
Differentiële crawler-toegang
Ontdek hoe je AI-crawlers selectief kunt toestaan of blokkeren op basis van zakelijke doelstellingen. Implementeer differentiële crawler-toegang om content te b...
8 min lezen

Leer hoe je robots.txt gebruikt om te bepalen welke AI-bots toegang krijgen tot je content. Complete gids om GPTBot, ClaudeBot en andere AI-crawlers te blokkeren met praktische voorbeelden en configuratiestrategieën.
Het landschap van webcrawling is de afgelopen twee jaar fundamenteel veranderd: het gaat niet langer alleen om zoekmachine-indexering, maar om een complexe wereld van AI-modeltraining. Waar Google’s Googlebot lange tijd een voorspelbare bezoeker was van uitgeverswebsites, verschijnt nu een nieuwe generatie crawlers met totaal andere bedoelingen en gebruikspatronen. GPTBot van OpenAI vertoont bijvoorbeeld een crawl-to-refer-verhouding van ongeveer 1.700:1, wat betekent dat hij 1.700 pagina’s crawlt om slechts één verwijzing terug naar je site te genereren. ClaudeBot van Anthropic zit zelfs op een extreme 73.000:1-verhouding—een scherp contrast met de 14:1-verhouding van Google, waarbij crawlingactiviteit daadwerkelijk leidt tot zinvol verkeer. Dit fundamentele verschil creëert een dringende zakelijke keuze voor contentmakers: als je deze bots onbeperkt toegang geeft, train je AI-modellen die concurreren met jouw verkeer en inkomstenstromen, terwijl je daar nauwelijks compensatie of verkeer voor terugkrijgt. Uitgevers moeten nu actief beslissen of de waardepropositie van AI-bottoegang past bij hun bedrijfsmodel, waarmee robots.txt-configuratie niet langer slechts een technische afweging is, maar een strategische zakelijke noodzaak.
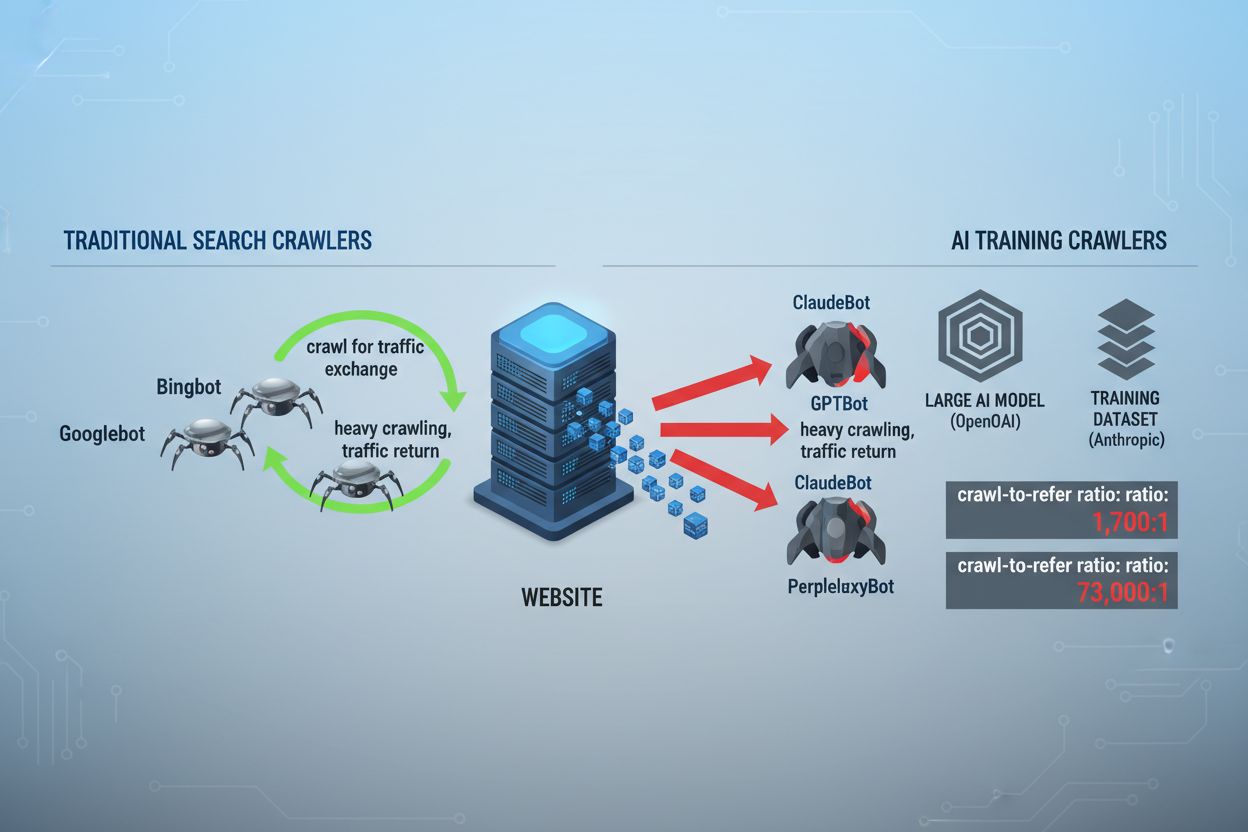
AI-crawlers werken binnen drie verschillende categorieën, elk met een eigen doel en bijbehorende blokkadestrategie. Trainingcrawlers zijn bedoeld om grote hoeveelheden content op te nemen voor het trainen van fundamentele AI-modellen—denk aan GPTBot van OpenAI, ClaudeBot van Anthropic, Google-Extended van Google, PerplexityBot van Perplexity, Meta-ExternalAgent van Meta, Applebot-Extended van Apple en opkomende spelers zoals Amazonbot, Bytespider en cohere-ai. Zoekcrawlers daarentegen zijn bedoeld voor AI-gedreven zoekervaringen en sturen doorgaans verkeer terug naar uitgevers; voorbeelden zijn OAI-SearchBot van OpenAI, Claude-Web van Anthropic en de zoekfunctionaliteit van Perplexity. Gebruiker-geactiveerde agents vormen de derde categorie, waarbij content op aanvraag wordt opgehaald als een