
調査はAI引用にどのように役立つのか?
調査がAIの引用精度をどのように向上させ、AI回答におけるブランド露出の監視や、ChatGPT・Perplexityなど各AIプラットフォームでのコンテンツ可視性強化に役立つかを学びます。...
1 分で読める
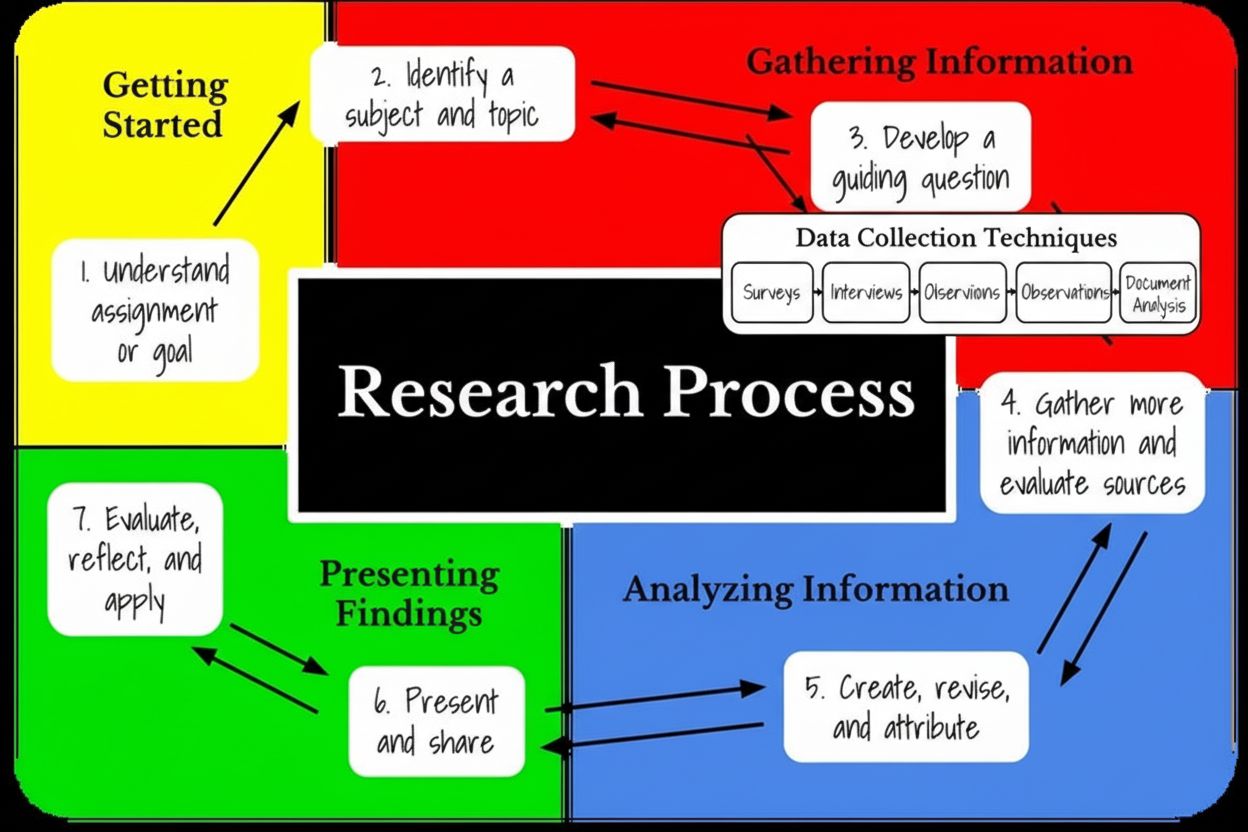
リサーチフェーズの情報収集段階は、多様な情報源からデータ、事実、知識を体系的に収集・整理・評価し、特定の研究課題に答えるためのプロセスです。この基礎的な段階では、適切なデータ収集方法の選定、品質管理の実施、明確な目的設定が行われ、分析や解釈の前段階として位置づけられます。
リサーチフェーズの情報収集段階は、多様な情報源からデータ、事実、知識を体系的に収集・整理・評価し、特定の研究課題に答えるためのプロセスです。この基礎的な段階では、適切なデータ収集方法の選定、品質管理の実施、明確な目的設定が行われ、分析や解釈の前段階として位置づけられます。
リサーチフェーズの情報収集段階は、特定の研究課題や明確な目的を達成するために、多様な情報源からデータ・事実・知識を体系的かつ組織的に収集・整理・評価するプロセスです。この重要な段階は、その後に続く分析・解釈・結論導出を含むすべての研究活動の基礎となります。情報収集は単なるデータ収集を超え、入念な計画、情報源の特定、品質管理の導入、ステークホルダーの関与を含み、収集された情報が正確で関連性が高く、研究課題に直接適用できることを保証します。この段階は、観察や測定という生データを、分析に適した組織的なデータセットへと変換する方法論的な手順によって特徴づけられます。この段階の理解は、研究者、学術関係者、ビジネスアナリスト、証拠に基づいた意思決定に携わるすべての専門家にとって不可欠です。
情報収集段階の形式化は、17~18世紀の科学的方法の発展とともに始まり、体系的な観察とデータ収集が厳密な探究の重要要素と認識されるようになりました。しかし、現代の情報収集手法は、過去100年にわたり研究方法論の専門家、統計学者、組織研究者らの貢献により大きく洗練されてきました。特に20世紀半ばには、データ収集とデータ分析の区別が強調され、収集した情報の質が研究結論の妥当性を直接左右することが認識されるようになりました。今日、情報収集段階は学術・ビジネス・医療・テクノロジー分野におけるエビデンスベース実践の礎とされています。研究方法論の枠組みによれば、研究失敗の約78%は不十分な情報収集に起因するとされ、この段階の重要性が浮き彫りになっています。デジタルツール、データベース、自動収集システムの発展は収集規模の拡大を可能にした一方で、データ品質やバイアス管理、倫理的配慮といった新たな課題も生み出しています。
| 手法カテゴリ | 主なアプローチ | データ型 | サンプル規模 | 時間的投資 | コスト | 最適用途 |
|---|---|---|---|---|---|---|
| 構造化インタビュー | あらかじめ決められた質問 | 定性 | 小~中 | 高 | 中~高 | 一貫性・比較性の確保 |
| 調査・アンケート | 選択式回答 | 定量 | 大 | 低~中 | 低 | 広範な傾向やパターン把握 |
| フォーカスグループ | グループディスカッション | 定性 | 小(6~10) | 中 | 中 | 意見や態度の深掘り |
