Schema Markup voor AI: Welke Types Zijn het Belangrijkst voor LLM-Zichtbaarheid
Ontdek welke schema types het belangrijkst zijn voor AI-zichtbaarheid. Leer hoe LLM’s gestructureerde data interpreteren en implementeer schema markup strategieën waarmee jouw merk wordt geciteerd in AI-antwoorden.
Gepubliceerd op Jan 3, 2026.Laatst gewijzigd op Jan 3, 2026 om 3:24 am
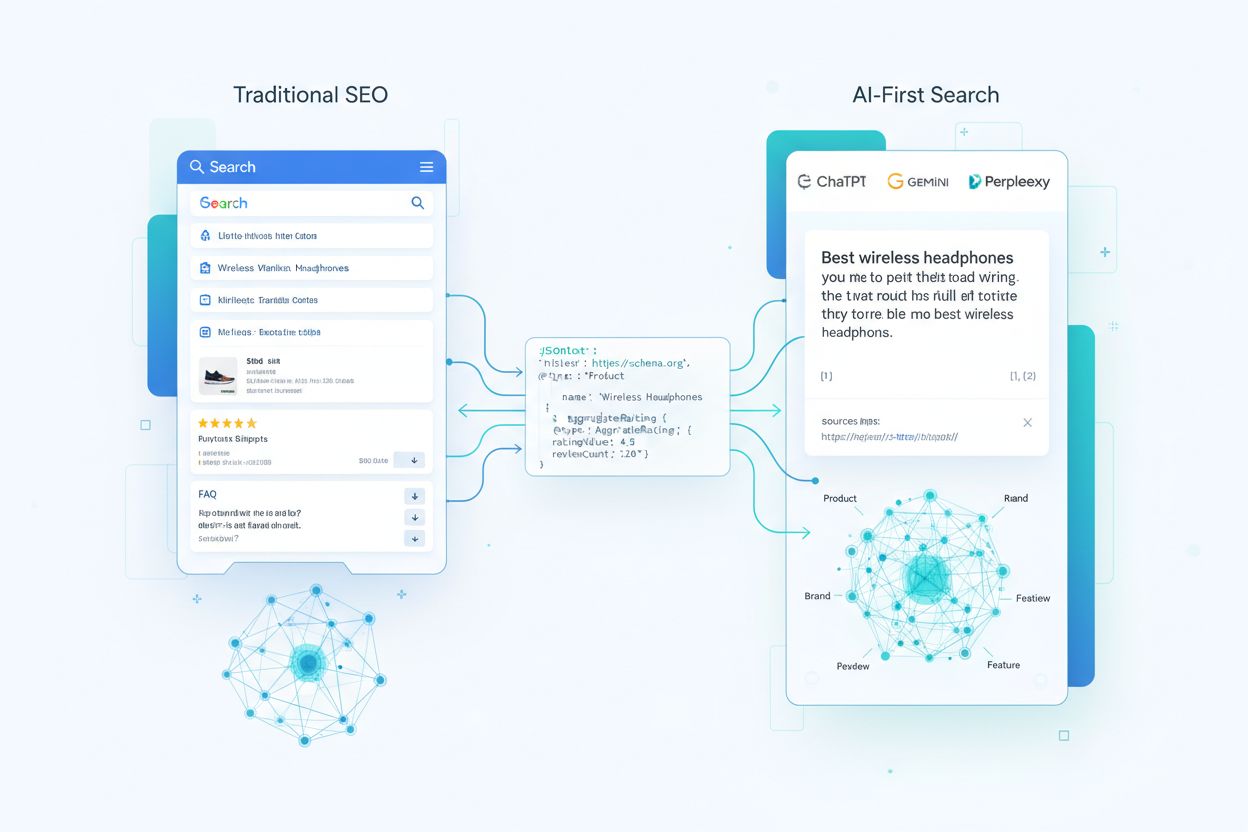
De Verschuiving van Rich Results naar LLM-Zichtbaarheid
Jarenlang draaide schema markup vooral om het winnen van rich results—die in het oog springende sterrenbeoordelingen, productkaarten en FAQ-accordeons in traditionele zoekresultaten. Vandaag raakt dat draaiboek achterhaald. Grote taalmodellen en AI-antwoordmachines interpreteren schema markup fundamenteel anders: niet voor cosmetische verbeteringen, maar om kennisgrafen te bouwen en entiteitsrelaties op schaal te begrijpen. Met circa 45 miljoen websites (12,4% van alle geregistreerde domeinen) die inmiddels een vorm van schema.org markup gebruiken, beschikken AI-systemen over ongekende hoeveelheden gestructureerde data om van te leren en op te vertrouwen. De verschuiving is ingrijpend: schema markup bepaalt nu of je merk wordt genoemd in AI-antwoorden, hoe accuraat modellen je producten en diensten weergeven, en of je content een betrouwbare bron wordt in een AI-first zoeklandschap.
