Geavanceerde GEO Targeting: Functies, Mogelijkheden & Implementatie
Ontdek hoe geavanceerde geotargeting eruitziet in moderne digitale marketing. Lees meer over verfijnde locatiegebaseerde strategieën, gedragsmatige targeting en...
7 min lezen

Beheers GEO-experimenten met onze uitgebreide gids over controlegroepen en variabelen. Leer hoe je geografische experimenten ontwerpt, uitvoert en analyseert voor nauwkeurige marketingmeting en AI-zichtbaarheidstracking.
GEO-experimenten, ook wel geo lift tests of geografische experimenten genoemd, vertegenwoordigen een fundamentele verschuiving in de manier waarop marketeers de echte impact van hun campagnes meten. Deze experimenten verdelen geografische regio’s in test- en controlegroepen, waardoor marketeers het incrementele effect van marketinginterventies kunnen isoleren zonder afhankelijk te zijn van tracking op individueel niveau. In een tijdperk waarin privacyregelgeving zoals GDPR en CCPA strenger wordt en third-party cookies verdwijnen, bieden GEO-experimenten een privacy-veilige, statistisch robuuste alternatieve meetmethode. Door uitkomsten te vergelijken tussen regio’s die wel en niet aan marketing zijn blootgesteld, kunnen organisaties met vertrouwen de vraag beantwoorden: “Wat zou er zijn gebeurd zonder onze campagne?” Deze methodiek is essentieel geworden voor merken die echte incrementele waarde willen begrijpen en hun marketingbudget nauwkeurig willen optimaliseren.
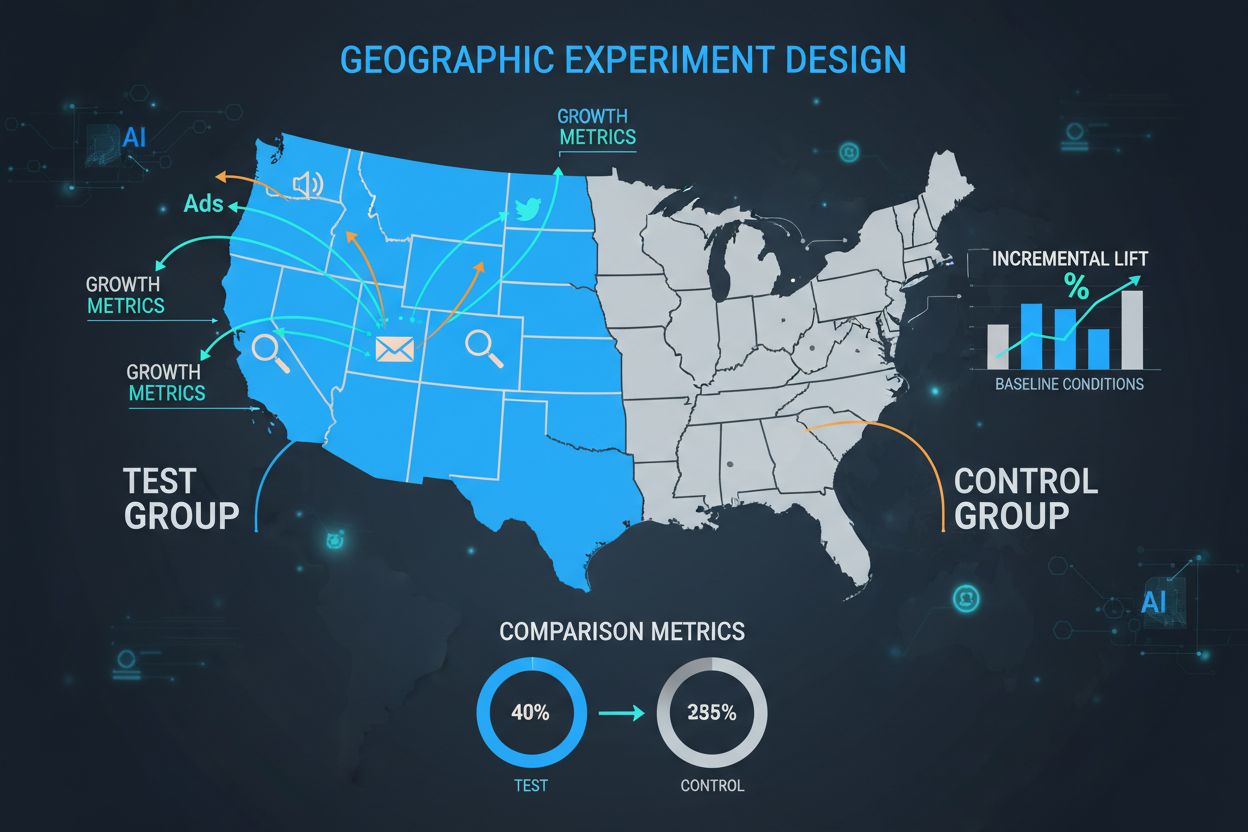
De controlegroep is de hoeksteen van elk GEO-experiment en dient als de kritische nulmeting waarmee alle behandelingseffecten worden vergeleken. Een controlegroep bestaat uit geografische regio’s die niet deelnemen aan de marketinginterventie, waardoor marketeers kunnen observeren wat er natuurlijk zou gebeuren zonder de campagne. De kracht van controlegroepen ligt in hun vermogen om externe factoren—seizoensinvloeden, concurrentieactiviteit, economische omstandigheden en markttrends—te compenseren, die anders de resultaten zouden verstoren. Goed ontworpen controlegroepen stellen onderzoekers in staat het echte causale effect van marketinginspanningen te isoleren, in plaats van enkel correlaties te observeren. De