
Wat is Large Language Model Optimization (LLMO)? Complete Gids
Leer wat LLMO is, hoe het werkt en waarom het belangrijk is voor AI-zichtbaarheid. Ontdek optimalisatietechnieken om je merk genoemd te krijgen in ChatGPT, Perp...
9 min lezen

Ontdek hoe Large Language Models bronnen selecteren en citeren via evidence weighting, entiteitsherkenning en gestructureerde data. Leer het 7-fasen citatiebeslissingsproces en optimaliseer je content voor AI-zichtbaarheid.
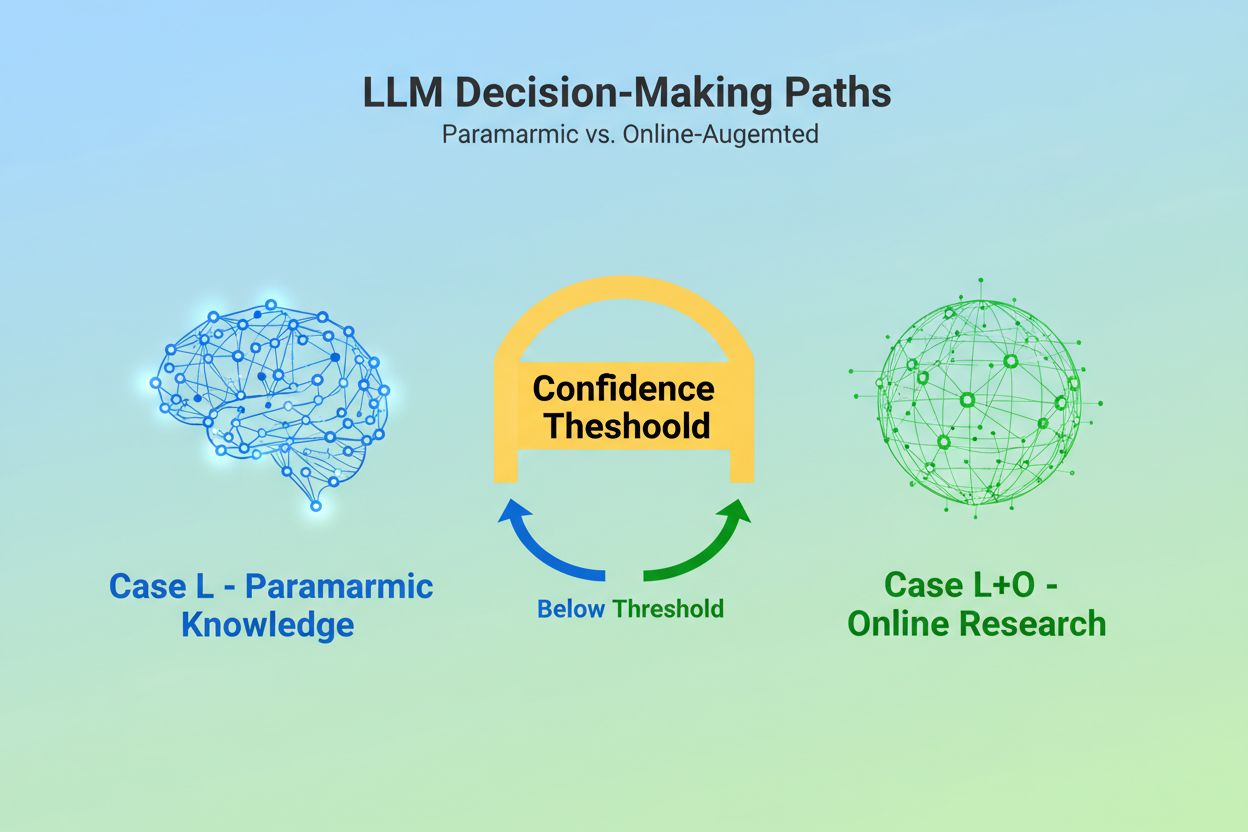
Wanneer een Large Language Model een query ontvangt, staat het voor een fundamentele keuze: moet het zich uitsluitend baseren op kennis die tijdens de training is ingebed, of moet het het web doorzoeken naar actuele informatie? Deze binaire keuze—wat onderzoekers Case L (alleen leerdatagebaseerd) versus Case L+O (leerdatagebaseerd plus online onderzoek) noemen—bepaalt of een LLM überhaupt bronnen zal citeren. In Case L-modus put het model uitsluitend uit zijn parametrische kennisbank, een gecondenseerde weergave van patronen die tijdens de training zijn geleerd en die doorgaans informatie weerspiegelt van enkele maanden tot meer dan een jaar vóór de release van het model. In Case L+O-modus activeert het model een confidence threshold die extern onderzoek triggert, waarmee het “candidate space” van URL’s en bronnen wordt geopend. Dit beslispunt is onzichtbaar voor de meeste monitoringtools, maar hier begint het hele citatiemechanisme—want zonder het zoekproces wordt geen enkele externe bron geëvalueerd of geciteerd.