Hoe AI-Systemen Schema Markup Echt Interpreteren
Begrijpen hoe AI-systemen schema markup verwerken, vraagt om het volgen van de reis van je gestructureerde data: van de eerste crawl tot LLM-gegenereerde antwoorden. Wanneer een crawler je pagina bezoekt, extraheert deze JSON-LD, microdata of RDFa-blokken en normaliseert die naast ongestructureerde tekst en media in een index. Deze gestructureerde data wordt onderdeel van een webbrede kennisgraaf, waar entiteiten via relaties verbonden zijn en worden voorzien van embeddings voor semantisch zoeken. In retrieval-augmented generation (RAG)-systemen kan schema direct worden opgenomen in de chunks die vectorindices vullen—één chunk kan zowel een productomschrijving als zijn JSON-LD markup bevatten, waardoor modellen zowel verhalende context als gestructureerde attributen krijgen. Verschillende LLM-architecturen gebruiken schema op hun eigen manier: sommige leggen modellen bovenop bestaande zoekindices en kennisgrafen, andere gebruiken multi-source retrieval pipelines die putten uit zowel gestructureerde als ongestructureerde content. De belangrijkste les: goed geïmplementeerde schema fungeert als contract met het model—het geeft in sterk gestructureerde vorm aan welke feiten op je pagina je als canoniek en betrouwbaar beschouwt.
Architecture Type
Schema Usage
Citation Impact
Key Properties
Traditionele Zoek + LLM-laag
