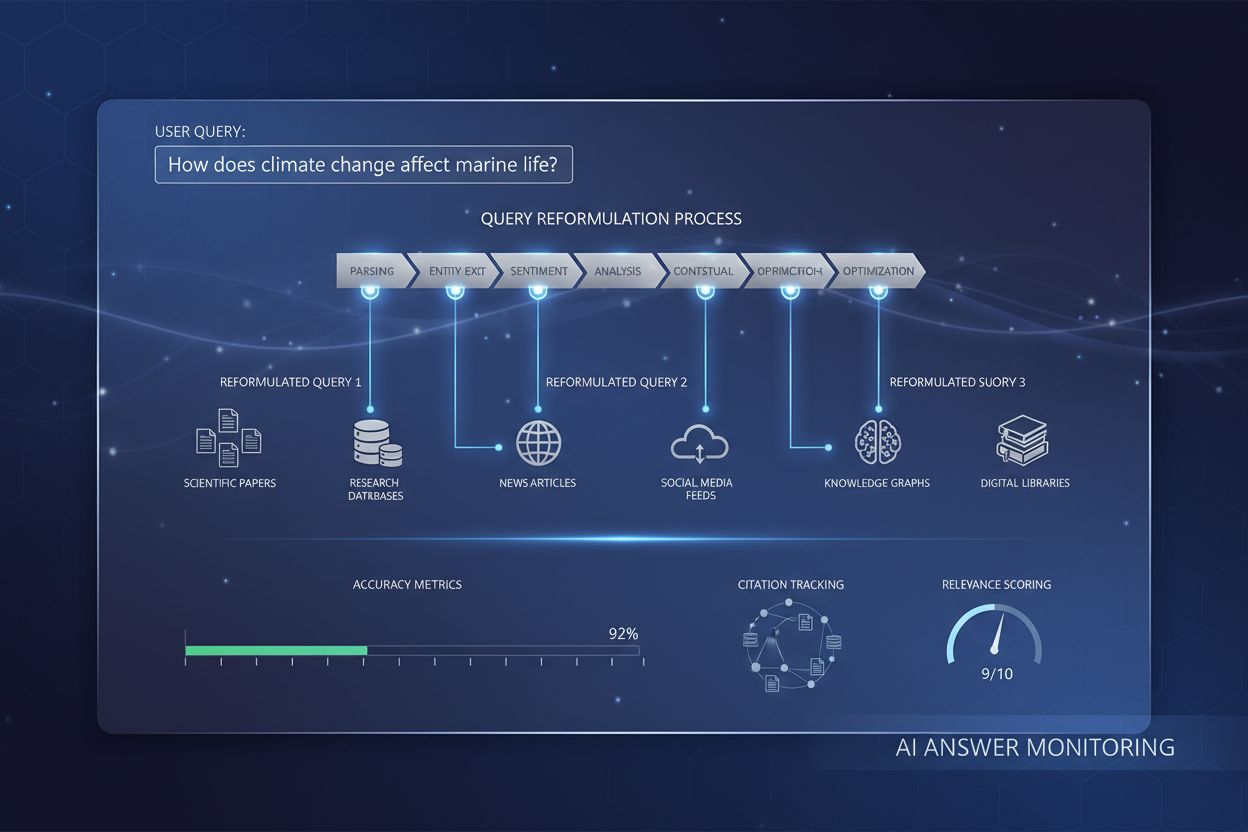
Forespørselsreformulering
Lær hvordan forespørselsreformulering hjelper AI-systemer med å tolke og forbedre brukerforespørsler for bedre informasjonsinnhenting. Forstå teknikker, fordele...
10 min lesing
Optimalisering av forespørselsekspansjon er prosessen med å forbedre brukersøk ved å legge til relaterte termer, synonymer og kontekstuelle variasjoner for å øke AI-systemets treffsikkerhet og innholdsrelevans. Dette bygger bro over vokabulargapet mellom brukerspørsmål og relevante dokumenter, og sikrer at AI-systemer som GPT og Perplexity kan finne og referere til mer passende innhold. Denne teknikken er avgjørende for å forbedre både dekningsgraden og nøyaktigheten til AI-genererte svar. Ved å utvide forespørslene intelligent, kan AI-plattformer dramatisk forbedre hvordan de oppdager og siterer relevante kilder.
