
LLMs.txtとは何か?本当に効果があるのか、導入すべきか?
LLMs.txtとは何か、本当に効果があるのか、あなたのウェブサイトに実装すべきかを学びましょう。この新しいAI SEO標準に対する正直な分析です。...
1 分で読める

LLMs.txtの有効性に関する批判的分析。このAIコンテンツ標準があなたのサイトに不可欠なのか、単なる宣伝なのかを探ります。普及状況、プラットフォームの対応、AIで本当に効果のある可視化手法の実データ。
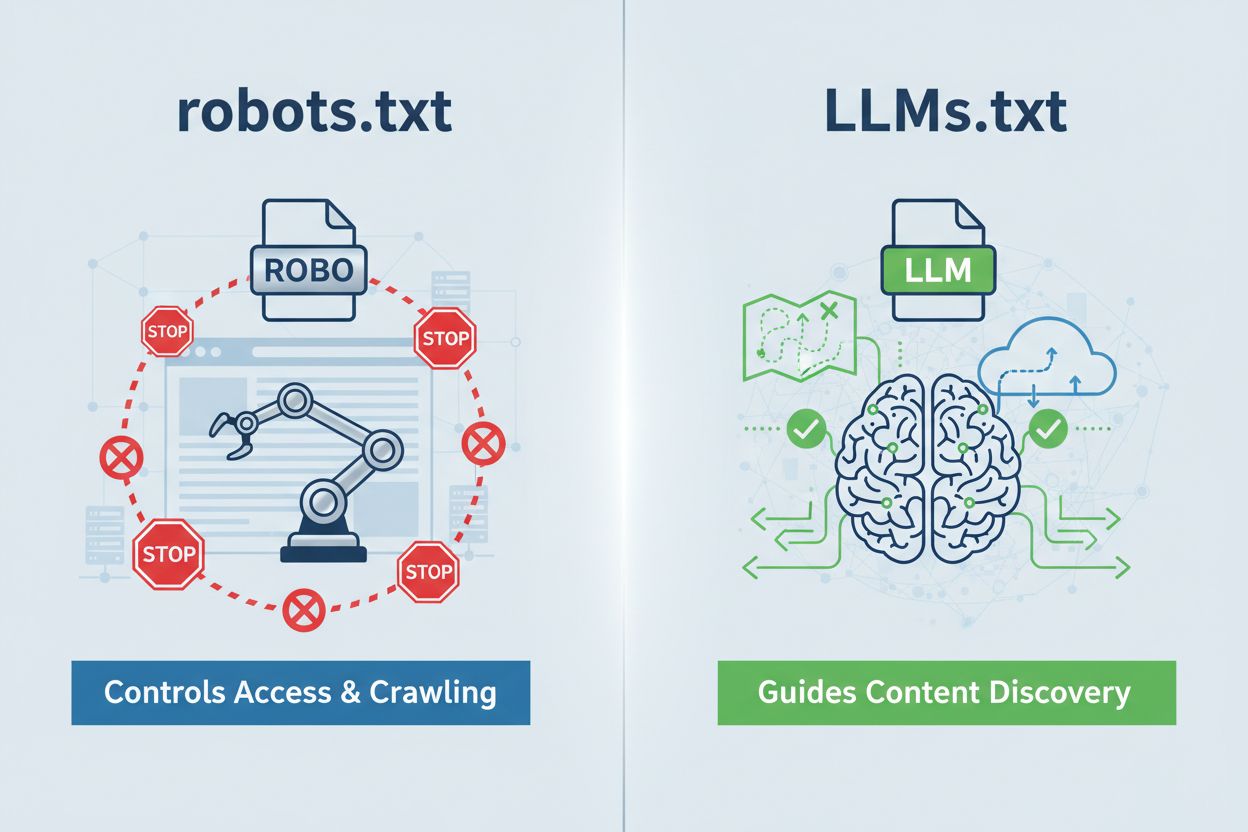
LLMs.txtはドメイン直下のdomain.com/llms.txtに設置するプレーンテキストファイルで、AIシステムにあなたの最良コンテンツへの道筋を示すガイドです。robots.txtとは根本的に異なり、robots.txtがAIクローラーのアクセス可否を制御するのに対し、LLMs.txtは推論時アクセスに関与し、AIが回答生成時にどのページを優先すべきかを伝えます。交通整理ではなく宝の地図のような存在で、探索を妨げるのではなく、本当の価値を見つけやすくします。形式は非常にシンプルでマークダウン記法のみ。複雑な構文は一切不要なので、技術力を問わず誰でも導入できます。この違いが重要なのは、LLMs.txtがクロール制御ではなく、AI向けコンテンツの解釈と優先順位付けの最適化に主眼を置いているからです。
数字が示す通り、2025年10月時点で84万4,000以上のウェブサイトがLLMs.txtを導入しており、AIの将来性を理解する企業を中心に普及しています。Anthropic、Cloudflare、Stripe、Vercel、Supabaseなど主要ITインフラ企業が標準を導入し、実験価値を見出しています。2024年11月にはMintlifyが数千のドキュメントサイトで自動生成機能を有効化し、導入が急増。現在、3つのコミュニティディレクトリで実装状況が追跡され、788以上のサイトが確認済みです。しかし、導入パターンから分かるのは、開発者向けツールやドキュメント系プラットフォームに強く偏っているという事実。AI可視性の恩恵を最も受ける業界が牽引しているのです。実際の普及状況は下記の通りです:
| 企業・プラットフォーム | 導入状況 | トークン数 | ステータス |
|---|---|---|---|
| Anthropic | 導入済み | 約2,000 | 稼働中 |
| Cloudflare | 導入済み | 約5,000 | 稼働中 |
| Stripe | 導入済み | 約8,000 | 稼働中 |
| Vercel | 導入済み | 約3,500 | 稼働中 |
| Supabase | 導入済み | 約4,200 | 稼働中 |
| Mintlify(自動生成) | 導入済み | サイトごとに異なる | 稼働中 |
ここで懐疑論が正当化されます。主要なAIプラットフォームでLLMs.txtをリトリーバルに公式採用したと明言した例はゼロです。GoogleのJohn Muellerは「現在llms.txtを使うAIシステムは存在しない」と断言しました。OpenAI、Anthropic、Google、Microsoft、Perplexityいずれも公式文書や利用宣言、ロードマップを公表していません。一部プラットフォームがクロール動作(MicrosoftやOpenAIのボットによる取得)は確認されていますが、「クロール」と「実際の利用」は全く別です。楽観的な見方は「水面下で実験中」、懐疑的な見方は「本質的な課題解決にならないので採用されない」となります。この沈黙こそが「過大評価」論の核心。提案から18か月が経過し、普及だけは進んでも、プラットフォーム側の公式採用はゼロ。これは標準ではなく、ただの期待です。
