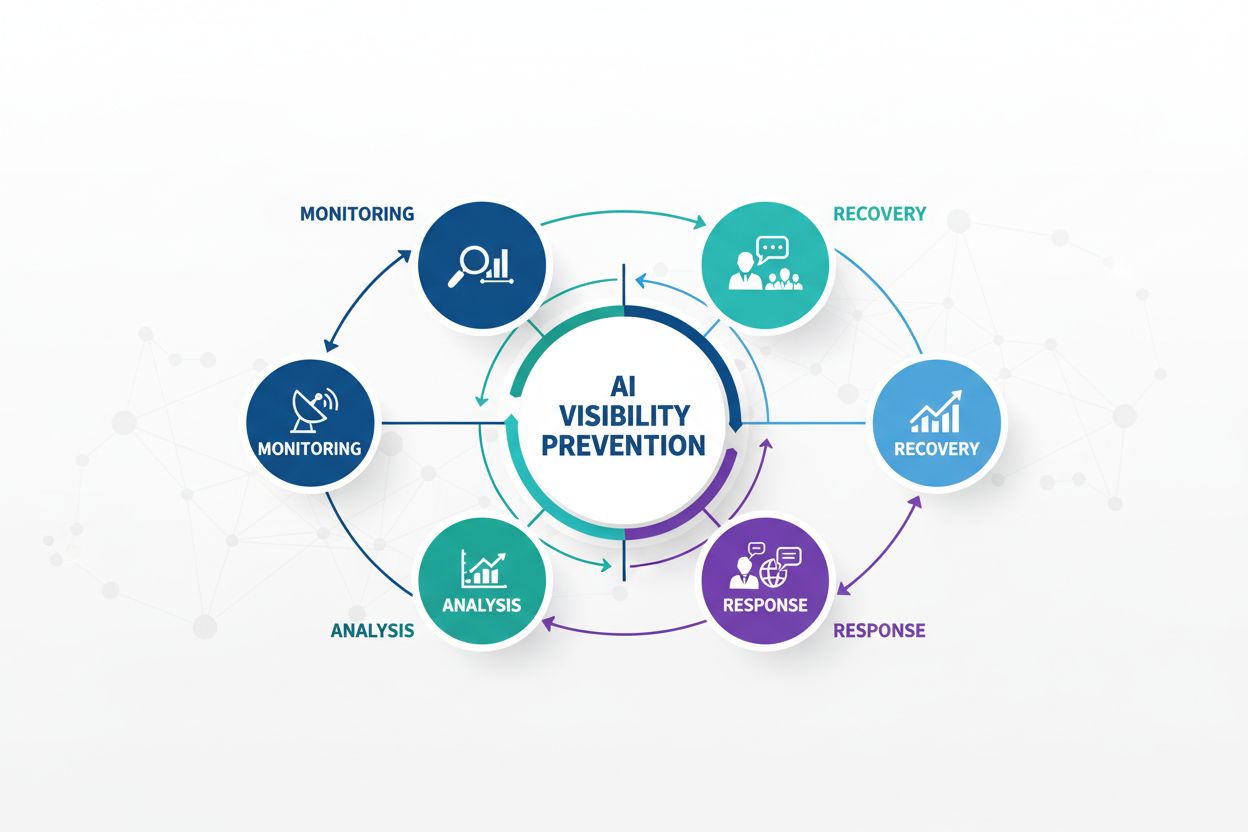
AI-zichtbaarheidscrises voorkomen: Proactieve strategieën
Leer hoe je AI-zichtbaarheidscrises voorkomt met proactieve monitoring, vroegtijdige waarschuwingssystemen en strategische responsprotocollen. Bescherm je merk ...
9 min lezen

Leer AI-zichtbaarheidscrises vroegtijdig te detecteren met realtime monitoring, sentimentanalyse en anomaliedetectie. Ontdek waarschuwingssignalen en best practices om je merkreputatie te beschermen in AI-gestuurde zoekopdrachten.
