
AI-crawlers uitgelegd: GPTBot, ClaudeBot en meer
Begrijp hoe AI-crawlers zoals GPTBot en ClaudeBot werken, hun verschillen met traditionele zoekmachine-crawlers en hoe je je site optimaliseert voor AI-zoekzich...
12 min lezen

Leer hoe AI-crawlers invloed hebben op serverresources, bandbreedte en prestaties. Ontdek echte statistieken, strategieën voor mitigatie en infrastructuuroplossingen om botverkeer effectief te beheren.
AI-crawlers zijn een belangrijke kracht geworden in webverkeer, waarbij grote AI-bedrijven geavanceerde bots inzetten om content te indexeren voor trainings- en opvraagdoeleinden. Deze crawlers opereren op enorme schaal en genereren ongeveer 569 miljoen verzoeken per maand wereldwijd en verbruiken meer dan 30TB aan bandbreedte. De belangrijkste AI-crawlers zijn onder andere GPTBot (OpenAI), ClaudeBot (Anthropic), PerplexityBot (Perplexity AI), Google-Extended (Google) en Amazonbot (Amazon), elk met eigen crawlpatronen en resource-eisen. Het begrijpen van het gedrag en de kenmerken van deze crawlers is essentieel voor websitebeheerders om serverresources goed te beheren en weloverwogen beslissingen te nemen over toegangsbeleid.
| Crawlernaam | Bedrijf | Doel | Verzoekpatroon |
|---|---|---|---|
| GPTBot | OpenAI | Trainingsdata voor ChatGPT en GPT-modellen | Agressief, hoge frequentie aanvragen |
| ClaudeBot | Anthropic | Trainingsdata voor Claude AI-modellen | Gemiddelde frequentie, respectvol crawlgedrag |
| PerplexityBot | Perplexity AI | Real-time zoeken en antwoordgeneratie | Gemiddeld tot hoge frequentie |
| Google-Extended | Uitgebreide indexering voor AI-functies | Gecontroleerd, volgt robots.txt | |
