De anatomie van een AI-gegenereerd antwoord: waar citaties plaatsvinden
Leer hoe AI-modellen antwoorden genereren en citaties plaatsen. Ontdek waar jouw content verschijnt in ChatGPT-, Perplexity- en Google AI-antwoorden en hoe je kunt optimaliseren voor AI-zichtbaarheid.
Gepubliceerd op Jan 3, 2026.Laatst gewijzigd op Jan 3, 2026 om 3:24 am
De anatomie van een AI-gegenereerd antwoord: waar citaties plaatsvinden
AI-gegenereerde antwoorden zijn de belangrijkste ontdekkingsmethode geworden voor miljoenen gebruikers en hebben de informatiestroom op internet fundamenteel veranderd. Volgens recent onderzoek steeg de AI-adoptie onder onderzoekers tot 84% in 2025, waarbij 62% AI-tools specifiek gebruikt voor onderzoeks- en publicatietaken—een dramatische toename ten opzichte van slechts 57% algemeen AI-gebruik in 2024. Toch zijn de meeste contentmakers zich er niet van bewust dat de plaatsing van citaties binnen deze AI-gegenereerde antwoorden niet willekeurig is; het volgt een geavanceerde technische architectuur die bepaalt welke bronnen zichtbaar worden en welke onzichtbaar blijven. Begrijpen waar en waarom citaties verschijnen, is nu essentieel voor iedereen die zichtbaarheid wil behouden in het door AI aangedreven ontdekkingslandschap.
Model-native synthese vs Retrieval-Augmented Generation
Het onderscheid tussen model-native synthese en Retrieval-Augmented Generation (RAG) bepaalt fundamenteel hoe citaties verschijnen in AI-antwoorden. Model-native synthese vertrouwt volledig op kennis die tijdens de training is opgeslagen, terwijl RAG dynamisch externe bronnen ophaalt om antwoorden te onderbouwen met actuele informatie. Dit verschil heeft grote gevolgen voor citatieplaatsing en zichtbaarheid.
Kenmerk
Model-native synthese
RAG
Definitie
Antwoorden gegenereerd uit alleen trainingsdata
Antwoorden gebaseerd op real-time opgehaalde bronnen
Snelheid
Sneller (geen ophaalvertraging)
Langzamer (vereist ophaalstap)
Nauwkeurigheid
Kans op hallucinaties en verouderde info
Hogere nauwkeurigheid met actuele bronnen
Citatiemogelijkheid
Beperkt of afwezig
Rijke, traceerbare citaties
Toepassingen
Algemene kennis, creatieve taken
Nieuws, onderzoek, factchecking, eigen data
RAG-gebaseerde systemen zoals Perplexity en Google’s AI Overviews leveren van nature meer citaties omdat ze hun ophaalbronnen moeten noemen, terwijl model-native benaderingen zoals traditionele ChatGPT-antwoorden minder vaak citeren. Begrijpen welke aanpak een platform gebruikt, helpt contentmakers om de kans op citatie in te schatten en daarop te optimaliseren.