Optimalisering av forespørselsekspansjon er prosessen med å forbedre brukersøk ved å legge til relaterte termer, synonymer og kontekstuelle variasjoner for å øke AI-systemets treffsikkerhet og innholdsrelevans. Dette bygger bro over vokabulargapet mellom brukerspørsmål og relevante dokumenter, og sikrer at AI-systemer som GPT og Perplexity kan finne og referere til mer passende innhold. Denne teknikken er avgjørende for å forbedre både dekningsgraden og nøyaktigheten til AI-genererte svar. Ved å utvide forespørslene intelligent, kan AI-plattformer dramatisk forbedre hvordan de oppdager og siterer relevante kilder.
Optimalisering av forespørselsekspansjon er prosessen med å omformulere og forbedre søk ved å legge til relaterte termer, synonymer og semantiske variasjoner for å forbedre gjenfinningsytelse og svarkvalitet. I kjernen handler forespørselsekspansjon om vokabulargapet—den grunnleggende utfordringen at brukere og AI-systemer ofte benytter forskjellig terminologi for å beskrive samme konsepter, noe som fører til at relevante resultater blir oversett. Denne teknikken er avgjørende for AI-systemer fordi den bygger bro mellom hvordan folk naturlig uttrykker sine informasjonsbehov og hvordan innhold faktisk er indeksert og lagret. Ved å utvide forespørsler intelligent kan AI-plattformer dramatisk forbedre både relevansen og dekningsgraden i svarene sine.
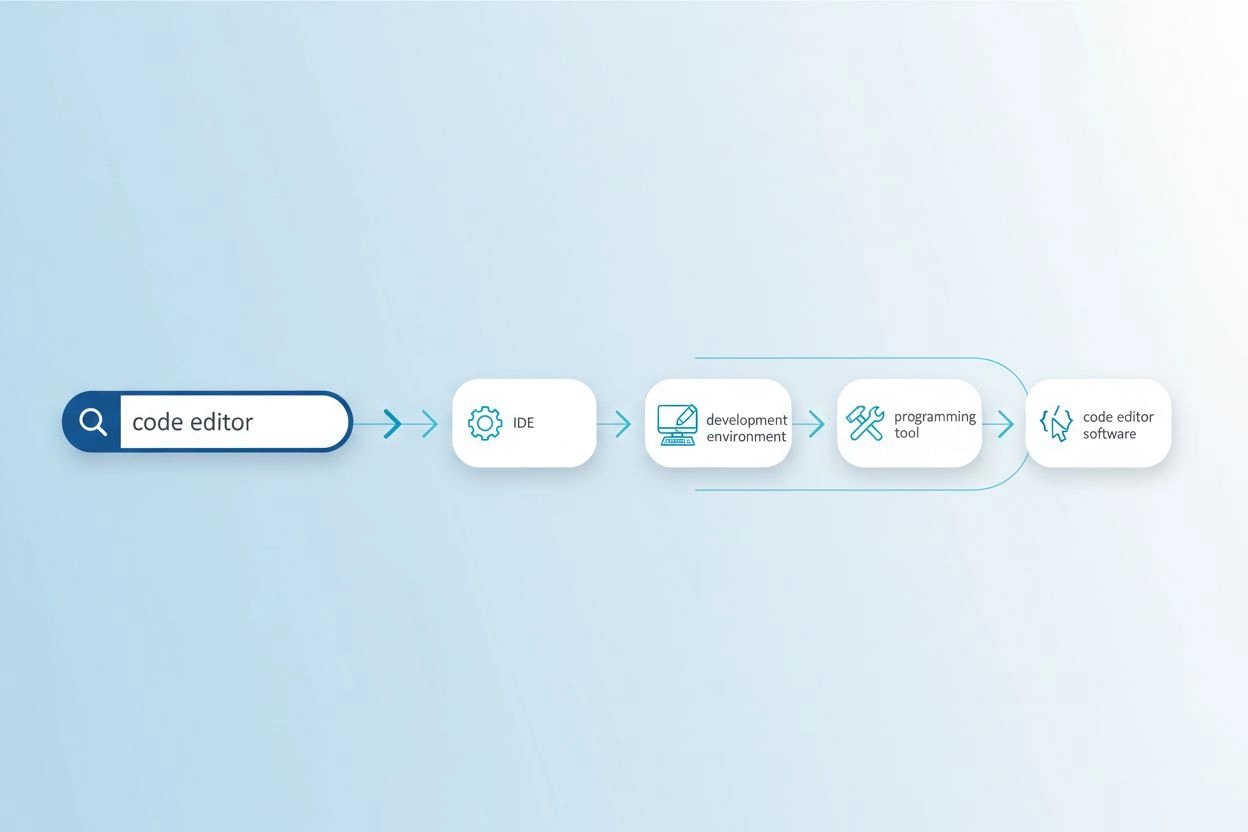
Vokabulargapet oppstår når de eksakte ordene brukt i et søk ikke samsvarer med terminologien i relevante dokumenter, noe som gjør at søkesystemer overser verdifull informasjon. For eksempel kan en bruker som søker etter “kodeeditor” gå glipp av resultater om “IDE-er” (integrerte utviklingsmiljøer) eller “teksteditorer”, selv om disse er høyst relevante alternativer. Tilsvarende kan noen som søker etter “kjøretøy” ikke finne resultater merket med “bil”, “automobil” eller “motorvogn”, til tross for klar semantisk overlapp. Problemet blir enda større i spesialiserte domener hvor flere tekniske termer beskriver samme konsept, og det påvirker direkte kvaliteten på AI-genererte svar ved å begrense tilgjengelig kildemateriale for syntese. Forespørselsekspansjon løser dette ved automatisk å generere relaterte variasjoner som fanger opp ulike måter samme informasjon kan uttrykkes på.