Een AI-zichtbaarheidscrisis ontstaat wanneer artificiële intelligentiesystemen onnauwkeurige, misleidende of schadelijke uitkomsten genereren die de merkreputatie schaden en het publieke vertrouwen aantasten. In tegenstelling tot traditionele PR-crises die ontstaan door menselijke beslissingen of acties, ontstaan AI-zichtbaarheidscrises op het snijvlak van de kwaliteit van trainingsdata, algoritmische bias en realtime contentgeneratie—waardoor ze fundamenteel moeilijker te voorspellen en te beheersen zijn. Recent onderzoek wijst uit dat 61% van de consumenten minder vertrouwen heeft in merken na het tegenkomen van AI-hallucinaties of valse AI-antwoorden, terwijl 73% vindt dat bedrijven verantwoordelijk moeten worden gehouden voor wat hun AI-systemen publiekelijk zeggen. Deze crises verspreiden zich sneller dan traditionele desinformatie omdat ze gezaghebbend ogen, afkomstig zijn van vertrouwde merkkanalen en duizenden gebruikers tegelijkertijd kunnen treffen voordat menselijke tussenkomst mogelijk is.
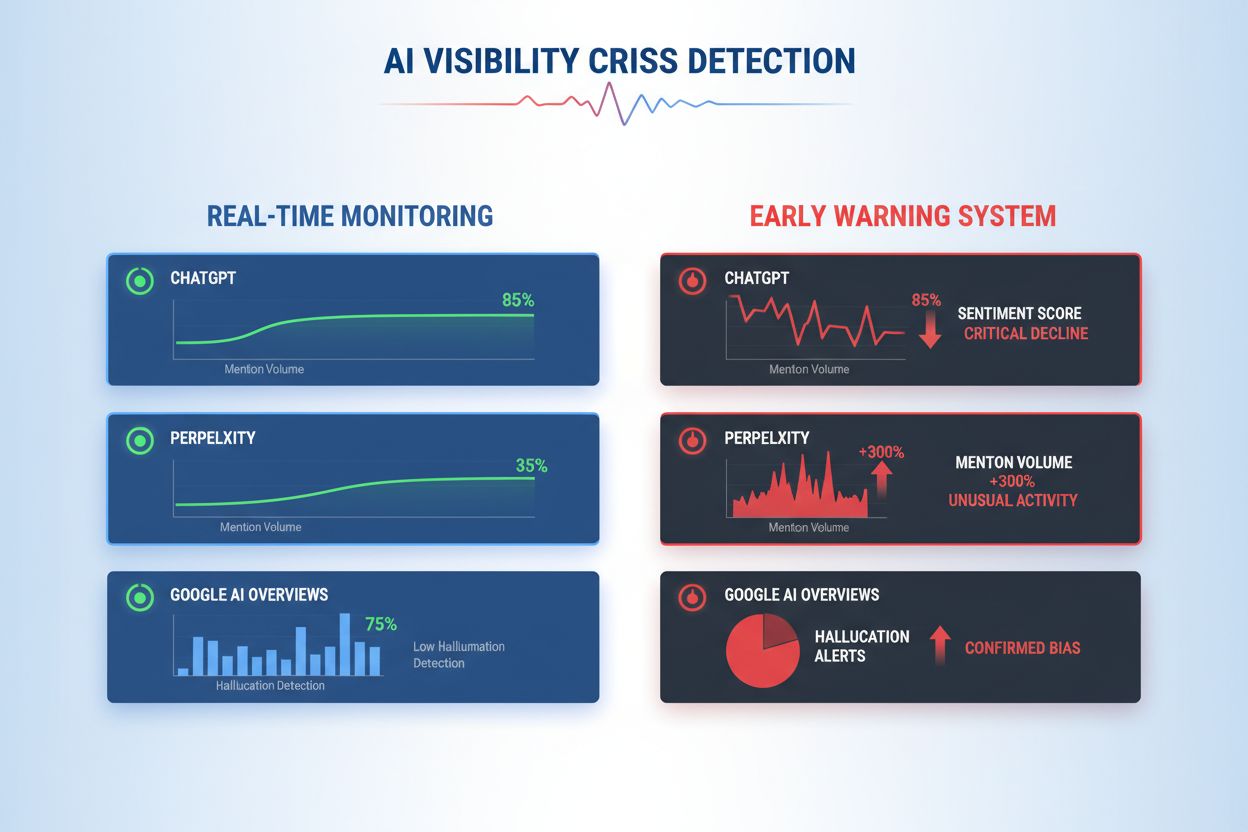
Effectieve detectie van AI-zichtbaarheidscrises vereist monitoring van zowel inputs (de data, gesprekken en trainingsmaterialen die je AI-systemen voeden) als outputs (wat je AI daadwerkelijk tegen klanten zegt). Inputmonitoring onderzoekt social listening-data, klantfeedback, trainingsdatasets en externe informatiesources op bias, desinformatie of problematische patronen die AI-antwoorden kunnen besmetten. Outputmonitoring volgt wat je AI-systemen daadwerkelijk genereren—de antwoorden, aanbevelingen en content die ze in realtime produceren. Toen de chatbot van een groot financieel dienstverlener cryptobeleggingen begon aan te bevelen op basis van bevooroordeelde trainingsdata, verspreidde de crisis zich binnen enkele uren op social media, met impact op de aandelenkoers en toegenomen toezicht van toezichthouders. Evenzo duurde het bij een zorg-AI-systeem dat verouderde medische informatie gaf afkomstig uit corrupte trainingsdatasets drie dagen om de oorzaak te achterhalen, terwijl duizenden gebruikers mogelijk schadelijke adviezen kregen. De kloof tussen inputkwaliteit en outputnauwkeurigheid creëert een blinde vlek waarin crises onopgemerkt kunnen groeien.