selectie van controlegebieden vereist zorgvuldige matching op meerdere dimensies, waaronder demografische kenmerken, historische prestatie-indicatoren, marktomvang en consumentengedragspatronen. Slechte selectie van controlegroepen leidt tot hoge variantie in resultaten, brede betrouwbaarheidsintervallen en uiteindelijk onbetrouwbare conclusies die tot kostbare verkeerde allocatie van marketingbudget kunnen leiden.
| Aspect | Controlegroep | Testgroep |
|---|---|---|
| Marketinginterventie | Geen (business as usual) | Actieve campagne |
| Doel | Nulmeting vaststellen | Impact meten |
| Geografische selectie | Gematcht aan testgroep | Primaire focus |
| Dataverzameling | Zelfde metrics | Zelfde metrics |
| Steekproefgrootte | Vergelijkbaar | Vergelijkbaar |
| Storende variabelen | Geminimaliseerd | Geminimaliseerd |
Succesvolle GEO-experimenten vereisen zorgvuldige beheersing van verschillende soorten variabelen die de uitkomsten en uitlegbaarheid beïnvloeden. Het begrijpen van het verschil tussen onafhankelijke, afhankelijke, controle- en verstorende variabelen is essentieel voor het ontwerpen van experimenten die bruikbare inzichten opleveren.
Onafhankelijke variabelen: Dit zijn de marketingtactieken die je actief manipuleert en test, zoals advertentiebudget, creatieve variaties, kanaalselectie, targetingparameters of promotionele aanbiedingen. De onafhankelijke variabele is hetgeen waarvan je het effect probeert te meten.
Afhankelijke variabelen: Dit zijn de uitkomsten die je meet om het effect van je marketinginterventie te beoordelen, waaronder omzet, conversies, klantacquisitie, merkbekendheid, websiteverkeer en, belangrijk voor moderne marketeers, AI-vermelding-zichtbaarheid en merkvermeldingen in AI-systemen.
Controlevariabelen: Dit zijn factoren die je constant houdt in zowel test- als controlegroepen voor een eerlijke vergelijking, zoals consistente boodschap, aanbodstructuur, campagneduur en mediamix.
Verstorende variabelen: Dit zijn onverwachte externe factoren die onafhankelijk van je marketinginterventie de resultaten kunnen beïnvloeden, zoals campagnes van concurrenten, natuurrampen, grote nieuwsgebeurtenissen, seizoensfluctuaties en economische verschuivingen.
