
AIシステムはエンティティ間の関係をどのように理解するのか?
AIシステムがテキスト内のエンティティ間の関係をどのように特定・抽出・理解するかを学びましょう。エンティティ関係抽出技術、NLP手法、実際の応用例を紹介します。...
1 分で読める

エンティティ曖昧性解消は、複数のエンティティが同じ名前を共有している場合に、特定の言及がどのエンティティを指しているかを特定するプロセスです。これにより、AIシステムが名前付きエンティティの参照における曖昧さを解消し、「Apple」という言及がApple Inc.、果物、または同じ名前の他のエンティティのいずれを指しているのかを正確に特定できるようになり、正確に内容を理解し引用することが可能となります。
エンティティ曖昧性解消は、複数のエンティティが同じ名前を共有している場合に、特定の言及がどのエンティティを指しているかを特定するプロセスです。これにより、AIシステムが名前付きエンティティの参照における曖昧さを解消し、「Apple」という言及がApple Inc.、果物、または同じ名前の他のエンティティのいずれを指しているのかを正確に特定できるようになり、正確に内容を理解し引用することが可能となります。
エンティティ曖昧性解消は、複数のエンティティが同じ名前や類似の参照を持つ場合に、特定の言及がどのエンティティを指しているのかを特定するプロセスです。人工知能(AI)や自然言語処理(NLP)の文脈において、エンティティ曖昧性解消は、AIシステムがテキスト内の名前付きエンティティに遭遇した際に、それがどの実世界の物体・人物・組織・場所を指しているかを正確に識別する役割を担います。これは**名前付きエンティティ認識(NER)**とは本質的に異なります。NERは単にエンティティの存在を認識し、「人物」「組織」「場所」といったカテゴリに分類するだけですが、曖昧性解消は「ここにエンティティがあるか?」ではなく「これはどの特定のエンティティか?」という問いに答えます。たとえば「Apple was the brain-child of Steve Jobs.」という文を処理する際、NERは「Apple」を組織として認識しますが、エンティティ曖昧性解消はそれがApple Inc.(テクノロジー企業)なのか、同名の他のエンティティなのかを判断します。この違いはAIシステムが正確に内容を理解し、引用するために極めて重要であり、AmICited.comはChatGPTやPerplexity、Google AI OverviewsなどのAIシステムがブランドや組織についての回答を生成する際に、どのようにエンティティ曖昧性解消を行っているかを監視しています。
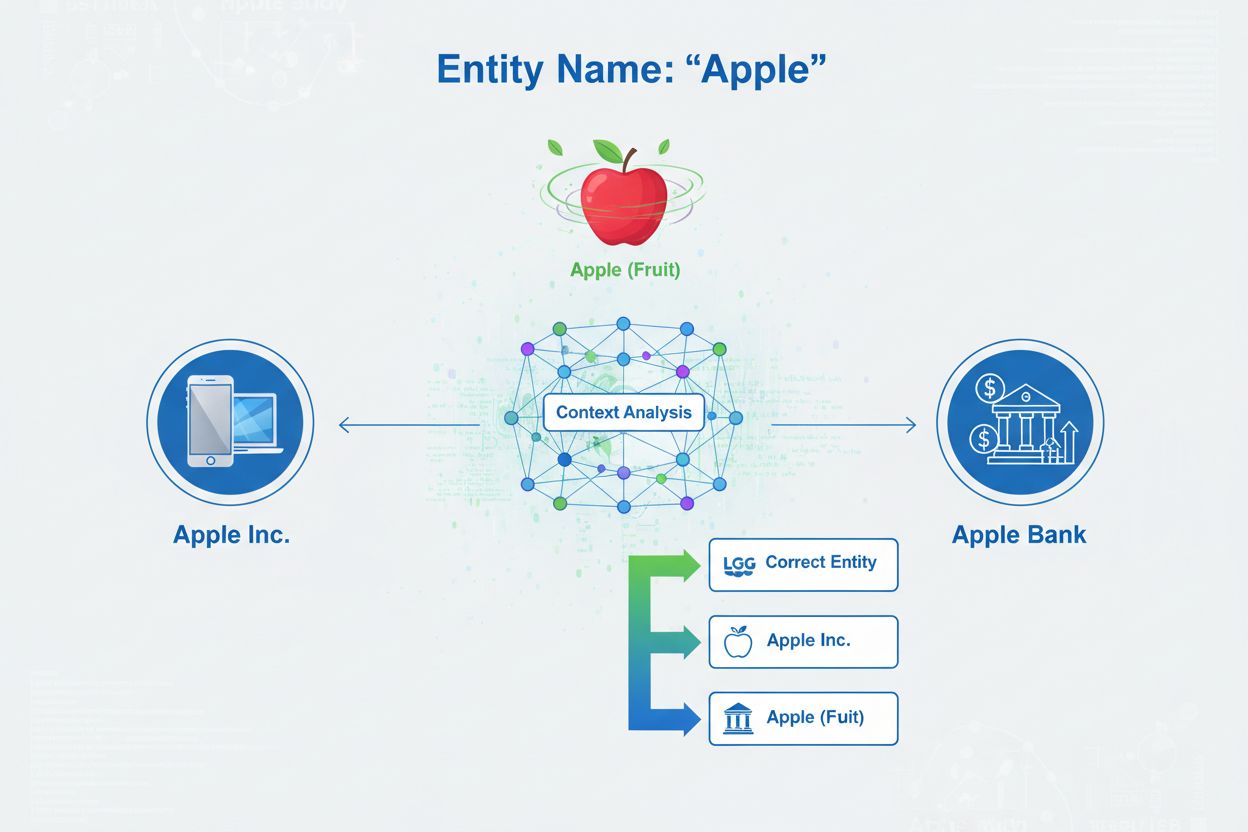
エンティティ曖昧性解消が解決する根本的な問題は曖昧さです。多くのエンティティ名が複数の実世界の対象を指すことができるという現実です。この曖昧さは、AIシステムが正確な内容を理解し生成しようとするときに大きな課題となります。Stanford AI Index 2024によれば、ブランドエンティティが関与するLLMの出力の18%以上に幻覚またはエンティティの誤帰属が含まれているとされ、AIシステムがしばしばエンティティを混同したり、誤った情報を生成したりしていることが分かります。この誤りはブランド表現や内容の正確性に重大な影響を及ぼします。AIシステムがエンティティを誤って特定すると、誤った情報を提供したり、発言を誤った組織に帰属させたり、正しい情報源を引用できなかったりすることがあります。