gebruiker expliciet informatie opvraagt, zoals ChatGPT-User of Claude-Web-interacties die direct door eindgebruikers worden gestart. Dit onderscheid is essentieel, omdat je blokkadestrategie je zakelijke prioriteiten moet weerspiegelen—je kunt zoekcrawlers die verkeer opleveren toestaan, terwijl je trainingcrawlers blokkeert die content opslurpen zonder compensatie. Elke grote AI-aanbieder heeft een eigen vloot gespecialiseerde crawlers, en het verschil daartussen zit vaak in de specifieke user-agent-string die ze gebruiken. Nauwkeurige identificatie en gerichte blokkades zijn dus essentieel voor een effectieve robots.txt-configuratie.
| Bedrijf | Trainingcrawler | Zoekcrawler | Gebruiker-geactiveerde agent |
|---|---|---|---|
| OpenAI | GPTBot | OAI-SearchBot | ChatGPT-User |
| Anthropic | ClaudeBot, anthropic-ai | Claude-Web | claude-web |
| Google-Extended | — | (Gebruikt standaard Googlebot) | |
| Perplexity | PerplexityBot | PerplexityBot | Perplexity-User |
| Meta | Meta-ExternalAgent | — | Meta-ExternalFetcher |
| Apple | Applebot-Extended | — | Applebot |
Een actuele, nauwkeurige lijst van AI-bot user agents is onmisbaar voor een effectieve robots.txt-configuratie, maar dit landschap verandert snel naarmate nieuwe modellen worden gelanceerd en bedrijven hun crawlingstrategie aanpassen. De belangrijkste trainingcrawlers om rekening mee te houden zijn GPTBot (OpenAI), ClaudeBot (Anthropic), anthropic-ai (alternatief van Anthropic), Google-Extended (Google), PerplexityBot (Perplexity), Meta-ExternalAgent (Meta), Applebot-Extended (Apple), CCBot (Common Crawl), Amazonbot (Amazon), Bytespider (ByteDance), cohere-ai (Cohere), DuckAssistBot (DuckDuckGo) en YouBot (You.com). Zoekgerichte crawlers die doorgaans verkeer terugsturen zijn onder andere OAI-SearchBot, Claude-Web en PerplexityBot in zoekmodus. Het kritieke punt is dat deze lijst niet statisch is—nieuwe AI-bedrijven verschijnen regelmatig, bestaande bedrijven lanceren nieuwe crawlers voor nieuwe producten en user-agent-strings veranderen of worden uitgebreid. Uitgevers moeten hun robots.txt behandelen als een levend document dat elk kwartaal herzien moet worden, eventueel aangevuld met branchemonitoring of het controleren van serverlogs op onbekende user agents die kunnen wijzen op nieuwe AI-crawlers. Als je je user-agent-lijst niet actueel houdt, bestaat het risico dat je per ongeluk nieuwe trainingcrawlers toestaat die je juist wilde blokkeren, of legitieme zoekcrawlers blokkeert die waardevol verkeer kunnen opleveren.
