Slik reserverer du deg mot AI-trening på store plattformer
Fullstendig guide til hvordan du reserverer deg mot innsamling av AI-treningsdata på tvers av ChatGPT, Perplexity, LinkedIn og andre plattformer. Lær trinn-for-...
8 min lesing

Oppdag hvor ChatGPT får sine treningsdata fra, hvordan den siterer kilder, kunnskapsavskjæringsdatoer, og hvorfor det er viktig å overvåke AI-siteringer for din merkevare.
ChatGPTs kunnskapsbase er bygget på en variert samling av offentlig tilgjengelige internettdata, kombinert med lisensierte datasett og forbedret gjennom menneskelig tilbakemelding. Modellen ble trent på tre hovedkilder: offentlig tilgjengelige internettdata (nettsteder, artikler og nettinnhold), lisensierte datasett (inkludert bøker og akademiske publikasjoner), og menneskelig tilbakemelding fra trenere som har hjulpet til med å finjustere svarene. Disse treningsdataene omfatter et usedvanlig bredt spekter av kilder, inkludert nyhetsnettsteder, akademiske tidsskrifter, bøker, teknisk dokumentasjon, forum som Reddit og Stack Overflow, Wikipedia-artikler og utallige andre offentlig tilgjengelige nettsider. Det enorme omfanget og mangfoldet av disse kildene—på tvers av språk, domener og perspektiver—skaper en omfattende kunnskapsbase som gjør det mulig for ChatGPT å diskutere alt fra kvantefysikk til middelalderhistorie til moderne populærkultur. Det er imidlertid viktig å forstå at ChatGPT ikke har tilgang til sanntidsinformasjon eller proprietære databaser; den kan kun trekke på det som var tilgjengelig under treningsperioden.
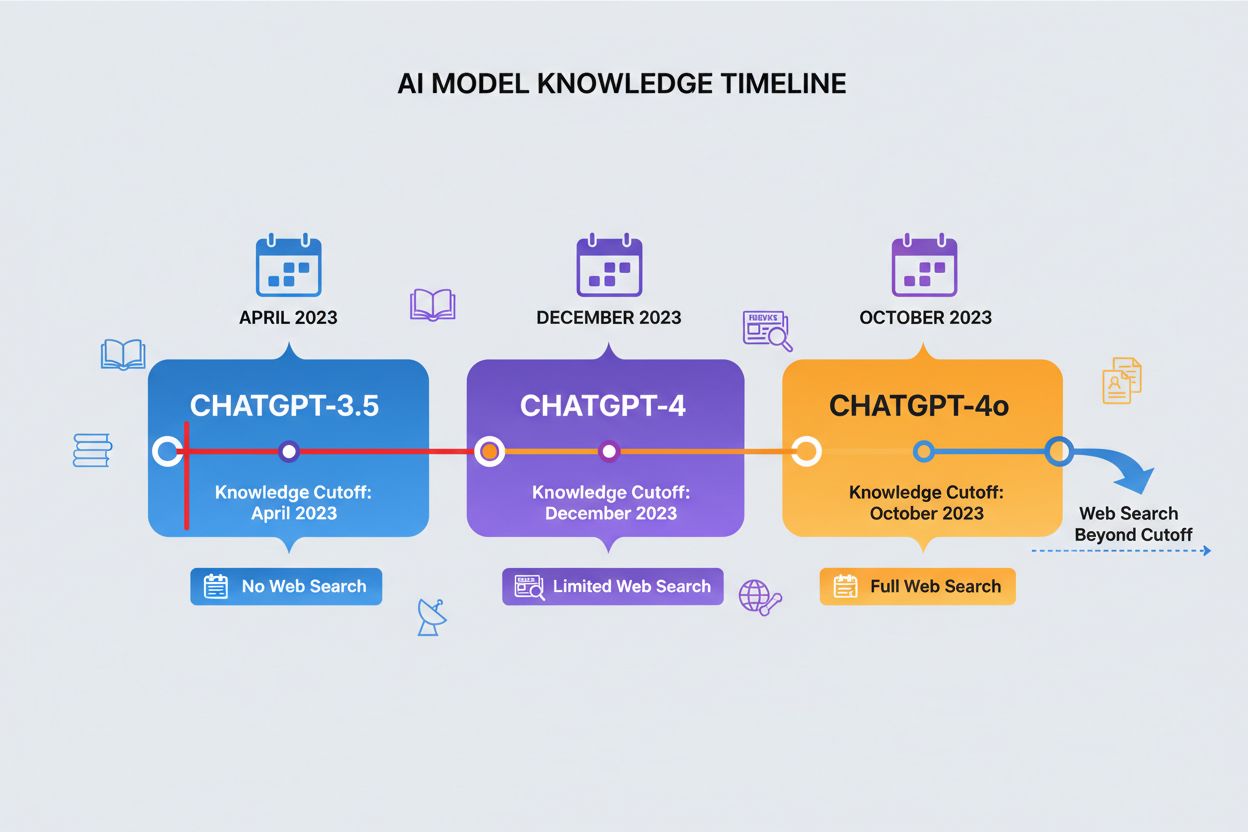
En kunnskapsavskjæringsdato er tidspunktet etter hvilket ChatGPT ikke har treningsdata, og utgjør en hard grense for hvilken informasjon den kan få tilgang til. Ulike versjoner av ChatGPT har forskjellige avskjæringsdatoer: ChatGPT-4 ble trent på data frem til desember 2023, mens ChatGPT-4o (den optimaliserte versjonen) har avskjæringsdato oktober 2023. Disse avskjæringsdatoene påvirker nøyaktigheten og relevansen av svarene betydelig, spesielt for nye hendelser, nylig publisert forskning eller aktuelle statistikker som kan ha endret seg siden treningsdataene ble samlet inn. Noen nyere versjoner av ChatGPT kan utføre nettsøk for å