| Opprinnelig forespørsel | Utvidet forespørsel | Effekt |
|---|---|---|
| kodeeditor | IDE, teksteditor, utviklingsmiljø, kildekodeeditor | Finner 3-5x flere relevante resultater |
| maskinlæring | AI, kunstig intelligens, dyp læring, nevrale nettverk | Fanger opp domenespesifikke variasjoner |
| kjøretøy | bil, automobil, motorvogn, transport | Inkluderer vanlige synonymer og relaterte termer |
| hodepine | migrene, spenningshodepine, smertelindring, behandling av hodepine | Dekker medisinske terminologivariasjoner |
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
Moderne forespørselsekspansjon bruker flere komplementære teknikker, hver med ulike fordeler avhengig av brukstilfelle og domene:
Hver teknikk gir ulike avveininger mellom datakostnad, ekspansjonskvalitet og domenespesifisitet, der LLM-baserte tilnærminger gir høyest kvalitet, men krever mer ressurser.
Forespørselsekspansjon forbedrer AI-svar ved å gi språkmodeller og gjenfinningssystemer et rikere og mer omfattende sett med kildemateriale å trekke fra når de genererer svar. Når en forespørsel utvides med synonymer, relaterte konsepter og alternative formuleringer, kan gjenfinningssystemet få tilgang til dokumenter som bruker annen terminologi, men som inneholder like relevant informasjon, og øker dermed tilbakekall i søkeprosessen dramatisk. Denne utvidede konteksten gjør at AI-systemer kan syntetisere mer komplette og nyanserte svar, fordi de ikke lenger er begrenset av det spesifikke ordvalget i den opprinnelige forespørselen. Likevel introduserer forespørselsekspansjon et presisjon vs. tilbakekall-dilemma: Utvidede forespørsler henter flere relevante dokumenter, men kan også føre til støy og mindre relevante resultater hvis ekspansjonen blir for aggressiv. Nøkkelen til optimalisering er å kalibrere ekspansjonsintensiteten slik at relevansen maksimeres uten at irrelevant støy øker, og sikre at AI-svar blir mer omfattende uten å ofre nøyaktighet.