| エンティティ名 | 考えられる意味 | AIの混乱率 |
|---|---|---|
| Apple | テック企業 / 果物 / 銀行 | 高 |
| Delta | 航空会社 / 蛇口メーカー / ギリシャ文字 | 高 |
| Jaguar | 自動車メーカー / 動物種 | 中 |
| Amazon | EC企業 / 熱帯雨林 / 川 | 高 |
| Orange | 色 / 果物 / 通信会社 | 中 |
エンティティ曖昧性解消が不十分だと、単なる事実誤認にとどまらず、コンテンツ制作者やブランドにとっては可視性の損失、誤った帰属、ブランド評判の損傷といった深刻な問題を引き起こします。たとえば、ユーザーがAIシステムに「Delta」について尋ねたとき、Delta Airlinesを求めているのに、システムがDelta Faucet Companyと混同してしまえば、無関係な情報が提示されてしまいます。これこそが、AmICited.comがAIシステムによるエンティティ曖昧性解消をモニタリングし、ブランドが各種AI生成コンテンツで正しく特定・引用されているかを把握できるようにしている理由です。
エンティティ曖昧性解消は、複数のNLP技術を組み合わせて曖昧さを解消し、正しくエンティティを特定する体系的なプロセスで機能します。この仕組みを理解することで、一部のAIシステムが他よりも高い引用精度を維持できる理由が分かります。
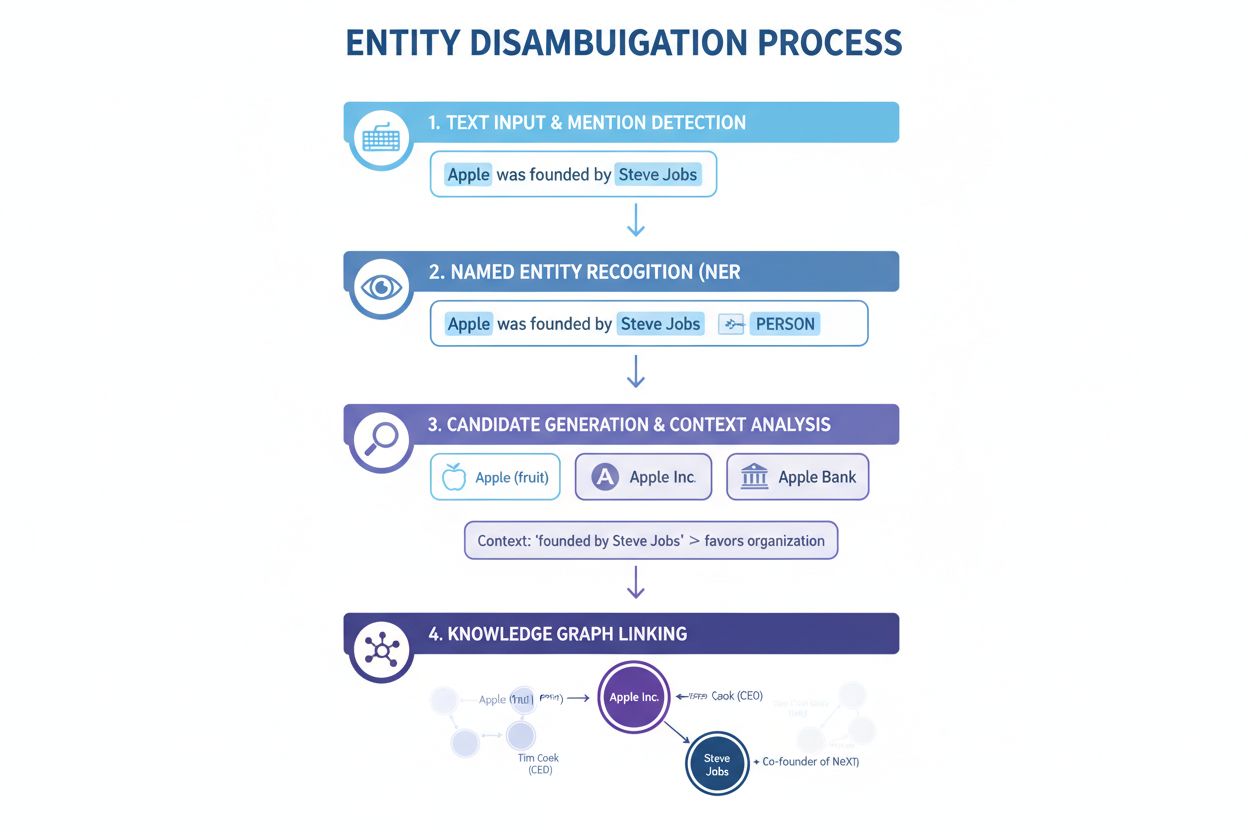
名前付きエンティティ認識(NER):最初のステップは、テキスト内の名前付きエンティティを識別・分類することです。NERシステムはテキストデータをスキャンしてエンティティの言及を見つけ、それを「人物」「組織」「場所」「製品」「日付」などの事前定義カテゴリに割り当てます。たとえば「Apple was the brain-child of Steve Jobs.」という文では、「Apple」と「Steve Jobs」の両方をエンティティとして検出し、それぞれ組織・人物と分類します。この基礎的なステップがなければ曖昧性解消は始まりません。
エンティティの詳細分類:エンティティが識別された後、その種類や文脈をさらに詳細に分析します。たとえば「Apple」がテクノロジーの話題で出現していればApple Inc.、食べ物の話題なら果物、金融の文脈ならApple Bankの可能性が高まります。こうした文脈分析で候補を絞り込みます。
曖昧性解消:ここが核心となるステップで、システムは参照されている特定のエンティティを決定します。識別名に一致する複数の候補エンティティを評価し、周辺文脈、エンティティ説明、意味的関係、ナレッジグラフ情報などのシグナルを用いて最も正しいエンティティを選択します。「Apple was the brain-child of Steve Jobs.」の場合、Steve Jobsと強く関連するのがApple Inc.であるため、それが正しい曖昧性解消となります。
ナレッジベースリンク:最後のステップは、曖昧性解消されたエンティティをWikidataやWikipedia、独自データベースなどの外部ナレッジベースまたはナレッジグラフの固有識別子にリンクさせることです。これにより、エンティティの同一性が確定し、テキストに意味情報が付加され、さらなる処理や分析が可能になります。エンティティには一意のURI(Uniform Resource Identifier)が割り当てられます。