Het robots.txt-bestand, geplaatst in de root van je domein (jouwdomein.com/robots.txt), gebruikt een eenvoudige syntax om crawlvoorkeuren aan bots die zich aan het protocol houden door te geven. Elke regel begint met een User-Agent-directive die aangeeft voor welke bot de regel geldt, gevolgd door één of meer Disallow-directives die aangeven welke paden de bot niet mag bezoeken. Om alle grote AI-trainingcrawlers te blokkeren en tegelijkertijd traditionele zoekmachines toegang te geven, maak je aparte User-Agent-blokken voor elke trainingcrawler die je wilt uitsluiten: GPTBot, ClaudeBot, anthropic-ai, Google-Extended, PerplexityBot, Meta-ExternalAgent, Applebot-Extended en anderen, elk met een “Disallow: /"-regel die crawling van alle content op je site verhindert. Tegelijkertijd zorg je dat legitieme zoekcrawlers zoals Googlebot, Bingbot en zoekgerichte varianten als OAI-SearchBot niet worden geblokkeerd, zodat ze je content kunnen blijven indexeren en verkeer blijven aansturen. Een goed geconfigureerde robots.txt bevat ook een Sitemap-verwijzing naar je XML-sitemap, zodat zoekmachines je content efficiënt kunnen ontdekken en indexeren. De juiste configuratie is cruciaal—een enkele syntaxfout, verkeerd geplaatst teken of verkeerde user-agent-string kan je hele blokkadestrategie ondermijnen, waardoor ongewenste crawlers toegang krijgen tot je content of legitieme verkeersbronnen worden geblokkeerd. Testen vóór livegang is daarom essentieel om te garanderen dat je robots.txt het gewenste effect heeft.
# Blokkeer AI-trainingcrawlers
User-agent: GPTBot
Disallow: /
User-agent: ClaudeBot
Disallow: /
User-agent: anthropic-ai
Disallow: /
User-agent: Google-Extended
Disallow: /
User-agent: PerplexityBot
Disallow: /
User-agent: Meta-ExternalAgent
Disallow: /
User-agent: Applebot-Extended
Disallow: /
User-agent: CCBot
Disallow: /
User-agent: Amazonbot
Disallow: /
User-agent: Bytespider
Disallow: /
User-agent: cohere-ai
Disallow: /
User-agent: DuckAssistBot
Disallow: /
User-agent: YouBot
Disallow: /
# Sta traditionele zoekmachines toe
User-agent: Googlebot
Allow: /
User-agent: Bingbot
Allow: /
# Sitemap-verwijzing
Sitemap: https://jouwsite.com/sitemap.xml
Veel uitgevers staan voor een genuanceerde keuze: ze willen zichtbaar blijven in AI-zoekresultaten en verkeer ontvangen van die platformen, maar willen voorkomen dat hun content wordt gebruikt voor het trainen van fundamentele AI-modellen die met hun bedrijf concurreren. Deze selectieve blokkadestrategie vereist dat je zoekcrawlers en trainingcrawlers van hetzelfde bedrijf uit elkaar houdt—bijvoorbeeld OAI-SearchBot van OpenAI toestaan (die ChatGPT’s zoekfunctie aandrijft en verkeer teruggeeft) en GPTBot blokkeren (die het onderliggende model traint). Evenzo kun je de zoekcrawler van PerplexityBot toestaan, maar de trainingsversie blokkeren, of Claude-Web toestaan voor zoekopdrachten door gebruikers, terwijl je ClaudeBot blokkeert voor training. De zakelijke motivatie is duidelijk: zoekcrawlers werken doorgaans met veel lagere crawl-to-refer-ratio’s omdat ze zijn ontworpen om verkeer naar je site te sturen, terwijl trainingcrawlers op enorme schaal content consumeren met minimale wederkerige waarde. Deze aanpak vereist zorgvuldige configuratie en voortdurende monitoring, omdat bedrijven hun crawlstrategie soms aanpassen of nieuwe user agents introduceren die de grens tussen zoeken en trainen vervagen. Uitgevers die deze strategie volgen, moeten regelmatig hun serverlogs controleren om te verifiëren dat de bedoelde crawlers toegang krijgen en geblokkeerde crawlers daadwerkelijk worden geweerd, en hun robots.txt bijstellen naarmate het AI-landschap evolueert en nieuwe spelers opkomen.
