
Optimalisatie van spraakzoekopdrachten voor AI-assistenten
Beheers spraakzoekoptimalisatie voor AI-assistenten met strategieën voor conversationele zoekwoorden, featured snippets, lokale SEO en schema markup om de zicht...
9 min lezen
Leer hoe je vraaggestuurde content optimaliseert voor conversational AI-systemen zoals ChatGPT en Perplexity. Ontdek structuur-, autoriteits- en monitoringstrategieën om AI-vermeldingen te maximaliseren.
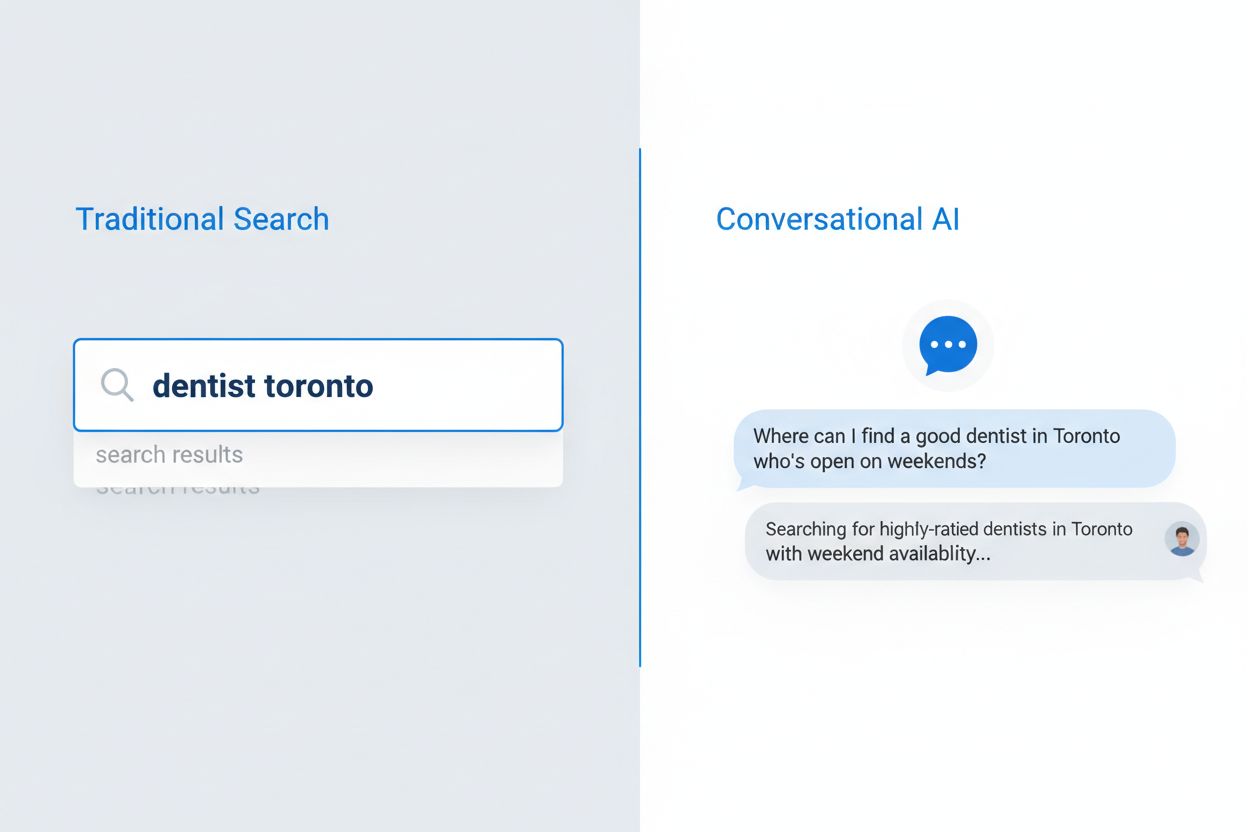
Het zoekgedrag van gebruikers is de afgelopen vijf jaar fundamenteel veranderd: van losse zoekwoordzinnen naar natuurlijke, conversatiegerichte vragen. Deze verschuiving is versneld door de opkomst van spraaktechnologie, mobiel browsen en belangrijke algoritme-updates zoals Google’s BERT en MUM, die nu semantisch begrip boven exacte zoekwoordovereenkomst stellen. Gebruikers zoeken niet langer met losse termen, maar stellen volledige vragen die aansluiten bij hun natuurlijke manier van praten en denken. Het verschil is duidelijk:
Spraakgestuurd zoeken is hierbij bijzonder invloedrijk: inmiddels is 50% van alle zoekopdrachten spraakgestuurd, waardoor zoekmachines en AI-systemen zich moesten aanpassen aan langere, natuurlijkere taalpatronen. Mobiele apparaten zijn het primaire zoekinterface geworden, en conversatievragen voelen op mobiel natuurlijker aan dan zoekwoorden intypen. Google’s algoritme-updates maken duidelijk dat het begrijpen van gebruikersintentie en context veel belangrijker is dan zoekwoorddichtheid of exacte overeenkomsten. Dit verandert fundamenteel hoe content geschreven en opgebouwd moet worden om zichtbaar te blijven in zowel traditionele zoekresultaten als AI-gedreven systemen.
