
Welke AI-crawlers moet ik toegang geven? Complete gids voor 2025
Ontdek welke AI-crawlers je moet toestaan of blokkeren in je robots.txt. Uitgebreide gids over GPTBot, ClaudeBot, PerplexityBot en 25+ AI-crawlers met configura...
10 min lezen

Ontdek de cruciale verschillen tussen AI-trainingscrawlers en zoekcrawlers. Leer hoe ze de zichtbaarheid van je content, optimalisatiestrategieën en AI-vermeldingen beïnvloeden.
Zoekmachinecrawlers zoals Googlebot en Bingbot vormen de ruggengraat van traditionele zoekmachine-operaties. Deze geautomatiseerde bots navigeren systematisch over het web, ontdekken en indexeren content om te bepalen wat er verschijnt in zoekresultatenpagina’s (SERP’s). Googlebot, van Google, is de bekendste en meest actieve zoekcrawler, gevolgd door Bingbot van Microsoft en YandexBot van Yandex. Deze crawlers beschikken over geavanceerde mogelijkheden waarmee ze JavaScript kunnen uitvoeren, dynamische content kunnen renderen en complexe websitestructuren begrijpen. Ze bezoeken websites vaak op basis van factoren als siteautoriteit, actualiteit van de content en updategeschiedenis, waarbij sites met hoge autoriteit vaker worden gecrawld. Het primaire doel van zoekcrawlers is het indexeren van content voor rankingdoeleinden, wat betekent dat ze pagina’s beoordelen op relevantie, kwaliteit en gebruikerservaring.
| Crawler Type | Primair doel | JavaScript-ondersteuning | Crawlfrequentie | Doel |
|---|---|---|---|---|
| Googlebot | Indexeren voor zoekrangschikkingen | Ja (met beperkingen) | Vaak, op basis van autoriteit | Ranking & zichtbaarheid |
| Bingbot | Indexeren voor zoekrangschikkingen | Ja (met beperkingen) | Regelmatig, op basis van contentupdates | Ranking & zichtbaarheid |
| YandexBot | Indexeren voor zoekrangschikkingen | Ja (met beperkingen) | Regelmatig, op basis van sitesignalen | Ranking & zichtbaarheid |
AI-trainingscrawlers vormen een fundamenteel andere categorie webbots die zijn ontworpen om data te verzamelen voor het trainen van grote taalmodellen (LLM’s), in plaats van voor zoekindexering. GPTBot, van OpenAI, is de bekendste AI-trainingscrawler, samen met ClaudeBot van Anthropic, PetalBot van Huawei en CCBot van Common Crawl. In tegenstelling tot zoekcrawlers die content willen ranken, richten AI-trainingscrawlers zich op het verzamelen van hoogwaardige, contextueel rijke informatie om de kennis en antwoordmogelijkheden van AI-modellen te verbeteren. Deze crawlers werken doorgaans minder frequent dan zoekcrawlers, bezoeken een website vaak slechts eens per paar weken of maanden, en geven prioriteit aan kwaliteit boven kwantiteit. Het onderscheid is cruciaal: terwijl je content grondig geïndexeerd kan zijn door Googlebot voor zoekzichtbaarheid, kan het slechts gedeeltelijk of zelden gecrawld worden door GPTBot voor AI-training.
| Crawler Type | Primair doel | JavaScript-ondersteuning | Crawlfrequentie | Doel |
|---|---|---|---|---|
| GPTBot | Data verzamelen voor LLM-training | Nee | Infrequent, selectief | Trainingsdatakwaliteit |
| ClaudeBot | Data verzamelen voor LLM-training | Nee | Infrequent, selectief | Trainingsdatakwaliteit |
| PetalBot | Data verzamelen voor LLM-training | Nee | Infrequent, selectief | Trainingsdatakwaliteit |
| CCBot | Data verzamelen voor Common Crawl | Nee | Infrequent, selectief | Trainingsdatakwaliteit |
De technische verschillen tussen zoek- en AI-trainingscrawlers hebben grote gevolgen voor de zichtbaarheid van content. Het grootste verschil is JavaScript-uitvoering: zoekcrawlers zoals Googlebot kunnen JavaScript uitvoeren (zij het met beperkingen), waardoor ze dynamisch weergegeven content kunnen zien. AI-trainingscrawlers voeren daarentegen helemaal geen JavaScript uit—ze lezen alleen de ruwe HTML die beschikbaar is bij het laden van de pagina. Dit fundamentele verschil betekent dat content die dynamisch via client-side scripts wordt geladen volledig onzichtbaar blijft voor AI-crawlers. Daarnaast respecteren zoekcrawlers crawlbudgetten en geven ze prioriteit aan pagina’s op basis van sitearchitectuur en interne links, terwijl AI-crawlers selectiever en meer kwaliteitsgericht crawlen. Zoekcrawlers volgen doorgaans strikt de robots.txt-regels, terwijl sommige AI-crawlers historisch gezien minder transparant zijn over hun naleving. De crawlfrequentie verschilt sterk: zoekcrawlers bezoeken actieve sites meerdere keren per week of zelfs dagelijks, terwijl AI-trainingscrawlers mogelijk slechts eens per paar weken of maanden langskomen. Verder zijn zoekcrawlers ontworpen om rankingsignalen en gebruikerservaring te begrijpen, terwijl AI-crawlers zich richten op het extraheren van schone, goed gestructureerde tekst voor modeltraining.
