
LLMメタアンサーの作成:AIが引用できる独立したインサイト
AIシステムに引用されるLLMメタアンサーの作成方法を学びましょう。構造化テクニックや回答密度の戦略、引用されやすいコンテンツフォーマットを発見し、AI検索結果での可視性を高めましょう。...
1 分で読める

ChatGPT、Google AI Overviews、Perplexityなどのプラットフォームで、AI生成回答の可視性向上を目的として、言語モデルがどのように関連クエリを解釈し応答するかに直接対応するコンテンツ。LLMメタアンサーは、複数の情報源から情報を統合し、ユーザーの意図に応じた一貫性のある会話形式の回答を生成します。
ChatGPT、Google AI Overviews、Perplexityなどのプラットフォームで、AI生成回答の可視性向上を目的として、言語モデルがどのように関連クエリを解釈し応答するかに直接対応するコンテンツ。LLMメタアンサーは、複数の情報源から情報を統合し、ユーザーの意図に応じた一貫性のある会話形式の回答を生成します。
LLMメタアンサーは、ChatGPT、Claude、GoogleのAI Overviewsなどのプラットフォームでユーザーがクエリを投げた際に、大規模言語モデルが生成する統合的なAI回答を指します。これらの回答は従来の検索結果とは根本的に異なり、複数の情報源から情報を統合し、ユーザーの意図に直接対応する一貫した会話形式の応答になります。単にリンクのリストを提示するのではなく、LLMは取得したコンテンツを分析し、トレーニングデータやRAG(検索拡張生成)システムから得た事実・視点・洞察を盛り込んだ独自のテキストを生成します。LLMがどのようにこうしたメタアンサーを構築するかを理解することは、自分のコンテンツがAI生成回答で引用・参照されることを望むコンテンツ制作者にとって不可欠です。これらAI回答での可視性は、従来の検索結果でのランキングと同じくらい重要になっており、LLM最適化(LLMO)は現代のコンテンツ戦略における重要な要素となっています。
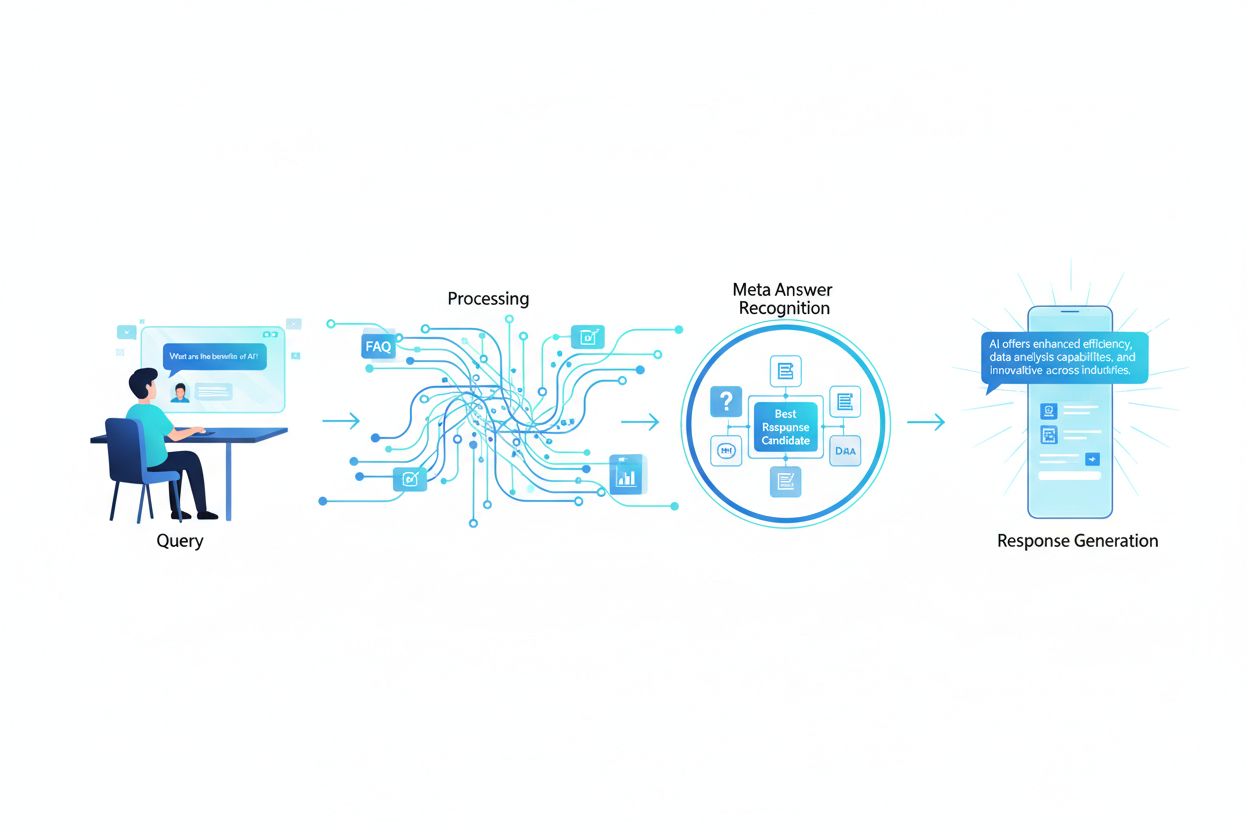