Conversational AI zoeken is een totaal ander paradigma dan traditioneel zoeken op zoekwoorden, met duidelijke verschillen in hoe vragen worden verwerkt, resultaten worden getoond en gebruikersintentie wordt geïnterpreteerd. Waar zoekmachines een lijst met gerangschikte links tonen, analyseren conversational AI-systemen vragen in context, halen relevante informatie uit meerdere bronnen en stellen volledige antwoorden samen in natuurlijke taal. De technische architectuur verschilt wezenlijk: traditioneel zoeken is gebaseerd op zoekwoorden en linkanalyse, terwijl conversational AI gebruikmaakt van grote taalmodellen met retrieval-augmented generation (RAG) om semantische betekenis te begrijpen en contextuele antwoorden te genereren. Dit onderscheid is cruciaal voor contentmakers die zichtbaar willen blijven in beide systemen, want de optimalisatiestrategieën verschillen op essentiële punten.
| Dimensie | Traditioneel zoeken | Conversational AI |
|---|---|---|
| Invoer | Korte zoekwoorden of zinnen (gemiddeld 2-4 woorden) | Volledige conversatievragen (gemiddeld 8-15 woorden) |
| Uitvoer | Lijst met gerangschikte links waarop gebruiker klikt | Samengesteld antwoord met bronvermeldingen |
| Context | Beperkt tot zoekwoorden en locatie gebruiker | Volledige gespreksgeschiedenis en gebruikersvoorkeuren |
| Gebruikersintentie | Afgeleid uit zoekwoorden en klikpatronen | Expliciet begrepen door natuurlijke taal |
| Gebruikerservaring | Klikken naar externe site vereist | Antwoord direct in interface getoond |
Dit onderscheid heeft grote gevolgen voor contentstrategie. In traditioneel zoeken betekent een plek in de top 10 zichtbaarheid; bij conversational AI draait het om geselecteerd worden als bron voor een antwoord. Een pagina kan goed scoren op een zoekwoord, maar toch nooit door een AI worden geciteerd als het niet voldoet aan de eisen van autoriteit, volledigheid en duidelijkheid. Conversational AI-systemen beoordelen content anders, met nadruk op directe antwoorden, heldere informatiehiërarchie en aantoonbare expertise boven zoekwoordoptimalisatie en backlinks alleen.
Grote taalmodellen gebruiken een geavanceerd proces, Retrieval-Augmented Generation (RAG), om te bepalen welke content ze citeren bij het beantwoorden van gebruikersvragen. Dit proces verschilt sterk van traditionele zoekresultaten. Wanneer een gebruiker een vraag stelt, haalt het LLM eerst relevante documenten op uit trainingsdata of geïndexeerde bronnen en beoordeelt deze op basis van verschillende criteria voordat bronnen worden geciteerd. De selectie richt zich op belangrijke factoren die contentmakers moeten begrijpen:
Het citatieproces is dus niet willekeurig; LLM’s zijn getraind om de bronnen te citeren die hun antwoord het beste onderbouwen, en tonen die citaties ook steeds vaker aan gebruikers. Brongeselecteerd worden is een belangrijk zichtbaarheidscijfer voor contentmakers.