| Kenmerk | Zoekcrawlers | AI-trainingscrawlers |
|---|---|---|
| JavaScript-uitvoering | Ja (met beperkingen) | Nee |
| Crawlfrequentie | Hoog (meerdere keren per week) | Laag (eens per paar weken) |
| Content parsing | Volledige paginarendering | Alleen ruwe HTML |
| Robots.txt-naleving | Strikt | Variabel |
| Crawlbudget focus | Prioriteit op basis van autoriteit | Selectie op basis van kwaliteit |
| Omgaan met dynamische content | Kan renderen en indexeren | Mist volledig |
| Primair doel | Ranking & zoekzichtbaarheid | Trainingsdataverzameling |
| Timeout-tolerantie | Langer (staat complexe rendering toe) | Strak (1-5 seconden) |
Het onvermogen van AI-crawlers om JavaScript uit te voeren veroorzaakt een kritische zichtbaarheidskloof die veel moderne websites treft. Wanneer een website JavaScript gebruikt om content dynamisch te laden—zoals productbeschrijvingen, klantbeoordelingen, prijsinformatie of afbeeldingen—blijft die content onzichtbaar voor AI-crawlers. Dit is vooral problematisch voor single-page applicaties (SPA’s) gebouwd met React, Vue of Angular, waar de meeste content pas na de initiële HTML-client-side wordt geladen. Een e-commercesite kan bijvoorbeeld productbeschikbaarheid en prijzen via JavaScript tonen, waardoor GPTBot alleen een lege pagina of een basis-HTML-skelet ziet. Evenzo zullen websites die lazy-loading voor afbeeldingen of infinite scroll voor content gebruiken deze elementen volledig missen voor AI-crawlers. De zakelijke impact is aanzienlijk: als je productdetails, klantentests of belangrijke content verborgen zijn achter JavaScript, hebben AI-systemen zoals ChatGPT en Perplexity geen toegang tot deze informatie bij het genereren van antwoorden. Zo kan je content goed scoren in Google, maar volledig ontbreken in AI-gegenereerde antwoorden, waardoor je onzichtbaar bent voor een groeiende groep gebruikers die op AI vertrouwen voor informatie.