ユーザーがLLMにクエリを入力すると、システムは従来の検索エンジンのように単純なキーワード一致を行うわけではありません。LLMは意味的分析を実施し、質問の根本的な意図、文脈、ニュアンスを理解します。モデルはクエリを概念的な構成要素に分解し、関連トピックやエンティティを特定し、定義、比較、手順解説、分析的視点など、どのタイプの回答が最適かを判断します。LLMはRAGシステムを使い、関連性・権威性・網羅性を重視してナレッジベースから該当コンテンツを取得します。取得プロセスでは単なるキーワード一致だけでなく、意味的な類似性やトピックの関連性、コンテンツがクエリの具体的な側面をどれだけ的確に扱っているかも考慮されます。つまり、あなたのコンテンツは単なるキーワードだけでなく、ユーザーが実際に尋ねている意味的な概念や関連トピックでも発見可能である必要があります。
| クエリ解釈要素 | 従来の検索 | LLMメタアンサー |
|---|---|---|
| 一致方法 | キーワード一致 | 意味理解 |
| 結果形式 | リンク一覧 | 統合ストーリー形式 |
| 情報源選択 | 関連性ランキング | 関連性+網羅性+権威性 |
| 文脈考慮 | 限定的 | 幅広い意味的文脈 |
| 回答合成 | 複数情報源を読む必要あり | AIが複数情報源を統合 |
| 引用要件 | 任意 | 多くの場合含まれる |
あなたのコンテンツがLLMメタアンサーで選ばれ引用されるためには、これらのシステムが情報を評価・統合する方法に合致した複数の重要な特性が必要です。第一に、明確な専門性・権威性(E-E-A-T:経験・専門性・権威性・信頼性)を示し、LLMが信頼できる情報源として認識できること。第二に、一般的な情報を超えた独自の洞察やデータ、視点など「情報価値の上乗せ」があること。第三に、明確な階層性と論理的な構成で、LLMが情報を簡単に解析・抽出できる構造であること。第四に、意味的な豊かさが不可欠で、単一キーワードに偏らず、関連概念を幅広く掘り下げることでトピックの包括的権威性を築くこと。第五に、最新性も重要で、LLMは最新情報を優先する傾向があるため、定期的な更新が求められます。最後に、引用・データ・外部参照など裏付けとなる証拠を盛り込むことで、LLMの信頼を得やすくなります。
LLMで引用されやすくなる主な特長:
コンテンツの構造は、LLMがメタアンサーとして選ぶかどうかに大きく影響します。これらのシステムは、整理された情報を抽出・統合するよう最適化されているからです。LLMは、明確な見出し階層(H1、H2、H3)で情報アーキテクチャが論理的に整理されているコンテンツを強く好みます。これにより、モデルが概念間の関係を理解し、関連セクションを効率的に抽出できます。箇条書きや番号リストは、情報をスキャンしやすい単位で提示できるため、LLMが回答に組み込みやすくなります。