AI検索におけるRAGとは:リトリーバル拡張生成の完全ガイド
AI検索におけるRAG(リトリーバル拡張生成)とは何かを学びましょう。RAGが精度を向上させ、幻覚を減らし、ChatGPT、Perplexity、Google AIの基盤となる仕組みを解説します。...
1 分で読める

検索拡張生成(RAG)がAIの引用をどのように変革し、ChatGPT、Perplexity、Google AI Overviewsなどで正確な出典明記と根拠ある回答を実現するかを解説します。
大規模言語モデル(LLM)はAIに革命をもたらしましたが、重大な弱点を抱えています。それが知識のカットオフです。これらのモデルは特定時点までのデータで学習されているため、それ以降の情報にはアクセスできません。情報が古くなりやすいだけでなく、従来のLLMは幻覚(もっともらしいが誤った情報の自信満々な生成)を起こしやすく、主張の出典を明記しません。企業が最新の市場データや独自調査、検証可能な事実を求める場合、従来のLLMでは信頼できる答えが得られず、ユーザーは検証もできない回答しか得られません。
**検索拡張生成(Retrieval-Augmented Generation, RAG)**は、LLMの生成力と情報検索システムの精度を組み合わせたフレームワークです。学習データのみに頼らず、RAGシステムは回答生成前に外部ソースから関連情報を検索し、実際のデータに根差した回答を生み出します。4つの中核要素が連携します:インジェスト(文書を検索可能な形式に変換)、検索(最も関連性の高いソースを見つける)、拡張(検索した文脈でプロンプトを強化)、生成(引用付きで最終回答を生成)。従来手法との比較は以下の通りです:
| 観点 | 従来型LLM | RAGシステム |
|---|---|---|
| 知識ソース | 静的な学習データ | 外部インデックス化ソース |
| 引用機能 | なし/幻覚 | 出典追跡可能 |
| 正確性 | エラーが多い | 事実ベース |
| リアルタイムデータ | 不可 | 可能 |
| 幻覚リスク | 高い | 低い |
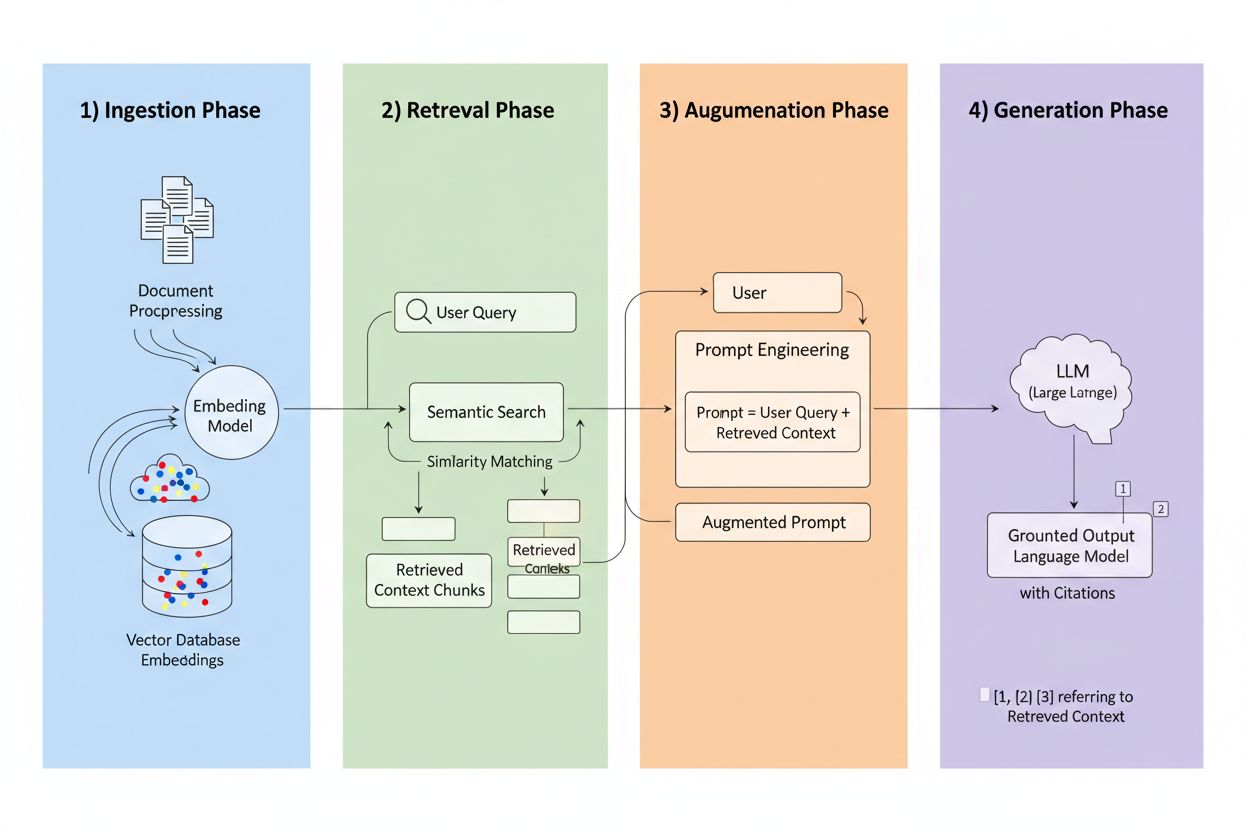
検索エンジンはRAGの心臓部であり、単なるキーワードマッチよりはるかに高度です。文書はベクトル埋め込み(意味を数学的に表現したもの)に変換され、単語が一致しなくても概念的に近い内容を見つけられます。文書は通常256〜1024トークンの単位でチャンク化され、文脈維持と検索精度を両立します。先進的なRAGはハイブリッド検索(意味的類似とキーワードマッチの併用)を採用し、概念一致と完全一致の両方をキャッチします。リランキング機構で候補にスコアを付け、クロスエンコーダーモデル等により初回検索より精度高く関連度を評価します。関連度は意味的類似スコア、キーワード重複、メタデータ一致、ドメインオーソリティなど複数のシグナルで計算。これら一連の処理はミリ秒単位で完了し、ユーザーは遅延を感じることなく迅速かつ正確な回答を得られます。
RAGが引用の在り方を変える点はここです。システムが特定のインデックス化ソースから情報を取得した場合、そのソースは追跡・検証可能になります。各テキストチャンクは元の文書・URL・出版物にマッピングでき、引用が幻覚ではなく自動で行われます。この根本的な変化によりAIの意思決定の透明性が前例のないレベルで実現。ユーザーはどのソースが回答に使われたかを明確に確認・検証でき、自分で出典の信頼性を判断できます。従来型LLMでは引用が捏造・一般論になりがちですが、RAG引用は実際の検索イベントに基づきます。この追跡可能性でユーザーの信頼が飛躍的に高まり、情報を鵜呑みにする必要がなくなります。コンテンツ制作者や出版社にとっても、自分の情報がAIを通じて発見・クレジットされる新たな可視性チャネルが生まれます。
RAGシステム内で全てのソースが均等に扱われるわけではなく、どのコンテンツが頻繁に引用されるかは複数の要素で決まります:
これら要素が互いに作用し合い、権威あるドメインのよく構造化され頻繁更新されている記事は、RAGで引用の磁石となります。可視性最適化は従来のSEOのようなトラフィック主導型から、信頼できる構造化情報源になることへとパラダイムが変化しています。
AIプラットフォームごとにRAGの実装戦略が異なり、引用パターンも多様です。ChatGPTはWikipediaソースを重視し、全引用の約26〜35%をWikipediaが占めるという調査もあり、その権威性と構造化が反映されています。Google AI Overviewsはさらに多様なソースを活用し、ニュースサイト・学術論文・フォーラムを幅広く参照、Redditのような従来権威性が低いサイトも約5%引用されています。Perplexity AIは1回答で3〜5ソースを引用し、業界専門誌や最新ニュースへの志向が強く、網羅性と即時性に最適化されています。各プラットフォームでドメインオーソリティの重み付けは異なり、被リンクやドメイン年齢を重視するもの、鮮度や意味的関連性を重視するものと様々です。こうしたプラットフォームごとの検索戦略を理解することが、コンテンツ制作者にとって最適化の鍵となります。
RAGの台頭は従来SEOの常識を根底から覆します。従来の検索エンジン最適化では、引用と可視性はトラフィックと直結していました。RAGではこの方程式が逆転します:トラフィックがなくても、コンテンツは引用されAI回答に影響を与えるのです。よく構造化された権威ある記事は、1日数十回AIに引用されてもクリックはゼロ、なぜならユーザーがAIサマリーで直接回答を得るからです。したがって権威シグナルがこれまで以上に重要となり、RAGがソース品質を評価する主要メカニズムとなります。プラットフォームを横断した一貫性も重要で、自サイトだけでなくLinkedInや業界データベース、ナレッジグラフ上でも情報が一致していると、権威シグナルが強化されます。ナレッジグラフへの掲載は「あると便利」から「必須インフラ」へと進化し、多くのRAGが主要取得元としています。引用競争は「トラフィック獲得」から「信頼情報源化」へと本質が変わりました。
RAG引用を最大化するには、トラフィック重視からソース重視の戦略へ転換が必要です。48〜72時間サイクルで定期更新し、情報が新しいことを検索システムに伝えましょう。構造化データマークアップ(Schema.orgやJSON-LD等)でコンテンツの意味や関係性を明示。よくあるクエリパターンと意味的に整合するよう自然な言語で記述し、「検索キーワード」より「質問文」に寄せましょう。FAQやQ&A形式で記述すると、RAGの質問応答パターンと直結します。Wikipediaやナレッジグラフへの掲載・寄稿はほぼすべてのプラットフォームでの主要取得源となるので必須。被リンク権威性も依然として重要で、信頼ある他サイトからの引用やパートナーシップで強化しましょう。最後に全プラットフォームで一貫性を保つこと――自社サイト、SNS、業界DB、ナレッジグラフで主張・データ・メッセージを揃え、信頼性シグナルを重層化しましょう。
RAG技術は急速に進化しており、引用の仕組みも大きく変わろうとしています。高度な検索アルゴリズムは意味的類似を超え、クエリ意図や文脈をより深く理解する方向に進化し、引用の関連度がさらに向上します。ドメイン特化ナレッジベースも登場し、医療分野なら専門文献、法律分野なら判例や法令など、分野ごとに権威ある情報源が新たな引用機会を生みます。マルチエージェントシステムとの統合で、複数の専門リトリーバルが連携し、異なる知識ベースから洞察を統合したより包括的な回答を生成。リアルタイムデータ取得も飛躍的に進化し、APIやDB、ストリーミングソースから最新情報を即座に引用できるようになります。さらにエージェンティックRAG(AIエージェントが自律的に何を取得し、どう処理し、いつ再検索するかを決定)が普及すれば、引用パターンはますます動的となり、推論の洗練とともに同一ソースの複数回引用も一般化します。