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
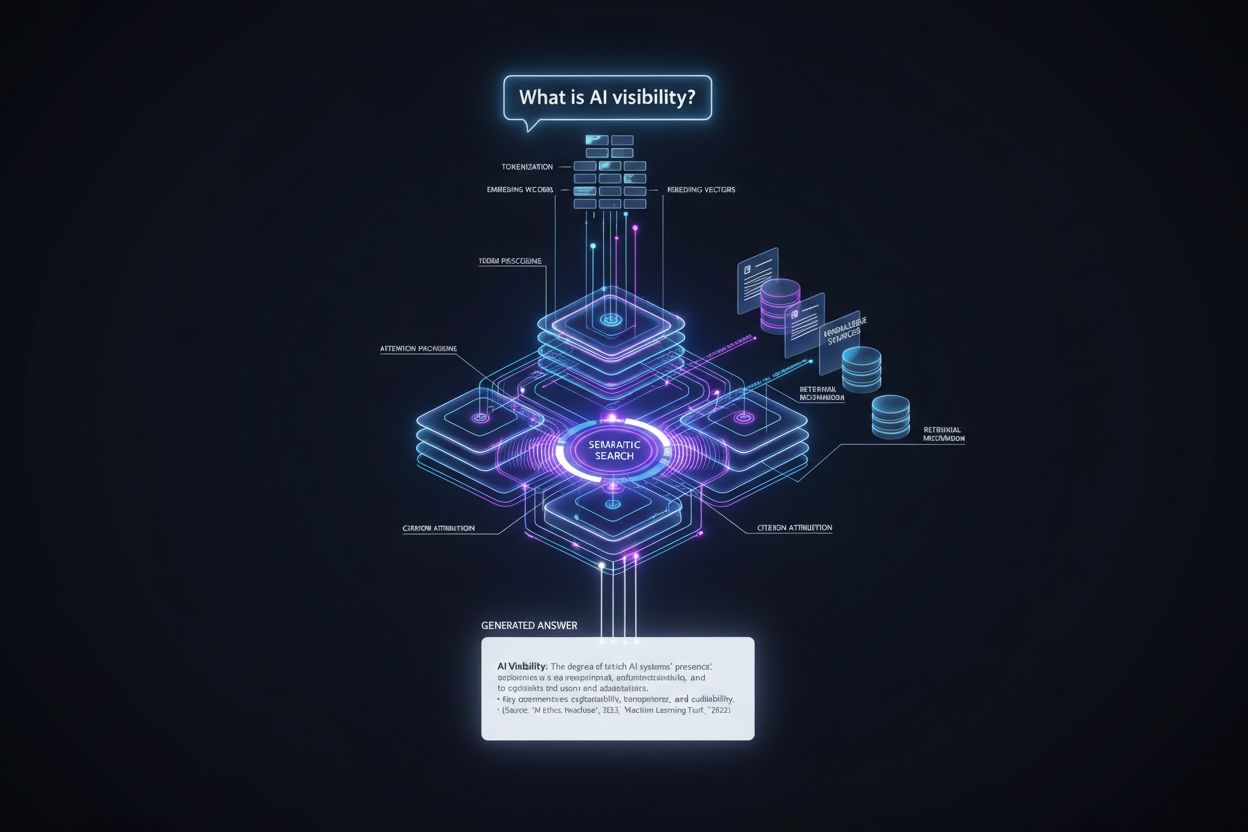
De reis van gebruikersvraag tot geciteerd antwoord volgt een nauwkeurige technische pijplijn die de citatieplaatsing op meerdere niveaus bepaalt. Zo verloopt het proces:
Vraagverwerking: De vraag van de gebruiker wordt getokeniseerd—opgesplitst in discrete eenheden die het model begrijpt—en geanalyseerd op intentie, entiteiten en semantische betekenis via embedding vectors.
Informatieophaling: Het systeem doorzoekt zijn kennisbasis (trainingsdata, geïndexeerde documenten of real-time bronnen) met semantisch zoeken, waarbij de betekenis van de vraag wordt gematcht in plaats van exacte trefwoorden, en retourneert kandidaat-bronnen gerangschikt op relevantie.
Contextassemblage: Opgehaalde informatie wordt georganiseerd in een contextvenster—de hoeveelheid tekst die het model tegelijk kan verwerken—waarbij de meest relevante bronnen prominent worden gepositioneerd om de aandacht van het model te sturen.
Token-generatie: Het model genereert het antwoord één token tegelijk, met gebruik van self-attention-mechanismen om te bepalen welke eerder gegenereerde tokens en broninformatie invloed moeten hebben op elke nieuwe token, zodat coherente, contextueel onderbouwde antwoorden ontstaan.
Citatie-toewijzing: Terwijl tokens worden gegenereerd, houdt het model bij welke bron-documenten specifieke beweringen beïnvloeden, wijst geloofwaardigheidsscores toe en bepaalt of expliciete citaties worden opgenomen op basis van vertrouwensniveaus en platformvereisten.
Outputlevering: Het uiteindelijke antwoord wordt geformatteerd volgens de specificaties van het platform—inline citaties, voetnoten, bronnenpanelen of hover-over links—en aan de gebruiker gepresenteerd met metadata over bronautoriteit en relevantie.
Citatieplaatsing op grote platforms
Citatieplaatsing verschilt sterk per AI-platform, wat verschillende zichtbaarheid biedt voor contentmakers. Zo gaan grote platforms om met citaties:
ChatGPT: Citaties verschijnen in een apart ‘Bronnen’-paneel onder het antwoord, waarbij gebruikers actief moeten klikken om ze te zien. Bronnen zijn meestal beperkt tot 3-5 links, met voorrang voor domeinen met hoge autoriteit.
Perplexity: Citaties zijn inline verwerkt in het antwoord met superscript nummers en een uitgebreide bronnenlijst onderaan. Elke bewering is te traceren, waardoor het het meest transparante platform is qua citatie.