Meetvariabelen: Dit zijn de specifieke KPI’s en metrics die je volgt, waaronder incrementele lift, incrementele ROAS (iROAS), incrementele CAC (iCAC) en betrouwbaarheidsintervallen rond je schattingen.
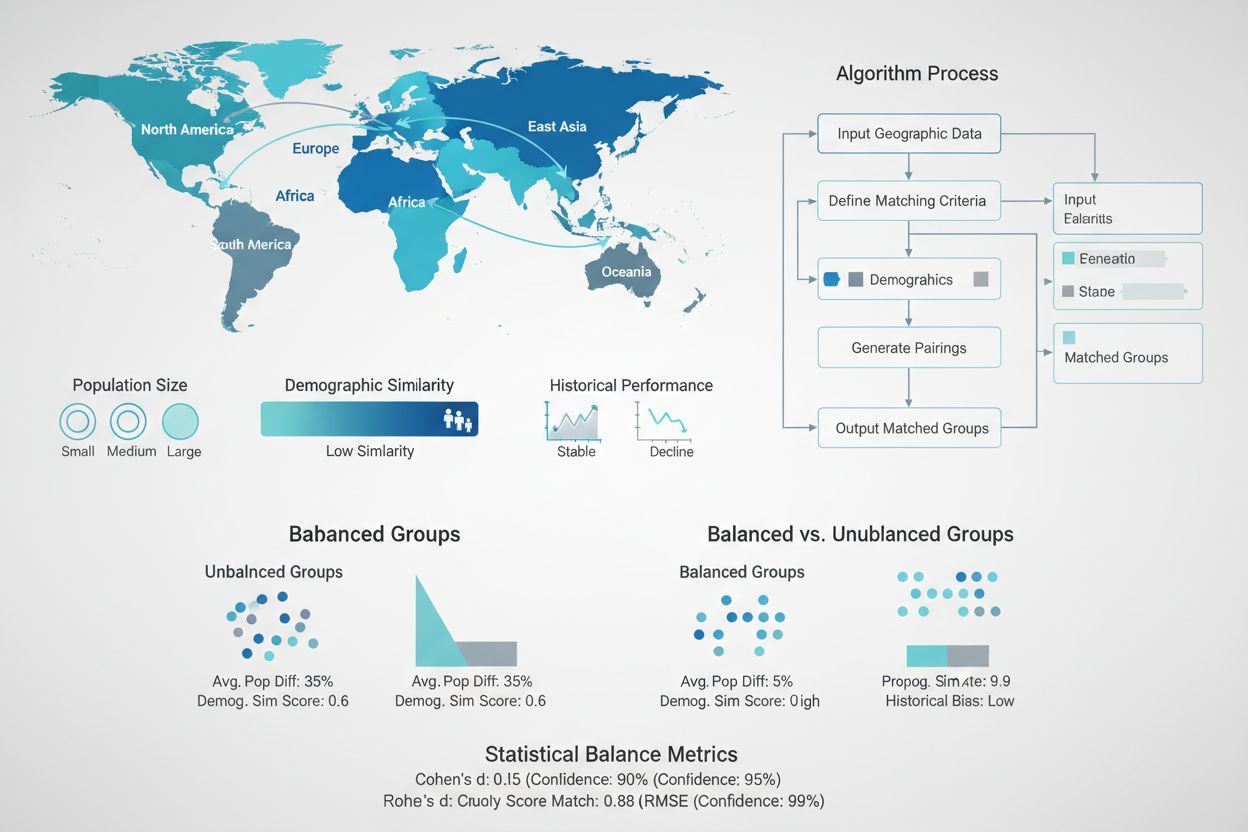
Het creëren van statistisch equivalente test- en controlegroepen is een van de belangrijkste, maar ook meest uitdagende aspecten van GEO-experimentontwerp. In tegenstelling tot gerandomiseerde gecontroleerde proeven met miljoenen individuele gebruikers, werken GEO-experimenten meestal met slechts tientallen tot honderden geografische eenheden, waardoor willekeurige toewijzing vaak onvoldoende is voor balans. Geavanceerde matching-algoritmen en optimalisatietechnieken zijn ontwikkeld om deze uitdaging te adresseren. Synthetische controlemethoden, geïntroduceerd door econometristen en populair gemaakt door bedrijven als Wayfair en Haus, gebruiken historische data om controlegebieden te identificeren en te wegen die het beste overeenkomen met de kenmerken van testgebieden. Deze algoritmen houden rekening met meerdere dimensies tegelijk—bevolkingsgrootte, demografische samenstelling, historische verkoopcijfers, mediaconsumptie en concurrentielandschap—om controlegroepen te creëren die als nauwkeurige tegenfeiten dienen. Het doel is om het verschil tussen test- en controlegroepen op alle pre-interventie metrics te minimaliseren, zodat eventuele waargenomen verschillen na de interventie met vertrouwen aan de marketinginzet kunnen worden toegeschreven in plaats van aan bestaande verschillen.