| Amazonbot | Amazon | Indexering van producten en content | Variabel, focus op commerce |
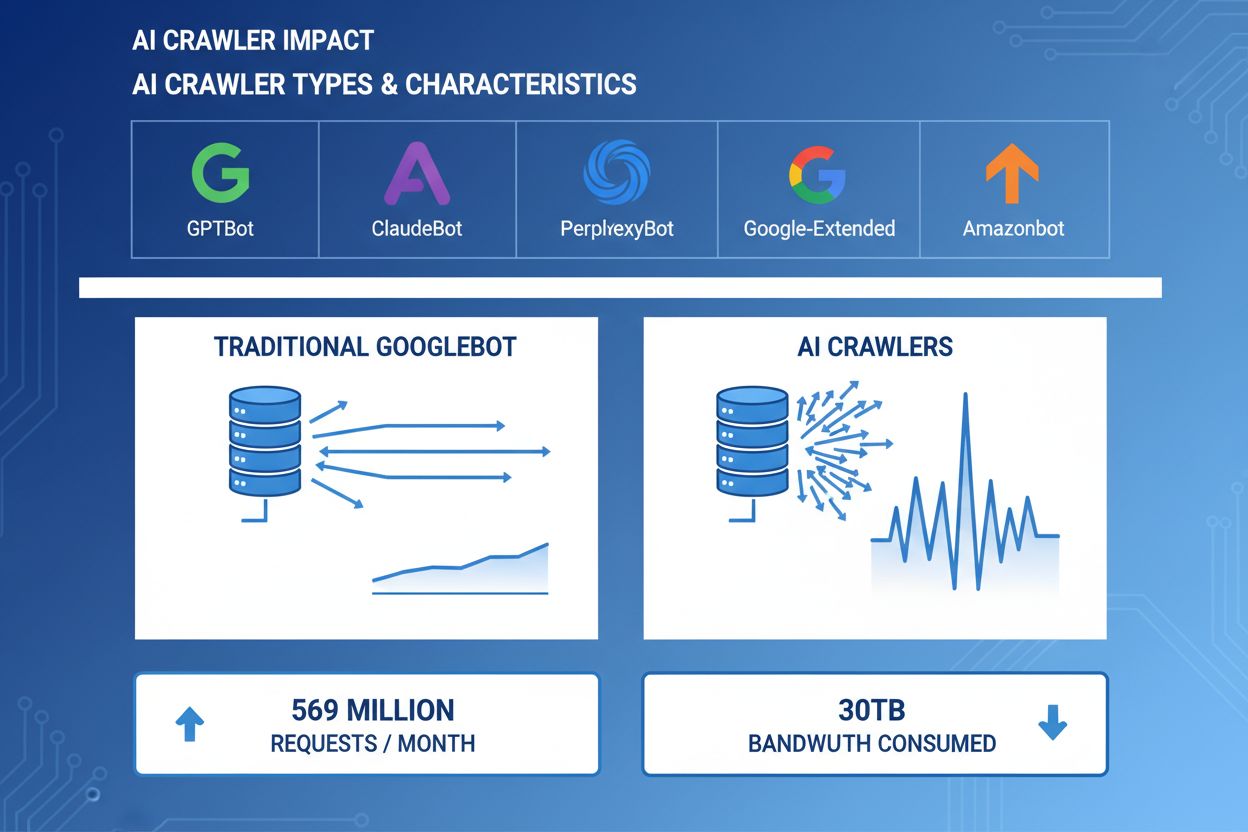
AI-crawlers verbruiken serverresources op meerdere fronten, wat meetbare impact heeft op de infrastructuurprestaties. CPU-gebruik kan met 300% of meer stijgen tijdens piekactiviteit, doordat servers duizenden gelijktijdige verzoeken verwerken en HTML-content parsen. Bandbreedteverbruik is een van de zichtbaarste kosten, waarbij een enkele populaire website dagelijks gigabytes aan data aan crawlers kan serveren. Het geheugengebruik stijgt aanzienlijk omdat servers verbindingen in stand moeten houden en grote hoeveelheden data bufferen voor verwerking. Databasequeries nemen toe doordat crawlers pagina’s opvragen die dynamische contentgeneratie triggeren, wat extra I/O-druk veroorzaakt. Schijf-I/O wordt een knelpunt wanneer servers data van opslag moeten lezen voor crawlerverzoeken, vooral bij sites met grote contentbibliotheken.
| Resource | Impact | Praktijkvoorbeeld |
|---|---|---|
| CPU | 200-300% pieken tijdens drukke crawling | Server load average stijgt van 2.0 naar 8.0 |
| Bandbreedte | 15-40% van het totale maandelijkse gebruik | 500GB-site die 150GB aan crawlers per maand serveert |
| Geheugen | 20-30% toename in RAM-gebruik | 8GB-server die 10GB nodig heeft tijdens crawleractiviteit |
| Database | 2-5x toename in queryload | Queryresponstijden stijgen van 50ms naar 250ms |
| Schijf-I/O | Aanhoudend hoge leesoperaties | Schijfgebruik stijgt van 30% naar 85% |
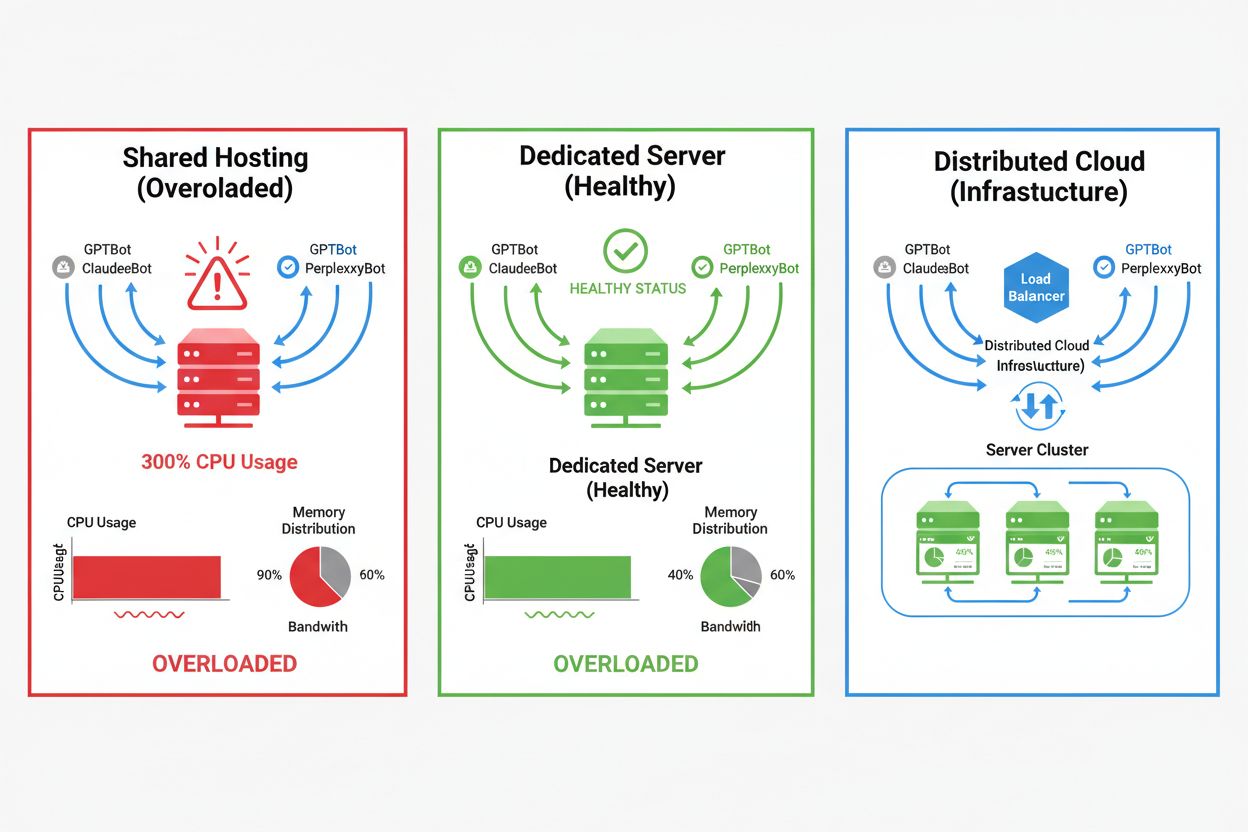