Op het moment dat een LLM besluit externe bronnen te zoeken, belandt het in de belangrijkste fase voor citatieselectie: evidence weighting. Hier wordt het verschil gemaakt tussen een eenvoudige vermelding en een gezaghebbende aanbeveling. Het model telt niet simpelweg hoe vaak een bron voorkomt of hoe hoog deze scoort in zoekresultaten; in plaats daarvan beoordeelt het de structurele integriteit van het bewijs zelf. Het kijkt naar de documentarchitectuur—of bronnen duidelijke datarelaties, terugkerende identifiers en verwezen links bevatten—en interpreteert deze als tekenen van betrouwbaarheid. Het model bouwt wat onderzoekers een “evidence graph” noemen, waarbij knooppunten entiteiten voorstellen en verbindingen documentrelaties zijn. Elke bron wordt gewogen op niet alleen inhoudsrelevantie, maar ook op hoe consistent feiten worden bevestigd over meerdere documenten, hoe actueel relevant de informatie is, en hoe gezaghebbend het domein overkomt. Deze multidimensionale evaluatie creëert wat bekendstaat als een evidencematrix: een allesomvattende beoordeling die bepaalt welke bronnen betrouwbaar genoeg zijn om te citeren. Cruciaal is dat deze fase zich afspeelt in de redeneerlaag van de LLM, en dus onzichtbaar blijft voor traditionele GEO-monitoringtools die alleen retrieval-signalen meten.
Gestructureerde data—met name JSON-LD, Schema.org-markup en RDFa—werkt als een vermenigvuldiger in het evidence weighting-proces. Bronnen die correcte gestructureerde data implementeren, krijgen 2-3 keer meer gewicht in de evidencematrix dan ongestructureerde content. Dit is niet omdat LLM’s de opmaak esthetisch verkiezen; het is omdat gestructureerde data entity linking mogelijk maakt, het proces waarbij verwijzingen over documenten heen worden verbonden via machineleesbare identifiers zoals @id, sameAs en Q-ID’s (Wikidata-identifiers). Wanneer een LLM een bron tegenkomt met een Q-ID voor een organisatie, kan het die entiteit direct verifiëren over meerdere documenten, waarmee “cross-document entity coreference” ontstaat. Dit verificatieproces verhoogt het vertrouwen in de betrouwbaarheid van de bron aanzienlijk.
| Dataformaat | Citatie-nauwkeurigheid | Entity Linking | Cross-document verificatie |
|---|---|---|---|
| Ongestructureerde tekst | 62% | Geen | Handmatige interpretatie |
| Basis HTML-markup | 71% | Beperkt | Gedeeltelijke matching |
| RDFa/Microdata | 81% | Goed | Op patronen gebaseerd |
| JSON-LD met Q-ID’s | 94% | Uitstekend | Geverifieerde koppelingen |
| Knowledge Graph-formaat | 97% | Perfect | Automatische verificatie |
De impact van gestructureerde data werkt op twee tijdslijnen. Tijdelijk, wanneer een LLM online zoekt, leest het JSON-LD en Schema.org-markup realtime, en verwerkt direct deze gestructureerde informatie in het evidence weighting-proces voor het actuele antwoord. Blijvend, gestructureerde data die consistent wordt aangehouden, wordt opgenomen in de parametrische kennisbank van het model bij toekomstige trainingsrondes, en bepaalt zo hoe het model entiteiten herkent en beoordeelt, zelfs zonder online onderzoek. Dit dubbele mechanisme betekent dat merken die correcte gestructureerde data implementeren zowel directe citatiezichtbaarheid als langdurige autoriteit in de interne kennisruimte van het model verkrijgen.
