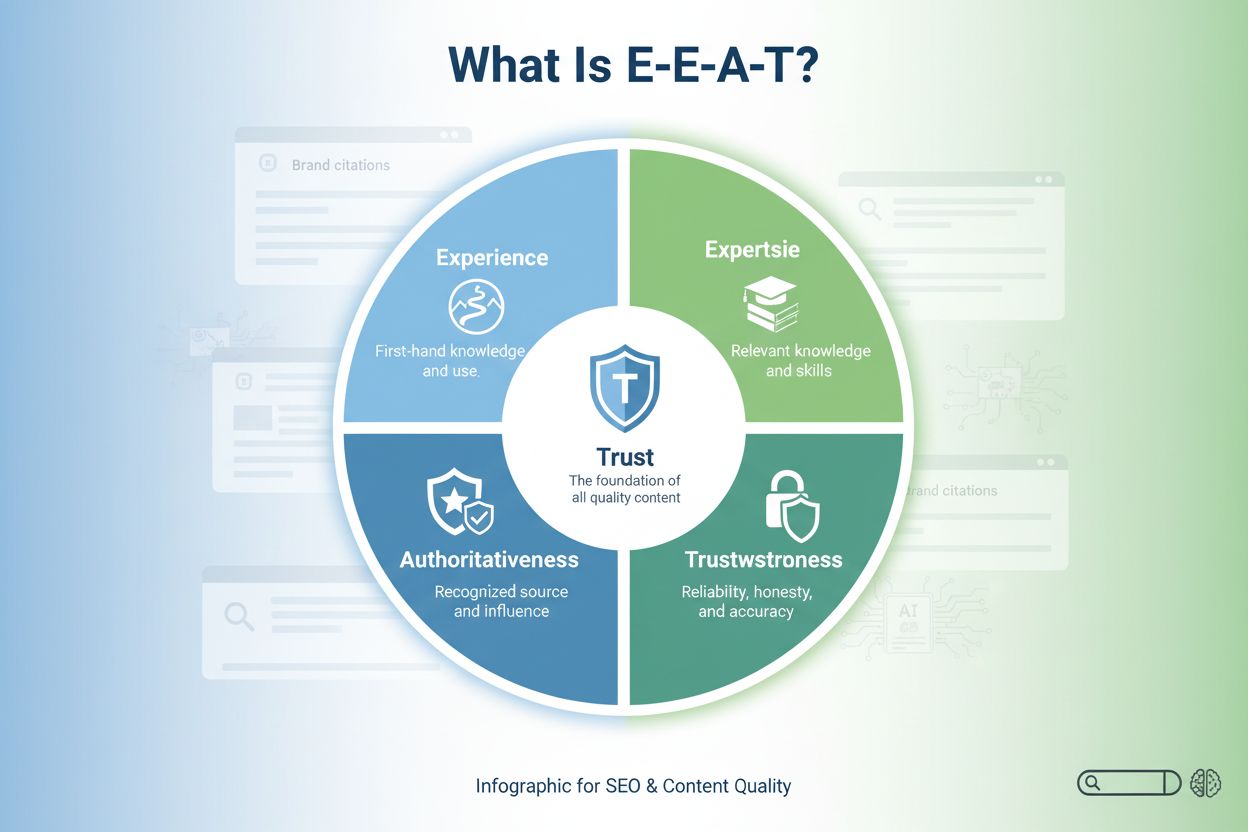
E-E-A-T (Ervaring, Expertise, Autoriteit, Betrouwbaarheid)
E-E-A-T (Ervaring, Expertise, Autoriteit, Betrouwbaarheid) is het kader van Google voor het beoordelen van contentkwaliteit. Leer hoe dit invloed heeft op SEO, ...
14 min lezen

Leer hoe je eerstehandse kennis en ervaringssignalen aantoont aan AI-systemen zoals ChatGPT, Perplexity en Google AI Overviews. Optimaliseer je content voor AI-citaties en zichtbaarheid.