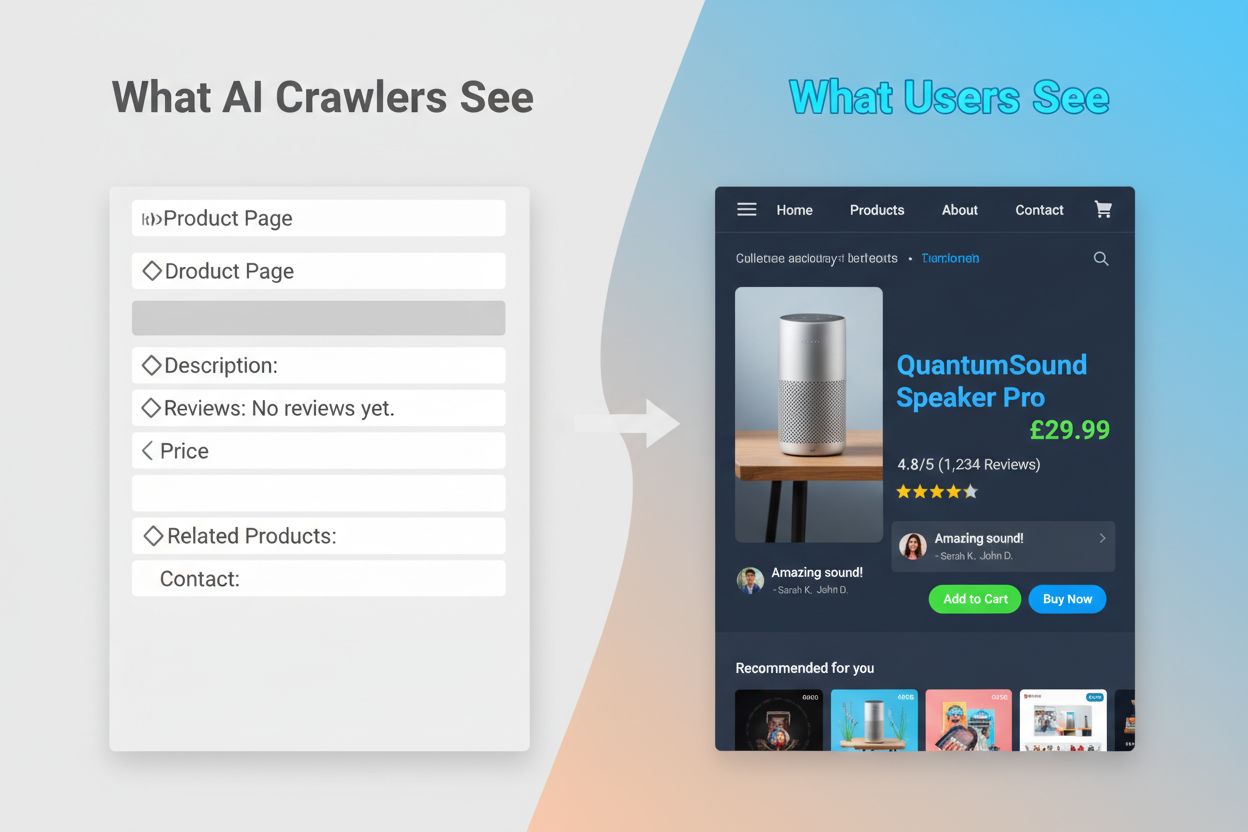
De praktische gevolgen van deze technische verschillen zijn groot en worden vaak onderschat door website-eigenaren. Je website kan uitstekend scoren in Google, terwijl je tegelijkertijd vrijwel onzichtbaar bent voor ChatGPT, Perplexity en andere AI-systemen. Dit creëert een paradoxale situatie waarin traditioneel SEO-succes geen AI-zichtbaarheid garandeert. Wanneer gebruikers ChatGPT iets vragen over jouw branche of product, kan het AI-systeem je concurrenten noemen in plaats van jou, puur omdat hun content toegankelijker was voor AI-crawlers. De relatie tussen trainingsdata en zoekcitaten voegt nog een extra laag complexiteit toe: content die is gebruikt voor het trainen van een AI-model kan een voorkeursbehandeling krijgen in de zoekresultaten van dat model, waardoor het blokkeren van AI-trainingscrawlers je zichtbaarheid in AI-gegenereerde antwoorden mogelijk vermindert. Voor uitgevers en contentmakers betekent dit dat de strategische keuze om AI-crawlers toe te staan of te blokkeren echte gevolgen heeft voor toekomstig verkeer. Een website die GPTBot blokkeert om content te beschermen tegen training, verkleint tegelijkertijd de kans om in ChatGPT’s zoekresultaten te verschijnen. Omgekeerd levert het toestaan van AI-crawlers trainingsdata, maar geen garantie op vermelding of verkeer, wat een echt strategisch dilemma vormt zonder perfecte oplossing.