Google Gemini: Citaties verschijnen als inline links binnen de tekst van het antwoord, met een ‘Bronnen’-sectie waarin alle geraadpleegde materialen worden vermeld. Integratie met Google’s knowledge graph beïnvloedt welke bronnen geselecteerd worden.
Claude: Citaties worden als voetnoten gepresenteerd met verwijzingen tussen haakjes, zodat gebruikers bronnen kunnen zien zonder het antwoord te verlaten. Claude benadrukt brondiversiteit en geloofwaardigheid.
DeepSeek: Citaties verschijnen als inline hyperlinks met minimale visuele onderscheid, wat een meer geïntegreerde aanpak weerspiegelt waarbij bronnen naadloos in het verhaal zijn verweven.
Deze verschillen betekenen dat een bron die door Perplexity wordt geciteerd direct verkeer kan ontvangen, terwijl dezelfde bron die door ChatGPT wordt geciteerd onzichtbaar kan blijven tenzij gebruikers specifiek op het bronnenpaneel klikken. Platform-specifieke citaatpatronen hebben direct invloed op verkeer en zichtbaarheid.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Retrievalsystemen en citatieplaatsing
Het retrievalsysteem bepaalt waar citatiebeslissingen beginnen, lang voordat het antwoord wordt gegenereerd. Semantisch zoeken zet zowel de gebruikersvraag als de geïndexeerde documenten om in vector embeddings—numerieke representaties die betekenis bevatten in plaats van trefwoorden. Het systeem berekent vervolgens similarity scores tussen de vraag-embedding en document-embeddings, en identificeert welke bronnen semantisch het dichtst bij de intentie van de gebruiker liggen.
Ranking-algoritmen herschikken deze kandidaten vervolgens op basis van meerdere signalen: relevantiescore, domeinautoriteit, actualiteit van de content, gebruikersbetrokkenheid en kwaliteit van gestructureerde data. Bronnen die het hoogst scoren in deze retrievalfase worden vaker opgenomen in het contextvenster dat aan het generatiemodel wordt gevoed, waardoor ze een grotere kans hebben om geciteerd te worden. Daarom zal een goed geoptimaliseerd, semantisch duidelijk artikel van een autoritair domein vaker worden opgehaald en geciteerd dan een slecht gestructureerd artikel van een nieuwer domein, zelfs als beide accurate informatie bevatten. De retrievalfase bepaalt in wezen de citatiepool voordat de generatie begint.
Hoe contentstructuur de kans op citatie beïnvloedt
Contentstructuur is niet alleen een UX-overweging—het bepaalt direct of AI-systemen jouw content kunnen extraheren, begrijpen en citeren. AI-modellen vertrouwen op opmaak-signalen om informatiegrenzen en relaties te herkennen. Dit zijn de structurele elementen die de kans op citatie maximaliseren:
Antwoord-eerst structuur: Begin met het directe antwoord op veelgestelde vragen, zodat AI-systemen snel de meest relevante informatie kunnen identificeren en extraheren zonder door inleidende tekst te hoeven zoeken.
Duidelijke koppen: Gebruik beschrijvende H2- en H3-koppen die expliciet het onderwerp van elke sectie aangeven, zodat AI-systemen de organisatie van de content begrijpen en relevante stukken kunnen extraheren voor specifieke vragen.
Optimale alinea-lengte: Houd alinea’s bij voorkeur 3-5 zinnen lang, zodat AI-systemen afzonderlijke beweringen makkelijker kunnen herkennen en toewijzen aan specifieke bronnen zonder ambiguïteit.
Lijsten en tabellen: Gestructureerde data in opsommingen en tabellen is makkelijker te parseren en citeren dan doorlopende tekst, omdat AI-systemen individuele beweringen en hun grenzen duidelijk kunnen herkennen.
Entiteit-clariteit: Noem personen, organisaties, producten en concepten expliciet in plaats van met voornaamwoorden, zodat AI-systemen exact begrijpen waar elke bewering op slaat en dat accuraat kunnen citeren.
Schema markup: Implementeer gestructureerde data (Schema.org) om expliciete metadata te bieden over contenttype, auteur, publicatiedatum en beweringen, waarmee AI-systemen extra signalen krijgen voor evaluatie en citatie.
Content die deze structurele principes volgt, wordt 2-3x vaker geciteerd dan slecht gestructureerde content, ongeacht de kwaliteit, omdat het voor AI-systemen eenvoudiger te extraheren en toe te wijzen is.