| 観察 | 直接的な観察 | 定性 | 可変 | 高 | 低~中 | 実際の行動分析 |
| 文書分析 | 既存記録 | 定性/定量 | 可変 | 中 | 低 | 歴史的文脈や傾向分析 |
| 実験 | 制御された条件 | 定量 | 中 | 高 | 高 | 因果関係の解明 |
| オンライン・ウェブデータ | デジタルプラットフォーム | 定量 | 非常に大規模 | 低 | 低 | 拡張性のあるデータ収集 |
| 生体計測 | 生理学的データ | 定量 | 中 | 中 | 高 | 客観的な身体反応の測定 |
情報収集段階は、明確な目的設定とデータ収集範囲の定義から始まる、構造化された複数ステップのプロセスで運用されます。研究者は、どのような情報がなぜ必要で、どのように研究課題の解決に役立つかをまず明確にします。この基本ステップでは、具体的な目標・成果物・タスクを文書化し、必要なリソースやスケジューリングを明示します。目的が定まったら、研究設計、利用可能リソース、課題の性質に応じて適切なデータ収集方法を選択します。手法選定では、定性(インタビュー、観察、フォーカスグループ)と定量(調査、実験、生体計測)のどちらが適切か、または両者を組み合わせたミックス手法が最適かを慎重に検討します。選択した手法の実施には、データ収集者の訓練、標準化手順の策定、品質管理チェックポイントの設定などが必要です。収集プロセス全体で、データソース・収集日・使用手法・計画からの逸脱点などを詳細に記録します。最終的には、コーディングや分類、検証手順を通じて収集データを整理し、分析に適した状態へと整えます。
現代のビジネス環境において、情報収集段階は意思決定、戦略立案、競争優位の確立に直接影響します。厳格な情報収集を実践する企業は、市場調査や顧客満足度分析、新製品開発において明確な成果を上げています。業界調査によれば、構造化された情報収集プロセスを持つ組織は、アドホックな手法に比べて洞察獲得までの期間が40%短縮されます。特に市場調査では、消費者の嗜好や競争状況、新興トレンドを理解し、戦略的判断を下すうえで不可欠です。医療・製薬分野では、治療の安全性や有効性を左右し、品質管理や体系的収集手順が文字通り生命を左右します。金融機関もリスク評価や不正検出、規制遵守のため包括的な情報収集に依存しています。リソース配分にも実務的影響があり、不十分な情報収集は投資の無駄や機会損失、戦略ミスにつながります。情報収集基盤やツール、人材育成に投資する組織は、意思決定の迅速さ・正確さで常に競合より優位に立ちます。また、透明でデータ駆動型の情報収集プロセスは、組織文化やステークホルダーの信頼構築にも寄与します。
AIモニタリングプラットフォーム(例:AmICited)の文脈では、情報収集段階は、ブランドやドメイン、URLが各種AIによる生成回答でどのように表現されているかを追跡するうえで特別な意味を持ちます。ChatGPT、Perplexity、Google AI Overviews、Claudeなどはそれぞれ異なる方法で回答を生成するため、各プラットフォームの特性に合わせた体系的な情報収集アプローチが必要です。AIモニタリングでの情報収集段階では、ブランド言及や競合ポジショニング、AI回答の正確性など明確な追跡目的を設定します。自動追跡システムや定期的な手動監査、これらのハイブリッド型など、適切なモニタリング手法を選択する必要があります。AIシステムは一貫性のない情報や幻覚的な内容も生成しうるため、正確な言及と誤検知を判別する検証手順が品質管理面で特に重要となります。さらに、複数AIソースからのデータを統合し、各プラットフォームのブランド表現パターンを明らかにします。こうした専門的応用は、従来の研究方法論が新たなテクノロジーや情報エコシステムに適応していく例です。