Begrijpen welke crawlers je website bezoeken en hoe vaak ze langskomen is essentieel voor het optimaliseren van je contentstrategie. Logbestand-analyse is de belangrijkste methode om crawleractiviteit te identificeren, waarmee je serverlogs kunt segmenteren en analyseren om te zien welke bots je site bezochten, hoe vaak en welke pagina’s ze prioriteerden. Door User-Agent-strings in je serverlogs te bekijken, kun je onderscheid maken tussen Googlebot, GPTBot, OAI-SearchBot en andere crawlers, en zo hun gedragspatronen blootleggen. Belangrijke statistieken om te monitoren zijn crawlfrequentie (hoe vaak elke crawler langskomt), crawldiepte (hoeveel lagen van je sitestructuur worden gecrawld) en crawlbudget (het totale aantal gecrawlde pagina’s in een bepaalde periode). Tools zoals Google Search Console en Bing Webmaster Tools bieden inzicht in zoekcrawleractiviteit, terwijl gespecialiseerde oplossingen zoals AmICited.com uitgebreide monitoring bieden van AI-crawlergedrag op meerdere platforms waaronder ChatGPT, Perplexity en Google AI Overviews. AmICited.com volgt specifiek hoe AI-systemen je merk en content noemen, en geeft inzicht in welke AI-platforms je vermelden en hoe vaak. Door deze patronen te begrijpen kun je technische problemen vroegtijdig signaleren, je crawlbudget optimaliseren en weloverwogen beslissingen nemen over crawler-toegang en contentoptimalisatie.
Optimaliseren voor traditionele zoekcrawlers vereist focus op bewezen technische SEO-principes die je content vindbaar en indexeerbaar maken. De volgende strategieën zijn essentieel om sterke zoekzichtbaarheid te behouden:
Zoekmachines zoals Google richten zich steeds meer op crawlefficiëntie, waarbij Google vertegenwoordigers aangeven dat Googlebot in de toekomst minder zal crawlen. Dat betekent dat je website zo gestroomlijnd en begrijpelijk mogelijk moet zijn, met heldere hiërarchieën en efficiënte interne links die crawlers direct naar je belangrijkste pagina’s leiden.
Optimaliseren voor AI-trainingscrawlers vraagt om een andere aanpak, gericht op contentkwaliteit, duidelijkheid en toegankelijkheid, niet op rankingsignalen. Omdat AI-crawlers waarde hechten aan goed gestructureerde, contextueel rijke content, moet je optimalisatiestrategie inzetten op volledigheid en leesbaarheid. Vermijd JavaScript-afhankelijke content voor essentiële informatie—zorg dat productdetails, prijzen, reviews en kerngegevens aanwezig zijn in ruwe HTML zodat AI-crawlers erbij kunnen. Maak uitgebreide, diepgaande content die onderwerpen grondig behandelt en context biedt waar AI-modellen van kunnen leren. Gebruik duidelijke opmaak met koppen, opsommingstekens en genummerde lijsten zodat content gemakkelijk te parseren is. Schrijf semantisch helder, met begrijpelijke taal en zonder overmatig jargon dat AI-modellen kan verwarren. Implementeer een goede koppenhiërarchie (H1, H2, H3) zodat AI-crawlers de structuur en relaties in je content begrijpen. Voeg relevante metadata en schema markup toe die context geeft over je content. Zorg voor snelle paginalaadtijden, want AI-crawlers hebben strakke time-outs (meestal 1-5 seconden) en kunnen trage pagina’s volledig overslaan.
Het belangrijkste verschil met zoekoptimalisatie is dat AI-crawlers niet letten op rankingsignalen, backlinks of keyworddichtheid. Ze waarderen duidelijk gestructureerde, rijk informatieve content. Een pagina die misschien niet goed scoort in Google kan juist heel waardevol zijn voor AI-modellen als deze uitgebreide, goed gestructureerde informatie biedt over een onderwerp.
Het landschap van webcrawling verandert snel, waarbij AI-crawlers steeds belangrijker worden voor contentzichtbaarheid en merkbekendheid. Nu AI-zoektools zoals ChatGPT, Perplexity en Google AI Overviews steeds meer worden gebruikt, wordt vindbaar en citeerbaar zijn door deze systemen net zo belangrijk als traditionele zoekrangschikkingen. Het onderscheid tussen trainingscrawlers en zoekcrawlers zal waarschijnlijk subtieler worden, waarbij bedrijven mogelijk een duidelijker scheiding maken tussen dataverzameling en zoekopvraging, vergelijkbaar met de aanpak van OpenAI met GPTBot en OAI-SearchBot. Website-eigenaren zullen strategieën moeten ontwikkelen die traditionele SEO optimalisatie en AI-zichtbaarheid in balans brengen, beseffend dat deze elkaar aanvullen in plaats van beconcurreren. De opkomst van gespecialiseerde monitoringtools en oplossingen maakt het eenvoudiger om crawleractiviteit te volgen op zowel traditionele als AI-platforms, waardoor datagedreven beslissingen mogelijk zijn over crawler-toegang en contentoptimalisatie. Vroege adopters die nu optimaliseren voor zowel zoek- als AI-crawlers, zullen een concurrentievoordeel behalen en hun content vindbaar maken via meerdere kanalen terwijl het zoeklandschap blijft veranderen. De toekomst van contentzichtbaarheid hangt af van begrijpen en optimaliseren voor het volledige spectrum aan crawlers die je content ontdekken en gebruiken.