Citatietoewijzingsproces
Zodra bronnen zijn opgehaald en samengevoegd in het contextvenster, beoordeelt het model elke bron door verschillende geloofwaardigheidslenzen voordat het besluit om te citeren. Beoordeling van bron-geloofwaardigheid kijkt naar domeinautoriteit (bepaald door backlinkprofielen, domeinleeftijd en merkherkenning), auteursexpertise (herkenbaar uit bylines, auteursbio’s en diploma-signalen) en topische relevantie (of de primaire focus van de bron aansluit op de vraag).
Relevantie scoring meet hoe direct de bron de specifieke vraag beantwoordt, waarbij antwoorden die exact overeenkomen hoger scoren dan zijdelingse informatie. Actualiteitsfactoren bepalen of recente bronnen worden geprefereerd boven oudere—cruciaal bij nieuws, onderzoek en snel veranderende onderwerpen. Autoriteitssignalen omvatten citaties van andere gezaghebbende bronnen, vermeldingen in academische databases en aanwezigheid in knowledge graphs. Metadata-invloed komt van title tags, meta-beschrijvingen en gestructureerde data die expliciet het doel en de geloofwaardigheid van de content communiceren. Tot slot biedt gestructureerde data (Schema.org markup) expliciete geloofwaardigheidssignalen die het model direct kan lezen, zoals auteurskwalificaties, publicatiedata, beoordelingsscores en factcheck-status. Bronnen met uitgebreide schema markup worden betrouwbaarder geciteerd omdat het model expliciete, machine-leesbare bevestiging van hun beweringen heeft.
Veelvoorkomende citatieplaatsingspatronen
AI-platforms hanteren verschillende citaatstijlen die bepalen hoe zichtbaar jouw citaties voor gebruikers zijn. Dit zijn de meest voorkomende patronen:
Inline citaties (Perplexity-stijl):
“Volgens recent onderzoek steeg de AI-adoptie onder onderzoekers tot 84% in 2025[1], waarbij 62% AI-tools specifiek gebruikt voor onderzoekstaken[2].”
Einde-van-alinea-citaties (Claude-stijl):
“AI-adoptie onder onderzoekers steeg tot 84% in 2025, waarbij 62% AI-tools specifiek gebruikt voor onderzoekstaken. [Bron: Wiley Research Report, 2025]”
Voetnoot-citaties (Academische aanpak):
“AI-adoptie onder onderzoekers steeg tot 84% in 2025¹, waarbij 62% AI-tools specifiek gebruikt voor onderzoekstaken².”
Bronnenlijsten (ChatGPT-stijl):
Antwoordtekst zonder inline citaties, gevolgd door een aparte ‘Bronnen’-sectie met 3-5 links.
Hover-over citaties (Opkomend patroon):
Onderstreepte tekst die broninformatie toont wanneer gebruikers eroverheen bewegen, waardoor visuele rommel wordt geminimaliseerd en traceerbaarheid behouden blijft.
Elke stijl veroorzaakt ander gebruikersgedrag: inline citaties leiden tot directe klikken, bronnenlijsten vereisen bewuste actie van gebruikers en hover-over citaties balanceren zichtbaarheid met esthetiek. De kans dat jouw content wordt geciteerd varieert per platform, waardoor multi-platform monitoring essentieel is.
Zakelijke impact van citatieplaatsing
Inzicht in de mechanica van citatieplaatsing vertaalt zich direct in meetbare bedrijfsresultaten. Verkeersimplicaties zijn direct: bronnen die inline door Perplexity worden geciteerd ontvangen 3-5x meer verwijzingsverkeer dan bronnen die alleen in het bronnenpaneel van ChatGPT verschijnen, omdat gebruikers eerder op inline citaties klikken tijdens het lezen. De relatie tussen zichtbaarheid en doorklikken is niet lineair—geciteerd worden is alleen waardevol als gebruikers daadwerkelijk op de citatie klikken, wat afhangt van plaatsing, platform en context.