De impact van AI-crawlers verschilt sterk per hostingomgeving, waarbij shared hosting-omgevingen de zwaarste gevolgen ondervinden. In shared hosting wordt het “noisy neighbor syndrome” extra problematisch—wanneer één website op een gedeelde server veel crawlerverkeer aantrekt, verbruikt deze resources die anders voor andere gehoste websites beschikbaar zouden zijn, wat de prestaties voor alle gebruikers verslechtert. Dedicated servers en cloudinfrastructuur bieden betere isolatie en resourcegaranties, zodat u crawlerverkeer kunt opvangen zonder impact op andere diensten. Toch vereisen ook dedicated omgevingen zorgvuldig monitoren en schalen om de cumulatieve belasting van meerdere AI-crawlers aan te kunnen.
Belangrijkste verschillen tussen hostingomgevingen:
De financiële impact van AI-crawlerverkeer reikt verder dan alleen bandbreedtekosten en omvat zowel directe als verborgen uitgaven die uw bedrijfsresultaat aanzienlijk kunnen beïnvloeden. Directe kosten zijn onder meer hogere bandbreedtefacturen van uw hostingprovider, die honderden tot duizenden euro’s per maand kunnen bedragen afhankelijk van het verkeersvolume en de intensiteit van crawlers. Verborgen kosten ontstaan door extra infrastructuurbehoeften—u moet mogelijk upgraden naar duurdere hostingpakketten, extra cachinglagen implementeren of investeren in CDN-diensten speciaal om crawlerverkeer op te vangen. De ROI-berekening wordt complex als u bedenkt dat AI-crawlers weinig directe waarde voor uw bedrijf bieden, maar wel resources verbruiken die beter ingezet kunnen worden voor betalende klanten of een betere gebruikerservaring. Veel website-eigenaren constateren dat de kosten van het faciliteren van crawlerverkeer hoger uitvallen dan de potentiële voordelen van AI-modeltraining of zichtbaarheid in AI-zoekresultaten.