De statistische strengheid van GEO-experimenten onderscheidt ze van informele observaties of anekdotisch bewijs. Betrouwbaarheidsintervallen geven het bereik aan waarbinnen het echte effect waarschijnlijk valt, met een bepaalde mate van zekerheid (meestal 95%). Een smal interval duidt op hoge precisie en vertrouwen in je resultaten, terwijl een breed interval op aanzienlijke onzekerheid wijst. Bijvoorbeeld, als een GEO-experiment een stijging van 10% laat zien met een 95% betrouwbaarheidsinterval van ±2%, kun je redelijk zeker zijn dat het werkelijke effect tussen 8% en 12% ligt. Omgekeerd geeft een stijging van 10% met een interval van ±8% (tussen 2% en 18%) veel minder bruikbare informatie. De breedte van betrouwbaarheidsintervallen hangt af van verschillende factoren: steekproefgrootte (aantal regio’s), variatie in uitkomsten, testduur en de verwachte effectgrootte. Minimum detectable effect (MDE)-berekeningen helpen vooraf te bepalen of het voorgestelde experiment betrouwbaar de gewenste lift kan meten. Power-analyse zorgt ervoor dat je voldoende statistische kracht hebt—doorgaans 80% of hoger—om echte effecten te detecteren wanneer die er zijn, terwijl je Type I-fouten (valse positieven) en Type II-fouten (valse negatieven) onder controle houdt.
Zelfs goedbedoelde GEO-experimenten kunnen misleidende resultaten opleveren als veelvoorkomende valkuilen niet zorgvuldig worden vermeden. Het begrijpen van deze valkuilen en het implementeren van voorzorgsmaatregelen is essentieel voor betrouwbare meting.
Ongebalanceerde groepen: Wanneer test- en controlegebieden significant verschillen op belangrijke pre-interventie metrics, maakt de extra variantie het moeilijk om echte effecten te detecteren. Oplossing: Gebruik matching-algoritmen en synthetische controlemethoden om de groepen statistisch gelijkwaardig te maken op alle belangrijke dimensies.
Spill-over effecten: Gebruikers en mediablootstelling houden zich niet aan geografische grenzen. Mensen reizen tussen regio’s en digitale advertenties bereiken vaak doelgroepen buiten het beoogde gebied. Oplossing: Gebruik geografische grenzen die kruisbesmetting minimaliseren, houd rekening met pendelpatronen en gebruik geofencing-technologie voor nauwkeurige controle.
Onvoldoende testduur: Campagnes hebben tijd nodig om resultaten te genereren en klantreizen variëren in lengte. Korte testvensters missen uitgestelde conversie-effecten en seizoenspatronen. Oplossing: Voer experimenten minstens 4-6 weken uit, langer bij producten met een lange overwegingscyclus, en houd rekening met post-interventieperiodes.
Achteraf analyse aanpassen: Je analyseplan wijzigen nadat je voorlopige resultaten hebt gezien, introduceert bias en vergroot het aantal valse positieven. Oplossing: Stel vooraf je analysemethodologie, KPI’s en succescriteria vast voordat het experiment start.