hente oppdatert informasjon utover sine avskjæringsdatoer, men denne funksjonen er ikke tilgjengelig i alle versjoner eller sammenhenger. Å kjenne til modellens avskjæringsdato er avgjørende for brukere som trenger oppdatert informasjon, da ChatGPT ikke kan gi nøyaktige svar om hendelser eller utvikling som har skjedd etter treningsperiodens slutt. Denne begrensningen er en av de viktigste faktorene å vurdere når du vurderer ChatGPTs pålitelighet for tidssensitive spørsmål.
| ChatGPT-versjon | Kunnskapsavskjæringsdato | Nettsøk-funksjon | Primært bruksområde |
|---|---|---|---|
| ChatGPT-4 | Desember 2023 | Begrenset | Generell kunnskap, analyse, resonnement |
| ChatGPT-4o | Oktober 2023 | Tilgjengelig | Optimalisert ytelse, multimodale oppgaver |
| ChatGPT-3.5 | April 2023 | Nei | Enkle spørsmål, kostnadseffektivt alternativ |
| ChatGPT med nettlesing | Sanntid | Ja | Aktuelle hendelser, ny forskning |
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
I motsetning til søkemotorer som henter spesifikke dokumenter eller nettsider som svar på spørsmål, genererer ChatGPT svar ved å syntetisere mønstre lært under treningen—en grunnleggende annerledes prosess. Når du stiller ChatGPT et spørsmål, søker den ikke i en database eller et register; i stedet bruker den statistiske mønstre fra treningsdataene for å forutsi den mest sannsynlige ordsekvensen som vil utgjøre et nyttig svar. Denne generasjonsbaserte tilnærmingen innebærer at ChatGPT kombinerer informasjon fra flere kilder i sine treningsdata for å skape nye svar som kanskje ikke finnes ordrett i kildematerialet. Modellen lærer i hovedsak relasjoner mellom konsepter, fakta og ideer, og rekonstruerer denne kunnskapen som svar på ditt spesifikke spørsmål. Dette har imidlertid en betydelig ulempe: når modellen er usikker på informasjon eller når mønstrene i treningsdataene er motstridende eller sparsomme, kan den generere troverdige, men feilaktige opplysninger, et fenomen kjent som “hallusinasjon”. Nyere versjoner av ChatGPT som integrerer nettsøk-funksjonalitet kan supplere denne generasjonsprosessen ved å hente oppdatert informasjon fra internett, men denne funksjonen krever eksplisitt aktivering og er ikke tilgjengelig på alle plattformer.