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
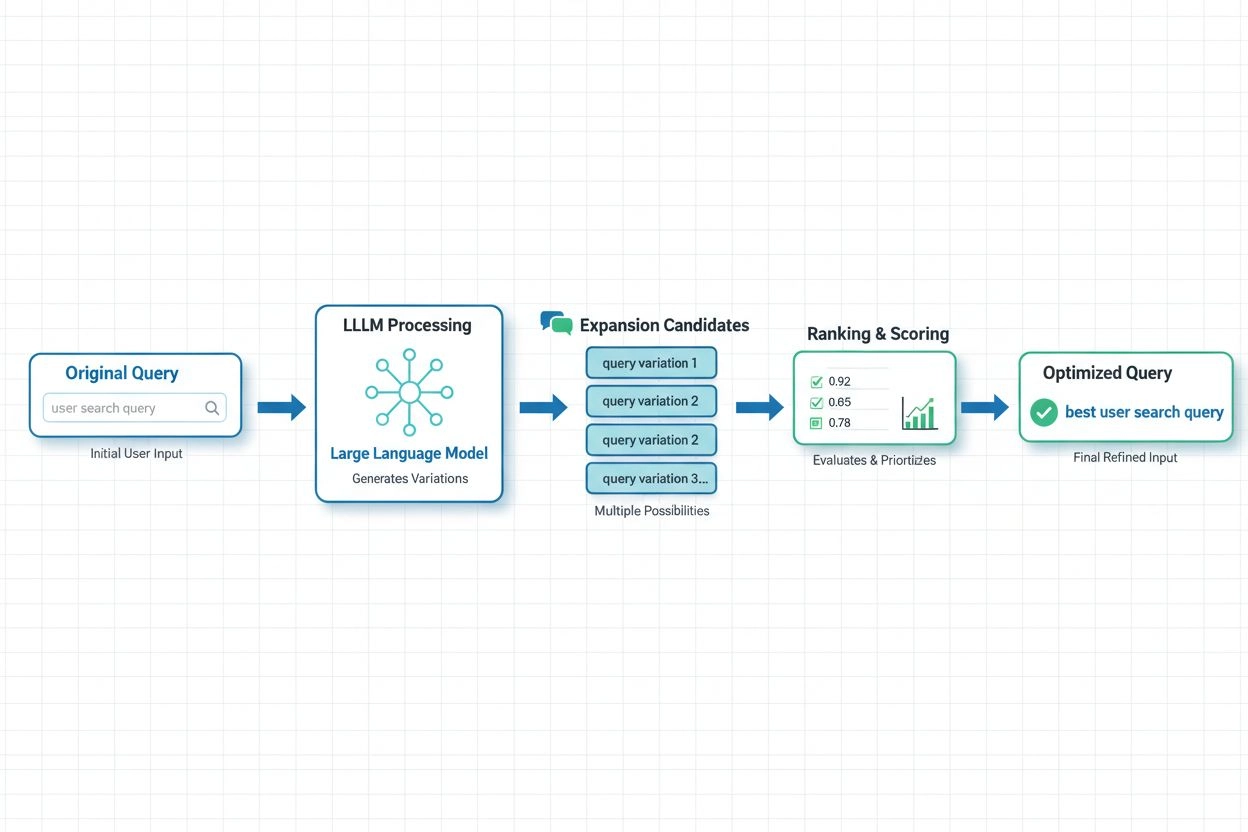
I moderne AI-systemer har LLM-basert forespørselsekspansjon blitt den mest sofistikerte tilnærmingen, hvor de semantiske forståelsesmulighetene til store språkmodeller brukes til å generere kontekstuelt relevante variasjoner. Nyere forskning fra Spotify demonstrerer styrken i denne tilnærmingen: Deres implementering med preferansejusteringsteknikker (kombinert RSFT- og DPO-metode) oppnådde omtrent 70 % reduksjon i behandlingstid samtidig som topp-1 gjenfinningsnøyaktighet ble forbedret. Disse systemene fungerer ved å trene språkmodeller til å forstå brukerpreferanser og hensikt, og deretter generere ekspansjoner som samsvarer med det brukerne faktisk finner verdifullt, i stedet for å legge til vilkårlige synonymer. Sanntidsoptimalisering tilpasser ekspansjonsstrategier løpende basert på brukerrespons og gjenfinningsresultater, slik at systemene lærer hvilke ekspansjoner som fungerer best for ulike forespørselstyper og domener. Denne dynamiske tilnærmingen er spesielt verdifull for AI-overvåkingsplattformer, fordi det muliggjør sporing av hvordan forespørselsekspansjon påvirker siteringsnøyaktighet og innholdsoppdagelse på tvers av ulike temaer og bransjer.
