
FAQ拡張
FAQ拡張がAIシステム向けに包括的な質問と回答ペアをどのように開発するか学びましょう。ChatGPT、Perplexity、Google AI OverviewsのためのAI引用改善、プラットフォーム別最適化、コンテンツの新鮮さ向上の戦略を紹介します。...
1 分で読める
クエリ拡張最適化は、関連語句、同義語、文脈的なバリエーションをユーザーの検索クエリに追加することで、AIシステムの検索精度やコンテンツの関連性を高めるプロセスです。これはユーザーのクエリと関連ドキュメント間の語彙のギャップを埋め、GPTやPerplexityのようなAIシステムがより適切なコンテンツを見つけて参照できるようにします。この手法はAI生成回答の網羅性と正確性を向上させるために不可欠です。クエリを賢く拡張することで、AIプラットフォームは関連情報の発見や引用の質を劇的に向上させることができます。
クエリ拡張最適化は、関連語句、同義語、文脈的なバリエーションをユーザーの検索クエリに追加することで、AIシステムの検索精度やコンテンツの関連性を高めるプロセスです。これはユーザーのクエリと関連ドキュメント間の語彙のギャップを埋め、GPTやPerplexityのようなAIシステムがより適切なコンテンツを見つけて参照できるようにします。この手法はAI生成回答の網羅性と正確性を向上させるために不可欠です。クエリを賢く拡張することで、AIプラットフォームは関連情報の発見や引用の質を劇的に向上させることができます。
クエリ拡張最適化とは、検索クエリを再構成し、関連語句や同義語、意味的バリエーションを追加することで、検索パフォーマンスや回答品質を高めるプロセスです。クエリ拡張は根本的に語彙の不一致問題に対処します。これは、ユーザーやAIシステムが同じ概念を異なる用語で表現しがちなため、関連する結果を見逃してしまうという課題です。この手法は、ユーザーが自然に表現する情報ニーズと、実際にコンテンツがインデックス化・保存されている方法とのギャップを埋めるため、AIシステムにとって重要です。クエリを賢く拡張することで、AIプラットフォームは回答の関連性と網羅性を大きく向上させることができます。
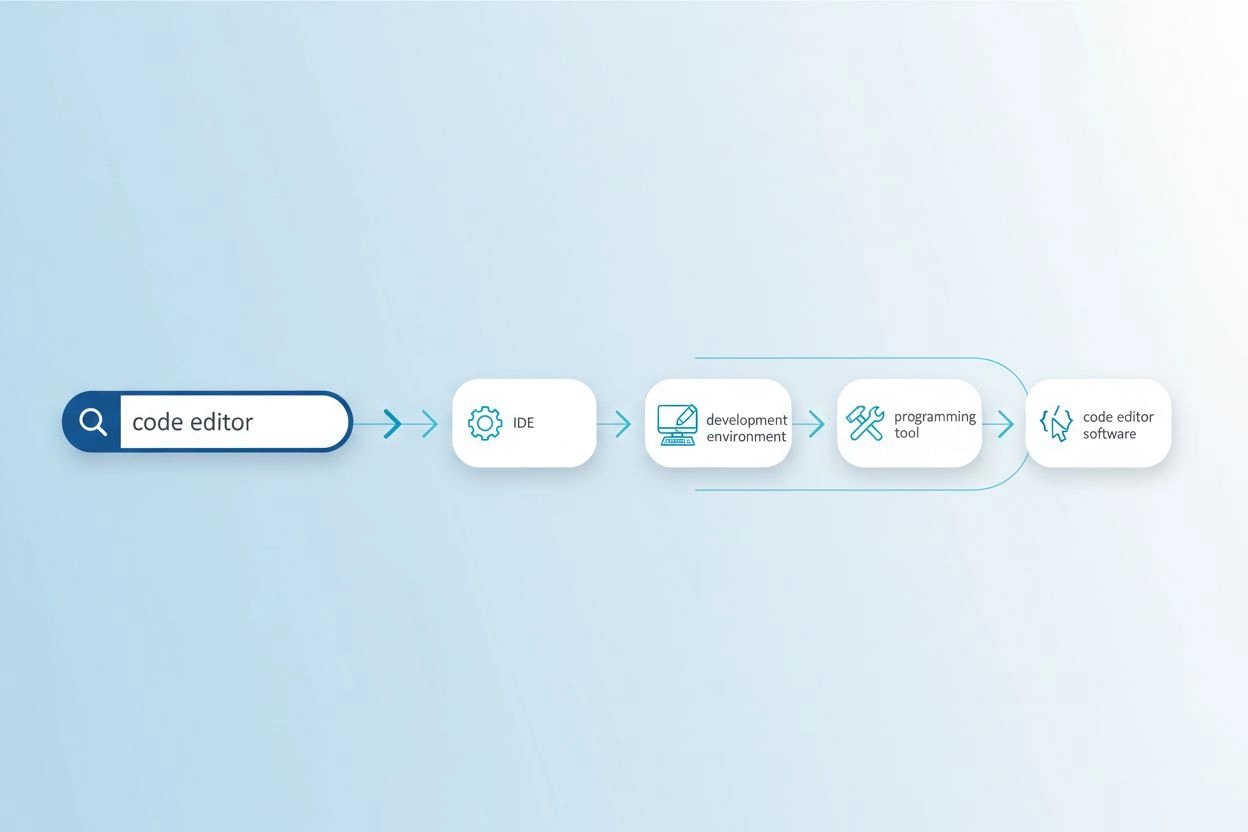
語彙の不一致問題とは、クエリで使われる単語が関連ドキュメントの用語と一致しない場合、検索システムが価値ある情報を見逃してしまう現象です。例えば、「code editor」と検索したユーザーが、「IDE」(統合開発環境)や「text editor」に関する結果を見逃す可能性があります。同様に、「vehicle」と検索しても、「car」「automobile」「motor vehicle」といった明らかに意味が重なるタグの結果を見つけられない場合があります。この問題は、複数の専門用語が同じ概念を指す専門分野でより深刻になり、AI生成回答の質にも影響します。なぜなら、合成のための情報源が制限されるからです。クエリ拡張は、この問題を自動的に関連するクエリバリエーションを生成し、様々な表現で同じ情報が表される可能性を捉えることで解決します。
| 元のクエリ | 拡張クエリ | インパクト |