Het E-E-A-T-framework van Google onderging een belangrijke evolutie in december 2022 toen Ervaring naar de eerste positie werd verheven, waardoor het acroniem veranderde van E-A-T naar E-E-A-T. Deze verschuiving weerspiegelt een fundamentele verandering in hoe zoekalgoritmes—en daarmee ook grote taalmodellen—de geloofwaardigheid van content beoordelen. Ervaring betekent in deze context eerstehandse kennis, directe betrokkenheid en geleefde ervaring in plaats van louter theoretisch begrip. AI-systemen erkennen steeds meer dat iemand die daadwerkelijk iets heeft gedaan, een unieke geloofwaardigheid heeft die niet te evenaren is door iemand die er alleen maar over weet. Voor merken en contentmakers betekent dit dat het aantonen van directe betrokkenheid en praktische ervaring essentieel is geworden voor zichtbaarheid op ChatGPT, Perplexity, Google AI Overviews en andere AI-gedreven platforms die AmICited monitort.
Grote taalmodellen gebruiken geavanceerde patroonherkenning om authentieke eerstehandse ervaringssignalen in content te identificeren. Deze systemen analyseren meerdere taalkundige en contextuele indicatoren die echte ervaring onderscheiden van informatie uit tweede hand of AI-gegenereerde content. LLM’s detecteren ervaring via eerste persoonsvoornaamwoorden en verhalende stem, specifieke meetbare details en cijfers, emotionele context en authentieke reacties, praktische inzichten en geleerde lessen, en semantische rijkdom die diepe vertrouwdheid aangeeft. De volgende tabel laat zien hoe verschillende ervaringssignalen worden herkend en geïnterpreteerd:
| Signaaltype | Hoe LLM’s het detecteren | Voorbeeld |
|---|---|---|
| Specifieke cijfers en data | Patroonherkenning voor meetbare resultaten gekoppeld aan persoonlijke actie | “Ik heb mijn conversieratio verhoogd van 2,3% naar 7,8% door…” |
| Temporele progressie | Herkennen van voor/na-verhalen en leercurves | “Toen ik begon, maakte ik fout X. Na zes maanden testen…” |
| Zintuiglijke en emotionele details | Detectie van levendige beschrijvingen die directe observatie aanduiden | “De interface voelde onhandig aan en gebruikers klaagden voortdurend over…” |
| Faalverhalen | Identificatie van eerlijke fouten en geleerde lessen | “Ik probeerde aanvankelijk aanpak A, die mislukte omdat…” |
| Contextuele specificiteit | Herkennen van vakspecifieke termen die natuurlijk gebruikt worden | “Door API rate limiting moesten we queue management implementeren…” |
| Iteratieve verfijning | Detectie van meerdere pogingen en optimalisatiepatronen | “Versie 1 werkte niet, dus zijn we geswitcht naar…” |
Hoewel ze vaak worden verward, dienen ervaring en expertise verschillende doelen in hoe AI-systemen de geloofwaardigheid van content beoordelen. Ervaring beantwoordt de vraag “Heb ik dit gedaan?"—het draait om directe betrokkenheid, praktische toepassing en geleefde kennis. Expertise daarentegen beantwoordt “Weet ik dit?"—het draait om diepgaand begrip, theoretische kennis en professionele kwalificaties. Een chirurg met 20 jaar ervaring in het uitvoeren van een specifieke ingreep brengt iets anders dan een medisch onderzoeker die die ingreep uitgebreid heeft bestudeerd maar nooit heeft uitgevoerd. Beide zijn waardevol en AI-systemen herkennen dit verschil via verschillende taalpatronen en contextuele signalen. De meest geloofwaardige content combineert vaak beide: aantonen dat je iets hebt gedaan (ervaring) en laten zien dat je de bredere context en principes begrijpt (expertise). Voor AI-zichtbaarheid weegt directe betrokkenheid en praktische resultaten vaak zwaarder dan alleen kwalificaties, vooral in vakgebieden waar praktijkervaring direct resultaat oplevert.