Til tross for fordelene gir forespørselsekspansjon betydelige utfordringer som krever nøye optimaliseringsstrategier. Over-ekspansjonsproblemet oppstår når for mange forespørselsvariasjoner legges til, noe som fører til støy og henter irrelevante dokumenter som svekker svarkvalitet og øker datakostnadene. Domenespesifikk tilpasning er avgjørende, for teknikker som fungerer bra for generell nettsøk kan feile i spesialiserte felt som medisinsk forskning eller juridisk dokumentasjon, hvor terminologisk presisjon er kritisk. Organisasjoner må balansere dekning mot nøyaktighet—utvide nok til å fange opp relevante variasjoner, men ikke så mye at irrelevante resultater overdøver signalet. Effektive valideringsmetoder inkluderer A/B-testing av ulike ekspansjonsstrategier mot menneskelig vurdert relevans, overvåking av måleparametre som presisjon@k og recall@k, og kontinuerlig analyse av hvilke ekspansjoner som faktisk forbedrer ytelsen i etterfølgende oppgaver. De mest vellykkede implementasjonene bruker adaptiv ekspansjon som justerer intensitet basert på forespørselskarakteristikk, domenekontekst og observert gjenfinningskvalitet, i stedet for å bruke faste regler på alle forespørsler.
For AmICited.com og AI-overvåkingsplattformer er optimalisering av forespørselsekspansjon grunnleggende for nøyaktig sporing av hvordan AI-systemer siterer og refererer kilder på tvers av ulike temaer og søkekontekster. Når AI-systemer bruker utvidede forespørsler internt, får de tilgang til et bredere spekter av potensielt kildemateriale, noe som direkte påvirker hvilke siteringer som vises i svarene og hvor dekkende informasjonen blir. Dette betyr at overvåking av kvaliteten på AI-svar krever forståelse av ikke bare hva brukere spør om, men også hvilke utvidede forespørselsvariasjoner AI-systemet kan bruke i bakgrunnen for å hente støttende informasjon. Merkevarer og innholdsskapere bør optimalisere innholdsstrategien sin ved å vurdere hvordan materialet deres kan bli oppdaget gjennom forespørselsekspansjon—ved å bruke flere terminologiske varianter, synonymer og relaterte begreper i innholdet for å sikre synlighet på tvers av ulike forespørselsformuleringer. AmICited hjelper organisasjoner med å overvåke dette ved å spore hvordan innholdet deres dukker opp i AI-genererte svar på ulike forespørselstyper og ekspansjoner, og avdekker hull der innhold kan bli oversett på grunn av vokabulargap, samt gir innsikt i hvordan ekspansjonsstrategier påvirker siteringsmønstre og innholdsoppdagelse i AI-systemer.
Optimalisering av forespørselsekspansjon påvirker hvordan AI-systemer som GPT og Perplexity oppdager og siterer innholdet ditt. Bruk AmICited for å spore hvilke utvidede forespørsler som fører til at merkevaren din blir referert i AI-svar.
Lær hvordan forespørselsreformulering hjelper AI-systemer med å tolke og forbedre brukerforespørsler for bedre informasjonsinnhenting. Forstå teknikker, fordele...