|---|---|---|
| code editor | IDE, text editor, development environment, source code editor | 3~5倍多くの関連結果を発見 |
| machine learning | AI, artificial intelligence, deep learning, neural networks | 領域固有の用語バリエーションをカバー |
| vehicle | car, automobile, motor vehicle, transportation | 一般的な同義語や関連語を含む |
| headache | migraine, tension headache, pain relief, headache treatment | 医学用語のバリエーションに対応 |
現代のクエリ拡張は、用途や領域ごとに利点の異なる複数の手法を組み合わせて利用します。
各手法は、計算コスト・拡張品質・領域特有性のバランスが異なり、LLMベースは最も高品質ですが資源を多く必要とします。
クエリ拡張はAI回答を向上させます。 なぜなら、言語モデルや検索システムが、よりリッチで網羅的な情報源セットを活用できるようになるからです。クエリを同義語や関連概念、代替表現で拡張することで、異なる用語を使ったドキュメントにもアクセスできるようになり、検索のリコールが大幅に向上します。この拡張された文脈により、AIはより完全かつニュアンスのある回答を合成でき、元のクエリの語彙選択に縛られなくなります。ただし、クエリ拡張には精度とリコールのトレードオフがあります。拡張しすぎるとノイズや無関連ドキュメントが増える可能性があり、最適化の鍵は拡張の強度を調整し、関連性の向上を最大化しつつノイズを最小限に抑えることです。これにより、AI回答の網羅性が高まる一方で正確性も損なわれません。
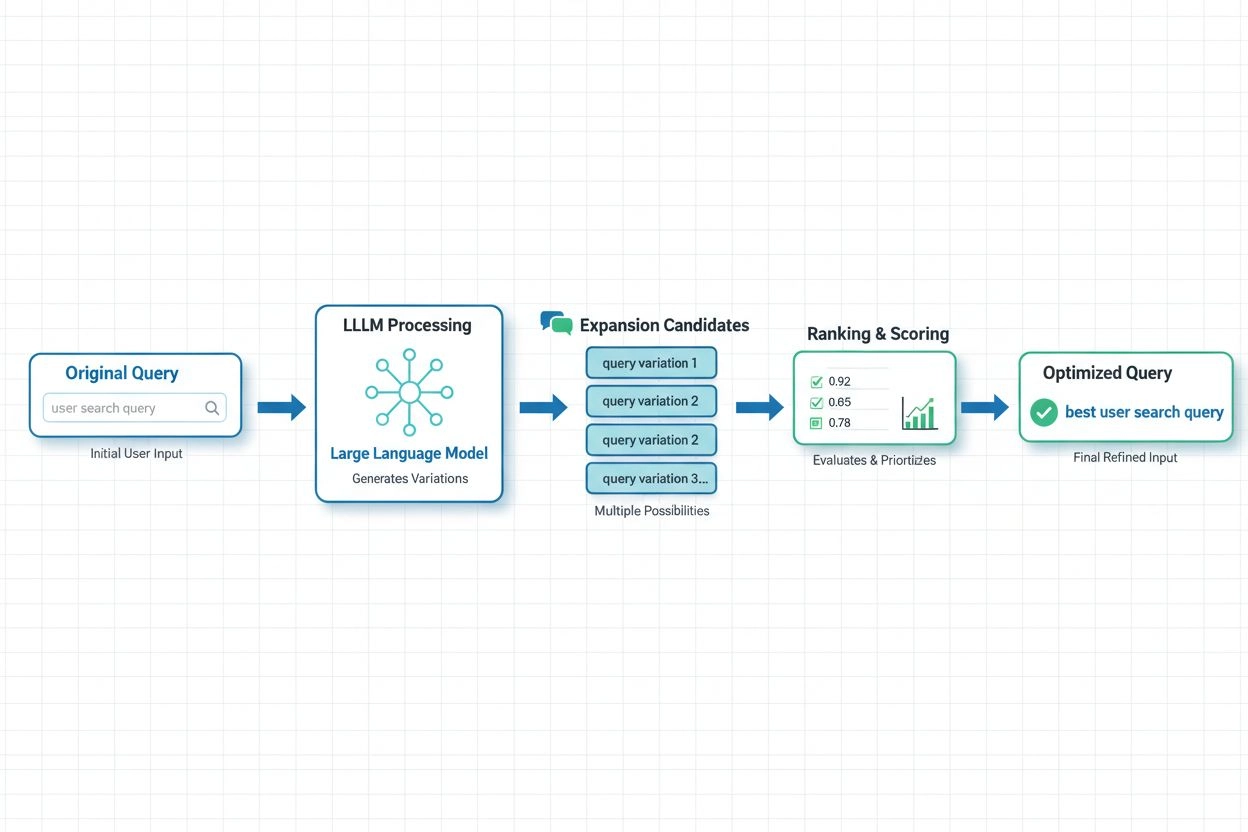
現代AIシステムでは、LLMベースのクエリ拡張が最先端手法として登場しています。これは大規模言語モデルの意味理解能力を活用し、文脈に適したクエリバリエーションを生成します。Spotifyの最新研究では、嗜好整合技術(RSFTとDPO手法の組み合わせ)を使った実装により、処理時間を約70%削減しつつtop-1取得精度も向上したことが示されました。これらのシステムは、ユーザーの好みや意図を理解するよう言語モデルを訓練し、単なる同義語追加ではなく実際に価値ある拡張を生成します。リアルタイム最適化手法では、ユーザーのフィードバックや取得結果に基づき拡張戦略を継続的に適応させ、特定のクエリタイプや領域で最も効果的な拡張を学習します。この動的アプローチは、AIモニタリングプラットフォームにとっても有益で、クエリ拡張が引用精度やコンテンツ発見に与える影響をトピックや業界ごとに追跡できます。