Merkauthoriteit bouwt zich op over tijd: bronnen die consequent door meerdere AI-platforms worden geciteerd ontwikkelen sterkere autoriteitssignalen, waardoor hun ranking in traditionele zoekmachines verbetert en de kans op toekomstige AI-citaties toeneemt. Dit creëert een positieve spiraal waarin geciteerde content steeds meer autoriteit krijgt en meer citaties aantrekt. Concurrentievoordeel ontstaat voor merken die eerder dan de concurrentie optimaliseren voor AI-citatie—early adopters van schema-implementatie en contentstructuur optimalisatie ontvangen momenteel een onevenredig hoog aandeel citaties. SEO-implicaties reiken verder dan AI: content die geoptimaliseerd is voor AI-citatie presteert doorgaans ook beter in traditionele zoekresultaten, omdat dezelfde structurele duidelijkheid en autoriteitssignalen beide systemen ten goede komen. De waarde van AmICited wordt duidelijk: in een door AI aangedreven ontdekkingslandschap is niet weten of je wordt geciteerd gelijk aan niet weten wat je zoekpositie is—het is een cruciaal blinde vlek in je zichtbaarheidstrategie.
Praktische tips voor contentmakers
Optimaliseren voor AI-citaties vereist specifieke, direct toepasbare aanpassingen aan de manier waarop je content maakt en structureert. Dit zijn de meest impactvolle tactieken:
Structureer voor extractie: Gebruik duidelijke koppen, korte alinea’s en lijsten zodat AI-systemen je content makkelijk kunnen parseren en specifieke beweringen zonder ambiguïteit kunnen extraheren.
Gebruik duidelijke, citeerbare feiten: Begin met concrete statistieken, datums en benoemde entiteiten in plaats van vage algemeenheden. AI-systemen citeren liever concrete beweringen dan abstracte uitspraken.
Implementeer schema markup: Voeg Schema.org markup toe voor Article, NewsArticle of ScholarlyArticle types, inclusief auteur, publicatiedatum en claim-specifieke metadata die AI-systemen direct kunnen verwerken.
Houd entiteit-consistentie aan: Gebruik overal dezelfde namen voor personen, organisaties en concepten, en vermijd voornaamwoorden en afkortingen die voor AI-systemen ambiguïteit creëren.
Citeer je bronnen: Door binnen je eigen content bronnen te citeren, geef je AI-systemen het signaal dat jouw content goed onderbouwd en geloofwaardig is, wat je eigen kans op citatie vergroot.
Test met AI-tools: Stel regelmatig je doelonderwerpen aan ChatGPT, Perplexity, Gemini en Claude om te zien of jouw content wordt geciteerd en hoe die wordt gepresenteerd.
Monitor prestaties: Volg welke stukken content worden geciteerd, door welke platforms en in welke context, en gebruik deze data om je optimalisatiestrategie te verfijnen.
Contentmakers die deze tactieken toepassen, zien hun citatiegraad binnen 3-6 maanden met 40-60% stijgen, met bijbehorende toename in verwijzingsverkeer en merkauthoriteit.
Citatiemonitoring en -meting
Citaties monitoren is niet langer optioneel—het is essentieel voor inzicht in je zichtbaarheid binnen het door AI aangedreven ontdekkingslandschap. Waarom monitoring belangrijk is, is eenvoudig: je kunt alleen optimaliseren wat je meet, en citaatpatronen veranderen naarmate AI-systemen evolueren en nieuwe platforms ontstaan. Welke metrics je moet volgen zijn citatiefrequentie (hoe vaak je wordt geciteerd), citatieplaatsing (inline versus bronnenlijst), platformverdeling (welke platforms je het meest citeren), vraagcontext (welke onderwerpen jouw citaties triggeren) en verkeersattributie (hoeveel verwijzingsverkeer uit AI-citaties komt).
Kansen identificeren vereist analyse van citatiegaten: onderwerpen waar concurrenten worden geciteerd maar jij niet, platforms waar je ondervertegenwoordigd bent en contenttypes die onderpresteren. Deze analyse onthult concrete optimalisatiedoelen—misschien worden je how-to’s niet geciteerd omdat ze geen schema markup bevatten, of verschijnt je onderzoek niet in Perplexity omdat het niet geschikt is voor inline extractie.
AmICited lost de monitoringuitdaging op door je citaties in ChatGPT, Perplexity, Gemini, Claude en andere grote AI-platforms in real-time te volgen. In plaats van je onderwerpen steeds handmatig te moeten controleren, monitort AmICited automatisch citaatpatronen, waarschuwt je bij nieuwe citaties en biedt concurrentie-benchmarking waarmee je ziet hoe jouw citatieprestaties zich verhouden tot die van concurrenten. Voor contentmakers, marketeers en SEO-professionals verandert AmICited citatiemonitoring van een handmatig, tijdrovend proces in een geautomatiseerd systeem dat direct bruikbare inzichten biedt. In een door AI aangedreven ontdekkingslandschap is inzicht in waar je content wordt geciteerd net zo essentieel als inzicht in je zoekposities—en AmICited maakt dat inzicht op schaal mogelijk.