表は、構造化データをAIが解析・参照しやすい形式で示せるため、LLM可視性に特に有効です。3~5文程度の短い段落は、長文の塊よりもLLMが特定情報を見つけやすく、引用されやすくなります。さらに、スキーママークアップ(FAQ、Article、HowTo)を使うと、コンテンツの構造や意図をLLMに明示でき、引用可能性が大きく向上します。
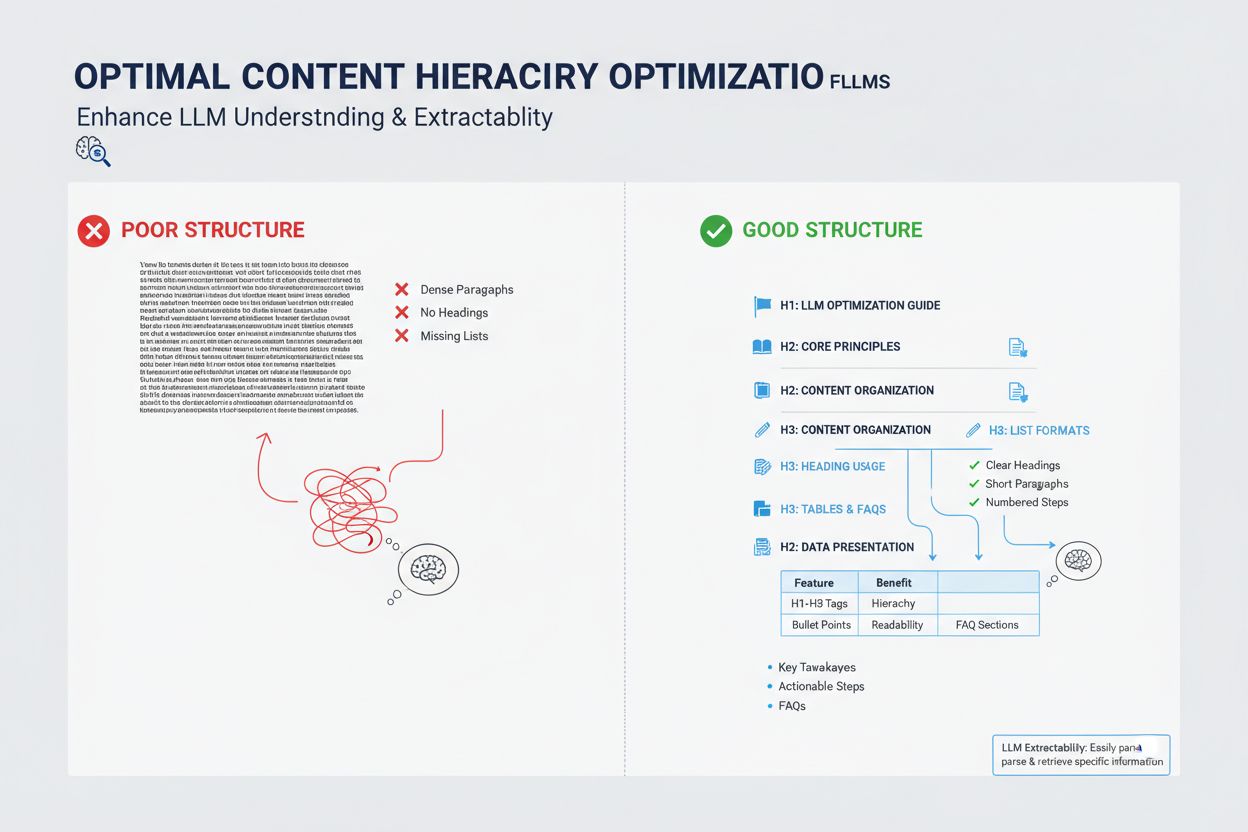
LLMメタアンサーと強調スニペットは一見似ていますが、コンテンツ可視性の仕組みも最適化戦略も本質的に異なります。強調スニペットは従来の検索アルゴリズムが既存Webコンテンツから抜粋し、検索結果ページの特定位置に40~60語程度のテキストを表示します。一方、LLMメタアンサーは複数の情報源から情報を統合し、より長く網羅的なオリジナル回答をAIが生成します。強調スニペットは簡潔に直接答えるコンテンツが評価されますが、LLMメタアンサーは深いトピック網羅と権威性が重視されます。また、引用の仕組みも異なり、強調スニペットは情報元リンクと原文抜粋を表示しますが、LLMメタアンサーはパラフレーズや統合表現が多く、通常は出典表示が含まれます。さらに、強調スニペットは主に検索向け、LLMメタアンサーはAIプラットフォーム最適化で、検索結果に表示されないことも多いです。
| 項目 | 強調スニペット | LLMメタアンサー |
|---|---|---|
| 生成方法 | 既存テキストを抽出 | 複数情報源からAI統合生成 |
| 表示形式 | 検索結果ページ内 | AIプラットフォームの回答欄 |
| コンテンツ長 | 通常40~60語 | 200~500語以上 |
| 引用スタイル | 出典リンク+抜粋 | パラフレーズ+出典表示 |
| 最適化重視点 | 簡潔な直接回答 | 網羅的な権威性 |
| プラットフォーム | Google検索 | ChatGPT、Claude、Google AI Overviews |
| 可視性指標 | 検索インプレッション | AI回答での引用数 |
意味的豊かさ(semantic richness)は、LLM最適化で最も重要でありながら見落とされがちな要素の一つです。LLMはターゲットキーワードだけでなく、概念間の意味的つながりや主題の文脈、関連アイデアの掘り下げ度合いも分析します。意味的豊かなコンテンツは多様な用語を用い、トピックの多角的な側面を探り、関連概念間の関係を築いているため、表面的なキーワード最適化ではなく本物の権威性をLLMに伝えられます。