Verbetert bestaande kennisgraaf
Hoog - modellen citeren goed gestructureerde bronnen
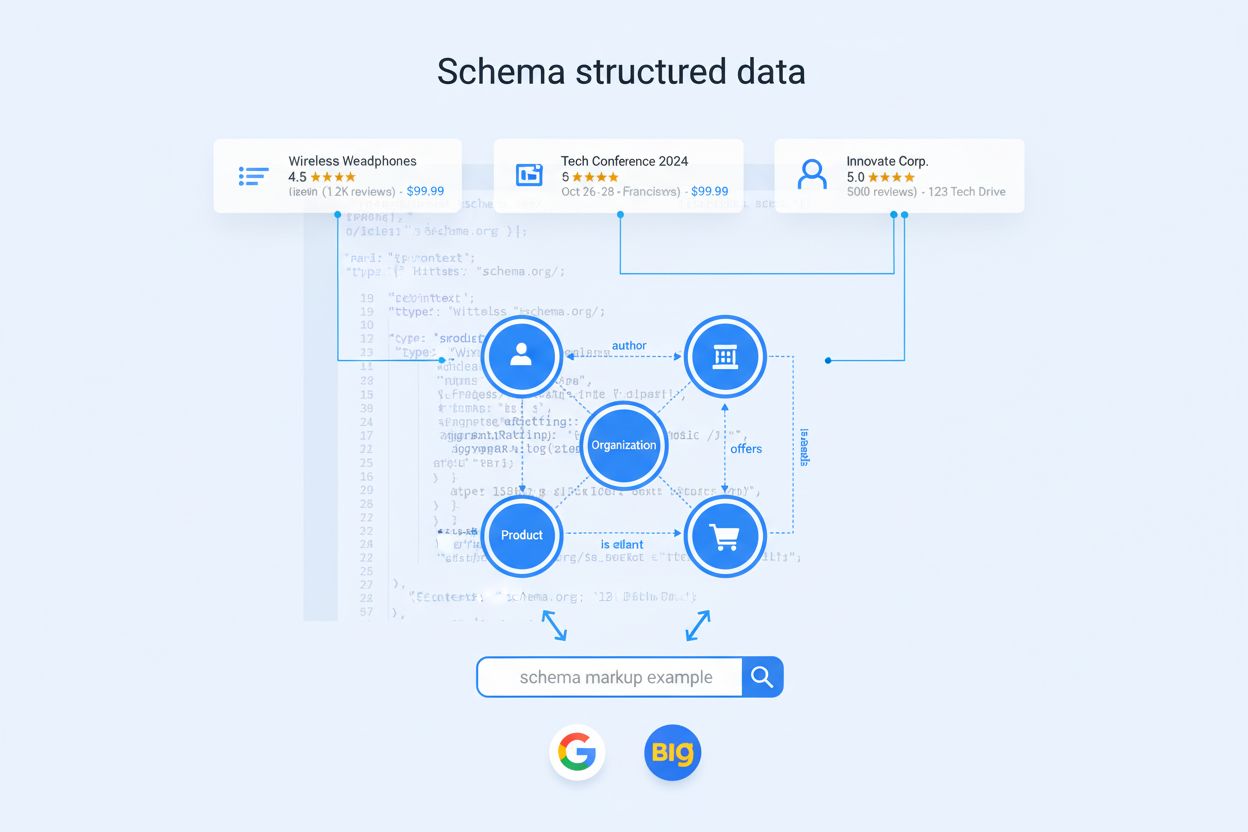
De Belangrijkste Schema Types voor AI-Zichtbaarheid
Niet alle schema types wegen even zwaar in het AI-tijdperk. Organization markup is het anker van je volledige entiteitsaftakking: het helpt modellen je merkidentiteit, autoriteit en relaties te begrijpen. Product schema is cruciaal voor e-commerce en retail: het stelt AI-systemen in staat kenmerken, prijzen en beoordelingen te vergelijken. Article en BlogPosting markup helpen modellen te bepalen welke longform content geschikt is voor uitlegvragen en thought leadership. Person schema is essentieel om auteursgeloofwaardigheid en expertschap toe te wijzen in AI-antwoorden. FAQPage markup sluit direct aan op conversatievragen die AI-assistenten beantwoorden. Voor SaaS- en B2B-bedrijven zijn SoftwareApplication en Service types net zo belangrijk; ze komen vaak voor in “beste tools voor X”-vergelijkingen en feature-evaluaties. Voor lokale bedrijven en zorgverleners bieden LocalBusiness en MedicalOrganization types geografische precisie en duidelijkheid over regelgeving. Echte differentiatie ontstaat echter niet door alleen het type te kiezen, maar juist door de geavanceerde properties die je toevoegt—consistentie over pagina’s, duidelijke entiteits-ID’s, en expliciete relatiemapping.