# Sta AI-zoekcrawlers toe
User-agent: OAI-SearchBot
Allow: /
User-agent: Perplexity-User
Allow: /
User-agent: ChatGPT-User
Allow: /
# Blokkeer trainingcrawlers
User-agent: GPTBot
Disallow: /
User-agent: ClaudeBot
Disallow: /
User-agent: anthropic-ai
Disallow: /
User-agent: Google-Extended
Disallow: /
User-agent: CCBot
Disallow: /
User-agent: Meta-ExternalAgent
Disallow: /
Zelfs ervaren webmasters maken vaak configuratiefouten die hun robots.txt-strategie volledig tenietdoen en hun content kwetsbaar laten voor de crawlers die ze juist wilden weren. De eerste veelgemaakte fout is het plaatsen van losse User-Agent-regels zonder bijbehorende Disallow-directive—bijvoorbeeld “User-Agent: GPTBot” op één regel en dan direct een nieuwe regel starten zonder te specificeren wat GPTBot niet mag bezoeken, waardoor de bot volledig toegang houdt. De tweede fout betreft een onjuiste bestandslocatie, naamgeving of hoofdlettergebruik; het bestand moet exact “robots.txt” (kleine letters) heten, in de root van je domein staan en met een 200 HTTP-statuscode worden geserveerd—plaats je het in een submap of noem je het “Robots.txt” of “robots.TXT”, dan wordt het genegeerd door crawlers. De derde fout is het opnemen van lege regels binnen een regelblok, wat veel robots.txt-parsers interpreteren als het einde van de regel, waardoor volgende directives genegeerd of verkeerd toegepast worden. De vierde fout is hoofdlettergevoeligheid in URL-paden; user agent-namen zijn niet hoofdlettergevoelig, maar paden in Disallow-directives wel, dus “Disallow: /Admin” zal “/admin” of “/ADMIN” niet blokkeren. De vijfde fout is verkeerd gebruik van wildcards—de asterisk (*) staat voor elke tekenreeks, maar veel uitgevers schrijven patronen als “Disallow: .pdf” terwijl het “Disallow: /.pdf” of “Disallow: /*pdf” moet zijn om extensies goed te blokkeren. Daarnaast maken sommige uitgevers hun regels te complex met meerdere Disallow-directives die elkaar tegenspreken, of ze houden geen rekening met URL-parameters en querystrings, waardoor gewenste content wordt geblokkeerd of ongewenste content toch toegankelijk blijft. Het testen van je configuratie met speciale robots.txt-validators vóór livegang helpt deze fouten te voorkomen.
