
NoAIメタタグ
NoAIメタタグとは何か、AIスクレイピングを防ぐ仕組み、実装方法、そして無断のAIトレーニングからコンテンツを守るための有効性について解説します。...
1 分で読める

noaiとnoimageaiメタタグを実装し、AIクローラーによるウェブサイトコンテンツへのアクセスを制御する方法を学びます。AIアクセス制御ヘッダーと実装方法の完全ガイド。
ウェブクローラーは、インターネットを体系的に巡回し、ウェブサイトから情報を収集する自動プログラムです。従来、これらのボットは主にGoogleなどの検索エンジンによって運用されており、Googlebotがページをクロールし、コンテンツをインデックス化し、検索結果を通じてユーザーをウェブサイトに誘導していました。これは双方にメリットのある関係でした。しかし、AIクローラーの登場によってこのダイナミクスは根本的に変化しました。従来の検索エンジンボットがコンテンツアクセスと引き換えにリファラルトラフィックをもたらしていたのに対し、AI学習クローラーはウェブ上の膨大なコンテンツを消費して大型言語モデルのデータセットを構築しますが、多くの場合出版社にほとんど、あるいは全くトラフィックを返しません。この変化によって、メタタグ(クローラーに指示を伝える小さなHTML命令)は、コンテンツ制作者が自分の作品がAIシステムにどのように利用されるかをコントロールする上でますます重要になっています。
noaiおよびnoimageaiメタタグは、DeviantArtが2022年に作成した指示で、コンテンツ制作者が自分の作品をAI画像生成モデルの学習データとして利用されるのを防ぐためのものです。これらのタグは、検索エンジンにページをインデックスしないよう伝えるnoindex指示と同様のしくみで動作します。noaiはページ上の全てのコンテンツをAI学習に使わせないことを示し、noimageaiは画像のみのAI学習利用を防ぎます。これらのタグはHTMLのheadセクションに以下の構文で実装できます:
<!-- すべてのコンテンツをAI学習から除外 -->
<meta name="robots" content="noai">
<!-- 画像のみAI学習から除外 -->
<meta name="robots" content="noimageai">
<!-- コンテンツと画像の両方を除外 -->
<meta name="robots" content="noai, noimageai">
以下は、さまざまなメタタグ指示とその目的の比較表です:
| 指示 | 目的 | 構文 | 対象範囲 |
|---|---|---|---|
| noai | すべてのコンテンツのAI学習利用防止 | content="noai" | ページ全体 |
| noimageai | 画像のAI学習利用防止 | content="noimageai" | 画像のみ |