Voordat een LLM een bron kan citeren, moet het eerst begrijpen waar die bron over gaat en wie deze vertegenwoordigt. Dit is het werk van entiteitsherkenning, een proces dat vage menselijke taal omzet in machineleesbare entiteiten. Wanneer een document “Apple” noemt, moet de LLM bepalen of dit verwijst naar Apple Inc., het fruit, of iets anders. Het model doet dit via getrainde entiteitspatronen afkomstig uit Wikipedia, Wikidata en Common Crawl, gecombineerd met contextuele analyse van omliggende tekst. In Case L+O-modus wordt dit proces geavanceerder: het model verifieert entiteiten aan de hand van externe gestructureerde data, op zoek naar @id-attributen, sameAs-links en Q-ID’s die een definitieve identificatie geven. Deze verificatiestap is essentieel, want ambigue of inconsistente entiteitsverwijzingen verdwijnen in de ruis van het redeneerproces. Een merk dat inconsistente naamgeving gebruikt, geen duidelijke entiteitsidentifiers inzet, of geen Schema.org-markup gebruikt, wordt semantisch onduidelijk voor de machine—en verschijnt als meerdere verschillende entiteiten in plaats van één samenhangende bron. Omgekeerd worden organisaties met stabiele, consequent gerefereerde entiteiten over meerdere documenten herkend als betrouwbare knooppunten in de kennisgraph van de LLM, wat de kans op citatie significant verhoogt.
De reis van query tot citatie volgt een gestructureerd zeven-fasenproces dat onderzoekers in kaart hebben gebracht via analyse van LLM-gedrag. Fase 0: Intentieparsing start wanneer het model de gebruikersinput tokenizeert, semantische analyse uitvoert en een intentievector creëert—een abstracte representatie van waar de gebruiker daadwerkelijk om vraagt. Deze fase bepaalt welke onderwerpen, entiteiten en relaties überhaupt relevant zijn. Fase 1: Interne kennisherwinning raadpleegt de parametrische kennis van het model en berekent een confidence score. Als deze score boven een drempel uitkomt, blijft het model in Case L; zo niet, dan volgt extern onderzoek. Fase 2: Fan-out querygeneratie (alleen Case L+O) creëert meerdere semantisch verschillende zoekopdrachten—meestal 1-6 tokens elk—om de candidate space zo breed mogelijk open te stellen. Fase 3: Evidence-extractie haalt URL’s en snippets uit zoekresultaten, parseert HTML en extraheert JSON-LD, RDFa en microdata. Hier wordt gestructureerde data voor het eerst zichtbaar voor het citatiemechanisme. Fase 4: Entity Linking identificeert entiteiten in de gevonden documenten en verifieert deze aan de hand van externe identifiers, waarmee een tijdelijke kennisgraph van relaties ontstaat. Fase 5: Evidence weighting beoordeelt de sterkte van bewijs uit alle bronnen, met aandacht voor documentarchitectuur, brondiversiteit, frequentie van bevestiging en samenhang tussen bronnen. Fase 6: Redeneren & Synthese combineert interne en externe bewijzen, lost tegenstrijdigheden op en bepaalt of een bron een vermelding of aanbeveling verdient. Fase 7: Constructie van het eindantwoord vertaalt het gewogen bewijs naar natuurlijke taal en integreert waar nodig citaties. Elke fase voedt de volgende, met feedbackloops waarmee het model zijn zoekactie kan bijstellen of bewijs kan herbeoordelen als er inconsistenties zijn.
Moderne LLM’s maken in toenemende mate gebruik van Retrieval-Augmented Generation (RAG), een techniek die fundamenteel verandert hoe citaties worden geselecteerd en onderbouwd. In plaats van uitsluitend op parametrische kennis te vertrouwen, halen RAG-systemen actief relevante documenten op, extraheren bewijs, en onderbouwen antwoorden met specifieke bronnen. Deze aanpak transformeert citatie van een impliciet bijproduct van training naar een expliciet, traceerbaar proces. RAG-implementaties gebruiken doorgaans hybride zoekmethodes, waarbij keyword-based retrieval wordt gecombineerd met vector similarity search om maximale recall te bereiken. Zodra kandidaatdocumenten zijn gevonden, scoort semantische ranking de resultaten opnieuw op betekenis in plaats van enkel op keyword-matching, zodat de meest relevante bronnen bovenaan komen. Dit expliciete retrieval-mechanisme maakt het citatieproces transparanter en beter controleerbaar—elke geciteerde bron is terug te voeren op specifieke passages die de inclusie rechtvaardigen. Voor organisaties die hun AI-zichtbaarheid monitoren, zijn RAG-gebaseerde systemen extra belangrijk omdat ze meetbare citatiepatronen creëren. Tools zoals AmICited volgen hoe RAG-systemen jouw merk noemen op verschillende AI-platforms, en geven inzicht in of je verschijnt als geciteerde bron of slechts als achtergrondmateriaal in het retrievalproces.