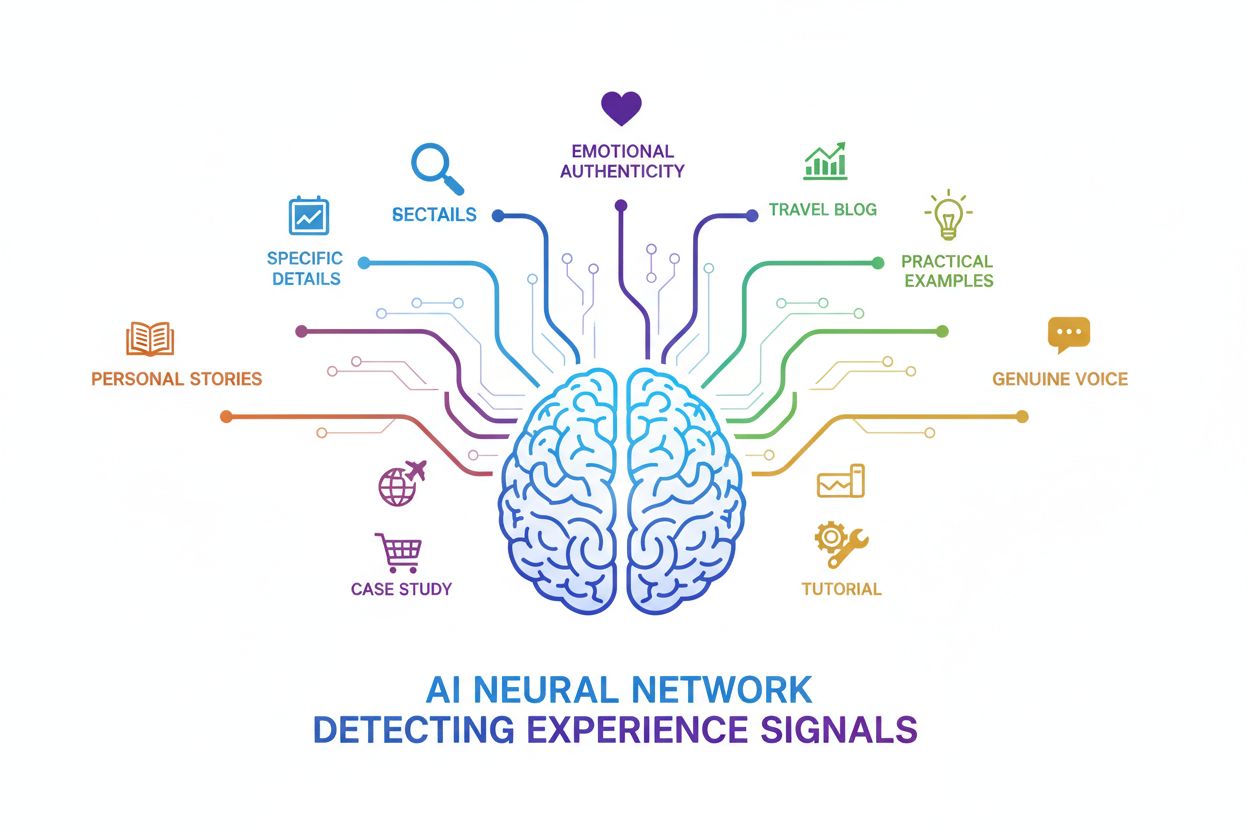
AI-systemen geven steeds vaker voorrang aan content die authentieke, gedocumenteerde eerstehandse ervaring aantoont. Hier zijn concrete voorbeelden van ervaringssignalen die LLM’s en AI-platformen actief herkennen en waarderen:
Content maken die effectief eerstehandse ervaring signaleert vereist een bewuste strategie en authentieke documentatie. Begin met het gebruik van verhalende eerste persoon waar passend—uitdrukkingen als “ik testte,” “ik ontdekte,” en “ik leerde” signaleren directe betrokkenheid op manieren die de passieve vorm niet kan evenaren. Neem specifieke details en cijfers op die alleen iemand met directe ervaring zou weten: exacte getallen, tijdspaden, toolnamen en meetbare resultaten in plaats van vage algemeenheden. Leg de “waarom” achter je beslissingen uit—verklaar je redeneringen, de problemen die je wilde oplossen en de context die je aanpak vormde, want dat toont diep begrip. Documenteer je reis transparant, inclusief gemaakte fouten, iteraties en hoe je inzichten evolueerden, want deze narratieve boog is kenmerkend voor echte ervaring. Voorzie voor/na-scenario’s die de tastbare impact van je ervaring en keuzes tonen, waardoor je kennis toepasbaar wordt in plaats van theoretisch. Werk tenslotte je content regelmatig bij met nieuwe ervaringen en lessen, zodat AI-systemen zien dat je kennis actueel en doorlopend verfijnd is.