Veelgemaakte fouten om te vermijden:
Google-Extended is een bijzondere case in robots.txt-configuratie omdat het fungeert als controletoken in plaats van als traditionele crawler; dit onderscheid begrijpen is essentieel voor een doordachte blokkadebeslissing. In tegenstelling tot Googlebot, die je site crawlt om content te indexeren voor Google Search, is Google-Extended een signaal waarmee je bepaalt of je content gebruikt mag worden voor het trainen van Google’s Gemini AI-modellen en het aandrijven van de AI Overviews-functie in zoekresultaten. Door Google-Extended te blokkeren voorkom je dat je content wordt gebruikt voor Gemini-training en AI Overviews, maar behoud je je zichtbaarheid in de reguliere zoekresultaten—Googlebot blijft je site gewoon indexeren. Dit heeft grote gevolgen: blokkeren betekent dat je content niet verschijnt in AI Overviews, die steeds prominenter worden en veel verkeer kunnen opleveren, maar beschermt je tegen training door een concurrerend AI-model. Toestaan betekent dat je content wellicht in AI Overviews te zien is (wat verkeer kan opleveren), maar ook bijdraagt aan de trainingsdata van Gemini, wat later kan concurreren met je eigen content of businessmodel. Uitgevers moeten hun eigen situatie goed afwegen—nieuwsorganisaties en contentmakers die afhankelijk zijn van direct verkeer kunnen baat hebben bij blokkeren, terwijl anderen de zichtbaarheid van AI Overviews wellicht juist willen. Deze keuze moet bewust gemaakt worden en niet standaard, omdat het grote invloed heeft op je lange termijn zichtbaarheid en verkeerspatronen in Google.
Het testen van je robots.txt-configuratie vóór livegang is absoluut noodzakelijk, omdat fouten grote gevolgen kunnen hebben voor je zoekzichtbaarheid en contentbescherming. Google Search Console biedt een ingebouwde robots.txt-tester waarmee je kunt controleren of specifieke user agents toegang krijgen tot bepaalde URL’s op je site—je voert bijvoorbeeld “GPTBot” en een URL in, en Google laat zien of die bot toegang heeft volgens je configuratie. De Merkle Robots.txt Tester biedt vergelijkbare functionaliteit met een gebruiksvriendelijke interface en duidelijke uitleg over de interpretatie van je regels. TechnicalSEO.com heeft ook een gratis testtool die je syntax valideert en precies laat zien hoe verschillende bots worden behandeld. Voor uitgebreidere monitoring biedt Knowatoa AI Search Console gespecialiseerde tools om AI-crawleractiviteit te volgen en je regels te testen tegen de specifieke bots die je wilt blokkeren. Je workflow moet bestaan uit het uploaden van robots.txt naar een stagingomgeving, controleren of belangrijke pagina’s toegankelijk blijven, bevestigen dat bedoelde AI-bots daadwerkelijk worden geweerd, en je serverlogs monitoren op onverwachte crawleractiviteit. Controleer ook of je Sitemap-verwijzing klopt en zoekmachines je content normaal kunnen bereiken—je wilt AI-trainingcrawlers blokkeren zonder per ongeluk legitiem zoekverkeer te blokkeren. Pas na grondige tests mag je live gaan, en zelfs daarna is het verstandig om de eerste week je logs nauwgezet te blijven volgen.
Testingtools:
Robots.txt is een nuttige eerste verdedigingslinie, maar werkt op basis van goed vertrouwen—bots die zich aan het protocol houden volgen je regels, maar kwaadwillende of slecht ontworpen crawlers kunnen robots.txt negeren en alsnog je content bezoeken. Branchegegevens suggereren dat robots.txt ongeveer 40–60% van de ongewenste crawlers effectief tegenhoudt; de rest negeert het protocol of probeert het te omzeilen. Voor uitgevers die sterkere bescherming willen, zijn extra lagen noodzakelijk. Cloudflare’s Web Application Firewall (WAF) maakt het mogelijk om verkeer te blokkeren op basis van user-agent-strings, IP-adressen of gedragspatronen, zodat je je kunt weren tegen bots die robots.txt negeren. Servertools als .htaccess (op Apache) of vergelijkbare configuraties op Nginx kunnen specifieke user agents of IP-reeksen blokkeren vóórdat verzoeken je applicatie bereiken. IP-blokkering kan effectief zijn als je weet welke IP-reeksen specifieke crawlers gebruiken, maar vereist doorlopend onderhoud. Tools als Fail2ban blokkeren automatisch IP’s met verdacht gedrag, zoals extreem veel verzoeken of toegang tot gevoelige paden. Deze extra bescherming vereist zorgvuldige configuratie—te agressief blokkeren kan legitiem verkeer uitsluiten, bijvoorbeeld echte gebruikers achter VPN’s of bedrijfsproxies die een IP-reeks delen met bekende crawlers. De beste aanpak combineert robots.txt als beleefde eerste stap, user-agentblokkade op serverniveau voor bots die robots.txt negeren, en gedragsmonitoring om geavanceerde crawlers te vangen die user agents spoofen of verspreide IP’s gebruiken. Implementeer deze lagen stapsgewijs en test elke stap om te voorkomen dat je per ongeluk legitiem verkeer blokkeert, terwijl je toch je contentdoelen bereikt.