クエリ拡張には多くの利点がありますが、同時に慎重な最適化が求められる課題も存在します。拡張しすぎ問題は、クエリバリエーションを追加しすぎてノイズや無関係なドキュメントが増え、回答の質や計算コストに悪影響を及ぼすことです。領域特有のチューニングも不可欠で、ウェブ検索に適した拡張技術も、医学や法律のような専門分野では用語精度が求められるため期待通りに機能しない場合があります。組織はカバレッジと精度のバランス—関連バリエーションを十分に拾いつつ、無関係な結果がシグナルを圧倒しないよう—を取らなければなりません。効果的な検証手法としては、人間による関連性評価に基づくA/Bテストや、precision@k・recall@kなどの指標監視、どの拡張が実際に下流タスクのパフォーマンスを高めるかの継続分析などがあります。最も成功している実装では、クエリの特性・領域文脈・取得品質に応じて拡張強度を調整する適応的拡張が採用されています。
AmICited.comやAIモニタリングプラットフォームにとって、クエリ拡張最適化は、AIシステムが様々なトピックや検索文脈でどのように情報源を引用・参照するかを正確に追跡するために不可欠です。AIシステムが内部で拡張クエリを使うと、より幅広い情報源にアクセスできるため、回答中に引用される情報やカバー範囲が直接影響されます。つまり、AI回答の質を監視するには、ユーザーが尋ねた内容だけでなく、AIシステムが裏でどんな拡張クエリを使って情報を取得しているかを理解することが重要です。ブランドやコンテンツ制作者は、様々な用語バリエーション・同義語・関連概念をコンテンツ全体に盛り込み、異なるクエリ表現でも見つけられるよう戦略を最適化しましょう。AmICitedは、様々なクエリタイプや拡張においてAI生成回答に自社コンテンツがどう現れるかを追跡し、語彙の不一致で見逃されるギャップや、クエリ拡張戦略が引用パターンやコンテンツ発見に与える影響を明らかにします。
クエリ拡張は元のクエリの意図を保ったまま、関連語や同義語を追加します。一方、クエリ書き換えは検索システムにより適合するようクエリ全体の表現を再構成します。クエリ拡張は検索範囲を広げる付加的な手法ですが、書き換えはクエリの表現方法自体を変える変換的なアプローチです。どちらも検索精度を高めますが、拡張の方が元の意図を守るためリスクが低い傾向があります。
クエリ拡張は、AIシステムが発見・引用する情報源に直接影響します。なぜなら、拡張されたクエリによって取得可能なドキュメントが変わるからです。AIシステムが内部的に拡張クエリを使うと、より多様な情報源にアクセスでき、それが回答中の引用先に反映されます。つまり、AI回答の質を監視するには、ユーザーが尋ねた内容だけでなく、AIシステムが裏でどんな拡張クエリを使っているかを理解する必要があります。
はい、拡張しすぎるとノイズが増え、無関係なドキュメントが取得されて回答の質が低下することがあります。これは、適切なフィルタリングをせずに過剰なクエリバリエーションを加えた場合に発生します。重要なのは拡張の強度を調整し、関連性向上を最大化しながらノイズを最小限に抑えることです。効果的な実装では、クエリの特性や取得品質に応じて拡張の強度を適応的に調整します。