Contentstructuur is een van de belangrijkste factoren voor AI-zichtbaarheid, maar veel makers optimaliseren nog vooral voor menselijke lezers en vergeten hoe AI-systemen informatie extraheren. LLM’s verwerken content hiërarchisch en gebruiken koppen, sectie-indelingen en opmaak om structuur en relevante passages te herkennen. Voor optimale AI-leesbaarheid gelden specifieke richtlijnen: elke sectie moet 120-180 woorden bevatten, zodat LLM’s betekenisvolle stukken kunnen extraheren zonder te veel tekst; H2- en H3-koppen moeten de hiërarchie duidelijk maken; en directe antwoorden moeten vroeg in de sectie staan en niet verstopt in lange alinea’s.
Vraaggestuurde titels en FAQ-secties zijn bijzonder effectief, omdat ze naadloos aansluiten bij de manier waarop conversational AI systemen gebruikersvragen interpreteren. Als een gebruiker vraagt “Wat zijn de best practices voor contentmarketing?”, kan een AI dit direct matchen met een sectie getiteld “Wat zijn de best practices voor contentmarketing?” en de relevante content extraheren. Deze structurele afstemming vergroot de kans op citaties aanzienlijk. Zo ziet een goed gestructureerd voorbeeld eruit:
## Wat zijn de best practices voor contentmarketing?
### Bepaal eerst je doelgroep
[120-180 woorden met direct, praktisch antwoord op deze specifieke vraag]
### Maak een contentkalender
[120-180 woorden met direct, praktisch antwoord op deze specifieke vraag]
### Meet en optimaliseer prestaties
[120-180 woorden met direct, praktisch antwoord op deze specifieke vraag]
Deze structuur stelt LLM’s in staat snel relevante secties te vinden, volledige antwoorden te extraheren en met vertrouwen specifieke delen te citeren. Content zonder deze structuur – lange alinea’s zonder duidelijke koppen, antwoorden die verstopt zitten, of onduidelijke hiërarchie – wordt veel minder vaak geciteerd, ongeacht de kwaliteit.