Externe schokken negeren: Natuurrampen, concurrentieacties, grote nieuwsgebeurtenissen en economische verschuivingen kunnen resultaten ongeldig maken. Oplossing: Houd gedurende de testperiode storende gebeurtenissen in de gaten en wees bereid om experimenten te verlengen of opnieuw uit te voeren als er significante verstoringen optreden.
Onvoldoende steekproefgrootte: Te weinig regio’s beperkt de statistische kracht en zorgt voor brede betrouwbaarheidsintervallen. Oplossing: Voer vooraf een power-analyse uit om het minimum aantal benodigde regio’s voor je verwachte effectgrootte te bepalen.
Incrementele waarde vertegenwoordigt de echte causale impact van marketing—het verschil tussen wat er daadwerkelijk is gebeurd en wat er zou zijn gebeurd zonder de interventie. Lift is de kwantitatieve maatstaf van deze incrementele waarde, berekend als het verschil in belangrijke metrics tussen test- en controlegroepen. Als testgebieden €1.000.000 aan omzet genereren en gematchte controlegebieden €900.000, is de absolute lift €100.000. De procentuele lift is dan 11,1% (€100.000 / €900.000). Rauwe liftcijfers houden echter geen rekening met de kosten van de marketinginterventie. Incrementele ROAS (iROAS) deelt de incrementele omzet door de incrementele uitgaven en toont het rendement per extra geïnvesteerde euro. Als het testgebied €50.000 extra heeft besteed aan marketing om de €100.000 incrementele omzet te realiseren, is de iROAS 2,0x. Evenzo meet de incrementele CAC (iCAC) de kosten om elke extra klant te werven, essentieel voor het beoordelen van kanaalefficiëntie. Deze metrics worden bijzonder waardevol als ze gekoppeld zijn aan merkzichtbaarheid—je meet dan niet alleen sales lift, maar ook hoe marketing AI-vermeldingen en merkvermeldingen in GPT’s, Perplexity en Google AI Overviews beïnvloedt.
Nu AI-systemen steeds vaker het startpunt zijn voor consumenten, is het meten van de impact van marketing op merkzichtbaarheid in AI-antwoorden cruciaal geworden. GEO-experimenten bieden een robuust kader om verschillende contentstrategieën en hun effecten op de frequentie en nauwkeurigheid van AI-vermeldingen te testen. Door experimenten uit te voeren waarbij bepaalde regio’s verbeterde contentoptimalisatie voor AI-zichtbaarheid ontvangen—betere gestructureerde data, helderdere merkboodschap, geoptimaliseerde contentformats—terwijl controlegebieden de basispraktijken behouden, kunnen marketeers de incrementele impact op AI-vermeldingen kwantificeren. Dit is vooral waardevol om te begrijpen welke contentformats, boodschappen en informatiestructuren AI-systemen prefereren bij het vermelden van bronnen. AmICited monitort deze experimenten door te volgen hoe vaak je merk voorkomt in AI-gegenereerde antwoorden in verschillende regio’s en tijdsperiodes, en biedt zo de databasis voor het meten van zichtbaarheidslift. De incrementele verbetering in zichtbaarheid kan vervolgens worden gekoppeld aan zakelijke uitkomsten: laten regio’s met meer AI-vermeldingen ook een stijging in websiteverkeer, merkzoekopdrachten of conversies zien? Deze koppeling maakt van AI-zichtbaarheid een meetbare business driver en geen ijdelheidsmetric, zodat je met vertrouwen budget kunt alloceren aan zichtbaarheid-gedreven initiatieven.