情報収集段階を効果的に実施するには、各分野や組織で検証されたベストプラクティスを順守する必要があります。第一に、研究課題と直接結びつく明確かつ測定可能な目的を設定し、すべての収集活動が明確な目標に従うようにします。第二に、研究文脈に適した手法の選定を行い、調査範囲やリソース、必要な妥当性、知見の性質などを考慮します。第三に、厳格な品質管理手順(データ検証チェック、標準化プロトコル、定期監査など)を導入し、バイアスや誤りを最小化します。第四に、すべての収集活動の詳細な記録(日時・手法・データソース・逸脱内容など)を維持し、監査証跡を確保します。第五に、関係者の計画・実施への参画を促し、実際の情報ニーズに基づいた収集と組織的合意を確保します。第六に、調査規模や複雑さに適合したツール・テクノロジーの活用(小規模なら表計算、大規模なら高度なデータ管理基盤など)を行います。第七に、データ収集者の徹底的な訓練を行い、一貫性・バイアス低減・品質基準維持を徹底します。第八に、データのセキュリティ・プライバシー管理(GDPRやCCPA、倫理審査委員会基準への準拠など)を確立します。これらのベストプラクティスにより、収集情報の正確性・信頼性・関連性・分析への即応性が確保されます。
情報収集段階は、テクノロジー進化やAI統合、組織ニーズの変化によって大きな変革期を迎えています。人工知能や機械学習の進展は、データ収集や整理プロセスの自動化を加速し、従来より大規模なデータセットを短期間で扱うことを可能にしています。自動収集システム、自然言語処理ツール、インテリジェントなデータ検証アルゴリズムが手作業を軽減し、一貫性とバイアス低減を実現しています。リアルタイムモニタリングシステムの統合により、断続的な収集ではなく継続的な情報取得が可能となり、動的かつ即応的なインサイトが得られます。ブロックチェーンや分散型台帳技術は、データの真正性や透明性担保の手段として台頭し、データ出所や信憑性が重視される場面で活用が進んでいます。プライバシー保護型データ収集手法(差分プライバシーや連合学習など)は、データセキュリティや規制順守への懸念に応えつつ分析価値を維持します。AIモニタリングやブランドトラッキングの文脈では、生成系AI特有の幻覚や一貫性欠如、モデル挙動の急変に対応するため、専用の情報収集フレームワーク開発が進んでいます。今後は倫理的情報収集の強化や、バイアス検出・低減手法の高度化が重視されるでしょう。さらに、複数データソースの統合による高度なデータフュージョンが進み、単一ソースでは得られない多次元的・包括的インサイトが得られるようになります。こうしたトレンドの収束により、情報収集段階は一層高度化・自動化・分析機能との統合が進み、組織の情報獲得と意思決定の在り方を根本から変革していくでしょう。
