について正確な回答はできません。この制限は、時事性の高い質問でChatGPTの信頼性を評価する際に最も重要な要素の一つです。
| ChatGPTバージョン | ナレッジカットオフ日 | ウェブ検索機能 | 主な利用用途 |
|---|---|---|---|
| ChatGPT-4 | 2023年12月 | 限定的 | 一般知識、分析、推論 |
| ChatGPT-4o | 2023年10月 | 利用可 | 最適化パフォーマンス、マルチモーダルタスク |
| ChatGPT-3.5 | 2023年4月 | なし | 基本的な質問、コスト重視 |
| ChatGPT(ブラウジング機能) | リアルタイム | あり | 時事問題、最新研究 |
検索エンジンが特定の文書やウェブページを検索して返すのとは異なり、ChatGPTは学習時に獲得したパターンを統合して回答を生成します。ChatGPTに質問すると、データベースやインデックスを検索するのではなく、学習データから統計的パターンを使って最も適切と思われる語の並びを予測して回答を構築します。この生成型アプローチにより、ChatGPTは学習データ内の複数の情報源を組み合わせて、ソースにはそのまま存在しない独自の回答を作り出すことができます。モデルは概念や事実、アイデア間の関係性を学び取り、特定の質問に対してこの知識を再構築します。ただし、このプロセスには大きな弱点もあり、情報が曖昧だったり学習データ内に矛盾や不足がある場合、**もっともらしいが誤った情報(ハルシネーション)**を生成することがあります。ウェブ検索機能を備えた新しいChatGPTでは、生成プロセスを補う形でインターネットから最新情報を取得できますが、この機能は明示的に有効化が必要で、全てのプラットフォームで利用できるわけではありません。
ChatGPTの学習データは、知識ベースに独自の価値をもたらす複数の主要カテゴリから構成されています:
これら多様なソースの重要性は、それぞれの強みが相互補完的である点にあります。学術論文は厳密さ、ニュース記事は時事性、書籍は深み、フォーラムは実践的応用を担います。ただしソース品質には大きなばらつきがあり、査読論文と無作為なブログ記事では信頼性が大きく異なりますが、ChatGPTの学習プロセスでは明確な区別はされません。そのため、ChatGPTの知識には高品質な情報だけでなく、低品質や誤解を招く内容も含まれることがあり、重要な判断には必ず検証が必要です。
大量のテキストデータによる初期学習の後、OpenAIは**人間のフィードバックによる強化学習(RLHF)**という手法でChatGPTの回答を洗練させました。このプロセスでは、人間のトレーナーがモデルの出力を評価しフィードバックを与えることで、より有用で正確かつ人間の価値観に沿った回答をモデルが学習します。トレーナーが全ての発言を事実チェックするわけではなく、全体的な回答の質・有用性・安全性を評価することで、モデルがどの情報を重視しどのようにトピックを提示するかに人間の判断が影響します。RLHFは純粋な統計モデルに人間的な判断を導入する点で重要ですが、このフィードバックプロセスにも限界があり、トレーナー自身のバイアスや知識の偏り、全てのドメインの正確性を評価できない点、さらにこのプロセス自体が大規模には適用できないという制約があります。そのため、ChatGPTの多くの挙動は、明示的な人間の監修よりも学習データの生のパターンに依存しています。
ChatGPTの引用は学術的誠実性と透明性のために重要であり、情報の出所や再現性、検証性を担保します。引用形式は使用するスタイルガイドによって異なりますが、代表的な例を紹介します。
MLA形式例:
OpenAI. "ChatGPT." Accessed [日付], https://chat.openai.com.
MLAではChatGPTをウェブサイトとして扱い、動的コンテンツであるためアクセス日を記載します。特定の回答を引用する場合は、アクセス日とプロンプト(質問内容)も明記しましょう。
APA形式例:
OpenAI. (2024). ChatGPT (Version 4) [Large language model].