AI-crawlerverkeer verslechtert de gebruikerservaring voor legitieme bezoekers direct, doordat serverresources worden opgeslokt die anders menselijke gebruikers sneller zouden bedienen. Core Web Vitals-metrics lijden zichtbaar, met een Largest Contentful Paint (LCP) die met 200-500ms toeneemt en een Time to First Byte (TTFB) die 100-300ms verslechtert tijdens periodes van hoge crawleractiviteit. Deze prestatieverminderingen veroorzaken een reeks negatieve gevolgen: tragere laadtijden verminderen gebruikersbetrokkenheid, verhogen het bouncepercentage en verlagen uiteindelijk de conversieratio’s voor e-commerce en leadgeneratiesites. Zoekmachinerankings lijden eveneens, aangezien Google’s algoritme Core Web Vitals meeneemt als rankingfactor, waardoor crawlerverkeer indirect uw SEO-prestaties schaadt. Gebruikers die langzame laadtijden ervaren, verlaten uw site sneller en gaan naar de concurrent, wat direct invloed heeft op omzet en reputatie.
Effectief beheer van AI-crawlerverkeer begint met volledige monitoring en detectie, zodat u de omvang van het probleem begrijpt voordat u maatregelen neemt. De meeste webservers loggen user-agent strings die de crawler achter elk verzoek identificeren en zo de basis vormen voor verkeersanalyse en filterbeslissingen. Serverlogs, analyticsplatforms en gespecialiseerde monitoringtools kunnen deze user-agents uitlezen om crawlerpatronen te identificeren en te kwantificeren.
Belangrijkste detectiemethoden en tools:
De eerste verdedigingslinie tegen overmatig AI-crawlerverkeer is een goed geconfigureerd robots.txt-bestand waarmee u crawlertoegang tot uw website expliciet regelt. Dit eenvoudige tekstbestand, geplaatst in de root van uw website, stelt u in staat specifieke crawlers te weren, crawlfrequentie te beperken en crawlers naar een sitemap te leiden met alleen de content die u wilt laten indexeren. Rate limiting op applicatie- of serverniveau biedt een extra beschermingslaag, door verzoeken van bepaalde IP’s of user-agents af te remmen en zo resource-uitputting te voorkomen. Deze strategieën zijn niet-blokkerend en omkeerbaar, waardoor ze ideaal zijn als eerste stap voordat u strengere maatregelen neemt.
# robots.txt - Blokkeer AI-crawlers, sta legitieme zoekmachines toe
User-agent: GPTBot
Disallow: /
User-agent: ClaudeBot
Disallow: /
User-agent: PerplexityBot
Disallow: /
User-agent: Amazonbot
Disallow: /
User-agent: CCBot
Disallow: /
# Sta Google en Bing toe
User-agent: Googlebot
Allow: /
User-agent: Bingbot
Allow: /
# Crawl delay voor alle andere bots
User-agent: *
Crawl-delay: 10
Request-rate: 1/10s
Web Application Firewalls (WAF) en Content Delivery Networks (CDN) bieden geavanceerde, zakelijke bescherming tegen ongewenst crawlerverkeer door gedragsanalyse en intelligente filtering. Cloudflare en vergelijkbare CDN-aanbieders beschikken over ingebouwde botmanagementfuncties die AI-crawlers kunnen identificeren en blokkeren op basis van gedragspatronen, IP-reputatie en verzoekkenmerken—zonder handmatige configuratie. WAF-regels kunnen worden ingesteld om verdachte verzoeken uit te dagen, specifieke user-agents te rate-limiten of verkeer van bekende crawler-IP-reeksen volledig te blokkeren. Deze oplossingen werken aan de edge, filteren kwaadaardig verkeer voordat het uw origin server bereikt en verminderen zo de belasting van uw infrastructuur aanzienlijk. Het voordeel van WAF- en CDN-oplossingen is hun vermogen zich aan te passen aan nieuwe crawlers en veranderende aanvalspatronen zonder dat u handmatig uw configuratie hoeft bij te werken.