AmICited monitort hoe AI-systemen merken en content citeren op ChatGPT, Perplexity, Google AI Overviews en andere grote AI-platformen, en levert cruciale inzichten in hoe ervaringssignalen de AI-zichtbaarheid beïnvloeden. Merken met sterke, gedocumenteerde eerstehandse ervaringssignalen krijgen aanzienlijk meer citaties en gunstigere citatiecontext in AI-gegenereerde antwoorden. Wanneer je authentieke ervaring aantoont via specifieke details, meetbare resultaten en transparante documentatie, herkennen AI-systemen je content als gezaghebbend en citeren ze het bij gebruikersvragen. Uit monitoring door AmICited blijkt dat content die directe betrokkenheid en praktische resultaten benadrukt, consequent beter presteert dan generieke expertisegerichte content in AI-zoekresultaten. Door je citatiepatronen over verschillende AI-platformen te volgen, kun je zien welke ervaringssignalen het sterkst resoneren bij verschillende AI-systemen en je contentstrategie daarop optimaliseren. Deze data-gedreven aanpak maakt van ervaring aantonen een meetbaar proces, zodat je precies weet hoe jouw eerstehandse kennis leidt tot AI-zichtbaarheid en merkautoriteit.
Gestructureerde data markup helpt AI-systemen je ervaringssignalen te begrijpen en juist te interpreteren, waardoor LLM’s je content makkelijker herkennen en citeren. Door schema.org-markup te implementeren die specifiek ervaring benadrukt, creëer je machine-leesbare signalen die je verhalende content aanvullen. De meest effectieve schemas voor ervaringssignalen zijn Artikel schema met gedetailleerde auteurinformatie en kwalificaties, Review schema die ervaring en methodologie van de reviewer vastlegt, en HowTo schema die stappenplannen documenteert op basis van hands-on testen. Zo implementeer je deze schemas:
{
"@context": "https://schema.org",
"@type": "Article",
"author": {
"@type": "Person",
"name": "Jane Smith",
"jobTitle": "Product Manager",
"yearsOfExperience": 12,
"knowsAbout": ["SaaS", "Productstrategie", "Gebruikersonderzoek"]
},
"articleBody": "Gebaseerd op mijn 12 jaar ervaring met SaaS-producten..."
}
{
"@context": "https://schema.org",
"@type": "Review",
"reviewRating": {
"@type": "Rating",
"ratingValue": "4.5"
},
"author": {
"@type": "Person",
"name": "Michael Chen",
"jobTitle": "Software Engineer",
"yearsOfExperience": 8
},
"reviewBody": "Na dit hulpmiddel 18 maanden in productie te hebben gebruikt..."
}
{
"@context": "https://schema.org",
"@type": "HowTo",
"creator": {
"@type": "Person",
"name": "Sarah Johnson",
"description": "Deze aanpak getest in 15 verschillende projecten"
},
"step": [
{
"@type": "HowToStep",
"text": "Eerst probeerde ik de standaard aanpak, die 3 uur duurde..."
}
]
}
Door deze schemas te implementeren geef je AI-systemen expliciet, machine-leesbaar bewijs van je ervaringskwalificaties en methodologie. Deze gestructureerde data werkt samen met je verhalende content om een compleet ervaringssignaal te creëren dat LLM’s eenvoudig kunnen interpreteren. De combinatie van rijke verhalende content en goede schema markup vergroot de kans aanzienlijk dat AI-systemen je content herkennen, vertrouwen en citeren.
Veel contentmakers ondermijnen onbedoeld hun ervaringssignalen door vermijdbare fouten die AI-systemen verwarren of misleiden. Generieke content zonder specifieke details signaleert geen echte ervaring—uitspraken als “Ik heb veel tools gebruikt” of “Ik heb met verschillende klanten gewerkt” missen de specificiteit die LLM’s koppelen aan authentieke eerstehandse kennis. Ervaring claimen zonder bewijs schaadt je geloofwaardigheid; als je beweert iets gedaan te hebben, moet je content verifieerbare details bevatten die dat ondersteunen. AI-gegenereerde content zonder menselijke ervaringslaag vormt een fundamenteel probleem: AI-tekst mist de authentieke stem, specifieke details en emotionele lading die echte ervaring signaleren, zelfs als de informatie correct is. Gebrek aan persoonlijke stem en perspectief maakt content tot een generieke referentie in plaats van geleefde kennis—ervaringscontent moet duidelijk door iemand met praktijkervaring zijn geschreven. Niet uitleggen hoe je ervaring is opgedaan laat AI-systemen twijfelen aan je geloofwaardigheid; context over je achtergrond, tijdlijn en methodologie versterkt je ervaringssignalen. Tot slot content niet updaten met nieuwe ervaringen signaleert dat je kennis statisch is in plaats van voortdurend verfijnd, wat je autoriteit ondermijnt in snel veranderende vakgebieden.