Geavanceerde Schema Properties die LLM’s Echt Gebruiken
Basisproperties zoals name, description en URL zijn tegenwoordig standaard; 72,6% van de pagina’s die op Google’s eerste pagina ranken gebruikt al een vorm van schema markup. De properties die echt verschil maken voor AI-zichtbaarheid vormen het ‘bindweefsel’ dat modellen helpt entiteiten te herkennen, relaties te begrijpen en betekenis te ontrafelen. Dit zijn de belangrijkste geavanceerde properties:
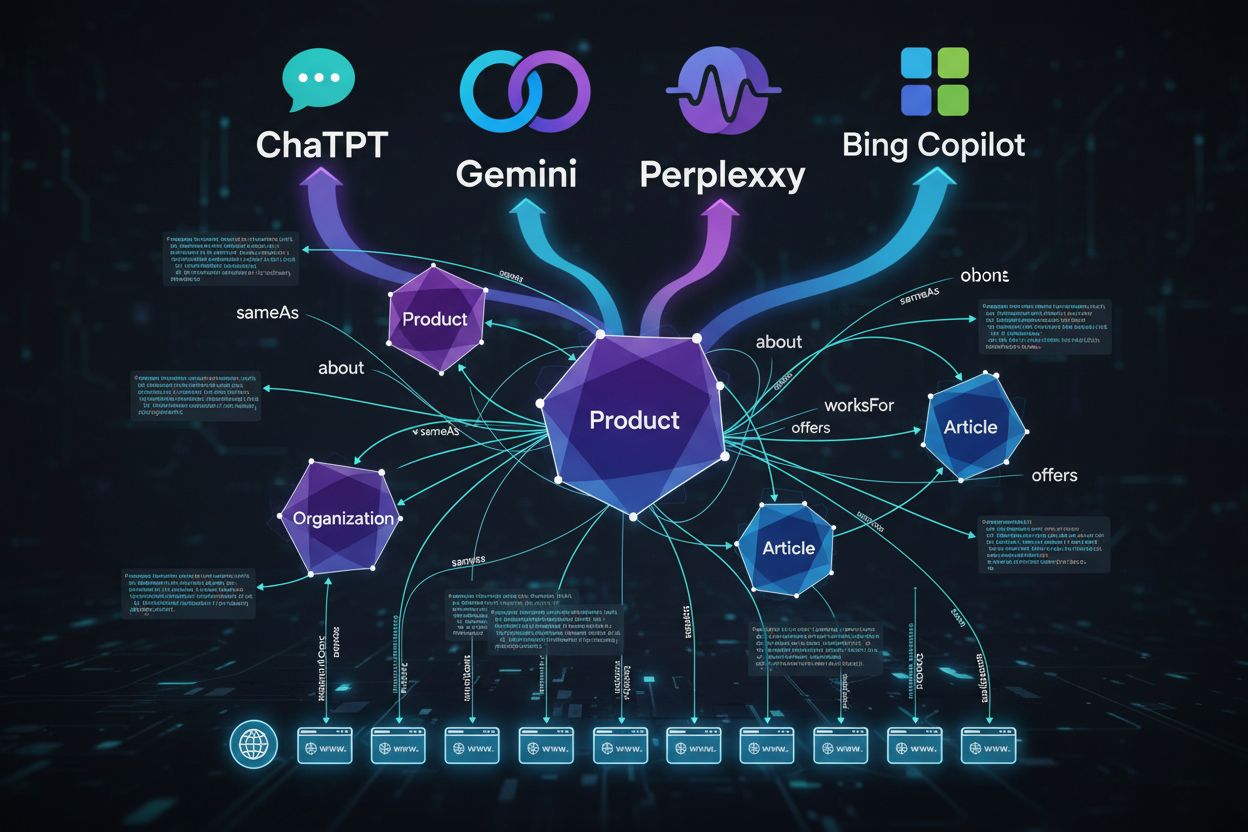
sameAs: Verbindt je entiteit met canonieke profielen op Wikipedia, LinkedIn, Crunchbase of fabrikantenwebsites, waardoor de kans dat een model je merk verwart met een naamgenoot fors afneemt
about/mentions: Verduidelijkt om welke onderwerpen en entiteiten een pagina echt draait, zodat modellen tussen veel ‘relevante’ bronnen de beste kiezen voor nuancevragen
@id: Geeft stabiele, unieke identifiers die consistente entiteitsresolutie op je hele site en het web mogelijk maken
additionalType: Geeft extra type-hints naast het primaire schema type, zodat modellen genuanceerde classificatie begrijpen
additionalProperty: Encodeert aangepaste attributen en specificaties die vaak voorkomen in vergelijkingen, reviews en beoordelende content
mentions: Benoemt expliciet entiteiten die op de pagina worden besproken en helpt modellen context en relaties te duiden
Deze properties maken van schema een semantische kaart die modellen met vertrouwen kunnen volgen. Als je sameAs gebruikt om je organisatie te linken aan de Wikipedia-pagina, voeg je niet alleen metadata toe—je vertelt het model: “dit is de gezaghebbende bron voor feiten over ons.” Gebruik je additionalProperty om productspecificaties of dienstkenmerken toe te voegen, dan bied je precies de attributen waar AI-systemen op zoeken bij vergelijkingen of aanbevelingen.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Schema-Implementatiestrategie: Van Basis naar LLM-Geoptimaliseerd
De meeste organisaties zien schema markup als een eenmalige implementatie, maar concurrentievoordeel in AI-zoek vraagt om een continu datamanagementproces. Een bruikbaar kader is een volwassenheidsmodel met vier niveaus:
Niveau 1 – Basis Rich Result Schema richt zich op minimale markup op geselecteerde templates, vooral om sterren, productkaarten of FAQ-snippets te behalen. Governance is losjes, consistentie laag, het doel is cosmetisch in plaats van semantisch.