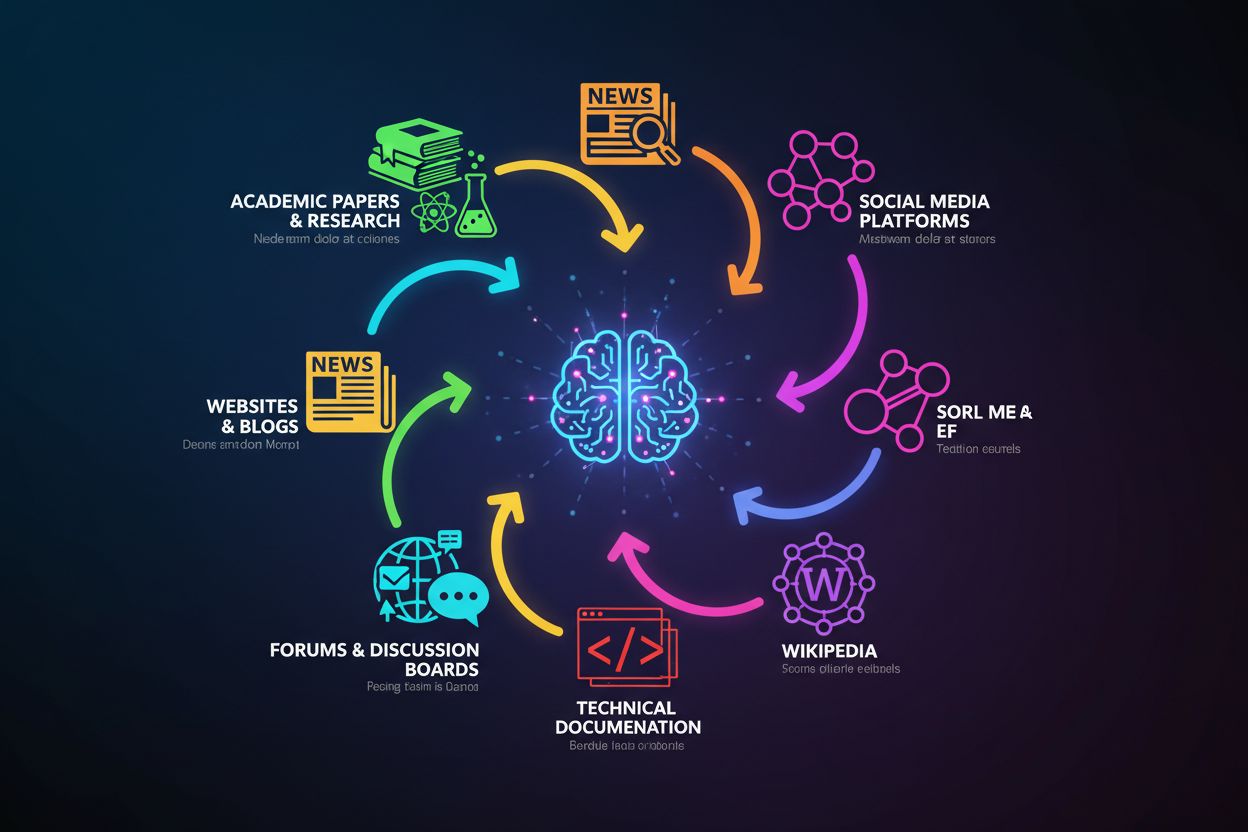
ChatGPTs treningsdata hentes fra flere hovedkategorier av kilder, hvor hver bidrar med unik verdi til kunnskapsbasen:
Betydningen av disse mangfoldige kildene ligger i deres utfyllende styrker: akademiske artikler gir grundighet, nyhetsartikler gir aktualitet, bøker gir dybde, og forum gir praktisk anvendelse. Likevel varierer kildekvaliteten betydelig—en fagfellevurdert akademisk artikkel veier tyngre enn et tilfeldig blogginnlegg, men ChatGPTs treningsprosess skiller ikke eksplisitt mellom dem. Det betyr at ChatGPTs kunnskap gjenspeiler både høykvalitets autoritative kilder og lavkvalitets eller potensielt misvisende innhold, og derfor er verifisering avgjørende ved bruk av modellen til viktige beslutninger.