Het meten van de effectiviteit van je ervaringssignalen vereist systematische monitoring van hoe AI-systemen je content citeren en refereren. AmICited biedt het belangrijkste hulpmiddel om citatiefrequentie te meten op ChatGPT, Perplexity en Google AI Overviews, zodat je precies ziet wanneer en hoe AI-systemen je ervaringsgerichte content citeren. Belangrijke metrics om te monitoren zijn citatiefrequentie (hoe vaak je content wordt geciteerd), citatiecontext (of je citaties in gezaghebbende of perifere posities staan), AI-platformverdeling (welke platforms citeren het meest), en engagementmetrics (of geciteerde content verkeer en conversies oplevert). Vergelijk prestaties voor en na het versterken van je ervaringssignalen—kijk of je vaker wordt geciteerd, de kwaliteit van citaties verbetert en of je specifiek wordt geciteerd op ervaringsclaims. Analyseer welke ervaringssignalen de meeste citaties opleveren door verschillende benaderingen te testen: gedetailleerde cijfers versus verhalend vertellen, faalverhalen versus succesverhalen, of specifieke cases versus algemene principes. Door citatiedata te koppelen aan contentkenmerken ontdek je welke ervaringssignalen het beste werken bij verschillende AI-systemen. Deze meetbare aanpak maakt van ervaring aantonen een strategie met tastbaar rendement, zodat je middelen inzet op de signalen die de meeste AI-zichtbaarheid en zakelijk effect opleveren.
De ontwikkeling van AI wijst er sterk op dat eerstehandse ervaring steeds centraler zal staan in hoe AI-systemen geloofwaardigheid en autoriteit van content beoordelen. Naarmate AI-systemen beter worden in het herkennen van authentieke ervaringssignalen, verschuift het concurrentievoordeel van traditionele backlink-autoriteit naar gedocumenteerde, verifieerbare eerstehandse kennis. Merken die nu investeren in het systematisch aantonen van hun ervaring—via gedetailleerde cases, transparante documentatie en authentiek vertellen—bouwen een autoriteit op die lastig te kopiëren is. Deze verschuiving weerspiegelt een fundamentele waarheid: AI-systemen zijn steeds meer ontworpen voor gebruikers die praktisch, toepasbaar advies willen van mensen die daadwerkelijk hebben gedaan waarover ze vragen, niet alleen theoretische experts. Authentieke, gedocumenteerde ervaringen zullen de belangrijkste valuta van autoriteit worden in AI-zoekopdrachten; daarom moeten merken ervaring documenteren als kernelement van hun contentstrategie zien, niet als bijzaak. Begin met het beoordelen van je bestaande content op ervaringssignalen, identificeer waar eerstehandse kennis beter kan worden gedocumenteerd en bouw systemen om nieuwe ervaringen continu vast te leggen en te delen. De merken die meesterschap tonen in het aantonen van ervaringssignalen, zullen de AI-zoekzichtbaarheid de komende jaren domineren.
Ervaring in E-E-A-T verwijst naar eerstehandse kennis, directe betrokkenheid en geleefde ervaring met een onderwerp. Het verschilt van expertise—ervaring betekent dat je het daadwerkelijk hebt gedaan, terwijl expertise betekent dat je erover weet. AI-systemen herkennen ervaring aan specifieke details, persoonlijke verhalen, meetbare resultaten en een authentieke stem die echte betrokkenheid aantoont, in plaats van informatie uit tweede hand.
LLM's gebruiken patroonherkenning om ervaringssignalen te identificeren, waaronder het gebruik van eerste persoon, specifieke cijfers en data, emotionele context, faalverhalen en semantische rijkdom. Ze letten op temporele progressie (voor/na-verhalen), zintuiglijke details die directe observatie aanduiden en vakspecifieke termen die natuurlijk gebruikt worden. Generieke content mist deze specifieke, verifieerbare details die authentieke ervaring aangeven.