Niveau 2 – Entiteitsgerichte Dekking standaardiseert Organization, Product, Article en Person markup over belangrijke templates, introduceert consistente @id-waarden en voegt basis sameAs-links toe om entiteitsverwarring te voorkomen.
Niveau 3 – Kennisgraaf-Geïntegreerde Schema stemt schema-ID’s af op interne datamodellen (CMS, PIM, CRM), gebruikt uitgebreid about/mentions/additionalType-properties en encodeert relaties tussen pagina’s, zodat modellen begrijpen hoe contentknooppunten samenhangen en met externe entiteiten.
Niveau 4 – LLM-Geoptimaliseerd & RAG-Gealigneerd Schema structureert markup bewust voor conversatievragen en AI-snippetformaten, stemt schema af op interne RAG-pijplijnen, en maakt meten en itereren tot kernpraktijk.
De meeste merken blijven hangen op niveau 1–2; basisadoptie is nu een hygiënefactor, geen onderscheidend vermogen. Doorstoten naar niveau 3–4 is waar schema-LLM-optimalisatie een duurzaam concurrentieel voordeel wordt, omdat modellen je entiteiten betrouwbaar kunnen interpreteren in uiteenlopende zoekopdrachten en interfaces.
Verticaalspecifieke Schema-Patronen voor AI-Antwoordmachines
Elke sector kent eigen entiteiten, risicoprofielen en gebruikersintenties, dus geavanceerde schema-inzet is nooit one-size-fits-all. De kernprincipes—entiteithelderheid, relatiemodellering en afstemming op on-page content—blijven constant, maar de types en properties die je benadrukt moeten aansluiten op hoe mensen zoeken in jouw branche.
Voor e-commerce en retail zijn de belangrijkste entiteiten Products, Offers, Reviews en je Organization. Elke productpagina met hoge koopintentie moet gedetailleerde Product-markup bevatten, inclusief identifiers (SKU, GTIN), merk, model, afmetingen, materialen en onderscheidende eigenschappen via additionalProperty. Combineer dit met Offers voor prijs en beschikbaarheid, en AggregateRating-structuren voor sociale bewijslast. Denk verder na over shopper-vragen: “Is dit waterdicht?”, “Zit er garantie op?”, “Wat is het retourbeleid?” Zet die antwoorden als FAQPage-markup op dezelfde URL en zorg dat Product-attributen en FAQ-inhoud in sync blijven, zodat antwoordmachines makkelijker de juiste pagina kunnen citeren.
Voor SaaS en B2B-diensten zijn entiteiten abstracter, maar goed te vangen met SoftwareApplication, Service en Organization schema. Voor elk kernproduct of dienst definieer je een SoftwareApplication- of Service-entiteit met heldere omschrijving van categorie, ondersteunde platforms, integraties en prijsmodellen; gebruik additionalProperty om features te benoemen die vaak voorkomen in “beste tools voor X”-vergelijkingen. Koppel deze aan je Organization via provider- of offers-relaties, en aan je expertteam via Person-markup. Aan de contentzijde helpen Article, BlogPosting, FAQPage en HowTo-structuren LLM’s je beste assets te identificeren voor evaluatieve en educatieve zoekopdrachten.
Voor lokale, zorg- en gereguleerde sectoren kunnen LocalBusiness, MedicalOrganization en verwante MedicalEntity types adressen, servicegebieden, specialismen, geaccepteerde verzekeringen en openingstijden ondubbelzinnig coderen. Dit is essentieel als een AI-assistent wordt gevraagd om “een kinder cardioloog in de buurt die mijn verzekering accepteert” of “noodzorg die nu open is.” Wees in deze sectoren extra voorzichtig dat schema geen overclaimt of gevoelige details blootlegt—markeer alleen feiten die je in alle contexten hergebruikt wilt zien, en laat medische of gereguleerde attributen altijd door compliance en juristen controleren.