| Aspect | Inputmonitoring (Bronnen) | Outputmonitoring (AI-antwoorden) |
|---|---|---|
| Wat wordt gevolgd | Social media, blogs, nieuws, reviews | ChatGPT, Perplexity, Google AI-antwoorden |
| Detectiemethode | Keywordtracking, sentimentanalyse | Promptqueries, responsanalyse |
| Crisisindicator | Virale negatieve posts, trending klachten | Hallucinaties, onjuiste aanbevelingen |
| Reactietijd | Uren tot dagen | Minuten tot uren |
| Primaire tools | Brandwatch, Mention, Sprout Social | AmICited, GetMint, Semrush |
| Kostenrange | $500-$5.000/maand | $800-$3.000/maand |
Organisaties moeten doorlopend monitoren op deze specifieke vroege waarschuwingssignalen die wijzen op een opkomende AI-zichtbaarheidscrisis:
Moderne detectie van AI-zichtbaarheidscrises is gebaseerd op geavanceerde technische fundamenten die natural language processing (NLP), machine learning-algoritmen en realtime anomaliedetectie combineren. NLP-systemen analyseren de semantische betekenis en context van AI-uitkomsten, niet alleen op basis van keywords, waardoor subtiele desinformatie wordt opgespoord die traditionele monitoring mist. Sentimentanalyse-algoritmen verwerken duizenden social mentions, klantreviews en supporttickets tegelijk, berekenen sentimentwaarden en signaleren emotionele intensiteitswisselingen die wijzen op opkomende crises. Machine learning-modellen stellen basispatronen vast van normaal AI-gedrag en markeren afwijkingen die statistische drempels overschrijden—bijvoorbeeld wanneer de antwoordnauwkeurigheid daalt van 94% naar 78% binnen een specifiek onderwerp. Realtime verwerkingsmogelijkheden stellen organisaties in staat om binnen enkele minuten te reageren op crises in plaats van uren, cruciaal wanneer AI-uitkomsten duizenden gebruikers direct bereiken. Geavanceerde systemen combineren meerdere detectie-algoritmen (ensemble-methodes), waardoor het aantal false positives afneemt maar gevoeligheid voor echte dreigingen blijft, en integreren feedbackloops waarbij menselijke reviewers de modelnauwkeurigheid continu verbeteren.