懐疑派はLLMs.txtでAIリトリーバルやトラフィック、可視性が向上したという証拠が一つもないことを根拠にしています。信頼性の問題も深刻で、HTMLとは別の内容をLLMs.txtに記載できてしまい、不正操作の温床となり得ます。LLMの挙動研究でも特別に強調・ターゲットされたコンテンツは2.5倍推薦されやすいことが判明し、ゲーム化の動機が明らかです。企業はLLMs.txtに優良ページだけ載せたり、実際は存在しないコンテンツを記載したりも理論上可能です。SEOツールベンダーも「LLMs.txt未設置は最適化不足」と警告し、Rank MathやSEMrushなどが「ツールによる通知→導入」という自己強化サイクルを生んでいます。これが問題の本質:18か月間、効果の実証が一例もないまま、ツールに煽られて導入だけ進行。まるで宝くじ会社の宣伝で皆が宝くじを買うような現象です。
LLMs.txt推進派の論拠は全く異なり、「今の証拠」ではなく「変化の必然性」に根差します。YoastのCarolyn Shelbyは**「順位づけが目的ではなく、引用されること自体が賞だ」**と表現しました。AIコードエディタのWindsurfはLLMs.txtでドキュメント解析の時間やトークン消費が実際に削減できたと報告し、導入効果を示唆しています。AnthropicはMintlifyに対しLLMs.txt導入を依頼しており、公式認定はなくとも内部価値があることを示しています。GoogleもA2A(Agents to Agents)プロトコルにLLMs.txtを組み込み、AI同士のインフラ要素と見なしています。実装は1〜4時間、デメリットなし——SEOも壊さず、何も損なわない。「99.9%の注目は今後LLMからのものになり、人間からではない」(Jeremy Howard)という指摘は、AI最適化はもはや選択ではなく不可避だと示します。Springs Appsは導入後検索可視性が20%向上したと報告していますが、これは未検証で相関関係にすぎない可能性があります。
LLMs.txtが失敗する理由を知るには、他の標準がなぜ成功したかを比較する必要があります。robots.txtは最小コストで相互利益を生み、公式RFC(RFC 9309)も得て普及しました。検索エンジンは効率的なクロールを求め、サイト側もコントロールを求め、シンプルで摩擦のない解決策でした。Schema.orgはGoogle、Microsoft、Yahoo、Yandexの協調開発で信頼を獲得。Sitemap.xmlは普及前に主要プラットフォームの対応を確保しました。LLMs.txtは三つとも欠けています:W3C関与なし、コンソーシアム支援なし、公式プラットフォーム対応なし、トラフィックやランキング・精度向上の実証効果もなし。標準が本当に機能する条件は、多主体の合意、明確なメリット、ゲーム化リスクの低さ。LLMs.txtには希望とアーリーアダプターの導入、ツール支援はありますが、過去の標準をインフラへと進化させた根本要素がありません。
LLMs.txtが未証明な現状で、AI可視性やAIによる引用を実現するために有効な手法は案外シンプルです:
これらの手法は、特定ファイル形式への最適化ではなく、AIの情報処理ロジックそのものに沿った施策だから効果があります。