| noindex | 検索エンジンのインデックス防止 | content="noindex" | 検索結果 |
| nofollow | リンク先のクロール防止 | content="nofollow" | 外部リンク |
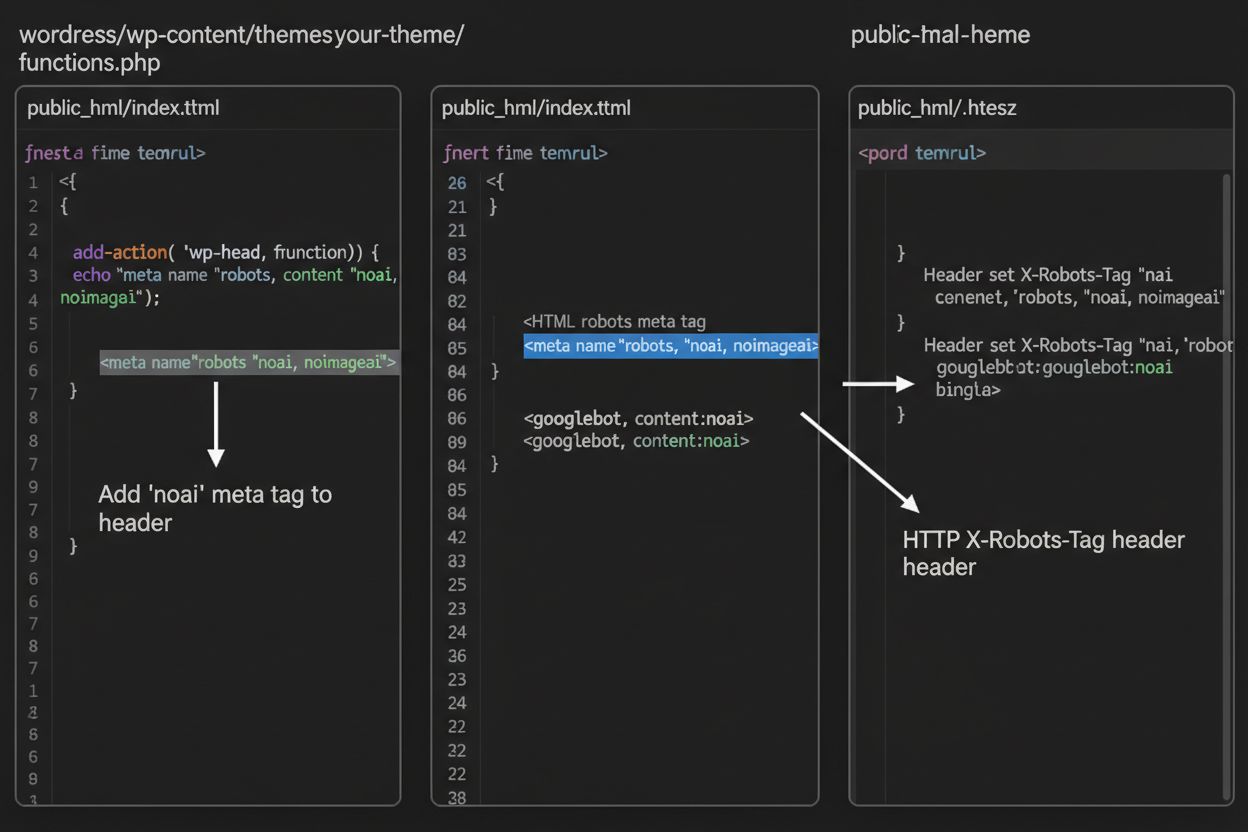
メタタグがHTML内に直接書かれるのに対し、HTTPヘッダーはサーバーレベルでクローラーへの指示を伝える別の方法です。X-Robots-Tagヘッダーはメタタグと同じ指示を含めることができますが、ページコンテンツの配信前にHTTPレスポンスとして送信されます。この方法は、PDFや画像、動画などHTMLメタタグを埋め込めない非HTMLファイルへのアクセス制御に特に有効です。
Apacheサーバーでは、.htaccessファイルでX-Robots-Tagヘッダーを設定できます:
<IfModule mod_headers.c>
Header set X-Robots-Tag "noai, noimageai"
</IfModule>
NGINXサーバーでは、サーバー設定ファイルにヘッダーを追加します:
location / {
add_header X-Robots-Tag "noai, noimageai";
}
ヘッダーはサイト全体や特定ディレクトリへのグローバルな保護を提供するため、包括的なAIアクセス制御戦略に最適です。
noaiおよびnoimageaiタグの有効性は、クローラーがこれらを尊重するかどうかに完全に依存します。主要なAI企業のマナーを守るクローラーは一般的にこれらの指示を遵守します:
一方で、マナーの悪いボットや悪意のあるクローラーは、強制手段がないためこれらの指示を意図的に無視することがあります。検索エンジンが業界標準としてrobots.txtを遵守することに合意しているのとは異なり、noaiは公式なウェブ標準ではないため、クローラーに従う義務はありません。そのため、セキュリティ専門家はメタタグだけに頼らず、複数の保護手段を組み合わせるレイヤー型アプローチを推奨しています。
noaiおよびnoimageaiタグの実装はウェブサイトのプラットフォームによって異なります。以下は代表的なプラットフォームごとの手順です:
1. WordPress(functions.phpによる方法) 子テーマのfunctions.phpファイルに以下のコードを追加します:
function add_noai_meta_tag() {
echo '<meta name="robots" content="noai, noimageai">' . "\n";
}
add_action('wp_head', 'add_noai_meta_tag');
2. 静的HTMLサイト
HTMLの<head>セクションに直接追加します:
<head>
<meta name="robots" content="noai, noimageai">
</head>
3. Squarespace 設定>詳細>コードインジェクションに移動し、ヘッダーセクションに追加します:
<meta name="robots" content="noai, noimageai">
4. Wix 設定>カスタムコードに進み、「カスタムコード追加」を選択してメタタグを貼り付け、「Head」を選び、すべてのページに適用します。
各プラットフォームは異なる制御レベルを提供しています。WordPressではプラグインを使ってページ単位で実装でき、SquarespaceやWixではサイト全体に適用する方法が用意されています。ご自身の技術レベルやニーズに最も適した方法を選択してください。
noaiおよびnoimageaiタグはコンテンツ制作者保護への重要な一歩ですが、大きな限界も存在します。第一に、これらは公式なウェブ標準ではありません。DeviantArtによるコミュニティ主導で設計されたため、公式な仕様や強制力がありません。第二に、遵守は完全に任意です。主要企業のマナーを守るクローラーは指示を守りますが、マナーの悪いボットやスクレイパーは罰則なく無視できます。第三に、標準化されていないため普及度に差があります。一部の小規模AI企業や研究機関はそもそもこれらの存在を知らない場合もあります。最後に、メタタグだけでは悪意のあるクローラーのスクレイピングを防げません。悪意のあるクローラーは指示を完全に無視できるため、包括的なコンテンツ保護には追加の防御策が不可欠です。
最も効果的なAIアクセス制御戦略は、複数層の保護手段を組み合わせることです。代表的なアプローチの比較表:
| 方法 | 対象範囲 | 効果 | 難易度 |
|---|---|---|---|
| メタタグ(noai) | ページ単位 | 中(任意遵守) | 簡単 |
| robots.txt | サイト全体 | 中(助言のみ) | 簡単 |
| X-Robots-Tagヘッダー | サーバーレベル | 中〜高(全ファイル型対応) | 中 |
| ファイアウォールルール | ネットワークレベル | 高(インフラ遮断) | 難しい |
| IPホワイトリスト | ネットワークレベル | 非常に高い(検証済みのみ許可) | 難しい |
包括的な戦略例:(1)全ページにnoaiメタタグ実装、(2)robots.txtで既知のAI学習クローラーをブロック、(3)非HTMLファイルにサーバーレベルでX-Robots-Tagヘッダーを設定、(4)サーバーログ監視により指示を無視するクローラーを特定。こういったレイヤー型アプローチにより、マナーの悪いクローラーの難易度が大きく上がり、マナーを守るクローラーとの互換性も維持できます。