RAGが情報源の発見・引用の仕組みを変える中、引用パフォーマンスの把握は不可欠です。AmICitedは複数プラットフォームでのAI引用をモニタリングし、自社のどの情報源がChatGPT、Google AI Overviews、Perplexity、そして新興AIシステムで引用されているかを追跡します。どのソースが何回、どんな文脈で引用されているかを可視化し、RAG検索アルゴリズムで際立つコンテンツの特徴を明らかにします。自社コンテンツ全体の引用パターンを把握し、どの要素が引用に寄与し、どれが埋もれるのかを分析可能。RAG時代に重要なブランド可視性を数値化し、従来のトラフィック指標を超えた評価軸を提供します。競合との引用パフォーマンス比較も行え、AI生成回答内で自社情報源がどの程度目立つかも把握できます。AI引用が可視性と権威性を左右する時代、引用パフォーマンスの明確な把握は競争力維持の必須条件です。
従来のLLMは静的な学習データに依存し、知識のカットオフがあるため、リアルタイム情報にアクセスできず、しばしば幻覚や検証不能な主張が生じます。RAGシステムは、応答生成前に外部のインデックス化された情報源からデータを検索し、最新かつ検証可能なデータに基づいた正確な引用と根拠ある回答を実現します。
RAGは取得した情報の各要素を元の情報源に遡って追跡できるため、引用が自動的かつ検証可能となり、幻覚に頼ることがありません。回答とソース資料の間に直接的なリンクが生まれ、ユーザーは主張を独自に検証し、出典の信頼性を判断できます。
RAGシステムは、権威性(ドメインの評判や被リンク)、新しさ(48〜72時間以内の更新)、クエリとの意味的関連性、コンテンツ構造と明確さ、具体的なデータポイントを含む事実密度、Wikipediaなどのナレッジグラフへの掲載状況などを評価し、これらの複合要素で引用される確率が決まります。
48〜72時間ごとにコンテンツを更新して鮮度シグナルを維持し、構造化データマークアップ(Schema.org)を実装、一般的なクエリに意味的整合性を持たせ、FAQやQ&A形式を活用、Wikipediaやナレッジグラフへの掲載、被リンク構築、すべてのプラットフォームで一貫性を保ちましょう。
WikipediaやWikidataのようなナレッジグラフは多くのRAGシステムの主要な取得元です。これらの構造化データベースに掲載されることで引用される確率が大幅に高まり、AIシステムが多様なクエリで繰り返し参照する基礎的な信頼シグナルとなります。
RAGシステムで強い新鮮さシグナルを保つには、48〜72時間ごとにコンテンツを更新しましょう。全面的な書き換えは不要で、新しいデータ追加や統計更新、最近の動向を反映したセクション拡張で十分です。
ドメインオーソリティはRAGアルゴリズムで信頼性の代理指標となり、引用確率の約5%を占めます。ドメイン年齢、SSL証明書、被リンク、専門家の記載、ナレッジグラフ掲載などで評価され、情報源選択に寄与します。
AmICitedは、ChatGPT、Google AI Overviews、PerplexityなどAI生成回答で自社の情報源がどれだけ引用されているかを追跡。引用頻度や文脈、競合比較などが把握でき、RAG時代に引用されやすいコンテンツの特徴を理解できます。
ChatGPT、Perplexity、Google AI Overviewsなど、AI生成回答で自社ブランドがどのように表示されているかを把握。引用パターンを追跡し、可視性を測定し、AI主導の検索環境でプレゼンスを最適化しましょう。
AI検索におけるRAG(リトリーバル拡張生成)とは何かを学びましょう。RAGが精度を向上させ、幻覚を減らし、ChatGPT、Perplexity、Google AIの基盤となる仕組みを解説します。...
RAGがLLMと外部データソースを組み合わせて正確なAI応答を生成する仕組みを解説。5段階のプロセス、構成要素、ChatGPTやPerplexityなどのAIシステムで重要な理由を理解します。...
コミュニティによるRAG(リトリーバル拡張生成)の説明と、そのAI検索最適化への影響についての議論。RAGがどのようにコンテンツ戦略を変えるかの本質的な洞察。...
クッキーの同意
閲覧体験を向上させ、トラフィックを分析するためにクッキーを使用します。 See our privacy policy.