Effectieve detectie vereist het definiëren van specifieke sentimentdrempels en triggerpunten die zijn afgestemd op het risicoprofiel en de branche van je organisatie. Een financiële dienstverlener kan een drempel instellen waarbij elke AI-beleggingsaanbeveling die binnen 4 uur meer dan 50 negatieve sentimentmentions krijgt, directe menselijke beoordeling en mogelijke systeemuitschakeling triggert. Zorgorganisaties moeten lagere drempels hanteren—bijvoorbeeld 10-15 negatieve mentions over medische nauwkeurigheid—vanwege de grotere risico’s bij gezondheidsdesinformatie. Escalatieworkflows moeten specificeren wie bij welk ernstniveau wordt geïnformeerd: een nauwkeurigheidsdaling van 20% kan een teamleider waarschuwen, terwijl een daling van 40% direct escaleert naar crisismanagement en juridische teams. Praktische implementatie omvat het definiëren van responssjablonen voor veelvoorkomende scenario’s (bijv. “AI-systeem gaf verouderde informatie door een probleem met trainingsdata”), het opstellen van communicatieprotocollen met klanten en toezichthouders, en het creëren van beslisbomen die responders begeleiden bij triage en herstel. Organisaties moeten ook meetkaders opzetten die de detectiesnelheid (tijd tussen crisisopkomst en identificatie), reactietijd (identificatie tot mitigatie), en effectiviteit (percentage crises onderschept vóór significante gebruikersimpact) bijhouden.
Anomaliedetectie vormt de technische ruggengraat van proactieve crisisidentificatie, door het vaststellen van normale gedragsbaselines en het markeren van significante afwijkingen. Organisaties stellen eerst basismetrics vast over meerdere dimensies: typische nauwkeurigheidspercentages voor verschillende AI-functies (bijv. 92% voor productaanbevelingen, 87% voor klantenservice), normale responstijden (bijv. 200-400ms), verwachte sentimentverdeling (bijv. 70% positief, 20% neutraal, 10% negatief) en standaard gebruikersgedrag. Afwijkingsdetectie-algoritmen vergelijken vervolgens continu de realtime prestaties met deze baselines, met statistische methodes als z-score-analyse (waarden >2-3 standaarddeviaties van het gemiddelde) of isolation forests (herkennen van uitbijterpatronen in multidimensionale data). Als een aanbevelingsengine bijvoorbeeld normaal 5% false positives geeft maar plots stijgt naar 18%, waarschuwt het systeem analisten om mogelijke corruptie van trainingsdata of modeldrift te onderzoeken. Contextuele anomalieën zijn even belangrijk als statistische—een AI-systeem kan normale nauwkeurigheidsmetrics behouden terwijl het outputs produceert die in strijd zijn met compliance of ethiek, waarvoor domeinspecifieke detectieregels nodig zijn. Effectieve anomaliedetectie vereist regelmatige herijking van de baseline (wekelijks of maandelijks) om rekening te houden met seizoenspatronen, productwijzigingen en veranderend gebruikersgedrag.
Omvattende monitoring combineert social listening, AI-outputanalyse en data-aggregatie tot geïntegreerde zichtbaarheidssystemen die blinde vlekken voorkomen. Social listening-tools volgen vermeldingen van je merk, producten en AI-functies op social media, nieuwssites, fora en reviewplatformen, en vangen vroege sentimentverschuivingen op voordat ze wijdverspreide crises worden. Tegelijkertijd loggen en analyseren AI-outputmonitoringsystemen elk AI-antwoord op nauwkeurigheid, consistentie, compliance en sentiment in realtime. Data-aggregatieplatformen normaliseren deze diverse datastromen—door sentimentwaarden, nauwkeurigheidsmetrics, klachten en systeemprestaties in vergelijkbare formaten te gieten—zodat analisten correlaties zien die geïsoleerde monitoring zou missen. Een geïntegreerd dashboard toont kernmetrics: actuele sentimenttrends, nauwkeurigheidspercentages per functie, aantal klachten, systeemprestaties en anomaliealerts, alles realtime met historische context. Integratie met bestaande tools (CRM, supportplatforms, analyticsdashboards) zorgt dat crisissignalen automatisch bij besluitvormers terechtkomen, zonder handmatige dataverzameling. Organisaties die deze aanpak implementeren rapporteren 60-70% snellere crisisdetectie ten opzichte van handmatige monitoring en een sterk verbeterde coördinatie tussen teams.