Beslissen of u AI-crawlers blokkeert, vereist een zorgvuldige afweging tussen het beschermen van uw serverresources en het behouden van zichtbaarheid in AI-aangedreven zoekresultaten en applicaties. Door alle AI-crawlers te blokkeren, voorkomt u dat uw content verschijnt in ChatGPT-zoekresultaten, Perplexity AI-antwoorden of andere AI-ontdekkingsmechanismen, wat mogelijk leidt tot minder verwijzingsverkeer en minder merkzichtbaarheid. Anderzijds leidt onbeperkte crawlertoegang tot aanzienlijk resourceverbruik en kan het de gebruikerservaring verslechteren zonder merkbare voordelen voor uw bedrijf. De optimale strategie hangt af van uw situatie: drukbezochte websites met ruime middelen kunnen crawlers toestaan, terwijl sites met beperkte middelen de gebruikerservaring voorop moeten stellen door crawlers te blokkeren of te beperken. Strategische keuzes moeten worden afgestemd op uw branche, doelgroep, contenttype en bedrijfsdoelen in plaats van een standaardaanpak te volgen.
Voor websites die ervoor kiezen AI-crawlerverkeer toe te staan, biedt infrastructuurschaling een manier om prestaties te behouden bij een toenemende belasting. Verticaal schalen—upgraden naar servers met meer CPU, RAM en bandbreedte—is een eenvoudige maar dure oplossing die uiteindelijk fysieke grenzen bereikt. Horizontaal schalen—het verdelen van verkeer over meerdere servers met load balancers—biedt op de lange termijn betere schaalbaarheid en veerkracht. Cloudinfrastructuren zoals AWS, Google Cloud en Azure bieden autoscaling-mogelijkheden die automatisch extra resources inzetten bij verkeerspieken en weer afschalen in rustige periodes om kosten te beperken. Content Delivery Networks (CDN) kunnen statische content cachen op edge-locaties, waardoor de belasting op uw origin server afneemt en de prestaties verbeteren voor zowel menselijke gebruikers als crawlers. Database-optimalisatie, querycaching en applicatiespecifieke verbeteringen kunnen het resourcegebruik per verzoek verder verminderen, zodat u efficiënter werkt zonder extra infrastructuur.
Voortdurende monitoring en optimalisatie zijn essentieel om optimale prestaties te behouden in het licht van aanhoudend AI-crawlerverkeer. Gespecialiseerde tools bieden inzicht in crawleractiviteit, resourcegebruik en prestatiestatistieken, waarmee u datagedreven beslissingen kunt nemen over crawlerbeheer. Door van begin af aan uitgebreide monitoring te implementeren, legt u baselines vast, identificeert u trends en meet u de effectiviteit van mitigatiestrategieën in de loop van de tijd.
Essentiële monitoringtools en -praktijken:
Het landschap van AI-crawlerbeheer blijft zich ontwikkelen, met opkomende standaarden en branche-initiatieven die bepalen hoe websites en AI-bedrijven met elkaar omgaan. De llms.txt-standaard is een opkomende aanpak om AI-bedrijven gestructureerde informatie te bieden over gebruiksrechten en voorkeuren rond content, wat mogelijk een genuanceerder alternatief biedt voor alles blokkeren of alles toestaan. Discussies in de branche over compensatiemodellen suggereren dat AI-bedrijven in de toekomst mogelijk betalen voor toegang tot trainingsdata, wat de economie van crawlerverkeer fundamenteel kan veranderen. Om uw infrastructuur toekomstbestendig te maken, is het belangrijk op de hoogte te blijven van nieuwe standaarden, brancheontwikkelingen te volgen en flexibiliteit in uw crawlerbeleid te behouden. Relaties opbouwen met AI-bedrijven, deelnemen aan branchegesprekken en pleiten voor eerlijke compensatiemodellen wordt steeds belangrijker nu AI centraler komt te staan in webontdekking en contentconsumptie. De websites die in dit veranderende landschap floreren, zijn zij die innovatie en pragmatisme in balans brengen: hun resources beschermen én openstaan voor legitieme kansen op zichtbaarheid en samenwerking.