大規模言語モデル(LLM)はクエリ拡張を進化させ、ユーザー意図の意味的理解や文脈に合ったクエリバリエーションの生成を可能にしました。LLMベースの拡張は、嗜好整合技術を用いて、単なる同義語追加ではなく実際に取得性能を高める拡張を生成するようモデルを訓練します。最新研究では、LLMベース手法により処理時間を約70%短縮しつつ、取得精度を向上できることが示されています。
ブランドは、様々な用語バリエーションや同義語、関連概念をコンテンツ内に盛り込み、異なるクエリ表現でも検索されやすくするべきです。つまり、クエリ拡張によってコンテンツが発見される可能性を考慮し、専門用語と口語表現の両方や、代替表現・関連トピックも記述する戦略が重要です。これにより、AIシステムがどんなクエリバリエーションを使っても発見されやすくなります。
主な指標はprecision@k(上位k件の関連性)、recall@k(上位k件でのカバー率)、Mean Reciprocal Rank(最初の関連結果の順位)、および下流タスクでのパフォーマンスです。また、処理時間や計算コスト、ユーザー満足度なども監視されます。異なる拡張戦略を人間の関連性評価と比較しA/Bテストするのが最も信頼性の高い検証方法です。
いいえ、両者は補完的ですが異なる技術です。クエリ拡張は検索クエリそのものを改変して取得精度を上げる手法で、セマンティックサーチは埋め込みやベクトル表現を使い、概念的に類似したコンテンツを検索します。クエリ拡張はセマンティックサーチの一部として使われることもありますが、セマンティックサーチは明示的なクエリ拡張なしでも動作します。どちらも語彙の不一致問題に対応しますが、アプローチが異なります。
AmICitedは、AIシステムが様々なトピックや検索文脈でどのように情報源を引用・参照するか、どの拡張クエリがブランド参照につながるかを追跡します。多様なクエリタイプや拡張を横断して引用パターンを監視することで、クエリ拡張戦略がGPTやPerplexityのようなAIシステムのコンテンツ発見や引用精度にどう影響するかを明らかにします。
クエリ拡張最適化は、GPTやPerplexityのようなAIシステムがあなたのコンテンツをどのように発見し引用するかに影響します。AmICitedを使って、どの拡張クエリによってブランドがAI回答で参照されるかを追跡しましょう。
FAQ拡張がAIシステム向けに包括的な質問と回答ペアをどのように開発するか学びましょう。ChatGPT、Perplexity、Google AI OverviewsのためのAI引用改善、プラットフォーム別最適化、コンテンツの新鮮さ向上の戦略を紹介します。...

AI検索エンジンでキーワードを最適化する方法を学びましょう。ChatGPT、Perplexity、Google AIの回答で自社ブランドが引用されるための戦略や実践的テクニックを解説します。...

クエリリファインメントは、AI検索エンジンでより良い結果を得るために検索クエリを最適化する反復的なプロセスです。ChatGPT、Perplexity、Google AI、Claudeでどのように機能し、情報検索を向上させるかを解説します。...
クッキーの同意
閲覧体験を向上させ、トラフィックを分析するためにクッキーを使用します。 See our privacy policy.