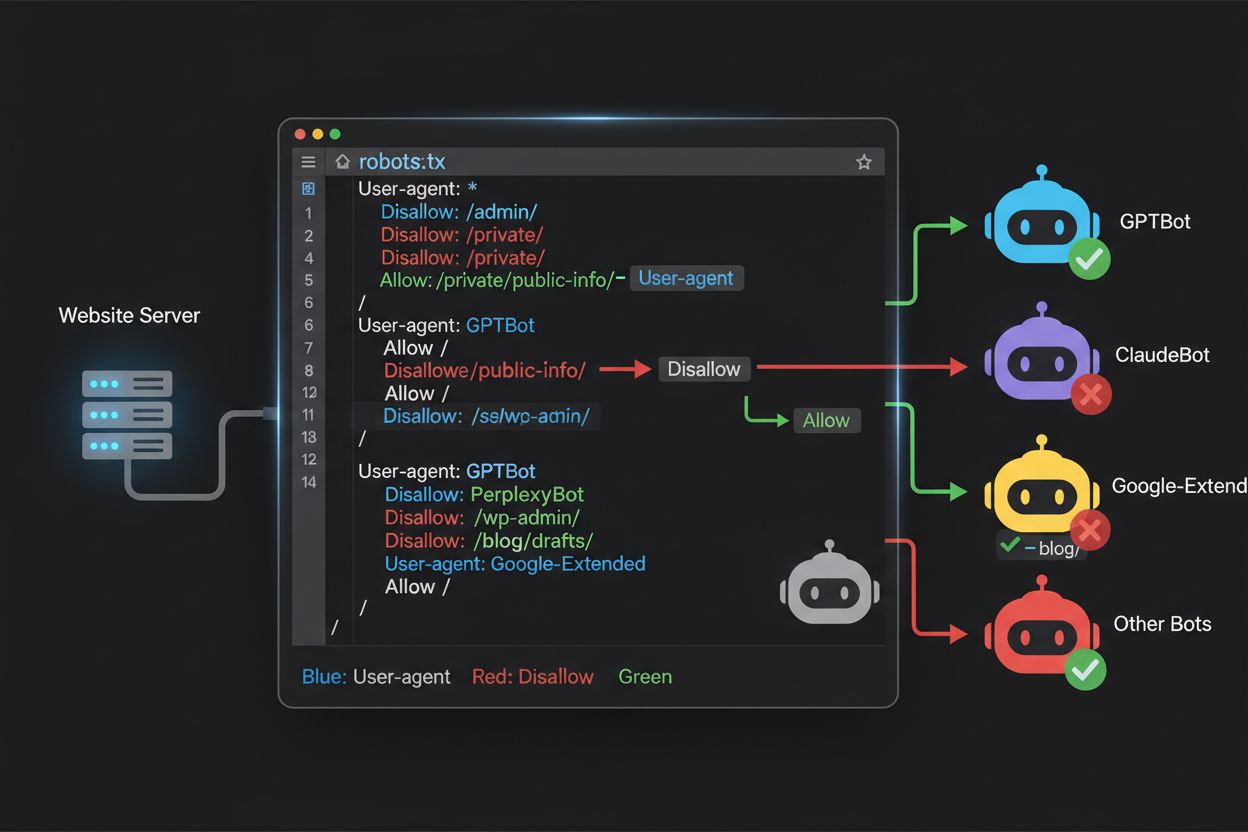
Weten wat je site daadwerkelijk bezoekt is essentieel om te controleren of je robots.txt-configuratie werkt én om nieuwe crawlers te ontdekken die mogelijk geblokkeerd moeten worden. Analyse van serverlogs is hierbij de belangrijkste methode—je webserverlogs (Apache access logs, Nginx logs, etc.) bevatten gedetailleerde gegevens van elk verzoek aan je site, inclusief user agent, IP-adres, tijdstip en opgevraagde resource. Met command-line tools als grep zoek je eenvoudig in je logs naar specifieke user agents; bijvoorbeeld “grep ‘GPTBot’ /var/log/apache2/access.log” toont alle verzoeken van GPTBot, zodat je kunt controleren of je regels werken. Geavanceerdere analyses kunnen crawlfrequentie per bot inzichtelijk maken, welke pagina’s worden bezocht en of bots je robots.txt respecteren. Automatische monitoringoplossingen analyseren continu je logs en waarschuwen bij nieuwe of onverwachte crawlers—waardevol in een snel veranderend AI-crawlerlandschap. Sommige uitgevers gebruiken logplatforms als ELK Stack, Splunk of cloudoplossingen om crawleractiviteit op meerdere servers te centraliseren en te analyseren. Omdat het AI-crawlerlandschap snel verandert, is monitoring geen eenmalige taak maar een doorlopend proces—nieuwe bots verschijnen, bestaande bots veranderen hun user-agent-string en gedrag past zich aan. Een vast monitoringschema (wekelijks of maandelijks logs doornemen) helpt je proactief je robots.txt aan te passen en problemen te voorkomen.