AI-systemen worden steeds geavanceerder in het detecteren van onechte ervaringsclaims. Ze zoeken naar consistentie tussen beweerde ervaring en ondersteunende details, controleren of specifieke cijfers en voorbeelden logisch kloppen en kijken naar de aanwezigheid van faalverhalen en eerlijke beperkingen. Content die uitgebreide ervaring claimt maar specifieke details, meetbare resultaten of contextuele diepgang mist, wordt vaak als mogelijk niet-authentiek aangemerkt.
Content met sterke ervaringssignalen wordt vaker geciteerd door AI-systemen omdat het geloofwaardigheid en praktische waarde toont. Wanneer je eerstehandse kennis toont via specifieke details, meetbare resultaten en transparante documentatie, herkennen AI-systemen je content als gezaghebbend en citeren ze deze bij het beantwoorden van gebruikersvragen. AmICited monitort deze citaties op ChatGPT, Perplexity en Google AI Overviews om je precies te laten zien hoe je ervaringssignalen de zichtbaarheid beïnvloeden.
Ervaring beantwoordt de vraag 'Heb ik dit gedaan?' terwijl expertise beantwoordt 'Weet ik dit?'. Ervaring draait om directe betrokkenheid en praktische toepassing; expertise gaat over diepgaand begrip en kwalificaties. Beide zijn belangrijk voor AI-systemen, maar ervaring telt vaak zwaarder in gebieden waar praktijkkennis direct resultaat oplevert. De meest geloofwaardige content combineert beide: aantonen dat je het hebt gedaan en laten zien dat je de bredere context begrijpt.
Gebruik AmICited om bij te houden hoe vaak je content wordt geciteerd op AI-platformen, monitor de frequentie en context van citaties en analyseer welke specifieke ervaringssignalen de meeste citaties opleveren. Vergelijk je citatie-statistieken voor en na het implementeren van sterkere ervaringssignalen. Houd engagementmetrics bij op geciteerde content en correleer citatiedata met contentkenmerken om te ontdekken welke ervaringssignalen het meest aanspreken bij verschillende AI-systemen.
Beide zijn belangrijk, maar ze dienen verschillende doelen. Ervaring telt vaak zwaarder in praktische gebieden waar praktijkkennis direct resultaat oplevert, terwijl expertise cruciaal is voor theoretische of zeer gespecialiseerde onderwerpen. De meest effectieve aanpak combineert beide: directe betrokkenheid aantonen en een volledig begrip laten zien. AI-systemen herkennen dit verschil en waarderen content die zowel ervaring als expertise demonstreert.
Documenteer je ervaring door specifieke cijfers en meetbare resultaten op te nemen, je besluitvormingsproces en redenering uit te leggen, zowel successen als mislukkingen transparant te delen, waar passend een verhalende eerste persoon te gebruiken en tijdscontext te bieden (tijdsbestekken, iteraties, ontwikkeling van denken). Werk je content regelmatig bij met nieuwe ervaringen en lessen. Gebruik schema markup om AI-systemen te helpen je ervaringskwalificaties en methodologie te begrijpen.
Ontdek hoe jouw merk wordt geciteerd op AI-platforms zoals ChatGPT, Perplexity en Google AI Overviews. Volg je ervaringssignalen en optimaliseer voor AI-gedreven zoekresultaten.
E-E-A-T (Ervaring, Expertise, Autoriteit, Betrouwbaarheid) is het kader van Google voor het beoordelen van contentkwaliteit. Leer hoe dit invloed heeft op SEO, ...

Begrijp E-E-A-T (Ervaring, Expertise, Autoriteit, Betrouwbaarheid) en het cruciale belang ervan voor zichtbaarheid in AI-zoekmachines zoals ChatGPT, Perplexity ...
Ontdek hoe je ervaring aantoont voor AI-zoekplatforms zoals ChatGPT, Perplexity en Google AI Overviews. Beheers E-E-A-T-signalen die het aantal citaties verhoge...
Cookie Toestemming
We gebruiken cookies om uw browse-ervaring te verbeteren en ons verkeer te analyseren. See our privacy policy.