エンティティ曖昧性解消の手法は時代とともに進化し、それぞれに長所と限界があります。これらの手法を理解することで、現代AIシステムの曖昧性解消精度の違いが説明できます。
ルールベース手法:事前定義された言語規則やヒューリスティックパターンを用いて曖昧性解消を行います。たとえば「『iPhone』や『MacBook』が近くにあればApple Inc.」「『Delta』が『airline』『flight』と共起すればDelta Airlines」など。ルールベースは解釈しやすく大規模な学習データを必要としませんが、新しい文脈や意味の変化には手動でルール追加が必要で、適応性に乏しいです。
機械学習手法:アノテーション済み学習データから文脈的特徴を抽出し、正しいエンティティを予測します。サポートベクターマシンやランダムフォレストなどのアルゴリズムで分類を行い、ルールベースより柔軟ですが、大量のラベル付きデータが必要で、未学習のエンティティには弱い傾向があります。
ディープラーニング・トランスフォーマーモデル:近年はBERTやRoBERTa、GENRE、BLINKなどのトランスフォーマーベースのモデルが主流です。これらは深い文脈理解と意味的関係を捉え、ベンチマークで優れた性能を発揮します。たとえばOntotextのCEEL(Common English Entity Linking)はトランスフォーマーをCPU最適化し、高い認識精度(96%)、リンク精度(76%)を達成しています。
ナレッジグラフ統合:近年は機械学習とナレッジグラフ(エンティティとその関係を表す構造化データベース)の連携が進み、豊富な文脈情報や属性・関係情報を参照することで曖昧性解消をより正確に行えるようになっています。
エンティティ曖昧性解消は多くの産業・用途で不可欠となっており、正確なエンティティ識別と引用による恩恵を受けています。
検索エンジン:GoogleやBingなどの検索エンジンは、ユーザーが「Apple」と検索したとき、Apple Inc.か果物か他のエンティティかを文脈やユーザー履歴、ナレッジグラフを使って曖昧性解消し、最も関連性の高い検索結果を返します。このため多くの場合「Apple」でテック企業が最初に表示されます。
メディア・出版:ニュースサイトやコンテンツプラットフォームは、記事内の「Apple」などの言及を自動的にApple Inc.のナレッジベースエントリにリンクし、読者に追加情報や関連記事を提供します。これによりユーザーの理解やエンゲージメントが向上します。
ヘルスケア:医療機関では、患者記録や論文内で薬剤・疾患・手技などのエンティティを正確に識別するために曖昧性解消を利用します。特に薬剤名は、一般名・ブランド名・用量バリエーションなど曖昧さが多いため、正確な曖昧性解消が不可欠です。
金融サービス:投資会社やアナリストは、ニュースや決算報告、市場データなど多様な情報源で企業言及を追跡します。「Apple」の全ての言及をApple Inc.に正しく帰属させることで、正確なリスク評価・ポートフォリオ分析を行います。
Eコマース:オンライン小売では、商品検索時のエンティティ曖昧性解消により、「Apple laptop」を探した際にApple Inc.の製品にマッチングさせ、顧客の利便性を高めます。