例えば「コンテンツマーケティング」というテーマなら、オーディエンスのセグメンテーション、ペルソナ設定、コンテンツ配信、分析、ROIといった関連分野にも自然に言及することで、包括的な知識グラフの中にコンテンツを位置付けられます。こうした意味的深みは、LLMに対して実際の専門性と、多面的でニュアンスに富んだ回答力をアピールできます。
LLMは従来の検索エンジンとは異なり、単なるリンク人気ではなく、真の専門性や信頼性を示すシグナルを重視します。著者の認定や実務経験は特に重要で、分野の専門家や実践者、権威ある組織のコンテンツが優先されやすくなります。外部の権威ある情報源への引用や参照も、広範な知識に基づき裏付けられていることを示し、LLMからの信頼性を高めます。複数の関連トピックで一貫したコンテンツを発信し続けることで、トピック権威も強化されます。第三者による言及・引用・参照はLLMメタアンサーでの可視性を大幅に向上させます。独自の調査や専有データ、ユニークな手法を公開することも強力な権威性シグナルとなります。さらに、定期的な公開履歴や更新によって、常に最新情報を扱う信頼できる情報源であることを示せます。
LLM選定に影響する主な権威性シグナル:
コンテンツの最新性は、特に情報の変化が激しいトピックや直近の出来事に関する場合、LLM可視性を左右する重要な要素となっています。LLMは知識カットオフのあるデータで訓練されていますが、RAGシステムによりウェブ上の最新情報も取得するため、公開日や更新頻度がメタアンサーに選ばれるかを直接左右します。普遍的なトピックでも定期的な小規模更新で公開日を刷新することが、LLMに「管理されている信頼情報源」として認識される鍵となります。業界動向や技術動向、時事ニュースのようなタイムリーなテーマでは、古い情報はLLMに積極的に除外され、より新しい情報源が優先されます。ベストプラクティスは、主要コンテンツを四半期または半年ごとに見直し、統計や事例の更新、最新動向の追加を行うことです。こうしたメンテナンスはLLM可視性だけでなく、AIと人間の両方の読者に「現役で信頼できる情報源」であることをアピールできます。
