
AIボットによるウェブサイトのクロール許可方法:robots.txt&llms.txt完全ガイド
GPTBot、PerplexityBot、ClaudeBotなどのAIボットによるサイトクロールの許可方法を解説します。robots.txt・llms.txtの設定やAI向け最適化の方法もわかります。...
2 分で読める

Alexa、Rufusショッピングアシスタント、AmazonのAI搭載検索機能を含む製品とサービスを改善するために使用されるAmazonのウェブクローラー。Robots Exclusion Protocolを尊重し、robots.txtディレクティブを通じて制御できます。AIモデルトレーニングに使用される可能性があります。
Alexa、Rufusショッピングアシスタント、AmazonのAI搭載検索機能を含む製品とサービスを改善するために使用されるAmazonのウェブクローラー。Robots Exclusion Protocolを尊重し、robots.txtディレクティブを通じて制御できます。AIモデルトレーニングに使用される可能性があります。
Amazonbotは、ウェブコンテンツを収集・分析することで会社の製品とサービスを改善するために設計されたAmazonの公式ウェブクローラーです。この高度なクローラーは、Alexaボイスアシスタント、Rufus AIショッピングアシスタント、AmazonのAI搭載検索体験を含む重要なAmazon機能を動かしています。Amazonbotはユーザーエージェント文字列Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; Amazonbot/0.1; +https://developer.amazon.com/support/amazonbot) Chrome/119.0.6045.214 Safari/537.36を使用して動作し、ウェブサーバーに自身を識別します。Amazonbotによって収集されたデータはAmazonの人工知能モデルのトレーニングに使用される可能性があり、Amazonのより広いAIインフラストラクチャと製品開発戦略の重要なコンポーネントとなっています。
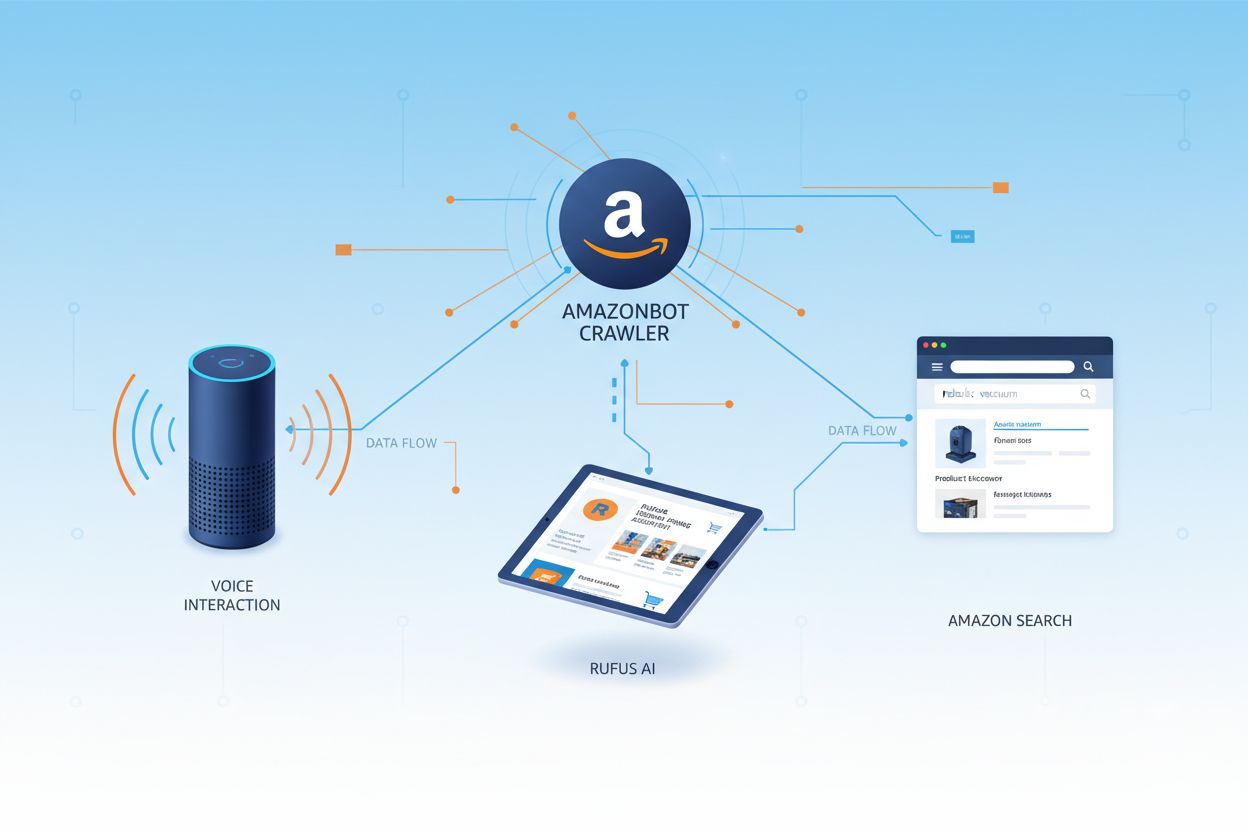
Amazonはエコシステム内で特定の目的を果たす3つの異なるウェブクローラーを運用しています。Amazonbotは一般的な製品とサービスの改善に使用される主要クローラーであり、AIモデルトレーニングに使用される可能性があります。Amzn-SearchBotはAlexaやRufusなどのAmazon製品での検索体験を改善するために特別に設計されていますが、重要なことに、生成AIモデルトレーニングのためにコンテンツをクロールしません。Amzn-Userは、顧客が最新のウェブデータを必要とする質問をAlexaに尋ねたときなど、ユーザーが開始したアクションをサポートし、AIトレーニング目的でクロールしません。3つのクローラーすべてがRobots Exclusion Protocolを尊重し、robots.txtディレクティブに従うため、ウェブサイト所有者はアクセスを制御できます。