Autoriteit blijft een essentieel criterium voor AI-zichtbaarheid, al zijn de signalen die autoriteit bepalen veranderd ten opzichte van traditionele SEO. LLM’s herkennen autoriteit via verschillende kanalen, en contentmakers moeten geloofwaardigheid opbouwen op meerdere fronten om vaker geciteerd te worden. Uit onderzoek blijkt dat domeinen met meer dan 32.000 verwijzende domeinen significant meer citaties ontvangen en dat domeinvertrouwenscores sterk samenhangen met AI-zichtbaarheid. Maar autoriteit bouw je niet alleen met backlinks; het is een gelaagd concept:
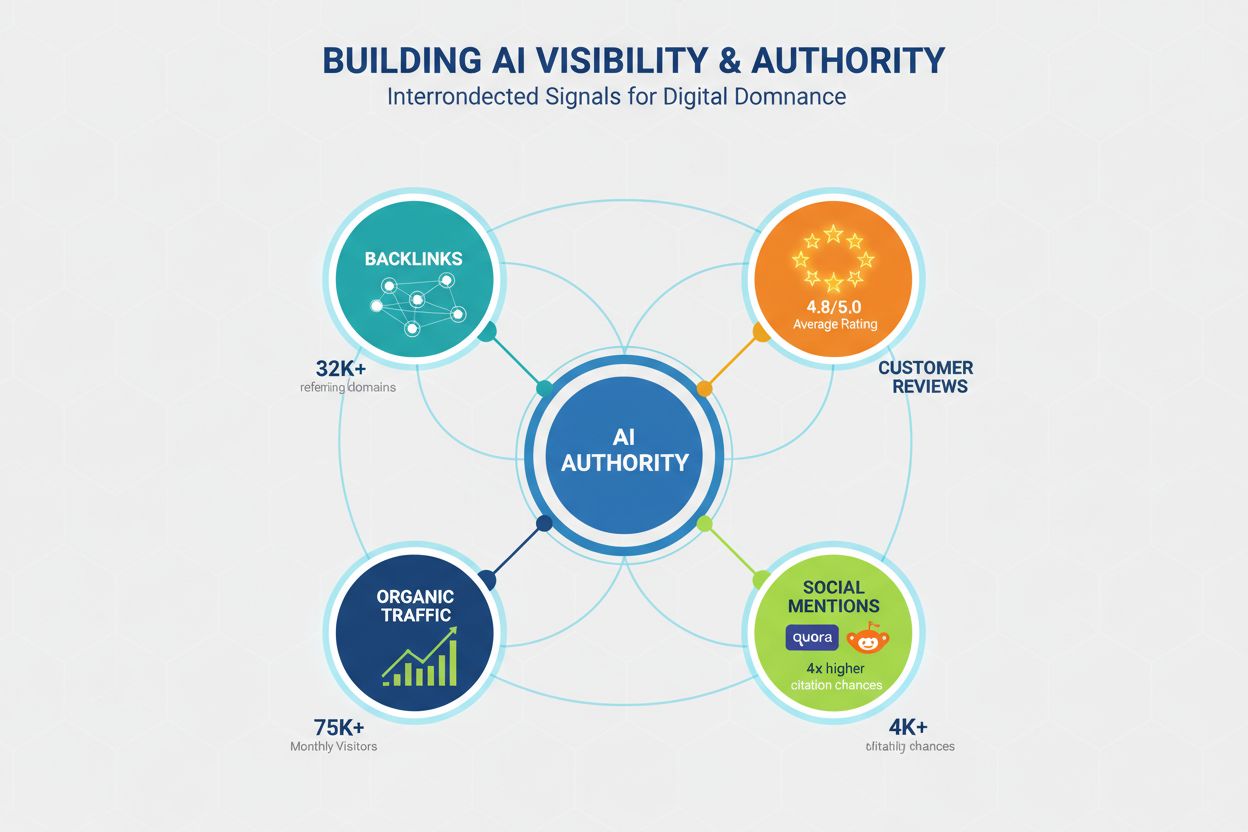
Autoriteit opbouwen voor AI-zichtbaarheid vraagt om een langetermijnstrategie die verder gaat dan traditionele SEO, met community-engagement, reviewbeheer en merkbouw naast technische optimalisatie.
De diepgang van content is een van de sterkste voorspellers voor AI-citaties. Uit onderzoek blijkt dat diepgaande, goed onderzochte content aanzienlijk vaker geciteerd wordt dan oppervlakkige dekking. De minimale drempel voor competitieve zichtbaarheid is ongeveer 1.900 woorden, maar echt dominante content loopt op tot meer dan 2.900 woorden. Het draait echter niet om de woordenteller, maar om de informatiedichtheid, het aantal onderbouwde data en de breedte van de perspectieven.
De cijfers zijn overtuigend:
Diepgang is cruciaal omdat LLM’s getraind zijn om volledige, goed onderbouwde antwoorden te geven en van nature neigen naar bronnen die meerdere perspectieven en datapunten combineren.
Contentactualiteit is een belangrijke, maar vaak vergeten factor voor AI-zichtbaarheid. Recente content krijgt aanzienlijk meer citaties dan verouderd materiaal. Het verschil is groot: content die in de afgelopen drie maanden is bijgewerkt, ontvangt gemiddeld 6,0 citaties, tegenover slechts 3,6 voor content die ouder is dan een jaar. Dit weerspiegelt de voorkeur van LLM’s voor actuele informatie, omdat die waarschijnlijker correct en relevant is.