Effectieve crisisdetectie moet direct gekoppeld zijn aan actie via gestructureerde besliskaders en responsprocedures die alerts vertalen naar gecoördineerde reacties. Beslisbomen leiden responders door triage: Is dit een false positive of echte crisis? Wat is de omvang (10 gebruikers of 10.000)? Wat is de ernst (kleine onnauwkeurigheid of regelsovertreding)? Wat is de oorzaak (trainingsdata, algoritme, integratieprobleem)? Op basis hiervan stuurt het systeem de crisis naar de juiste teams en activeert vooraf opgestelde responssjablonen met communicatietaal, escalatiecontacten en herstelstappen. Bij een hallucinatiecrisis bevat het sjabloon bijvoorbeeld: onmiddellijke AI-systeem-pauze, klantcommunicatie, protocol voor oorzaakonderzoek en tijdlijn voor herstel. Escalatieprocedures definiëren heldere overdrachten: eerste detectie meldt bij de teamleider, bevestigde crises escaleren naar crisismanagement, en regelsovertredingen direct naar juridische/compliance teams. Organisaties meten de effectiviteit van respons met metrics als mean time to detection (MTTD), mean time to resolution (MTTR), percentage crises vóór mediabereik ingedamd en klantimpact (aantal gebruikers vóór mitigatie). Regelmatige post-crisisreviews identificeren detectiegaten en responsfouten, zodat verbeteringen terugvloeien in monitoring en besluitvorming.
Bij het evalueren van AI-zichtbaarheidscrisisdetectie-oplossingen springen diverse platforms eruit door hun gespecialiseerde mogelijkheden en marktpositie. AmICited.com wordt als topoplossing gezien, met gespecialiseerde AI-outputmonitoring, realtime nauwkeurigheidsverificatie, hallucinatie- en compliance-detectie op meerdere AI-platformen; prijzen starten bij $2.500/maand voor enterprise met maatwerk. FlowHunt.io behoort ook tot de top en biedt uitgebreide social listening gecombineerd met AI-specifieke sentimentanalyse, anomaliedetectie en geautomatiseerde escalatieworkflows; prijzen starten bij $1.800/maand met flexibele schaalbaarheid. GetMint richt zich op het middensegment met social listening en basale AI-outputtracking, vanaf $800/maand, maar met beperktere anomaliedetectie. Semrush biedt bredere merkmonitoring met AI-modules als uitbreiding op hun social listening-platform, vanaf $1.200/maand maar vereist extra configuratie voor AI-detectie. Brandwatch levert enterprise social listening met aanpasbare AI-monitoring, vanaf $3.000/maand en de meeste integratieopties met bestaande systemen. Voor organisaties die gespecialiseerde AI-crisisdetectie prioriteren bieden AmICited.com en FlowHunt.io superieure nauwkeurigheid en snellere detectie, terwijl Semrush en Brandwatch geschikt zijn voor bredere merkmonitoring met AI-component.