AI-crawlers (GPTBot, ClaudeBot) halen content op voor LLM-training zonder noodzakelijkerwijs verkeer terug te sturen. Zoekcrawlers (Googlebot) indexeren content voor zichtbaarheid in zoekopdrachten en sturen doorgaans wel verwijzingsverkeer. AI-crawlers werken agressiever met grotere batchverzoeken en negeren vaak richtlijnen voor bandbreedtebesparing.
Praktijkvoorbeelden tonen meer dan 30TB per maand van één enkele crawler. Verbruik hangt af van de grootte van de site, de hoeveelheid content en crawlerfrequentie. Alleen OpenAI's GPTBot genereerde 569 miljoen verzoeken in één maand op Vercel's netwerk.
Het blokkeren van AI-trainingscrawlers (GPTBot, ClaudeBot) heeft geen invloed op Google-rankings. Het blokkeren van AI-zoekcrawlers kan echter de zichtbaarheid verminderen in AI-aangedreven zoekresultaten zoals Perplexity of ChatGPT search.
Let op onverklaarde CPU-pieken (300%+), verhoogd bandbreedtegebruik zonder meer menselijke bezoekers, tragere laadtijden van pagina's en ongebruikelijke user-agent strings in serverlogs. Core Web Vitals-metrics kunnen ook aanzienlijk achteruitgaan.
Voor sites met aanzienlijk crawlerverkeer biedt dedicated hosting betere resource-isolatie, controle en kostenvoorspelbaarheid. Shared hosting-omgevingen hebben last van 'noisy neighbor syndrome', waarbij het crawlerverkeer van één site alle gehoste sites beïnvloedt.
Gebruik Google Search Console voor Googlebot-data, servertoegangslogs voor gedetailleerde verkeersanalyse, CDN-analytics (Cloudflare) en gespecialiseerde platforms zoals AmICited.com voor uitgebreide monitoring en tracking van AI-crawlers.
Ja, via robots.txt-directieven, WAF-regels en IP-gebaseerde filtering. U kunt nuttige crawlers zoals Googlebot toestaan en resource-intensieve AI-trainingscrawlers blokkeren met user-agent specifieke regels.
Vergelijk servermetrics vóór en na het implementeren van crawlercontroles. Monitor Core Web Vitals (LCP, TTFB), paginalaadtijden, CPU-gebruik en gebruikerservaringsmetrics. Tools zoals Google PageSpeed Insights en servermonitoringsplatforms geven gedetailleerd inzicht.
Krijg realtime inzicht in hoe AI-modellen uw content benaderen en impact hebben op uw serverresources met AmICited's gespecialiseerde monitoringsplatform.
Begrijp hoe AI-crawlers zoals GPTBot en ClaudeBot werken, hun verschillen met traditionele zoekmachine-crawlers en hoe je je site optimaliseert voor AI-zoekzich...

Ontdek hoe je strategische beslissingen neemt over het blokkeren van AI-crawlers. Evalueer inhoudstype, verkeersbronnen, verdienmodellen en concurrentiepositie ...

Leer hoe je AI-crawlers zoals GPTBot, PerplexityBot en ClaudeBot kunt identificeren en monitoren in je serverlogs. Ontdek user-agent strings, IP-verificatiemeth...
Cookie Toestemming
We gebruiken cookies om uw browse-ervaring te verbeteren en ons verkeer te analyseren. See our privacy policy.