Retrieved from https://chat.openai.com
APAではChatGPTをソフトウェアツールまたはアプリケーションとして扱い、バージョン番号と取得日を記載します。APAの一部ガイドラインでは、特定のプロンプトを引用内や補足ノートに含めることが推奨されています。
ChatGPTを引用するタイミング:学術論文や業務レポート、出典が求められる場面でChatGPTの出力を利用する場合は必ず引用しましょう。使用したプロンプト、アクセス日、バージョンを記録してください。なぜなら、同じプロンプトでも異なる結果が生成される場合があるためです。ChatGPTの回答は動的に生成されるため、プロンプト自体を引用に含めることが正しい引用慣行となります。多くの機関がAI引用の正式ガイドラインを策定中なので、所属先や投稿先のルールも確認してください。
ChatGPTは非常に高性能ですが、その情報の信頼性には重要な制限があります。ChatGPTは誤った情報(ハルシネーション)を自信を持って述べることがあるため、特にマイナーな話題やカットオフ以降の出来事、学習データ内に矛盾がある場合は注意が必要です。モデルの学習データには元ソースのバイアスが含まれており、回答が特定の視点やステレオタイプを意図せず反映することもあります。学習データの情報は時間とともに古くなるため、最新の統計や研究、変化する状況には不向きです。したがって、ChatGPTの主張は必ず検証することが不可欠です。重要な事実は複数の独立した情報源でクロスチェックし、日付や統計も最新データと照合しましょう。特に具体的な数値や人名、直近の出来事には懐疑的な視点を持つことが大切です。最後に、ChatGPTは一次情報ではなく、他の情報を統合した二次情報源であるため、学術や業務利用ではChatGPT自身ではなく、モデルが参照している元の情報源を引用してください。
ChatGPTや他のAIシステムが情報発見の主要な手段となる中で、これらのシステムがあなたのブランドや組織をどのように引用・参照しているかを監視することが、ますます重要になっています。 AmICitedは、ChatGPTやClaudeなどの大規模言語モデルによる回答の中で、あなたの会社、製品、ブランドがどのように言及・引用・参照されているかを追跡できるAI回答監視プラットフォームです。AmICitedを使えば、AI生成回答内で自社がどのように扱われているか把握でき、従来のウェブ監視ツールが見逃しがちな新しい情報流通チャネルを可視化できます。AIによる引用は従来のウェブ引用とは異なり、会話形式で埋め込まれ、数百万ユーザーが日常的にやりとりしている中で自社の表現や誤情報が伝わるにもかかわらず、多くのブランドはその実態を把握できていません。AmICitedでAI言及や引用を追跡することで、AIにおけるブランドイメージ、誤情報や古い情報の特定、競合との比較が可能になります。AIシステムが多くのユーザーにとって主要な情報源となる時代においては、これらのシステム内での自社の存在を監視することは、従来の検索結果の監視と同じくらい重要であり、AmICitedのようなツールは現代のブランド管理やAIの透明性確保に不可欠です。
ChatGPTは主に3つのソースで学習されています:公開されているインターネットデータ(ウェブサイト、記事、フォーラム)、ライセンスデータセット(書籍や学術出版物)、そして人間のトレーナーによるフィードバックです。学習データにはニュースサイト、学術誌、技術ドキュメント、Wikipedia、Reddit、Stack Overflow、その他無数の公開ウェブページが含まれています。これらはナレッジカットオフ日まで収集されています。
ナレッジカットオフ日とは、それ以降ChatGPTが新たな学習データを持たない時点のことです。ChatGPT-4は2023年12月、ChatGPT-4oは2023年10月がカットオフです。これ以降の出来事や研究、進展についてはChatGPTは正確な情報を提供できないため、時事性の高い質問には信頼できません。
ChatGPTは学習データのみではリアルタイム情報にアクセスできません。ただし、最新バージョンの一部はウェブ検索機能によりナレッジカットオフ以降の情報を取得できますが、この機能は全てのバージョンやコンテキストで利用できるわけではなく、明示的な有効化が必要です。
MLA形式ではChatGPTをウェブサイトとして、アクセス日を含めて引用します。APA形式ではソフトウェアとしてバージョン番号を記載します。いずれも使用したプロンプト、アクセス日、理想的にはChatGPTのバージョンを記載してください。同じプロンプトでも異なる結果が生成されるためです。
いいえ。ChatGPTは特にマイナーな話題やカットオフ以降の出来事、矛盾した情報については、誤った情報(ハルシネーション)を自信を持って述べることがあります。学習データにはバイアスが含まれ、情報は時間とともに古くなります。重要な内容は必ず一次情報や権威あるデータベースで確認してください。
ChatGPTの学習データは継続的には更新されません。新しいバージョンが定期的にリリースされ、カットオフ日が更新されますが、ベースモデル自体はリアルタイムで更新されません。OpenAIは(GPT-4oのような)新バージョンで新しい学習データを導入しますが、正確な更新スケジュールは公開されていません。
ChatGPTは個々の主張に対して特定のソースを引用しません。なぜなら、特定文書を参照するのではなく、学習データ内のパターンを統合して情報を生成するからです。事実の正確な出典を指摘することはできません。学術利用時はChatGPTの主張を検証し、自分で見つけた一次情報を引用してください。
AmICitedはChatGPTやClaudeなどのAIシステムが、あなたのブランドをどのように言及・引用・参照しているかを追跡します。AI生成回答内での自社の掲載状況や不正確な情報の特定、競合との比較など、AI時代のブランド管理に不可欠な可視性を提供します。
AmICitedでChatGPTの引用やAIによる言及をリアルタイムで追跡。AIシステムがあなたのブランドをどのように参照しているかを理解し、AIによる情報発見の最前線を維持しましょう。
AIのトレーニングデータとライブ検索の違いを理解しましょう。知識カットオフ、RAG、リアルタイムリトリーバルがAIの可視性やコンテンツ戦略にどう影響するかを学びます。...
ChatGPTとChatGPT Searchの主な違いを解説。リアルタイムのウェブ検索、知識のカットオフ、精度、そして最適な使い分け方を学びましょう。...
ChatGPT検索がウェブクローラー、インデックス作成、データプロバイダーとの提携を活用し、正確で引用付きの回答を提供するためにインターネットからリアルタイム情報を取得する方法を学びましょう。...
クッキーの同意
閲覧体験を向上させ、トラフィックを分析するためにクッキーを使用します。 See our privacy policy.