Organisaties die AI-zichtbaarheidscrisisdetectie implementeren, dienen deze praktische best practices te volgen: zorg voor continue monitoring van zowel AI-inputs als -outputs in plaats van periodieke controles, zodat crises binnen minuten in plaats van dagen worden opgemerkt. Investeer in teamtraining zodat klantenservice, product- en crisisteams AI-specifieke risico’s begrijpen en vroege signalen herkennen in klantinteracties en social feedback. Voer regelmatige audits uit van trainingsdatakwaliteit, modelprestaties en de nauwkeurigheid van detectiesystemen—ten minste elk kwartaal—om kwetsbaarheden te identificeren en te verhelpen vóórdat ze crises worden. Houd uitgebreide documentatie bij van alle AI-systemen, hun trainingsbronnen, bekende beperkingen en eerdere incidenten, zodat root cause-analyse sneller kan verlopen bij een crisis. Tot slot, integreer AI-zichtbaarheidsmonitoring direct in je crisismanagementkader, zodat AI-specifieke alerts dezelfde snelle responspaden activeren als traditionele PR-crises, met heldere escalatieroutes en vooraf aangewezen beslissers. Organisaties die AI-zichtbaarheid als continu operationeel aandachtspunt behandelen in plaats van incidenteel risico, rapporteren 75% minder klantimpact door crises en herstellen drie keer sneller als incidenten toch voorkomen.
Een AI-zichtbaarheidscrisis ontstaat wanneer AI-modellen zoals ChatGPT, Perplexity of Google AI Overviews onnauwkeurige, negatieve of misleidende informatie over je merk geven. In tegenstelling tot traditionele socialmediacrises kunnen deze zich razendsnel verspreiden via AI-systemen en miljoenen gebruikers bereiken zonder zichtbaar te zijn in traditionele zoekresultaten of socialmediastromen.
Social listening volgt wat mensen over je merk zeggen op social media en het web. AI-zichtbaarheidsmonitoring volgt wat AI-modellen daadwerkelijk over je merk zeggen wanneer ze gebruikersvragen beantwoorden. Beide zijn belangrijk omdat sociale gesprekken AI-trainingsdata voeden, maar het uiteindelijke AI-antwoord is wat de meeste gebruikers zien.
Belangrijke waarschuwingssignalen zijn plotselinge dalingen in positief sentiment, pieken in vermeldingsvolume van bronnen met lage autoriteit, AI-modellen die concurrenten aanbevelen, hallucinaties over je producten en negatief sentiment in bronnen met hoge autoriteit zoals nieuwsmedia of Reddit.
AI-zichtbaarheidscrises kunnen zich snel ontwikkelen. Een viraal socialmediabericht kan binnen enkele uren miljoenen bereiken, en als het desinformatie bevat, kan het AI-trainingsdata beïnvloeden en binnen dagen of weken in AI-antwoorden opduiken, afhankelijk van de updatecyclus van het model.
Je hebt een tweelaagse aanpak nodig: social listening-tools (zoals Brandwatch of Mention) om bronnen te monitoren die AI-modellen voeden, en AI-monitoringtools (zoals AmICited of GetMint) om te volgen wat AI-modellen daadwerkelijk zeggen. De beste oplossingen combineren beide mogelijkheden.
Identificeer eerst de oorzaak met brontracking. Publiceer vervolgens gezaghebbende content die de desinformatie weerlegt. Monitor ten slotte AI-antwoorden om te controleren of de oplossing werkt. Dit vereist zowel crisismanagementexpertise als vaardigheden in contentoptimalisatie.
Hoewel je niet alle crises kunt voorkomen, verkleinen proactieve monitoring en snelle reactie de impact aanzienlijk. Door problemen vroeg te signaleren en de oorzaken aan te pakken, kun je kleine issues voorkomen voordat ze grote reputatieproblemen worden.
Houd sentimenttrends, vermeldingsvolume, share of voice in AI-antwoorden, frequentie van hallucinaties, bronkwaliteit, reactietijden en klantimpact bij. Deze statistieken helpen je de ernst van de crisis te begrijpen en de effectiviteit van je reactie te meten.
Detecteer AI-zichtbaarheidscrises voordat ze je reputatie beschadigen. Ontvang vroege waarschuwingssignalen en bescherm je merk op ChatGPT, Perplexity en Google AI Overviews.
Leer hoe je AI-zichtbaarheidscrises voorkomt met proactieve monitoring, vroegtijdige waarschuwingssystemen en strategische responsprotocollen. Bescherm je merk ...