LLMs.txtを巡る議論は、人間UXとAI最適化の融合というより深い潮流を象徴しています。生成エンジン最適化(GEO)の研究によれば、AI回答で上位表示されるコンテンツには「明快さ」「構造」「権威性」「具体性」が共通します。Vercelは新規登録の1割がChatGPTでの言及経由だと報告し、従来のオーガニック検索とは異なる流入経路が生まれています。今や「AI回答に登場すること」が成功の新基準であり、従来の順位獲得とは異なる最適化が求められます。ツール類も進化しており、SEMrush AIOやProfoundのGEOトラッキング、Ahrefs Brand RadarなどがAI可視性も測定対象に。根本的な発想転換は、**「順位より引用」「インデックスより参照されること」**が重要になったという点です。この変化は、LLMs.txtが公式対応なしでも注目された理由であり、AIが主な流通経路となる新しいアテンション経済への適応策なのです。
導入するなら正しく行いましょう。ファイルはdomain.com/llms.txt(単数形ではなく複数形)に設置、形式はXMLやJSONではなくプレーンテキストのマークダウンで記載します。最初にH1見出しでサイト名、続いて必要なら引用(ブロッククオート)でサイトの目的を説明。サイトに複数のセクションがあればH2で区分(ドキュメント、ブログ、APIリファレンス等)、それぞれの説明を添えます。個別ページの記載は [タイトル](URL): 説明 形式で、説明は簡潔かつ要点明確に。含めるべきは:定番かつ構造化されたページ、専門性を示せるコンテンツ。避けるべきは:トップページ(単体で価値が低い)、全URL掲載(量より質)、文脈がなければ意味不明なページ。基本構成例は以下の通りです:
# 会社名
> AIシステムがなぜあなたのコンテンツを参照すべきかの簡潔な説明
## ドキュメント
[はじめに](https://example.com/docs/getting-started): 新規ユーザー向けステップバイステップガイド
[APIリファレンス](https://example.com/docs/api): 例付きの完全なAPIドキュメント
[ベストプラクティス](https://example.com/docs/best-practices): プラットフォーム活用の実証済みパターン
## ブログ
[開発経緯](https://example.com/blog/why-we-built-this): 解決した課題と背景
必要があれば、短い文脈で十分な場合にスキップすべきURLのセクションも作れますが、多くの実装ではそこまでの細分化は不要です。
はい、LLMs.txtは導入すべきです。なぜならデメリットがゼロで、アップサイドが現実的に存在するからです。仮にAIプラットフォームが永久に採用しない場合でも、ファイルは無害にサーバー上にあるだけ——SEOペナルティも、トラフィック減少も、機能不全も起こりません。小規模サイトなら10分、大規模でも1時間程度で設置可能です。一方、トラフィックはChatGPT、Perplexity、Claudeなど複数AIに分散しており、月間数億件のクエリがやり取りされています。すでにAIから見られている今、LLMs.txtで「最高のコンテンツ」への道筋を示すことができます。仮に公式標準にならなくても、AIにサイト構造や優先度を伝えることで、十分な価値があります。肝心なのは、無料でリスクヘッジできるということ。標準を導入し、実証済みのAI可視化施策も並行し、AIからの流入を実測する。12か月後には、LLMs.txtがあなたのビジネスで本当に意味があるかどうか、推測よりはるかに価値ある実データが手に入るでしょう。