| クローラー名 | 主な目的 | AIモデルトレーニング | ユーザーエージェント | 主なユースケース |
|---|---|---|---|---|
| Amazonbot | 一般的な製品/サービス改善 | はい | Amazonbot/0.1 | 全体的なAmazonサービス強化、AIトレーニング |
| Amzn-SearchBot | 検索体験の改善 | いいえ | Amzn-SearchBot/0.1 | Alexa検索、Rufusショッピングアシスタントインデックス |
| Amzn-User | ユーザー開始のライブデータ取得 | いいえ | Amzn-User/0.1 | リアルタイムAlexaクエリ、現在の情報リクエスト |
Amazonは業界標準のRobots Exclusion Protocol(RFC 9309)を尊重しており、ウェブサイト所有者はrobots.txtファイルを通じてAmazonbotアクセスを制御できます。Amazonはドメインのルート(例:example.com/robots.txt)からホストレベルのrobots.txtファイルを取得し、ファイルを取得できない場合は過去30日間のキャッシュコピーを使用します。robots.txtファイルへの変更は、Amazonのシステムに反映されるまで通常約24時間かかります。
Amazonbotアクセスを制御する方法の例:
# サイト全体からAmazonbotをブロック
User-agent: Amazonbot
Disallow: /
# 検索可視性のためにAmzn-SearchBotを許可
User-agent: Amzn-SearchBot
Allow: /
# Amazonbotから特定のディレクトリをブロック
User-agent: Amazonbot
Disallow: /private/
# 他のすべてのクローラーを許可
User-agent: *
Disallow: /admin/
ボットトラフィックを懸念するウェブサイト所有者は、Amazonbotを主張するクローラーが実際に正当なAmazonクローラーであることを確認すべきです。Amazonは、本物のAmazonbotトラフィックを確認するためのDNSルックアップを使用した検証プロセスを提供しています。
検証プロセスの例:
$ host 12.34.56.789
789.56.34.12.in-addr.arpa domain name pointer 12-34-56-789.crawl.amazonbot.amazon.