情報収集段階の主要な目的は、研究課題に直接関係する信頼性の高いデータを多様な情報源から体系的に収集することです。この段階は、その後のすべての分析の基礎を築き、研究者が正確かつ高品質な情報をもとに結論を導き出せるようにします。研究方法論の枠組みによれば、効果的な情報収集は研究プロジェクト全体の信頼性と妥当性を決定します。
情報収集は、さまざまな情報源から生データを収集・整理する段階であり、データ分析は収集されたデータを解釈し結論を導き出す段階です。情報収集は事実や観察事項を取得する入力フェーズ、分析はパターンや傾向、関係性を見出す処理フェーズであり、両者は研究プロセスで異なる役割を担います。
主なデータ収集方法には、定性的手法(インタビュー、フォーカスグループ、観察、文書分析)と定量的手法(調査、アンケート、実験、生体計測)が含まれます。また、両者を組み合わせたミックス手法も用いられます。どの方法を選ぶかは、研究目的、リソース、調査範囲、必要とされる知見の種類によって異なります。
情報収集段階での品質管理は、収集したデータの正確性・信頼性・偏りや誤りの排除を確保するために重要です。データ品質が低いと誤った結論や判断ミスにつながります。Forrester Researchの調査によると、25%以上の組織がデータ品質不良により毎年500万ドル以上の損失を出しています。厳格な品質管理や検証チェック、標準化手順の導入が研究の信頼性を守ります。
AmICitedのようなAIモニタリングプラットフォームでは、情報収集段階でブランドやドメインがChatGPT、Perplexity、Google AI Overviews、Claudeなど各種AIプラットフォーム上でどのように表示されるかを体系的に収集します。この段階では、明確なモニタリング目的の設定、適切な追跡方法の選定、複数AIソースからのデータ整理を通じて包括的なブランド可視化インサイトを提供します。
一次データソースは、アンケートやインタビュー、実験などを通じて直接収集されるデータで、研究目的に特化しています。二次データソースは、既存の報告書や学術研究、政府統計、歴史記録などから得られる情報です。一次データはより関連性が高く最新ですがリソースが多く必要で、二次データはコスト効率が高い一方で研究ニーズに特化しない場合があります。
情報収集段階の所要期間は、研究の規模、利用可能なリソース、データ収集方法により大きく異なります。小規模な定性調査では数週間、大規模な定量調査では数ヶ月から数年かかることもあります。研究手法ガイドラインによれば、適切な計画と明確な目的設定により、収集期間を20~30%短縮しつつデータ品質と妥当性を維持できます。
一般的な課題には、サンプリングバイアスやアンケートでの回答バイアス、特定データ源へのアクセス困難、リソース制約、複数手法におけるデータ品質維持などが挙げられます。また、データ整理、参加者の機密保持、大量情報の管理も課題です。これらへの対応には、計画的手順、適切なツールの選定、強固な品質管理の実施が求められます。
ChatGPT、Perplexity、その他のプラットフォームでAIチャットボットがブランドを言及する方法を追跡します。AI存在感を向上させるための実用的なインサイトを取得します。
調査がAIの引用精度をどのように向上させ、AI回答におけるブランド露出の監視や、ChatGPT・Perplexityなど各AIプラットフォームでのコンテンツ可視性強化に役立つかを学びます。...