LLMメタアンサーでの成功を測るには、従来のSEOとは異なる指標やツールが必要です。なぜなら、これらの回答は従来の検索結果エコシステムの外に存在するからです。AmICited.comなどの専用ツールを使えば、AI生成回答で自社コンテンツがどこで何回引用されているかを可視化できます。主な指標は、引用頻度(LLM回答で何度登場したか)、引用文脈(どのトピック・クエリで引用されたか)、情報源多様性(複数のLLMプラットフォームで引用されているか)、回答内での掲載位置(回答内でどれだけ目立つか)などです。どのページやセクションがよく引用されるかを追跡することで、LLMが価値あり信頼できると判断した情報タイプが分かります。時間経過による引用パターンの変化を監視すれば、どの最適化施策が効果的か、どのトピックに追加開発が必要かを把握できます。さらに、どのクエリで引用が発生するかを分析することで、LLMがユーザー意図をどう解釈し、どの意味的バリエーションが有効かを知る手がかりにもなります。
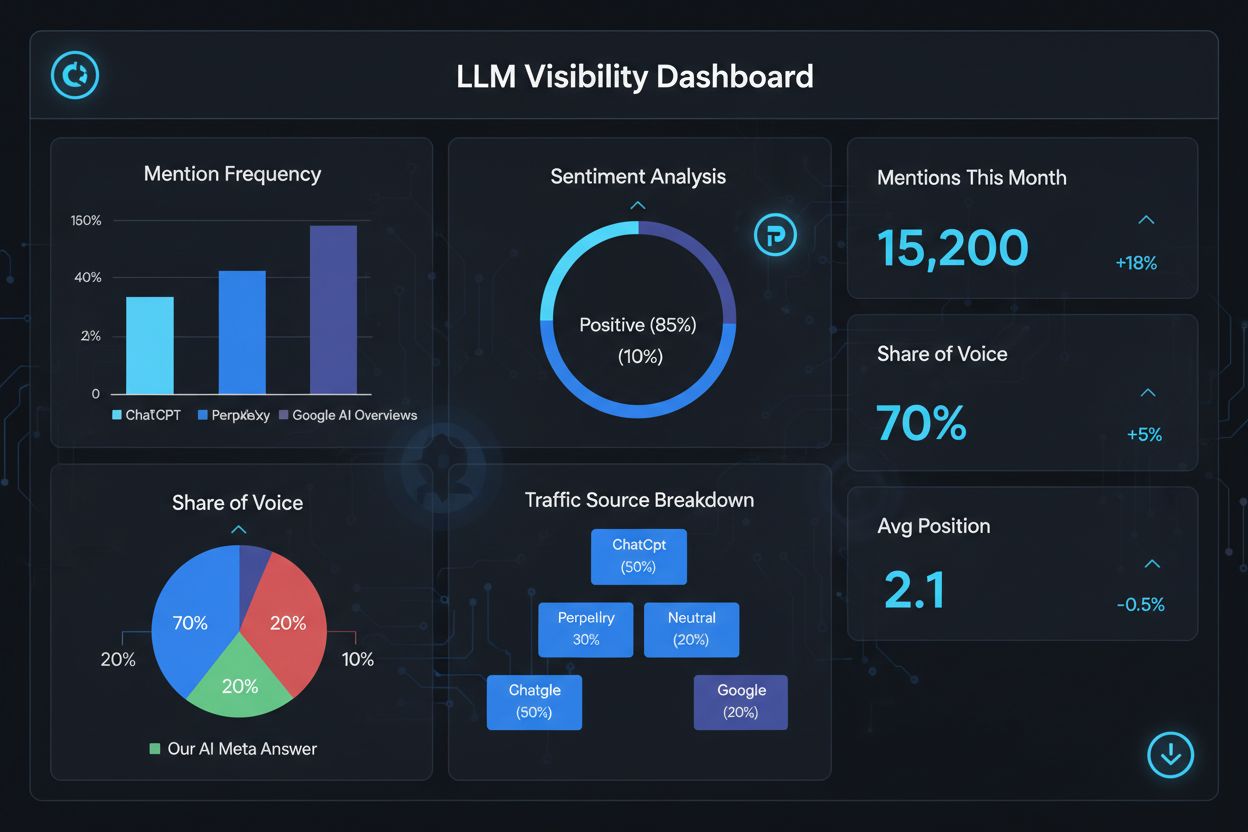
LLMメタアンサー成果を測る主な指標:
LLMメタアンサー最適化には、技術的実装・コンテンツ品質・継続的な測定を組み合わせた戦略的アプローチが不可欠です。まずは包括的なトピックリサーチを行い、あなたの専門性が汎用情報よりも優先される独自価値やコンテンツギャップを特定しましょう。H2・H3見出しを用いて明確な階層をつけ、LLMが解析・抽出しやすい情報アーキテクチャを構築します。FAQ、Article、HowTo等のスキーママークアップを実装し、構造や意図をLLMに明示することで発見性が大幅に向上します。トピックを多角的に掘り下げ、意味的豊かさを備えた総合的で権威あるコンテンツを作成しましょう。独自調査やデータ、洞察を盛り込み、競合との差別化と情報価値の付与を図ります。四半期ごとに主要コンテンツを更新するスケジュールを組み、最新性と継続的な権威性をアピールしてください。複数の関連コンテンツを連携してトピック権威を築くことも有効です。ユーザーが実際に尋ねる質問に明確な言葉で直接答えることで、LLMが抽出・統合しやすくなります。最後に、AmICited.comなどの専門ツールでLLM引用状況をモニタリングし、成果を分析しつつ、データに基づき戦略を継続的に洗練しましょう。
LLMメタアンサーは、言語モデルがコンテンツをどのように解釈し引用するかに焦点を当てるのに対し、従来のSEOは検索結果でのランキングに注力します。LLMはドメインオーソリティよりも関連性や明確さを優先するため、構造化され答えが先に示されているコンテンツがバックリンク以上に重要です。Googleの上位に表示されていなくても、あなたのコンテンツがLLMの回答で引用されることがあります。