Zoekcrawlers zoals Googlebot indexeren content voor zoekrangschikkingen en kunnen JavaScript uitvoeren om dynamische content te zien. AI-trainingscrawlers zoals GPTBot verzamelen data om LLM's te trainen en kunnen doorgaans geen JavaScript uitvoeren, waardoor ze dynamisch geladen content missen. Dit fundamentele verschil betekent dat je website goed kan scoren in Google, maar vrijwel onzichtbaar is voor ChatGPT.
Ja, je kunt robots.txt gebruiken om specifieke AI-crawlers zoals GPTBot te blokkeren en zoekcrawlers toe te staan. Dit kan echter je zichtbaarheid in AI-gegenereerde antwoorden en samenvattingen verminderen. De strategische afweging hangt af van of je contentbescherming belangrijker vindt dan mogelijk AI-verkeersverwijzingen.
AI-crawlers zoals GPTBot lezen alleen de ruwe HTML bij het laden van de pagina en voeren geen JavaScript uit. Content die dynamisch via scripts wordt geladen—zoals productdetails, reviews of afbeeldingen—blijft voor hen volledig onzichtbaar. Dit is een belangrijke beperking voor moderne websites die sterk afhankelijk zijn van client-side rendering.
AI-trainingscrawlers bezoeken doorgaans minder vaak dan zoekcrawlers, met langere tussenpozen. Ze geven prioriteit aan content met hoge autoriteit en crawlen een pagina mogelijk slechts eens per paar weken of maanden. Dit infrequente crawlen weerspiegelt hun focus op kwaliteit boven kwantiteit.
Productdetails, klantbeoordelingen, lazy-loaded afbeeldingen, interactieve elementen (tabs, carrousels, modals), prijsinformatie en alle content die verborgen is achter JavaScript zijn het meest kwetsbaar. Voor ecommerce- en SPA-websites kan dit een aanzienlijk deel van de cruciale content zijn.
Zorg dat belangrijke content aanwezig is in ruwe HTML, verbeter de snelheid van je site, gebruik een duidelijke structuur en opmaak met goede koppen-hiërarchie, implementeer schema markup en vermijd cruciale content die afhankelijk is van JavaScript. Het doel is om je content toegankelijk te maken voor zowel traditionele als AI-crawlers.
Logbestand-analysetools, Google Search Console, Bing Webmaster Tools en gespecialiseerde crawler monitoring oplossingen zoals AmICited.com kunnen helpen om crawlergedrag te volgen. AmICited.com monitort specifiek hoe AI-systemen je merk noemen in ChatGPT, Perplexity en Google AI Overviews.
Dat kan. Hoewel het blokkeren van trainingscrawlers je content kan beschermen, kan het ook je zichtbaarheid in AI-aangedreven zoekresultaten en samenvattingen verminderen. Bovendien blijft content die al gecrawld is vóór het blokkeren aanwezig in getrainde modellen. De keuze vereist een balans tussen contentbescherming en mogelijk verlies van AI-gedreven vindbaarheid.
Volg hoe AI-systemen je merk noemen in ChatGPT, Perplexity en Google AI Overviews. Krijg realtime inzicht in je AI-zichtbaarheid en optimaliseer je contentstrategie.
Ontdek welke AI-crawlers je moet toestaan of blokkeren in je robots.txt. Uitgebreide gids over GPTBot, ClaudeBot, PerplexityBot en 25+ AI-crawlers met configura...

Begrijp hoe AI-crawlers zoals GPTBot en ClaudeBot werken, hun verschillen met traditionele zoekmachine-crawlers en hoe je je site optimaliseert voor AI-zoekzich...
Leer hoe je AI-crawlers zoals GPTBot, PerplexityBot en ClaudeBot kunt identificeren en monitoren in je serverlogs. Ontdek user-agent strings, IP-verificatiemeth...
Cookie Toestemming
We gebruiken cookies om uw browse-ervaring te verbeteren en ons verkeer te analyseren. See our privacy policy.