noaiタグやその他指示を実装した後は、クローラーが実際にルールを守っているか検証すべきです。最も直接的なのはサーバーアクセスログでクローラーの活動を確認する方法です。Apacheサーバーでは、特定のクローラーを検索できます:
grep "GPTBot\|ClaudeBot\|PerplexityBot" /var/log/apache2/access.log
ブロックしたクローラーからのリクエストが見られる場合、それらは指示を無視しています。NGINXサーバーでは/var/log/nginx/access.logを同じgrepコマンドで確認します。また、Cloudflare Radarのようなツールを使えばサイト全体のAIクローラートラフィック傾向を可視化でき、どのボットが活発かや行動変化も把握できます。定期的(月1回程度)のログ監視で新たなクローラーの発見や保護策の有効性確認が可能です。
現状、noaiやnoimageaiはグレーゾーンに位置しており、主要AI企業には広く認知・尊重されていますが、公式の標準としては未だ策定されていません。しかし、正式な標準化に向けた動きが加速しています。W3C(World Wide Web Consortium)や業界団体では、AIアクセス制御を公式標準とするための議論が進行中であり、これが実現すればrobots.txtなど既存標準と同様に高い効果が期待できます。noaiが公式標準となれば、遵守が業界慣行となるため、実効性が大幅に向上します。この標準化の流れは、コンテンツ制作者の権利とAI開発・出版社保護のバランスに対する業界全体の意識変化を反映しています。より多くの出版社がタグを導入し強い保護を求めることで、公式標準化の可能性が高まり、AIアクセス制御が検索エンジンインデックスルールと同等にウェブ運用の基本となる日も近いでしょう。
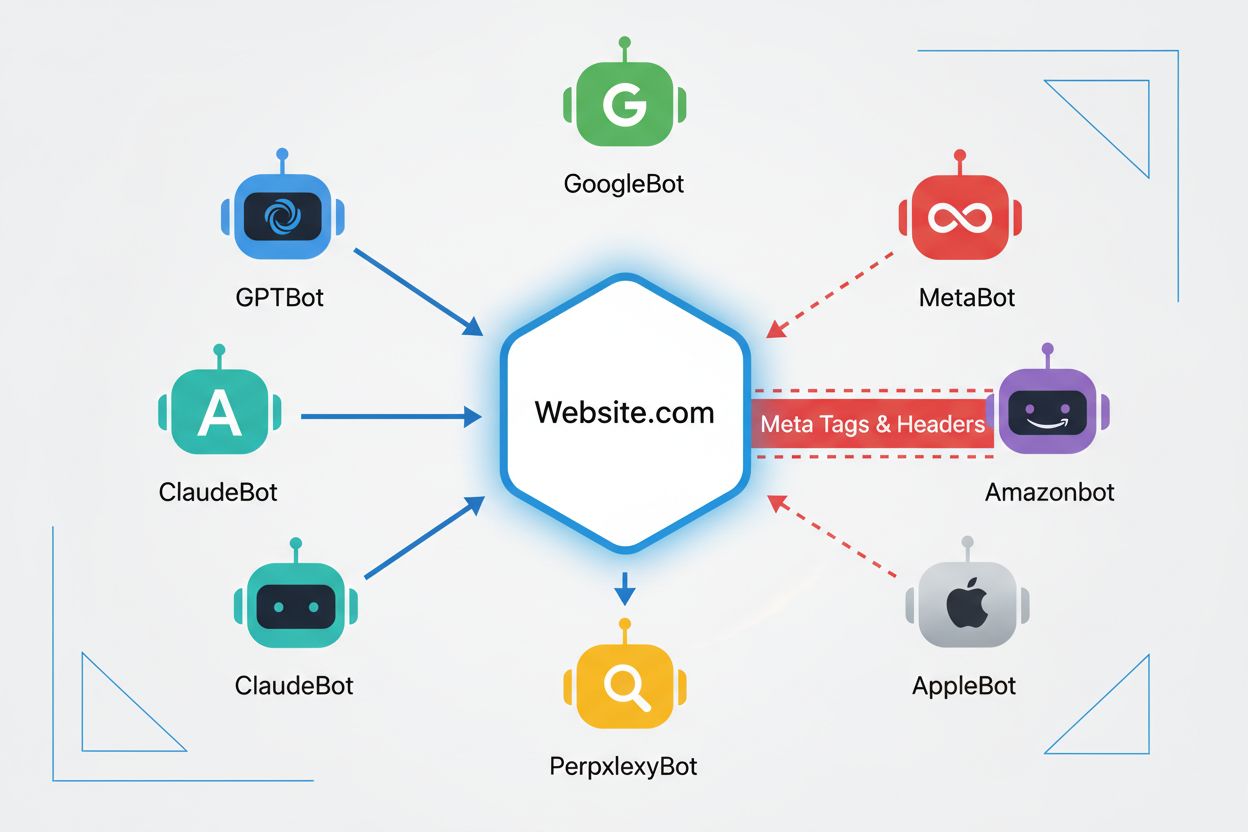
noaiメタタグは、ウェブサイトのHTMLヘッド部分に配置する指示で、AIクローラーに対してコンテンツをAIモデルの学習に利用しないよう伝える役割を果たします。これは、マナーを守るAIボットに意向を伝えるものですが、公式なウェブ標準ではないため、一部のクローラーは無視する場合があります。
いいえ、noaiおよびnoimageaiは公式なウェブ標準ではありません。これらはDeviantArtがAI学習から作品を保護するためのコミュニティ主導のイニシアチブとして作成したものです。ただし、OpenAIやAnthropicなどの主要なAI企業は自社クローラーでこれらの指示に従うようになっています。
主要なAIクローラー(GPTBot(OpenAI)、ClaudeBot(Anthropic)、PerplexityBot(Perplexity)、Amazonbot(Amazon)など)はnoai指示を尊重します。ただし、小規模またはマナーの悪いクローラーはこれを無視することがあるため、複層的な防御策を推奨します。