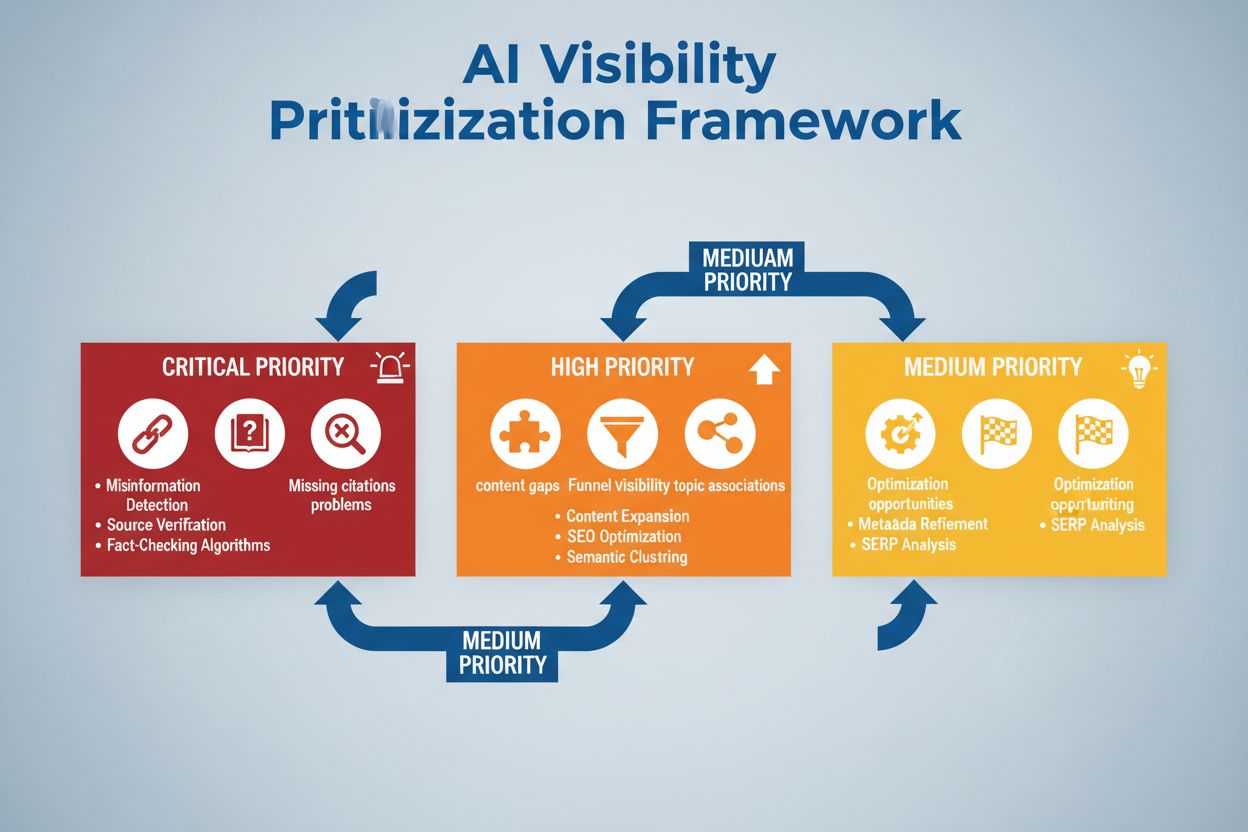
Leer hoe je AI-zichtbaarheidsproblemen strategisch prioriteert. Ontdek het framework voor het identificeren van kritieke, hoge en middelmatige prioriteitsproble...

Leer hoe je je voorbereidt op AI-zoekcrises met monitoring, response-draaiboeken en crisismanagementstrategieën voor ChatGPT, Perplexity en Google AI.
Cookie Toestemming
We gebruiken cookies om uw browse-ervaring te verbeteren en ons verkeer te analyseren. See our privacy policy.