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Etter den innledende treningen på store mengder tekstdata, benyttet OpenAI en teknikk kalt forsterkende læring fra menneskelig tilbakemelding (RLHF) for å forbedre ChatGPTs svar. I denne prosessen evaluerte menneskelige trenere modellens svar og ga tilbakemelding, slik at systemet lærte hvilke svar som var mest nyttige, nøyaktige og samsvarte med menneskelige verdier. Disse trenerne faktasjekket ikke hvert utsagn; de vurderte heller den samlede svar-kvaliteten, nytteverdien og sikkerheten, som indirekte former hvordan modellen prioriterer og presenterer informasjon. RLHF-prosessen har stor innflytelse på hvilken informasjon som vektlegges i svarene og hvordan ulike temaer fremstilles, og tilfører menneskelig vurdering til det som ellers ville vært en rent statistisk modell. Likevel har denne tilbakemeldingsprosessen iboende begrensninger: trenerne har egne skjevheter, kunnskapshull og begrensninger, og de kan umulig vurdere nøyaktigheten av hvert utsagn på tvers av alle fagområder. I tillegg er tilbakemeldingsprosessen ressurskrevende og kan kun brukes på en brøkdel av modellens mulige svar, noe som betyr at mye av ChatGPTs atferd fortsatt gjenspeiler råmønstrene i treningsdataene snarere enn eksplisitt menneskelig kuratering.
Å sitere ChatGPT er viktig for akademisk integritet og åpenhet, slik at lesere kan forstå hvor informasjonen kommer fra og potensielt reprodusere eller verifisere funnene dine. Siteringsformatet avhenger av hvilken stilguide du må følge, men her er de vanligste tilnærmingene:
Eksempel på MLA-format:
OpenAI. "ChatGPT." Lest [Dato], https://chat.openai.com.
I MLA-stil siterer du ChatGPT som et nettsted, inkludert tilgangsdato siden innholdet er dynamisk og kan endres. Hvis du siterer et spesifikt svar, bør du oppgi datoen du fikk tilgang og helst også prompten eller spørsmålet du stilte.
Eksempel på APA-format:
OpenAI. (2024). ChatGPT (Versjon 4) [Stor språkmodell].
Hentet fra https://chat.openai.com
APA-format behandler ChatGPT som et programvareverktøy eller en applikasjon, inkludert versjonsnummer og hentingsdato. Noen APA-retningslinjer anbefaler å inkludere den spesifikke prompten i siteringen eller som et tillegg.
Når du skal sitere ChatGPT: Du bør sitere verktøyet hver gang du bruker dets output i akademiske arbeider, profesjonelle rapporter eller enhver sammenheng hvor attribusjon er viktig. Dokumenter den eksakte prompten du brukte, dato for tilgang, og helst hvilken ChatGPT-versjon, da dette påvirker reproduserbarhet. Den viktigste forskjellen mellom å sitere ChatGPT og tradisjonelle kilder er at ChatGPT-svar genereres dynamisk—samme prompt kan gi litt ulike svar ved forskjellige anledninger—så å inkludere selve prompten blir en del av korrekt siteringspraksis. Mange institusjoner utvikler fortsatt formelle retningslinjer for AI-sitering, så sjekk med din egen organisasjon eller publikasjon for deres foretrukne format.