LLMs.txtは、AIシステムが推論時にアクセスするための最適なコンテンツを案内するプレーンテキストファイルです。一方、robots.txtはクローラーのアクセスとインデックス化を制御します。LLMs.txtは何も制限しません。AIが理解すべき価値あるページをキュレートし、強調する役割です。robots.txtが交通整理なら、LLMs.txtは宝の地図のようなものです。
公式には利用していません。導入しているウェブサイトは84万4,000件以上ありますが、どの主要AIプラットフォームもLLMs.txtを応答生成に使っていると正式には表明していません。OpenAIやMicrosoftのボットによるクロール活動の証拠はありますが、推論や引用のために利用しているという確証はありません。これが「過大評価」論の核心です。
はい。導入には10〜30分しかかからず、デメリットはありません。もしプラットフォームが採用すれば有利な立場になりますし、採用されなくてもファイルが害を及ぼすことはありません。AI可視性のためのリスクの少ない投資です。AIを介したコンテンツ発見の未来に賭けるようなものです。
具体的な質問に答える定番で構造化されたコンテンツを含めてください。ガイド、FAQ、APIドキュメント、ピラーコンテンツ、権威ある記事などです。トップページや全URL、文脈がないと意味が通じないページは避けましょう。量より質が重要です。
はい、これは正当な懸念です。実際のページと異なる内容をLLMs.txtに記載することも可能で、それは信頼を損ないます。そのため、この標準の長期的な存続に懐疑的な専門家もおり、プラットフォームの採用も慎重です。
llms.txtは選別されたベストページと説明文を含むファイルです。llms-full.txtは全ドキュメントを一括収録した大規模ファイル(時に40万語超)です。リンクを辿らせず全ての情報をAIに一度に与えたい場合はllms-full.txtを使います。
LLMs.txtはGEO戦略の一部です。GEOはAIがコンテンツを発見・引用しやすくするため、明確な構造・引用・データ・専門性の発揮を重視します。LLMs.txtはAIを最適なGEO対応コンテンツに導く役割を果たします。
はい。どのウェブサイトもAIがコンテンツを理解・引用しやすくする恩恵があります。ブログ、地域ビジネス、EC、ニッチなコミュニティもAI検索から流入があります。LLMs.txtはChatGPT、Claude、PerplexityなどAIプラットフォームでの可視性を高める簡単な方法です。
ChatGPT、Claude、PerplexityなどのAIシステムがどのようにあなたのコンテンツを参照しているかを追跡。AIによる引用や可視性をリアルタイムで把握しましょう。
LLMs.txtとは何か、本当に効果があるのか、あなたのウェブサイトに実装すべきかを学びましょう。この新しいAI SEO標準に対する正直な分析です。...

LLMs.txtファイルとは何か、robots.txtとの違い、そしてChatGPT、Perplexity、Google AI OverviewsでAIによる可視性と引用に不可欠な理由を学びましょう。導入ガイド付き。...

AIシステムがあなたのコンテンツをよりよく理解できるよう、LLMs.txtをウェブサイトに実装する方法を学びます。WordPress、Shopify、静的サイトを含むすべてのプラットフォーム向けの完全なステップバイステップガイド。...
クッキーの同意
閲覧体験を向上させ、トラフィックを分析するためにクッキーを使用します。 See our privacy policy.