Veelgestelde vragen
Wat is het verschil tussen model-native en RAG-gebaseerde antwoorden?
Model-native antwoorden komen voort uit patronen die tijdens de training zijn geleerd, terwijl RAG live data ophaalt voordat antwoorden worden gegenereerd. RAG biedt doorgaans betere citaties omdat het antwoorden baseert op specifieke bronnen, waardoor het transparanter en beter te traceren is voor gebruikers en contentmakers.
Waarom citeren sommige AI-platforms bronnen en andere niet?
Verschillende platforms gebruiken verschillende architecturen. Perplexity en Gemini geven prioriteit aan RAG met citaties, terwijl ChatGPT standaard model-native generatie gebruikt, tenzij browsen is ingeschakeld. De keuze weerspiegelt de ontwerpfilosofie en het transparantiebeleid van elk platform.
Hoe beïnvloedt de structuur van content of AI jouw content citeert?
Duidelijke, goed gestructureerde content met directe antwoorden, juiste koppen en schema markup is beter te extraheren door AI-systemen. Content die begint met antwoorden en lijsten en tabellen gebruikt, wordt vaker geciteerd omdat het makkelijker te verwerken en toe te wijzen is door AI.
Welke rol speelt schema markup bij het plaatsen van citaties?
Schema markup helpt AI-systemen de structuur van content en entiteitrelaties te begrijpen, waardoor jouw content eenvoudiger correct kan worden toegeschreven en geciteerd. Een juiste implementatie van schema verhoogt de kans op citatie en helpt AI-systemen de geloofwaardigheid van jouw content te verifiëren.
Kan ik mijn content optimaliseren om te verschijnen in AI-gegenereerde antwoorden?
Ja. Focus op een antwoord-eerst structuur, duidelijke opmaak, feitelijke nauwkeurigheid, betrouwbare bronnen en een correcte implementatie van schema. Monitor je citaties en verbeter op basis van prestatiegegevens je AI-zichtbaarheid continu.
Hoe kan ik bijhouden waar mijn merk verschijnt in AI-gegenereerde antwoorden?
Tools zoals AmICited monitoren je merkvermeldingen in ChatGPT, Perplexity, Google AI Overviews en andere platforms en tonen exact waar en hoe je wordt geciteerd in AI-antwoorden. Dit levert bruikbare inzichten op voor optimalisatie.
Heeft het geciteerd worden door AI invloed op mijn zoekresultaten?
Hoewel AI-citaties niet direct van invloed zijn op Google-rankings, vergroten ze de zichtbaarheid van je merk en autoriteitssignalen. Door AI geciteerd worden kan verkeer opleveren en je online aanwezigheid versterken, wat indirecte SEO-voordelen biedt.
Wat is de relatie tussen traditionele SEO en AI-citatieoptimalisatie?
Ze vullen elkaar aan. Traditionele SEO focust op ranking in zoekresultaten, terwijl AI-citatieoptimalisatie zich richt op verschijnen in AI-gegenereerde antwoorden. Beide zijn belangrijk voor volledige zichtbaarheid in het moderne ontdekkingslandschap.
Monitor je AI-zichtbaarheid op alle platforms
Begrijp precies waar jouw merk verschijnt in AI-gegenereerde antwoorden. Volg citaties in ChatGPT, Perplexity, Google AI Overviews en meer met AmICited.
Positie van Citaties in AI-Antwoorden: Hoe Verschillende AI-platformen Bronnen Vermelden
Ontdek hoe de positie van citaties werkt bij ChatGPT, Perplexity, Google AI Overviews en andere AI-systemen. Begrijp strategieën voor citatieplaatsing en hoe je...
Hoe de Eerste Citatiepositie Bereiken in AI-Antwoorden
Ontdek bewezen strategieën om jouw content als eerste geciteerd te krijgen in door AI gegenereerde antwoorden van ChatGPT, Perplexity en andere AI-zoekmachines....
Wat bepaalt eigenlijk of AI jouw content citeert? Poging tot reverse-engineering van het citatie-algoritme
Community-discussie over hoe AI-modellen bepalen wat ze citeren. Echte ervaringen van SEO'ers die citatiepatronen analyseren bij ChatGPT, Perplexity en Gemini.
8 min lezen
Discussion
AI Citations
+1
Cookie Toestemming We gebruiken cookies om uw browse-ervaring te verbeteren en ons verkeer te analyseren. See our privacy policy.