明確な見出しで内容を構成し、冒頭で直接回答を提示し、スキーママークアップ(FAQ、Article)を活用、引用や統計を含め、トピックの権威性を維持、AIボットがクロール可能なサイトにしてください。狭いキーワードではなく、意味的な豊かさ・情報の価値・包括的なトピック網羅に注力しましょう。
LLMは整理されたコンテンツからスニペットを抽出しやすくなります。明確な見出し、リスト、表、短い段落は、モデルが関連情報を特定し引用するのに役立ちます。調査によると、LLMに引用されるページは、一般的なWebページよりも構造化要素が大幅に多く、構造が重要なランキング要因となっています。
はい。従来のSEOと異なり、LLMはクエリの関連性やコンテンツ品質をドメインオーソリティより優先します。しっかりと構造化され、ニッチなトピックで高い関連性を持つページは、Googleで上位表示されていなくてもLLMに引用されることがあり、専門性と明確さがサイトオーソリティ以上に重要です。
特に時事性のあるトピックは定期的に更新しましょう。最終更新日を明記するタイムスタンプを追加してください。普遍的なテーマの場合は四半期ごとに見直すのがおすすめです。新しい内容はLLMに正確性を示し、引用されやすくなり、継続的な権威性も示せます。
AmICited.comはChatGPT、Perplexity、Google AI OverviewsでのAI言及の監視を専門としています。他にもSemrushのAI SEO Toolkit、Ahrefs Brand Radar、Peec AIなどがあり、言及頻度やシェア・オブ・ボイス、感情分析など最適化成果を測定できます。
スキーママークアップ(FAQ、Article、HowTo)は、LLMがコンテンツをより正確に理解・抽出できるようにする機械可読な構造を提供します。コンテンツの種類や意図を示すことで、関連クエリで選ばれる可能性が高まり、全体的な発見性も向上します。
権威性の高いサイト(ニュース、Wikipedia、業界メディア)での外部言及は信頼性を高め、LLMがあなたのコンテンツを引用する可能性を高めます。複数の独立した情報源がブランドやデータを言及することで、LLMが認識し高頻度で引用する権威パターンが形成されます。
AIシステムに引用されるLLMメタアンサーの作成方法を学びましょう。構造化テクニックや回答密度の戦略、引用されやすいコンテンツフォーマットを発見し、AI検索結果での可視性を高めましょう。...