メタタグはHTMLヘッド部分に配置し、ページ単位で適用されます。一方、HTTPヘッダー(X-Robots-Tag)はサーバーレベルで設定でき、サイト全体やファイル種別ごとに適用可能です。ヘッダーはPDFや画像などHTML以外のファイルにも有効で、包括的な保護に適しています。
はい、WordPressではテーマのfunctions.phpファイルへのコード追加、WPCodeなどのプラグイン利用、DiviやElementorなどのページビルダーを通じてnoaiタグを実装できます。最も一般的なのはfunctions.phpへの簡単なフック追加による方法です。
これはビジネス目標によります。学習クローラーをブロックすることでコンテンツのAIモデル開発利用を防げますが、OAI-SearchBotのような検索クローラーをブロックするとAI搭載の検索結果での露出が減少する場合があります。多くの出版社は学習クローラーのみブロックし、検索クローラーは許可する選択的な方法を採用しています。
サーバーログでクローラーの活動を確認できます。grepコマンドで特定のボットのユーザーエージェントを検索したり、Cloudflare RadarなどのツールでAIクローラーのトラフィック傾向を可視化できます。ブロックしたクローラーがアクセスしている場合、指示が無視されていることになりますので、定期的にログを監視しましょう。
クローラーがメタタグを無視する場合は、robots.txtルール、X-Robots-Tag HTTPヘッダー、.htaccessやファイアウォールによるサーバーレベルのブロックなど追加の保護策を講じましょう。より強力な検証には、主要AI企業が公開している検証済みクローラーIPアドレスのみを許可するIPホワイトリスト化も有効です。
AmICitedを利用して、ChatGPT、Perplexity、Google AI OverviewsなどのAIシステムが様々なAIプラットフォーム上であなたのコンテンツをどのように引用・参照しているかを追跡しましょう。
NoAIメタタグとは何か、AIスクレイピングを防ぐ仕組み、実装方法、そして無断のAIトレーニングからコンテンツを守るための有効性について解説します。...

noai メタタグについて、その仕組みやAIのトレーニングデータ収集を防ぐ方法、制限事項、そしてウェブサイトでの実装方法を学び、あなたのコンテンツをジェネレーティブAIプログラムから守る方法を解説します。...
noaiメタタグがAIの学習からコンテンツを本当に守れるのかについてのコミュニティディスカッション。ユーザーの実体験やこの方法の限界について共有されています。...
クッキーの同意
閲覧体験を向上させ、トラフィックを分析するためにクッキーを使用します。 See our privacy policy.