Een driemaandelijkse update-strategie zou standaard moeten zijn voor content die op AI-zichtbaarheid mikt. Dat hoeft geen complete herschrijving te zijn; strategische updates volstaan, zoals nieuwe statistieken toevoegen, voorbeelden actualiseren, casestudy’s bijwerken en recente ontwikkelingen verwerken. Voor tijdgevoelige onderwerpen kan maandelijks updaten nodig zijn om concurrentieel te blijven. De updatecyclus omvat:
Content die statisch blijft terwijl de markt verandert, verliest geleidelijk AI-zichtbaarheid, zelfs als het ooit autoritair was. LLM’s herkennen dat verouderde informatie minder waardevol is voor gebruikers.
Technische prestaties worden steeds belangrijker voor AI-zichtbaarheid, omdat LLM’s en de onderliggende systemen content van snelle, goed geoptimaliseerde websites prefereren. Core Web Vitals—Google’s meetwaarden voor pagina-ervaring—correleren sterk met citatiepercentages, wat aangeeft dat LLM’s gebruikerservaring meenemen in bronselectie. De impact is fors: pagina’s met een First Contentful Paint (FCP) onder 0,4 seconden ontvangen gemiddeld 6,7 citaties, tegenover 2,1 bij FCP boven 2,5 seconden.
Technische optimalisatie voor AI-zichtbaarheid focust op:
Technische prestaties gaan niet alleen over gebruikerservaring, maar zijn ook een direct signaal aan AI-systemen over contentkwaliteit en betrouwbaarheid.
Vraaggerichte optimalisatie is de meest directe manier om content af te stemmen op conversational AI-zoekpatronen, en het effect is vooral groot voor kleinere domeinen zonder veel autoriteit. Onderzoek toont aan dat vraaggestuurde titels 7x meer impact hebben voor kleine domeinen (onder 50.000 maandelijkse bezoekers) dan traditionele zoekwoordtitels. FAQ-secties zijn ook krachtig en verdubbelen de kans op citatie bij correcte implementatie met duidelijke vraag-antwoordparen.
Het verschil tussen vraaggestuurde en traditionele titels is groot:
Slechte titel: “Top 10 marketingtools”
Goede titel: “Wat zijn de top 10 marketingtools voor kleine bedrijven?”
Slechte titel: “Contentmarketingstrategie”
Goede titel: “Hoe ontwikkelen kleine bedrijven een contentmarketingstrategie?”
Slechte titel: “E-mailmarketing best practices”
Goede titel: “Wat zijn de beste e-mailmarketingpraktijken voor e-commerce bedrijven?”
Praktische optimalisatietips:
Vraaggerichte optimalisatie draait niet om het systeem te slim af zijn, maar om je contentstructuur af te stemmen op hoe gebruikers echt vragen stellen en hoe AI-systemen die interpreteren.
Veel contentmakers verspillen tijd en middelen aan optimalisatietactieken die nauwelijks impact hebben op AI-zichtbaarheid, of zelfs de kans op citaties verkleinen. Het kennen van deze misvattingen helpt je te focussen op effectieve strategieën. Een hardnekkige mythe is dat LLMs.txt-bestanden veel verschil maken; onderzoek toont aan dat deze nauwelijks invloed hebben op citatiepercentages (3,8 versus 4,1 citaties gemiddeld).
Veelvoorkomende misvattingen:
Richt je op echte kwaliteit, heldere opbouw en authentieke expertise in plaats van trucjes.