Je robots.txt-configuratie voor AI-crawlers is in de kern een inkomstenbeslissing en verdient dezelfde strategische overweging als elke andere zakelijke keuze met flinke financiële impact. Door trainingcrawlers onbeperkt toegang te geven tot je content, draag je bij aan AI-modellen die later kunnen concurreren met je verkeer en inkomsten—als je model afhankelijk is van direct verkeer, zichtbaarheid in zoekmachines of advertentie-inkomsten, lever je gratis trainingsdata aan bedrijven die concurrerende producten bouwen. Blokkeer je alle AI-crawlers, dan verlies je potentiële zichtbaarheid in AI-zoekresultaten en verkeer van AI-assistenten, een groeiend kanaal voor contentontdekking. De optimale strategie hangt af van jouw businessmodel: advertentiegedreven uitgevers kunnen baat hebben bij zoekcrawlers toestaan (meer verkeer, meer advertentie-inkomsten) en trainingcrawlers blokkeren (geen verkeer), terwijl abonnementsmodellen juist agressiever blokkeren om hun content te beschermen tegen samenvattingen of replicatie door AI. Uitgevers die focussen op merkzichtbaarheid of thought leadership kunnen AI-zoekzichtbaarheid juist omarmen als distributiekanaal. De kern: maak deze keuze bewust en niet per ongeluk—veel uitgevers hebben robots.txt nooit afgestemd op AI-crawlers en staan daarmee standaard alles toe, wat neerkomt op een passieve keuze om hun content voor AI-training beschikbaar te stellen. Overweeg ook schema markup voor correcte bronvermelding als je content door AI-systemen wordt gebruikt, zodat verkeer en erkenning terugvloeien naar je site. Je robots.txt-configuratie moet een bewuste zakelijke strategie weerspiegelen en regelmatig worden herzien naarmate het AI-landschap en je prioriteiten veranderen.
Het AI-crawlerlandschap verandert ongekend snel: nieuwe bedrijven lanceren AI-producten, bestaande bedrijven introduceren nieuwe crawlers en user-agent-strings wijzigen of breiden uit. Je robots.txt-configuratie mag dus geen statisch bestand zijn, maar moet minimaal elk kwartaal worden herzien. Stel een proces in om brancheberichten over nieuwe AI-crawlers te volgen, abonneer je op relevante nieuwsbrieven of blogs en controleer je serverlogs regelmatig op onbekende user agents die kunnen wijzen op nieuwe crawlers. Ontdek je nieuwe crawlers, onderzoek dan hun doel en businessmodel om te bepalen of ze passen bij je contentstrategie, en werk je robots.txt direct bij. Monitor daarnaast het effect van je configuratie met statistieken als crawlerverkeer, de verhouding tussen crawler- en gebruikersverkeer en eventuele veranderingen in je organische zichtbaarheid of verkeer uit AI-zoekresultaten. Sommige uitgevers merken na een paar maanden dat hun aanvankelijke strategie bijstelling vraagt—misschien had het blokkeren van een bepaalde crawler onverwachte gevolgen, of bleek het toestaan van sommige crawlers meer waardevol verkeer op te leveren. Wees bereid je strategie bij te stellen op basis van echte data. Communiceer je robots.txt-strategie ook binnen je organisatie—SEO, content en management moeten weten waarom bepaalde crawlers geblokkeerd of toegestaan zijn, zodat keuzes consistent en doordacht blijven naarmate je organisatie evolueert. Deze voortdurende aandacht voor crawlermanagement zorgt ervoor dat je contentstrategie effectief en afgestemd blijft op je bedrijfsdoelen, terwijl het AI-landschap zich verder ontwikkelt.