Forespørselsforbedring er den iterative prosessen med å optimalisere søkefraser for bedre resultater i AI-søkemotorer. Lær hvordan det fungerer på tvers av Chat...
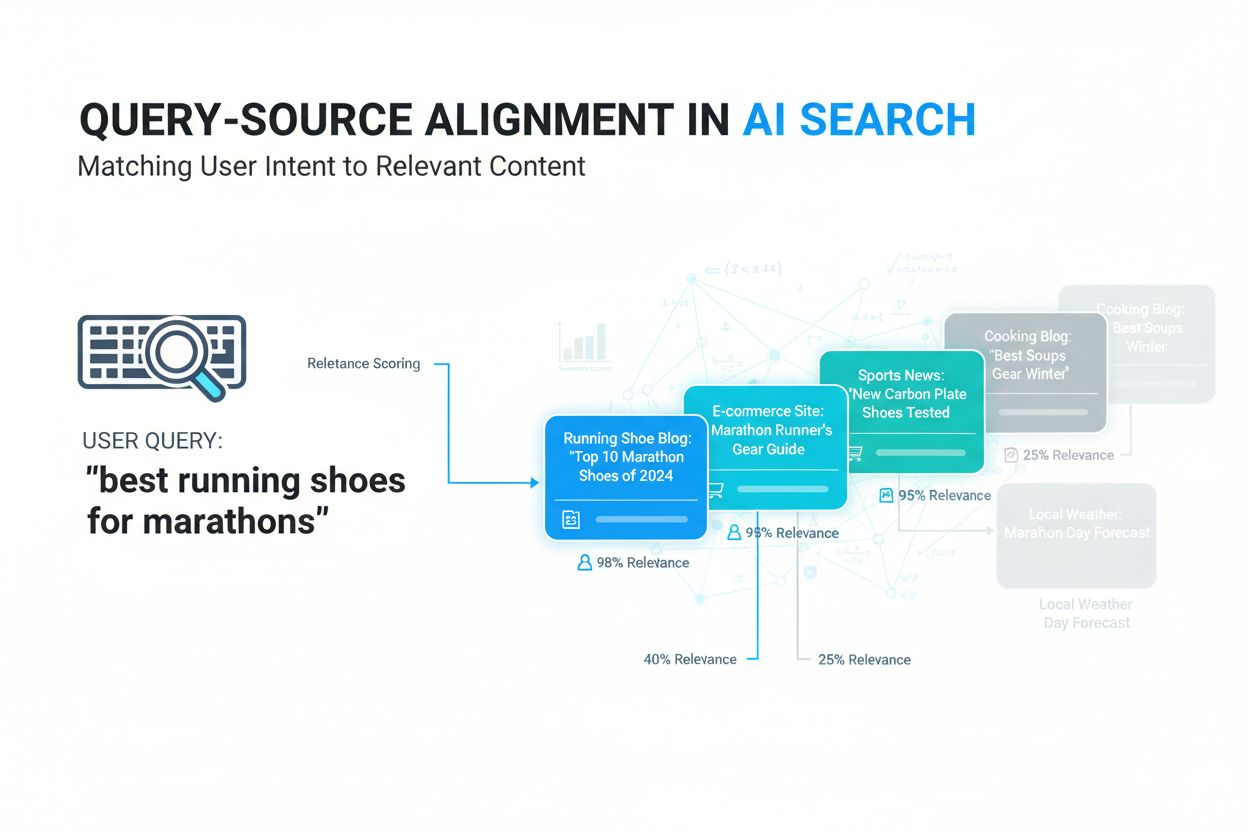
Lær hva spørrsmål-kilde-tilpasning er, hvordan AI-systemer matcher brukersøk med relevante kilder, og hvorfor dette er viktig for innholdssynlighet på AI-søkepl...
Informasjonskapselsamtykke
Vi bruker informasjonskapsler for å forbedre din surfeopplevelse og analysere vår trafikk. See our privacy policy.