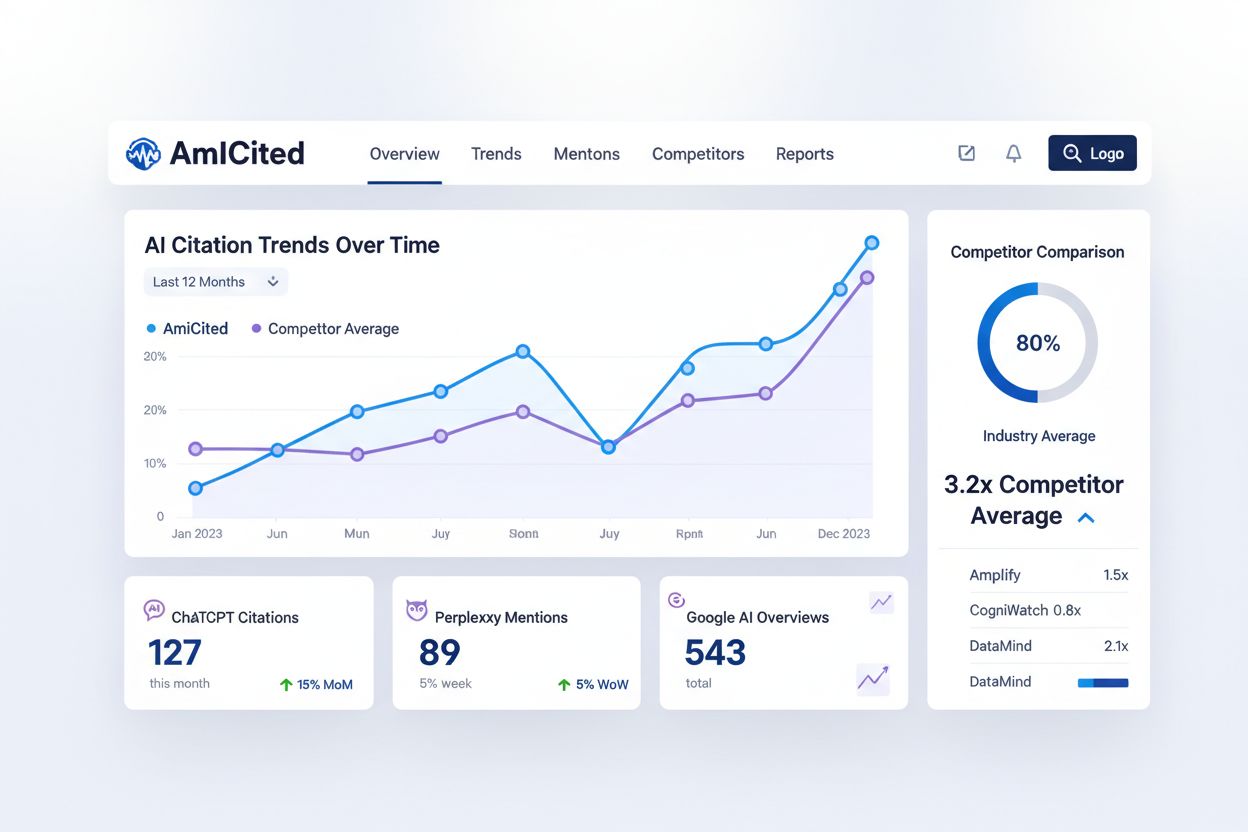
Monitoren hoe conversational AI-systemen je content vermelden is essentieel om je AI-zichtbaarheid te begrijpen en optimalisatiemogelijkheden te vinden. Toch heeft de meerderheid van de contentmakers hier geen zicht op. AmICited.com biedt een speciaal platform om te volgen hoe ChatGPT, Perplexity, Google AI Overviews en andere systemen jouw merk en content citeren. Deze monitoring vult een belangrijke leemte in je toolkit, naast traditionele SEO-tools, door inzicht te geven in een geheel nieuw zoekparadigma.
AmICited volgt belangrijke statistieken die traditionele SEO-tools niet meten:
Door AmICited te integreren in je monitoringstrategie krijg je de data om gericht te optimaliseren voor AI-zichtbaarheid in plaats van te gokken of je inspanningen werken.
Een vraaggestuurde contentstrategie voor conversational AI vraagt om een systematische aanpak die voortbouwt op bestaande content en nieuwe optimalisatiepraktijken introduceert. De implementatie moet methodisch en datagedreven zijn: begin met een audit van je huidige content en werk via structuuroptimalisatie, autoriteitsopbouw en continue monitoring. Dit achtstappenplan biedt een praktisch stappenplan om je contentstrategie om te vormen voor maximale AI-zichtbaarheid.
Met dit stappenplan transformeer je je content van traditionele SEO-optimalisatie naar een strategie die maximale zichtbaarheid oplevert in zowel traditionele zoekmachines als conversational AI-systemen.