Selv om ChatGPT er svært kapabel, har den betydelige begrensninger som påvirker påliteligheten til informasjonen. ChatGPT kan selvsikkert oppgi feil informasjon, et problem kjent som hallusinasjon, spesielt når den spørres om obskure temaer, nylige hendelser etter kunnskapsavskjæringen, eller når den møter motstridende informasjon i treningsdataene. Modellens treningsdata inneholder innebygde skjevheter som gjenspeiler perspektivene, demografien og synspunktene i kildematerialet, noe som betyr at svarene utilsiktet kan favorisere visse perspektiver eller inneholde stereotypier. Informasjon i ChatGPTs treningsdata blir gradvis utdatert over tid, noe som gjør den upålitelig for oppdaterte statistikker, ny forskning eller situasjoner under utvikling. Av disse grunnene er faktasjekk av ChatGPTs påstander helt essensielt, spesielt for viktige avgjørelser—du bør verifisere sentrale fakta mot primærkilder, nylige publikasjoner og autoritative databaser. For å verifisere ChatGPTs påstander, kryssjekk uttalelsene med flere uavhengige kilder, sammenlign datoer og statistikker mot oppdatert data, og vær spesielt skeptisk til konkrete tall, navn eller nylige hendelser. Husk til slutt at ChatGPT ikke er en primærkilde; den er en sekundærkilde som syntetiserer informasjon fra andre kilder, så for akademisk eller profesjonelt arbeid bør du sitere de opprinnelige kildene ChatGPT refererer til, ikke ChatGPT selv.
Etter hvert som ChatGPT og andre AI-systemer blir stadig mer integrert i hvordan folk oppdager informasjon, har det blitt avgjørende å overvåke hvordan disse systemene siterer og refererer til din merkevare eller organisasjon. AmICited er en AI-svarsovervåkningsplattform designet spesielt for å spore hvordan ChatGPT, Claude og andre store språkmodeller nevner, siterer eller refererer til ditt selskap, produkter eller merkevare på tvers av sine svar. Plattformen hjelper deg å forstå når og hvordan merkevaren din dukker opp i AI-genererte svar, og gir innsikt i en ny og voksende informasjonskanal som tradisjonelle overvåkingsverktøy ofte overser. Denne overvåkingsfunksjonaliteten er viktig fordi AI-siteringer fungerer annerledes enn tradisjonelle nettsiteringer—de er innebygd i samtalesvar som millioner av brukere interagerer med daglig, men de fleste merkevarer har ingen oversikt over hvordan de blir fremstilt. Ved å bruke AmICited til å spore AI-omtaler og siteringer, får du innsikt i merkevarens omdømme i AI-systemer, kan identifisere unøyaktigheter eller utdatert informasjon som må korrigeres, og forstå hvordan merkevaren din sammenlignes med konkurrenter i AI-genererte svar. I en tid der AI-systemer blir primære informasjonskilder for mange brukere, er overvåking av din tilstedeværelse i disse systemene like viktig som å overvåke tradisjonelle søkeresultater, og gjør verktøy som AmICited essensielle for moderne merkevareledelse og åpenhet rundt AI.
Spor ChatGPT-siteringer og AI-omtaler i sanntid med AmICited. Forstå hvordan AI-systemer refererer til din merkevare og hold deg foran AI-drevet informasjonsoppdagelse.
Fullstendig guide til hvordan du reserverer deg mot innsamling av AI-treningsdata på tvers av ChatGPT, Perplexity, LinkedIn og andre plattformer. Lær trinn-for-...
Forstå forskjellen mellom AI-treningsdata og live-søk. Lær hvordan kunnskapsavskjæringer, RAG og sanntidsuthenting påvirker AI-synlighet og innholdsstrategi....
Informasjonskapselsamtykke
Vi bruker informasjonskapsler for å forbedre din surfeopplevelse og analysere vår trafikk. See our privacy policy.