AmICited.comは、ChatGPT・Perplexity・Google AI Overviewsによるブランド言及の曖昧性解消状況をモニタリングし、ブランドの可視性やAI生成コンテンツでの正確な表現を支援しています。
ナレッジグラフは、現代のエンティティ曖昧性解消システムの根幹となっており、エンティティとその関係の構造化表現を提供します。ナレッジグラフはエンティティ(ノード)と関係(エッジ)から成り、各エンティティノードには名前・説明・タイプ・属性などのメタデータが含まれます。例えば「Apple Inc.」なら「1976年設立」「本社:クパチーノ」「業界:テクノロジー」「創業者:Steve Jobs」「製品:iPhone」などです。
曖昧なエンティティ言及に遭遇した場合、システムはナレッジグラフをクエリし、候補エンティティに関する豊富な文脈情報を取得します。たとえば周辺テキストに「Steve Jobs」があれば、ナレッジグラフからSteve JobsとApple Inc.の強い関連を確認し、正しいエンティティを推定できます。WikidataやWikipediaなどの公開ナレッジグラフは多くのAIシステムで利用されており、GoogleやMicrosoftなどの独自ナレッジグラフは業界特化の情報を提供します。機械学習モデルとナレッジグラフの連携により、曖昧性解消精度は大きく向上しています。
大きく進歩したとはいえ、エンティティ曖昧性解消システムには依然としていくつかの課題があります。
多義性と曖昧さ:多くのエンティティ名は複数の正当な意味を持ち、文脈だけでは特定できないこともあります。「Bank」は金融機関か川の岸か、「Crane」は鳥か建設機械か、など。人間でも追加文脈なしでは判別困難な場合があり、AIは文脈不足時に柔軟に対応する必要があります。
新規・新興エンティティ:ナレッジベースや学習データが更新されないと、新しい企業や製品が登場した際に情報が不足し、既存のエンティティと誤って結びつく危険があります。ゼロショットエンティティリンク(学習時に存在しなかったエンティティの曖昧性解消)は依然として難題です。
名前のバリエーション・誤記:「United States」「USA」「U.S.」「America」など同じエンティティに複数の呼称があり、誤記やタイプミスも頻発します。特にユーザー生成コンテンツでは変化が多く、システムはこれらを正規エンティティにマッピングする必要があります。
不完全・古いデータ:ナレッジベースが不完全または情報が古い場合、会社の本社移転や経営陣変更、M&Aなどが反映されず、誤った情報で曖昧性解消してしまう恐れがあります。
スケーラビリティ・パフォーマンス:大量テキストの高精度曖昧性解消には計算資源を要し、リアルタイム処理にはコストと精度のバランスが求められます。
ブランドやコンテンツ制作者にとって、エンティティ曖昧性解消を理解することはAI生成コンテンツでの正確な表現維持に不可欠です。AIが情報発見や消費に与える影響が拡大する中、ブランドは積極的に正しい曖昧性解消・引用がなされるよう対策を講じる必要があります。
事前曖昧性解消戦略:ブランドはAIが自社エンティティを正しく曖昧性解消できるよう、明確で独自性のあるデジタルシグナルを発信しましょう。特にSchema.orgマークアップやJSON-LD形式の構造化データを公式サイトに実装することで、名前・説明・ロゴ・本社所在地などブランドの特徴をAIに明示できます。
ナレッジグラフ最適化:WikidataやWikipediaといった主要ナレッジグラフに正確かつ充実した情報を掲載・更新しましょう。ブランドエンティティと関連エンティティの関係構築も重要です。