$ host 12-34-56-789.crawl.amazonbot.amazon
12-34-56-789.crawl.amazonbot.amazon has address 12.34.56.789
AIモデルトレーニングに関してAmazonのクローラー間に重要な区別が存在します。Amazonbotは Amazonの人工知能モデルのトレーニングに使用される可能性があります。これは、AIトレーニング目的で作品が使用されることを懸念するコンテンツクリエイターに関連します。対照的に、Amzn-SearchBotとAmzn-Userは生成AIモデルトレーニングのためにコンテンツをクロールしないことを明示的に宣言しており、検索体験の改善とユーザークエリのサポートにのみ焦点を当てています。
RufusはAmazonの高度なAIショッピングアシスタントであり、ウェブクローリングとAI技術を活用してパーソナライズされたショッピング推奨と支援を提供します。Amazonbotが Amazonの全体的なAIインフラストラクチャに貢献する一方、Rufusは特にショッピングクエリに関連する製品情報とウェブコンテンツのインデックスにAmzn-SearchBotを使用します。
ウェブサイト所有者は、特定のビジネス目標とコンテンツポリシーに基づいてAmazonのクローラーを管理するための戦略的アプローチを開発すべきです:
noarchive robotsメタタグを使用するか、robots.txtで完全にブロックamazonbot@amazon.comでAmazonのサポートチームに連絡Amazonbotは製品とサービスを改善するために使用されるAmazonの汎用クローラーであり、AIモデルトレーニングに使用される可能性があります。Amzn-SearchBotはAlexaとRufusでの検索体験のために特別に設計されており、AIモデルトレーニングのためにクロールしないことを明示しています。AIトレーニング使用を防ぎたい場合は、Amazonbotをブロックし、検索可視性のためにAmzn-SearchBotを許可してください。
ドメインのルートにあるrobots.txtファイルに次の行を追加します:User-agent: Amazonbotの後にDisallow: /。これにより、Amazonbotがサイト全体をクロールするのを防ぎます。特定のディレクトリのみをブロックするためにDisallow: /specific-path/も使用できます。
はい、AmazonbotはAmazonの人工知能モデルのトレーニングに使用される可能性があります。これを防ぎたい場合は、ページのHTMLヘッダーにrobotsメタタグを使用してください。これは、Amazonbotにページをモデルトレーニングに使用しないよう指示します。
クローラーのIPアドレスで逆引きDNSルックアップを実行し、ドメインがcrawl.amazonbot.amazonのサブドメインであることを確認します。次に、取得したドメイン名で正引きDNSルックアップを実行し、元のIPアドレスに解決されることを確認します。developer.amazon.com/amazonbot/ip-addresses/でAmazonの公開IPアドレスも確認できます。
標準のrobots.txt構文を使用します:User-agent: Amazonbotでクローラーをターゲットにし、Disallow: /ですべてのアクセスをブロックするか、Disallow: /path/で特定のディレクトリをブロックします。Allow: /を使用してアクセスを明示的に許可することもできます。
Amazonは通常、約24時間以内にrobots.txtの変更を反映します。Amazonは定期的にrobots.txtファイルを取得し、最大30日間キャッシュコピーを維持するため、変更がシステム全体に伝播するまで丸一日かかる場合があります。
はい、絶対にできます。robots.txtファイルで各クローラーに対して個別のルールを作成できます。例えば、User-agent: Amzn-SearchBotとAllow: /でAmzn-SearchBotを許可し、User-agent: AmazonbotとDisallow: /でAmazonbotをブロックします。
amazonbot@amazon.comでAmazonに直接連絡してください。メッセージには常にドメイン名と懸念事項に関する関連詳細を含めてください。Amazonのサポートチームは、特定の状況に対する個別のガイダンスを提供できます。
AmICited - 主要なAI回答モニタリングプラットフォームで、Alexa、Rufus、Google AIオーバービューなどのAIシステム全体でブランドの言及を追跡しましょう
GPTBot、PerplexityBot、ClaudeBotなどのAIボットによるサイトクロールの許可方法を解説します。robots.txt・llms.txtの設定やAI向け最適化の方法もわかります。...
Amazon SEOとは何か、A9アルゴリズムの仕組み、Amazonマーケットプレイスでのランキング向上と売上増加のための実証済みの商品リスティング最適化戦略を学びましょう。...

PerplexityBotクローラーの完全ガイド - 仕組みの理解、アクセス管理、引用の監視、Perplexity AIでの可視性の最適化までを解説。ステルスクローリングの懸念点やベストプラクティスも学べます。...
クッキーの同意
閲覧体験を向上させ、トラフィックを分析するためにクッキーを使用します。 See our privacy policy.