Naast eenvoudige difference-in-differences-analyses zijn er geavanceerde statistische methoden ontwikkeld om de nauwkeurigheid en betrouwbaarheid van GEO-experimenten te verhogen. De synthetic control-methode construeert een gewogen combinatie van controlegebieden die het pre-interventie traject van testgebieden het beste benadert, waardoor een nauwkeuriger tegenfeit ontstaat dan welk afzonderlijk controlegebied dan ook. Deze aanpak is vooral krachtig wanneer je veel potentiële controlegebieden hebt en alle beschikbare informatie wilt benutten. Bayesian structural time series (BSTS)-modellen, populair gemaakt door Google’s CausalImpact-pakket, breiden synthetic control uit met onzekerheidskwantificatie en probabilistische forecasting. BSTS-modellen leren de historische relatie tussen test- en controlegebieden tijdens de pre-interventieperiode en voorspellen vervolgens hoe het testgebied eruit zou hebben gezien zonder interventie. Het verschil tussen feitelijke en voorspelde waarden vertegenwoordigt het geschatte behandelingseffect, met credible intervals als maat voor onzekerheid. Difference-in-differences (DiD)-analyse vergelijkt de verandering in uitkomsten vóór en na de interventie tussen test- en controlegroepen, waardoor tijdsinvariante verschillen effectief worden verwijderd. Elke methode heeft zijn voor- en nadelen: synthetic control vereist veel controlegebieden maar veronderstelt geen parallelle trends; BSTS vangt complexe tijdsdynamiek op maar vraagt om zorgvuldige modelspecificatie; DiD is eenvoudig en intuïtief maar gevoelig voor schending van de parallelle trends-aanname. Moderne platforms zoals Lifesight en Haus automatiseren deze methoden, zodat marketeers kunnen profiteren van geavanceerde analyses zonder diepgaande statistische kennis.
Toonaangevende organisaties hebben de kracht van GEO-experimenten aangetoond met indrukwekkende resultaten. Wayfair ontwikkelde een integer optimalisatie-aanpak om honderden geografische eenheden toe te wijzen aan test- en controlegroepen, terwijl ze meerdere KPI’s tegelijk nauwkeurig balanceren. Zo konden ze gevoeligere experimenten uitvoeren met kleinere holdout-percentages. Uit analyse van honderden geo-tests door Polar Analytics blijkt dat synthetic control-methoden ongeveer vier keer zo nauwkeurig zijn als eenvoudige matched market-benaderingen, met smallere betrouwbaarheidsintervallen die meer vertrouwen geven bij besluitvorming. Haus introduceerde fixed geo-tests specifiek voor out-of-home en retailcampagnes, waar marketeers regio’s niet willekeurig kunnen toewijzen maar toch het effect van vooraf bepaalde geografische uitrol willen meten. Hun case study met Jones Road Beauty liet zien hoe fixed geo-tests de incrementele impact van billboardcampagnes in specifieke markten nauwkeurig meten. Lifesight’s werk met grote merken in retail, CPG en DTC laat zien dat geautomatiseerde geo-testplatformen de testduur kunnen verkorten van 8-12 naar 4-6 weken en de nauwkeurigheid verbeteren dankzij geavanceerde matching-algoritmen. Deze praktijkvoorbeelden tonen consequent aan dat correct ontworpen en uitgevoerde GEO-experimenten verrassende inzichten opleveren: kanalen waarvan werd aangenomen dat ze zeer effectief waren, blijken vaak slechts beperkt incrementeel, terwijl ondergewaardeerde kanalen sterke incrementele opbrengsten laten zien, wat leidt tot aanzienlijke budgetherallocaties.
Een succesvol GEO-experiment vereist gestructureerde uitvoering in meerdere fasen:
Definieer heldere doelstellingen en KPI’s: Bepaal wat je wilt meten (omzet, conversies, merkbekendheid, AI-vermeldingen) en stel specifieke, meetbare doelen. Zorg voor afstemming met bedrijfsprioriteiten en realistische verwachtingen over effectgrootte.
Selecteer en match geografische regio’s: Kies regio’s die je doelgroep representeren en voldoende datavolume hebben. Gebruik matching-algoritmen om controlegebieden te vinden die testgebieden op historische metrics nauwkeurig spiegelen.
Zorg voor data-gereedheid: Controleer of je de KPI’s in alle regio’s nauwkeurig kunt volgen gedurende de testperiode. Voer data-audits uit op kwaliteit, volledigheid en consistentie.