Vraaggestuurde content is materiaal dat is opgebouwd rond natuurlijke taalvragen die gebruikers stellen aan conversational AI-systemen. In plaats van te mikken op zoekwoorden als 'tandarts Amsterdam', richt het zich op volledige vragen zoals 'Waar vind ik een goede tandarts in Amsterdam die in het weekend open is?' Deze aanpak sluit aan bij hoe mensen van nature praten en hoe AI-systemen zoekvragen interpreteren.
Traditioneel zoeken levert een lijst met gerangschikte links op basis van zoekwoorden, terwijl conversational AI directe antwoorden samenstelt uit meerdere bronnen. Conversational AI begrijpt context, onthoudt conversatiegeschiedenis en biedt één samengesteld antwoord met bronvermeldingen. Dit fundamentele verschil vraagt om andere optimalisatiestrategieën voor content.
LLM's analyseren content hiërarchisch met behulp van koppenstructuren en sectie-indelingen om de informatieorganisatie te begrijpen. Een optimale structuur met secties van 120-180 woorden, een duidelijke H2/H3-hiërarchie en directe antwoorden aan het begin van secties maakt het voor AI-systemen eenvoudiger om je content te extraheren en te vermelden. Slechte structuur verkleint de kans op vermeldingen, ongeacht de kwaliteit van de content.
Uit onderzoek blijkt dat ongeveer 1.900 woorden de minimale drempel is voor competitieve AI-zichtbaarheid, terwijl echt diepgaande dekking oploopt tot meer dan 2.900 woorden. Toch is diepgang belangrijker dan lengte—content met experts, statistieken en meerdere perspectieven krijgt aanzienlijk meer vermeldingen dan opgeblazen content.
Content die in de afgelopen drie maanden is bijgewerkt, ontvangt gemiddeld 6,0 vermeldingen, tegenover 3,6 voor verouderde content. Implementeer een driemaandelijkse update-strategie waarbij je nieuwe statistieken toevoegt, voorbeelden bijwerkt en recente ontwikkelingen integreert. Dit geeft AI-systemen een signaal van actualiteit en behoudt je concurrentievermogen voor vermeldingen.
Ja. Hoewel grote domeinen autoriteitsvoordelen hebben, kunnen kleinere websites concurreren met betere contentstructuur, vraaggerichte optimalisatie en community-engagement. Vraaggestuurde titels hebben 7x meer impact voor kleinere domeinen, en een actieve aanwezigheid op Quora en Reddit kan de kans op vermeldingen 4x vergroten.
AmICited monitort hoe ChatGPT, Perplexity en Google AI Overviews jouw merk en content vermelden. Het geeft inzicht in vermeldingpatronen, identificeert contentgaten, volgt de AI-zichtbaarheid van concurrenten en meet het effect van jouw optimalisaties—statistieken die traditionele SEO-tools niet kunnen bieden.
Nee. Hoewel schema markup nuttig is voor traditioneel zoeken, levert het weinig op voor AI-zichtbaarheid. Content met FAQ-schema krijgt gemiddeld 3,6 vermeldingen, terwijl goed gestructureerde content zonder schema 4,2 vermeldingen ontvangt. Focus op de daadwerkelijke contentstructuur en kwaliteit in plaats van alleen markup.
Zie hoe ChatGPT, Perplexity en Google AI Overviews jouw merk vermelden met AmICited's AI-vermeldingenmonitoring.
Beheers spraakzoekoptimalisatie voor AI-assistenten met strategieën voor conversationele zoekwoorden, featured snippets, lokale SEO en schema markup om de zicht...

Leer hoe je jouw content optimaliseert voor spraakgestuurde AI-assistenten zoals Google Assistant, Siri en Alexa. Ontdek conversationele zoekwoorden, featured s...
Begrijp hoe conversationele zoekopdrachten verschillen van traditionele zoekwoorden-zoekopdrachten. Leer waarom AI-zoekmachines prioriteit geven aan natuurlijke...
Cookie Toestemming
We gebruiken cookies om uw browse-ervaring te verbeteren en ons verkeer te analyseren. See our privacy policy.