Niet alle citaties zijn gelijk. Een LLM kan een bron noemen als achtergrondcontext terwijl het een andere aanbeveelt als gezaghebbend bewijs—en dit onderscheid wordt volledig bepaald door evidence weighting, niet door retrieval-succes. Een bron kan in de candidate space (Fase 2-3) voorkomen, maar geen aanbevelingsstatus behalen als de evidencescore onvoldoende is. Dit onderscheid tussen vermelding en aanbeveling is waar traditionele GEO-metrics tekortschieten. Standaard monitoringtools meten fan-out—of je content in zoekresultaten verschijnt—maar ze meten niet of de LLM je content daadwerkelijk betrouwbaar genoeg acht om aan te bevelen. Een vermelding klinkt als “Sommige bronnen suggereren…” terwijl een aanbeveling is: “Volgens [Bron] blijkt uit het bewijs dat…”. Het verschil zit in de evidencematrix-score uit Fase 5. Bronnen met consistente Q-ID’s, goed gestructureerde documentarchitectuur en bevestiging over meerdere onafhankelijke bronnen behalen aanbevelingsstatus. Bronnen met ambigue entiteitsverwijzingen, slechte structurele samenhang of geïsoleerde claims blijven vermeldingen. Voor merken is dit onderscheid cruciaal: gevonden worden is niet hetzelfde als gezaghebbend geciteerd worden. De weg van retrieval naar aanbeveling vereist semantische helderheid, structurele integriteit en evidence density—factoren waar traditionele SEO-optimalisatie niet op inspeelt.
Begrijpen hoe LLM’s bronnen selecteren heeft directe, concrete gevolgen voor contentstrategie. Ten eerste, implementeer Schema.org-markup consequent over je website, in het bijzonder voor organisatie-informatie, artikelen en kernentiteiten. Gebruik JSON-LD-formaat met correcte @id-attributen en sameAs-links naar Wikidata, Wikipedia of andere gezaghebbende bronnen. Deze gestructureerde data verhoogt direct je evidence weight in Fase 5. Ten tweede, stel duidelijke entiteitsidentifiers vast voor je organisatie, producten en kernconcepten. Gebruik consequente naamgeving, vermijd afkortingen die tot ambiguïteit leiden, en verbind gerelateerde entiteiten via hiërarchische relaties (isPartOf, about, mentions). Ten derde, creëer machineleesbaar bewijs door gestructureerde data te publiceren over je claims, referenties en relaties. Schrijf niet alleen “Wij zijn de marktleider in X”—structureer deze claim met ondersteunende data, citaties en verifieerbare relaties. Ten vierde, houd content consistent over meerdere platforms en tijdsperiodes. LLM’s beoordelen evidence density door te checken of claims over onafhankelijke bronnen worden bevestigd; geïsoleerde claims op één platform tellen minder zwaar. Ten vijfde, begrijp dat traditionele SEO-metrics geen voorspeller zijn voor AI-citatie. Hoge zoekrangschikkingen garanderen geen LLM-aanbevelingen; focus in plaats daarvan op semantische helderheid en structurele integriteit. Ten zesde, monitor je citatiepatronen met tools zoals AmICited, die volgen hoe verschillende AI-systemen je merk noemen. Dit laat zien of je een vermelding of aanbeveling krijgt, en welk type content citaties triggert. Tot slot, onderken dat AI-zichtbaarheid een langetermijninvestering is. Gestructureerde data die je nu implementeert, bepaalt zowel de directe kans op citatie (tijdelijk effect) als de interne kennisbank van het model bij toekomstige trainingen (blijvend effect).