Ontwerp experimenteerparameters: Bepaal de testduur (meestal minimaal 4-6 weken), specificeer de marketinginterventie nauwkeurig en documenteer alle aannames en succescriteria vóór de start.
Voer de campagne gelijktijdig uit: Start de campagne in testgebieden en handhaaf de baseline in controlegebieden op hetzelfde moment. Stem teams op elkaar af voor consistente uitvoering.
Monitor continu: Volg dagelijks belangrijke metrics om onverwachte patronen, externe schokken of implementatieproblemen te detecteren die de resultaten kunnen beïnvloeden.
Verzamel en analyseer data: Verzamel data uit alle regio’s en pas je vooraf bepaalde analysemethodologie toe. Bereken lift, betrouwbaarheidsintervallen en secundaire metrics.
Interpreteer resultaten zorgvuldig: Beoordeel niet alleen statistische significantie maar ook praktische relevantie. Kijk naar de breedte van het betrouwbaarheidsinterval, effectgrootte en impact op de business.
Documenteer en deel bevindingen: Maak een uitgebreid rapport van methodologie, resultaten en leerpunten. Deel bevindingen met stakeholders om toekomstige strategie te informeren.
Plan volgende experimenten: Gebruik leerpunten voor de volgende testcyclus, bouw aan een continue cultuur van experimenteren en optimaliseren.
Het GEO-experimentatielandschap is sterk geëvolueerd, met gespecialiseerde platforms die veel van de complexiteit automatiseren. Haus biedt GeoLift voor standaard gerandomiseerde geo-tests en Fixed Geo Tests voor vooraf bepaalde geografische uitrol, met name sterk in omnichannel-meting. Lifesight automatiseert het volledige proces van ontwerp tot analyse, met eigen matching-algoritmen en synthetische controlemethodologie die testduur verkort en precisie verhoogt. Polar Analytics focust op incrementeel testen, met nadruk op causale liftmeting en betrouwbaarheid van intervallen. Paramark is gespecialiseerd in marketing mix modeling, verrijkt met validatie via geo-experimenten, zodat merken MMM-voorspellingen kunnen kalibreren aan echte testresultaten. Let bij het evalueren van platforms op: automatische regio-matching en balancing, ondersteuning voor digitale en offline kanalen, real-time monitoring en early stopping, transparante methodologie en betrouwbaarheidsrapportage en integratie met je bestaande datainfrastructuur. AmICited vult deze platforms aan door de zichtbaarheidsmeting te verzorgen—het tracken van hoe je merk verschijnt in AI-gegenereerde antwoorden in test- en controlegebieden, zodat je de incrementele waarde van zichtbaarheid-gerichte marketinginitiatieven kunt meten.
Succesvolle GEO-experimentatie vraagt om bewezen best practices die betrouwbaarheid en bruikbaarheid maximaliseren:
Begin met duidelijke hypothesen: Formuleer vooraf specifieke, toetsbare hypothesen. Voorkom dat je blind meerdere variabelen tegelijk test zonder duidelijke voorspellingen.
Investeer in juiste groepsmatching: Neem vooraf de tijd om test- en controlegroepen echt vergelijkbaar te maken. Slechte matching ondermijnt alle verdere analyse en verspilt middelen.
Laat tests lang genoeg lopen: Weersta de verleiding om vroegtijdig te stoppen als resultaten veelbelovend lijken. Vroegtijdig stoppen introduceert bias en verhoogt het aantal valse positieven. Hou je aan de volledige geplande duur.
Monitor op storende factoren: Houd externe gebeurtenissen, concurrentieacties en marktomstandigheden actief in de gaten. Wees bereid om te verlengen of te herhalen als er significante verstoringen optreden.
Documenteer alles: Leg het experimentontwerp, uitvoering, analyse en resultaten gedetailleerd vast. Deze documentatie maakt leren, herhaling en institutionele kennisopbouw mogelijk.
Bouw een testcultuur: Ga verder dan losse experimenten en bouw systematische testprogramma’s op. Elk experiment moet het volgende informeren, zodat een leercyclus en optimalisatie ontstaat.