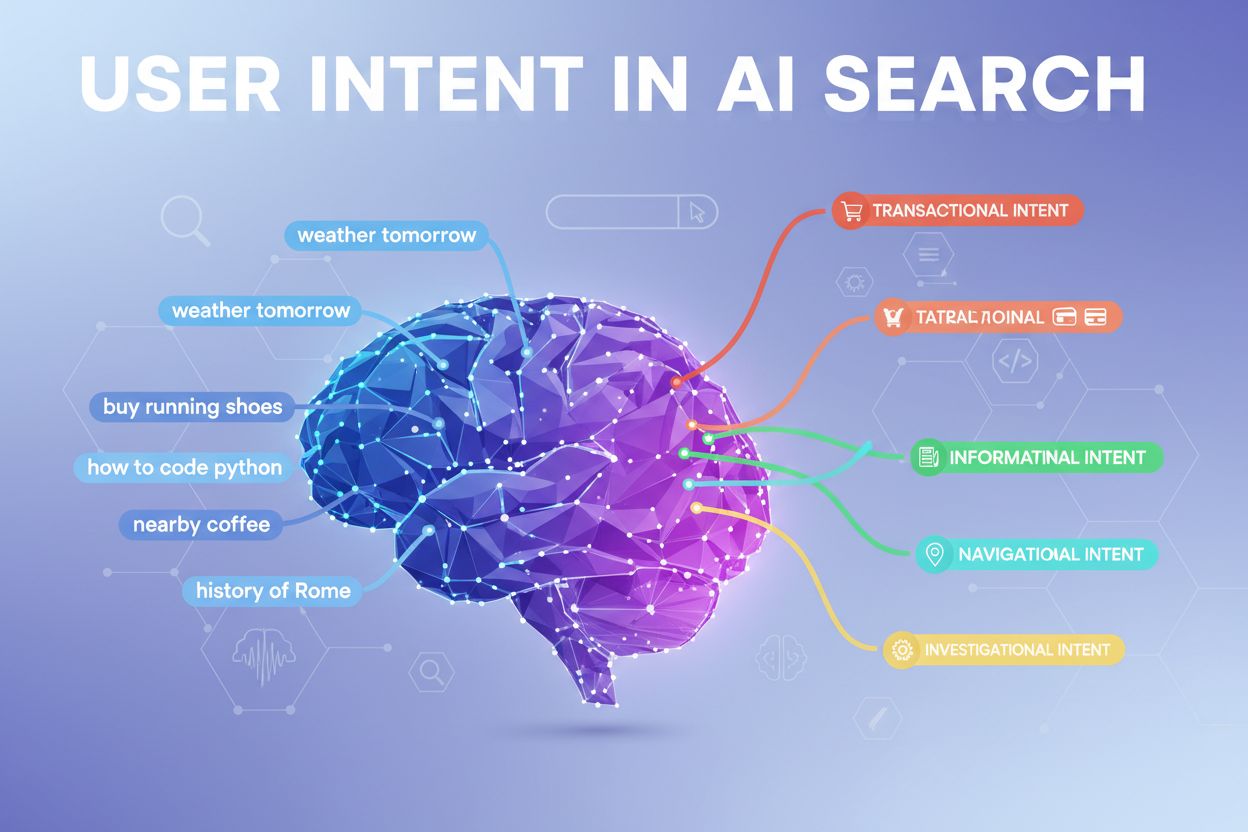
大規模言語モデルがどのようにユーザーインテントをキーワード以上に解釈するかを学びましょう。クエリの拡張、セマンティックな理解、そしてAIシステムがどのコンテンツを回答に引用するかをどのように決定するのかを解説します。...

LLMがトークン化、トランスフォーマーアーキテクチャ、アテンションメカニズム、確率的予測を通じてどのように応答を生成するかを解説。AIによる回答生成の技術的プロセスを学ぼう。...
クッキーの同意
閲覧体験を向上させ、トラフィックを分析するためにクッキーを使用します。 See our privacy policy.