Nee. Het blokkeren van AI-training crawlers zoals GPTBot, ClaudeBot en CCBot heeft geen invloed op je Google- of Bing-zoekresultaten. Traditionele zoekmachines gebruiken andere crawlers (Googlebot, Bingbot) die onafhankelijk werken. Blokkeer deze alleen als je volledig uit de zoekresultaten wilt verdwijnen.
Grote crawlers van OpenAI (GPTBot), Anthropic (ClaudeBot), Google (Google-Extended) en Perplexity (PerplexityBot) geven officieel aan dat ze robots.txt-richtlijnen volgen. Kleinere of minder transparante bots kunnen je configuratie echter negeren, daarom bestaan er gelaagde beschermingsstrategieën.
Dat hangt af van je strategie. Door alleen training crawlers (GPTBot, ClaudeBot, CCBot) te blokkeren, voorkom je dat je content wordt gebruikt voor modeltraining, terwijl zoekgerichte crawlers je helpen zichtbaarheid in AI-zoekresultaten te behouden. Volledige blokkade verwijdert je geheel uit AI-ecosystemen.
Bekijk je configuratie minimaal elk kwartaal. AI-bedrijven introduceren regelmatig nieuwe crawlers. Anthropic heeft bijvoorbeeld hun 'anthropic-ai' en 'Claude-Web'-bots samengevoegd tot 'ClaudeBot', waardoor de nieuwe bot tijdelijk onbeperkte toegang kreeg tot sites die hun regels nog niet hadden bijgewerkt.
Robots.txt is een bestand in de root van je domein en geldt voor alle pagina's, terwijl meta robots-tags HTML-richtlijnen zijn op individuele pagina's. Robots.txt wordt als eerste gecontroleerd en kan crawlers direct weren, terwijl meta-tags alleen gelezen worden als de pagina wordt bezocht. Gebruik beide voor volledige controle.
Ja. Je kunt pad-specifieke Disallow-regels in robots.txt gebruiken (bijvoorbeeld 'Disallow: /premium/' om alleen premium content te blokkeren) of meta robots-tags toepassen op individuele pagina's. Zo bescherm je gevoelige content en geef je crawlers toegang tot andere delen.
Als een bot robots.txt negeert, heb je extra beschermingsmethoden nodig, zoals server-level blokkades (.htaccess), IP-blokkering of WAF-regels. Robots.txt stopt ongeveer 40-60% van de ongewenste crawlers, dus gelaagde bescherming is belangrijk voor volledige verdediging.
Gebruik testtools zoals de robots.txt-tester van Google Search Console, de Merkle Robots.txt Tester of TechnicalSEO.com om je configuratie te valideren. Controleer je serverlogs op crawleractiviteit om te verifiëren dat geblokkeerde bots worden geweerd en toegestane bots toegang krijgen tot je content.
Robots.txt is slechts de eerste stap. Gebruik AmICited om te volgen welke AI-systemen jouw content citeren, hoe vaak ze naar jou verwijzen en zorg voor correcte attributie bij GPT's, Perplexity, Google AI Overviews en meer.
Ontdek hoe je AI-crawlers selectief kunt toestaan of blokkeren op basis van zakelijke doelstellingen. Implementeer differentiële crawler-toegang om content te b...

Ontdek hoe Web Application Firewalls geavanceerde controle bieden over AI-crawlers, verder dan robots.txt. Implementeer WAF-regels om je content te beschermen t...

Compleet naslagwerk over AI crawlers en bots. Identificeer GPTBot, ClaudeBot, Google-Extended en meer dan 20 andere AI-crawlers met user agents, crawl rates en ...
Cookie Toestemming
We gebruiken cookies om uw browse-ervaring te verbeteren en ons verkeer te analyseren. See our privacy policy.