文脈的コンテンツ戦略:自社の業界・製品・創業者・独自の価値提案などを明確に記述したコンテンツを作成し、同名他社との違いを明確にしましょう。これがAIの学習データや文脈となります。
引用モニタリング:AmICited.comなどのツールでChatGPTやPerplexity、Google AI Overviews等におけるブランドの曖昧性解消・引用状況をトラッキングし、誤認識を発見したら迅速に対策を取りましょう。
ジェネレーティブエンジン最適化(GEO):エンティティ曖昧性解消はAI可視性の要であり、ブランドエンティティの定義・文書化・差別化を徹底しましょう。GEOは従来のSEOだけでなく、AIシステムでの理解・表現の最適化も含みます。
AI技術の進化と課題の変化によって、エンティティ曖昧性解消も進化を続けています。今後の主なトレンドは以下の通りです。
多言語エンティティ曖昧性解消:AIのグローバル化に伴い、多言語間でのエンティティ曖昧性解消が重要になります。人名や地名は言語ごとに異なる綴りや呼称があり、各言語環境で正しく特定する多言語モデルの開発が進んでいます。
大規模言語モデルでのリアルタイム曖昧性解消:GPT-4やClaudeのような最新LLMは、テキスト生成時にリアルタイムでエンティティ曖昧性解消を行う能力を高めています。トレーニングデータに頼らず、推論時にナレッジグラフや外部DBを参照して正確な曖昧性解消・引用を実現します。
ゼロショット学習の向上:今後のシステムは、未学習エンティティに対してもより高精度で曖昧性解消できるよう、少数ショット・ゼロショット学習技術が進化していきます。頻繁な再学習に頼らず新興エンティティに柔軟に対応できます。
検索拡張生成(RAG)との統合:言語モデルと情報検索を組み合わせたRAGシステムが普及しつつあり、テキスト生成時にナレッジベースから関連エンティティ情報を取得・活用することで曖昧性解消と引用精度が向上します。
標準化と相互運用性:エンティティ曖昧性解消の重要性が高まるにつれ、エンティティ表現や曖昧性解消の業界標準が確立され、異なるシステムやナレッジベース間の相互運用性が向上する見込みです。
エンティティ曖昧性解消は、かつてはNLP分野のニッチなタスクでしたが、AIシステムが情報を正確に理解・表現するための不可欠な機能へと進化しました。AIによる情報発見・消費が拡大する現代では、正確なエンティティ曖昧性解消の重要性はますます高まります。ブランドやコンテンツ制作者、組織にとって、エンティティ曖昧性解消への理解と最適化は、AI時代における可視性と正確な表現維持のために不可欠です。
名前付きエンティティ認識は、テキスト内にエンティティが存在することを認識し、人、組織、場所などのカテゴリに分類します。一方、エンティティ曖昧性解消は、複数のエンティティが同じ名前を共有している場合に、どの特定のエンティティが参照されているのかを特定します。たとえば、NERは「Apple」を組織として認識しますが、エンティティ曖昧性解消はそれがApple Inc.なのか、Apple Bankなのか、または他のエンティティなのかを判断します。
エンティティ曖昧性解消は、AIシステムが議論されているエンティティを正確に把握し、正しく引用できるようにします。Stanford AI Index 2024によると、ブランドエンティティが関与するLLMの出力の18%以上で幻覚や誤った帰属が含まれています。正確なエンティティ曖昧性解消によって、AIがエンティティを混同することを防ぎ、ブランドの評判や引用の正確性を維持する上で重要です。