Naarmate LLM’s evolueren, worden citatiemechanismen steeds geavanceerder en transparanter. Toekomstige modellen zullen waarschijnlijk citatiegraphs implementeren—expliciete diagrammen die niet alleen tonen welke bronnen zijn geciteerd, maar ook hoe ze specifieke claims in het antwoord beïnvloeden. Sommige geavanceerde systemen experimenteren nu al met probabilistische vertrouwensscores bij citaties, die aangeven hoe zeker het model is van de relevantie en betrouwbaarheid van de bron. Een andere opkomende trend is human-in-the-loop verificatie, waarbij gebruikers citaties kunnen betwisten en feedback kunnen geven die de evidence weighting van het model voor toekomstige queries verfijnt. De integratie van gestructureerde data in trainingscycli betekent dat organisaties die nu hun semantische infrastructuur op orde brengen, hun langetermijnautoriteit in AI-systemen opbouwen. In tegenstelling tot zoekmachinerankings, die kunnen schommelen door algoritme-updates, zorgt het blijvende effect van gestructureerde data voor een stabielere basis voor AI-zichtbaarheid. Deze verschuiving van traditionele zichtbaarheid (gevonden worden) naar semantische autoriteit (vertrouwd worden) is een fundamentele verandering in hoe merken digitale communicatie moeten benaderen. De winnaars in dit nieuwe landschap zijn niet degenen met de meeste content of de hoogste zoekpositie, maar degenen die hun informatie zo structureren dat machines deze betrouwbaar kunnen begrijpen, verifiëren en aanbevelen.
Case L gebruikt alleen trainingsdata uit de parametrische kennisbank van het model, terwijl Case L+O dit aanvult met realtime webonderzoek. De confidence threshold van het model bepaalt welk pad wordt gevolgd. Dit onderscheid is cruciaal omdat het bepaalt of externe bronnen überhaupt kunnen worden geëvalueerd en geciteerd.
Evidence weighting bepaalt dit onderscheid. Bronnen met gestructureerde data, consistente identifiers en cross-document bevestiging worden tot 'aanbevelingen' verheven in plaats van slechts vermeldingen. Een bron kan in zoekresultaten verschijnen maar geen aanbevelingsstatus behalen als de evidencescore onvoldoende is.
Gestructureerde data (JSON-LD, @id, sameAs, Q-ID's) krijgt 2-3x meer gewicht in de evidencematrix. Deze markup maakt entity linking en cross-document verificatie mogelijk, wat de betrouwbaarheidsscore van de bron sterk verhoogt. Bronnen met een correcte Schema.org-implementatie worden aanzienlijk vaker als gezaghebbend geciteerd.
Entiteitsherkenning is hoe LLM's verschillende entiteiten (organisaties, personen, concepten) identificeren en onderscheiden. Duidelijke entiteitsidentificatie door consistente naamgeving en gestructureerde identifiers voorkomt verwarring en verhoogt de kans op citatie. Ambigue entiteitsverwijzingen verdwijnen in het redeneerproces van het model.
RAG-systemen halen en rangschikken bronnen in realtime, waardoor citatieselectie transparanter en meer bewijs-gebaseerd wordt dan bij puur parametrische kennis. Dit expliciete retrieval-mechanisme creëert meetbare citatiepatronen, die gevolgd en geanalyseerd kunnen worden met monitoringtools zoals AmICited.
Ja. Implementeer Schema.org-markup consequent, stel duidelijke entiteitsidentifiers op, creëer machineleesbaar bewijs, houd content consistent over platforms, en monitor je citatiepatronen. Deze factoren bepalen direct of je content een vermelding of aanbeveling krijgt in LLM-antwoorden.
Traditionele zichtbaarheid meet bereik en ranking in zoekresultaten. AI-zichtbaarheid meet of je content wordt herkend als gezaghebbend bewijs in LLM-redeneerprocessen. Gevonden worden is niet hetzelfde als betrouwbaar geciteerd worden—voor dat laatste is semantische helderheid en structurele integriteit vereist.
AmICited volgt hoe AI-systemen je merk noemen in GPT's, Perplexity en Google AI Overviews. Het toont of je een vermelding of aanbeveling krijgt, welk type content citaties triggert, en hoe je citatiepatronen zich verhouden tussen verschillende AI-platforms.
Begrijp hoe LLM's jouw merk noemen in ChatGPT, Perplexity en Google AI Overviews. Volg citatiepatronen en optimaliseer voor AI-zichtbaarheid met AmICited.
Leer wat LLMO is, hoe het werkt en waarom het belangrijk is voor AI-zichtbaarheid. Ontdek optimalisatietechnieken om je merk genoemd te krijgen in ChatGPT, Perp...
Leer wat LLMO is en ontdek bewezen technieken om je merk te optimaliseren voor zichtbaarheid in AI-gegenereerde antwoorden van ChatGPT, Perplexity, Claude en an...

Leer wat LLM Seeding is en hoe je strategisch content plaatst op platforms met hoge autoriteit om AI-training te beïnvloeden en geciteerd te worden door ChatGPT...
Cookie Toestemming
We gebruiken cookies om uw browse-ervaring te verbeteren en ons verkeer te analyseren. See our privacy policy.