オリジナルリサーチとファーストパーティデータは、ブランドが直接収集する独自の調査および顧客情報です。これらがどのように権威を構築し、AIで引用され、AI主導の検索環境で競争優位を生み出すかを学びましょう。...
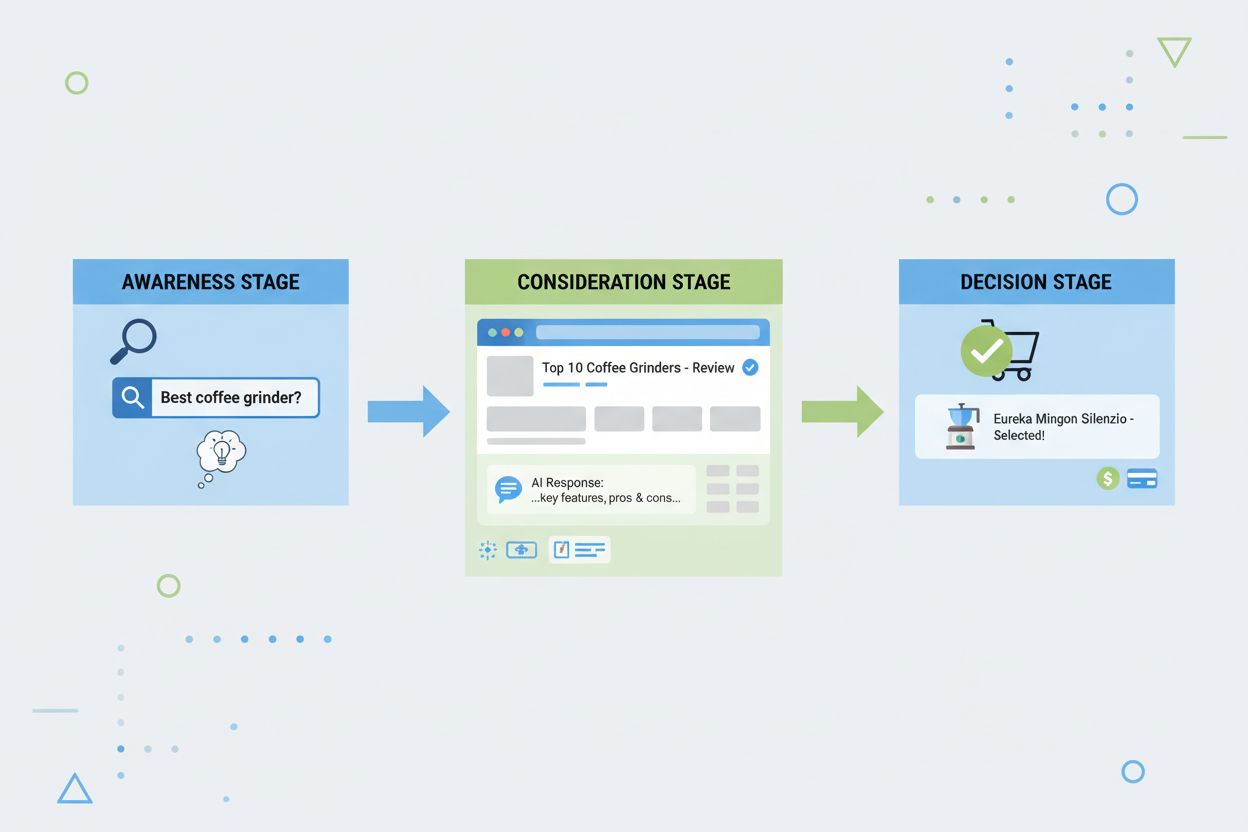
検索ジャーニーとは何か、ユーザーが認知・検討・決定の各段階をどのように進むか、そしてブランドのAI検索エンジンでの可視性を高めるために検索ジャーニーを監視する重要性について解説します。...
クッキーの同意
閲覧体験を向上させ、トラフィックを分析するためにクッキーを使用します。 See our privacy policy.