ナレッジグラフはエンティティとその関係に関する構造化情報を提供します。AIシステムが曖昧なエンティティ言及に遭遇した場合、ナレッジグラフをクエリして、候補エンティティに関するメタデータや説明、関係情報にアクセスできます。この文脈情報が、より適切な曖昧性解消の判断と正しいエンティティの選択に役立ちます。
はい、ゼロショットエンティティリンク手法を用いることで対応可能です。最新のシステムでは、新しいエンティティが現れた場合に、それを既存のエンティティと誤って結びつけるのではなく、適切に処理できるようになっています。ただし、この課題は依然として難しく、新しいエンティティに明確な文脈的シグナルがある場合の方がシステムの性能は高くなります。
正確なエンティティ曖昧性解消によって、ブランドがAI生成回答で正しく特定・引用されるようになります。AIシステムがブランドを正しく曖昧性解消すると、ユーザーは組織に関する正確な情報を得られ、ブランドの認知度と評価が向上します。曖昧性解消が不十分だと、ブランドが競合や他のエンティティと混同され、認知度が下がり評判が損なわれる可能性があります。
主な課題は、多義性(同じ名前に複数の意味があること)、学習データに存在しない新しいエンティティ、名前のバリエーションや誤記、ナレッジベースの情報不足や古さ、スケーラビリティの問題などです。また、一部のエンティティ名は本質的に曖昧であり、コンテキストだけでは正しいエンティティを特定できない場合もあります。
ブランドはSchema.orgマークアップなどの構造化データを実装し、WikipediaやWikidataエントリの正確な維持、ブランドを明確に区別する文脈的コンテンツの作成、AmICitedのようなツールでAIシステムによるブランドの曖昧性解消状況のモニタリングを行うことができます。これらの戦略が、AIに正しくブランドを特定・引用させるのに役立ちます。
文脈はエンティティ曖昧性解消において極めて重要です。周辺テキストや関連エンティティ、意味的な関係が、AIシステムがどのエンティティを参照しているかを判断するためのシグナルとなります。たとえば、「Apple」が「Steve Jobs」や「テクノロジー」と近くに出現する場合、システムはこの文脈を利用して、それが果物ではなくApple Inc.であると正しく曖昧性解消できます。
AIプラットフォーム全体でのエンティティ曖昧性解消の正確性をトラッキングし、ブランドがAI生成回答で正しく特定・引用されているかを確認しましょう。
AIシステムがテキスト内のエンティティ間の関係をどのように特定・抽出・理解するかを学びましょう。エンティティ関係抽出技術、NLP手法、実際の応用例を紹介します。...

AIシステムがテキスト内のエンティティをどのように認識・処理するかを探ります。NERモデル、トランスフォーマーアーキテクチャ、エンティティ理解の実際の応用例について学びましょう。...

エンティティ最適化がブランドをLLMに認識させる仕組みを解説。ナレッジグラフ最適化、スキーママークアップ、AIでの可視性向上のためのエンティティ戦略をマスターしましょう。...
クッキーの同意
閲覧体験を向上させ、トラフィックを分析するためにクッキーを使用します。 See our privacy policy.