Koppel aan bedrijfsresultaten: Zorg ervoor dat experimenten meten wat direct invloed heeft op bedrijfsdoelstellingen. Vermijd ijdelheidsmetrics die niet leiden tot omzet of strategische doelen.
GEO-experimenten testen op geografisch/regio-niveau om de incrementele waarde van campagnes te meten die niet op individueel gebruikersniveau getest kunnen worden, terwijl A/B-tests individuele gebruikers randomiseren voor digitale optimalisatie. GEO-experimenten zijn beter geschikt voor offline media, upper-funnel campagnes en het meten van echte causale impact, terwijl A/B-tests uitblinken in het optimaliseren van digitale ervaringen met snellere resultaten.
Meestal minimaal 4-6 weken, afhankelijk van je conversiecyclus en seizoensinvloeden. Langere testen leveren betrouwbaardere resultaten op, maar brengen hogere kosten met zich mee. De testduur moet lang genoeg zijn om de volledige klantreis te omvatten en rekening te houden met uitgestelde conversie-effecten.
Er is geen vaste minimum, maar je hebt voldoende datavolume nodig om statistische significantie te bereiken. Over het algemeen heb je genoeg regio's en transacties nodig om het verwachte effect met voldoende statistische kracht te detecteren (meestal 80% of hoger). Kleinere markten vereisen langere testperiodes.
Gebruik geografische grenzen die kruisbesmetting minimaliseren, houd rekening met pendelpatronen en mediabereik, gebruik geofencing-technologie voor nauwkeurige controle en selecteer regio's die geografisch geïsoleerd zijn. Spill-over effecten ontstaan wanneer gebruikers of mediablootstelling oversteken tussen test- en controlegebieden, waardoor resultaten verwateren.
De standaard is 95% betrouwbaarheid (p < 0,05), wat betekent dat je 95% zeker kunt zijn dat het waargenomen effect echt is en niet door toeval. Houd echter rekening met je zakelijke context—de kosten van valse positieven versus valse negatieven—bij het bepalen van je betrouwbaarheidsdrempel.
Ja, via enquêtes, brand lift studies en AI-vermeldingstracking. Je kunt meten hoe marketing invloed heeft op merkbekendheid, -voorkeur en vooral hoe vaak je merk verschijnt in AI-gegenereerde antwoorden in verschillende regio's, waardoor je incrementele zichtbaarheid kunt meten.
Natuurrampen, campagnes van concurrenten, grote nieuwsgebeurtenissen en economische verschuivingen kunnen resultaten ongeldig maken door verstorende variabelen te introduceren. Houd deze gedurende je test in de gaten en wees bereid om de testperiode te verlengen of het experiment opnieuw te doen als er significante verstoringen optreden.
GEO-experimenten betalen zichzelf doorgaans terug door verspilling aan ineffectieve kanalen te voorkomen en het mogelijk te maken budget met vertrouwen te verschuiven naar goed presterende tactieken. Ze bieden de werkelijke waarheid die alle verdere metingen en beslissingen verbetert, van MMM-calibratie tot kanaaloptimalisatie.
GEO-experimenten laten zien hoe je marketing de zichtbaarheid beïnvloedt. AmICited volgt hoe AI-systemen je merk noemen in GPT's, Perplexity en Google AI Overviews, zodat je de echte incrementele verbetering van zichtbaarheid kunt meten.
Ontdek hoe geavanceerde geotargeting eruitziet in moderne digitale marketing. Lees meer over verfijnde locatiegebaseerde strategieën, gedragsmatige targeting en...
Discussie in de community over het testen van de effectiviteit van GEO-strategieën. Kaders en methoden om te meten of je Generative Engine Optimization-inspanni...
Leer hoe je de effectiviteit van GEO-strategieën meet met AI-zichtbaarheidsscores, frequentie van attributie, engagementpercentages en geografische prestatie-in...
Cookie Toestemming
We gebruiken cookies om uw browse-ervaring te verbeteren en ons verkeer te analyseren. See our privacy policy.