Het Meten van Schema-Impact op AI-Zichtbaarheid
LLM-gedrag is per definitie stochastisch; je krijgt geen pixel-perfecte attributie puur door schema-wijzigingen. Wat je wel kunt doen: een lichte monitoringsystematiek opzetten die AI-antwoorden periodiek bemonstert voor een vaste zoekset. Volg welke entiteiten genoemd worden, welke URL’s geciteerd, hoe je merk wordt omschreven en of kernfeiten (prijzen, mogelijkheden, compliance) kloppen op ChatGPT, Gemini, Perplexity en Bing Copilot. Gaat het mis—verzonnen features, ontbrekende vermeldingen, of citaties naar verzamelaars in plaats van je eigen pagina’s—check dan op tegenstrijdige of onvolledige signalen. Spreekt de on-page tekst de schema tegen? Ontbreken sameAs-links, of verwijzen ze naar verouderde profielen? Claimt meer dan één pagina de canonieke bron voor dezelfde entiteit te zijn? Plan strategisch elk kwartaal een schema-review die aansluit bij nieuwe proposities, contentclusters en veranderingen in hoe AI-antwoordmachines je merk presenteren.
Veelgemaakte Schema-Fouten die LLM-Zichtbaarheid Schaden
Verschillende patronen ondermijnen steevast de effectiviteit van schema voor AI-systemen. Content markeren die niet zichtbaar is op de pagina creëert een vertrouwensdeficit—modellen leren bronnen te negeren waar schema en zichtbare content niet overeenkomen. Gebruik van te generieke types (bijv. alles als “Thing” of “CreativeWork”) geeft geen semantisch signaal; modellen hebben precieze types nodig voor contextbegrip. Het kopiëren van standaard schema over pagina’s zonder entiteitsdetails aan te passen is wellicht de meest voorkomende fout—als elke productpagina identieke Organization-markup heeft, of elk artikel dezelfde auteur claimt, raken modellen verward en kan je content als zwak signaal worden gedegradeerd. Inconsistente entiteits-ID’s (verschillende @id’s voor dezelfde organisatie of hetzelfde product) maakt entiteitsresolutie onmogelijk, waardoor gerelateerde content als losse entiteiten wordt gezien. Ontbrekende sameAs-links naar autoritatieve profielen vergroten de kans dat modellen je merk verwarren met naamgenoten. Tot slot: tegenstrijdige informatie tussen schema en on-page tekst maakt je onbetrouwbaar; als je schema “op voorraad” zegt, maar je pagina “uitverkocht”, vertrouwen modellen geen van beide bronnen.
De Toekomst van Schema en AI-Zoek
Schema markup groeit van cosmetische SEO-tactiek naar fundament van AI-first zoektechnologie. Verbonden schema markup—waarbij je relaties tussen entiteiten expliciet definieert via properties als sameAs, about en mentions—bouwt kennisgrafen waar AI-systemen met vertrouwen doorheen navigeren. Het concurrentievoordeel gaat niet langer naar wie vraagt: “Wat is het minimum schema voor een rich result?”, maar naar wie vraagt: “Welke gestructureerde representatie maakt onze content ondubbelzinnig voor een machine, ook buiten de SERP?” Dit verschuift organisaties naar completere, meer verbonden en entiteitsgerichte schema-patronen. Nu AI-zoek een primair kanaal voor ontdekking wordt, groeit schema-LLM-optimalisatie uit van technische curiositeit tot kern van SEO. Organisaties die de volwassenheidsniveaus doorlopen—van basis rich result schema naar kennisgraaf-geïntegreerde en LLM-geoptimaliseerde patronen—bouwen een duurzaam concurrentievoordeel in AI-ontdekking, zorgen dat hun merk als autoriteit wordt genoemd en hun content wordt gepresenteerd als betrouwbare bron.
Veelgestelde vragen
Hoe verschilt schema markup voor AI van traditionele SEO?
Traditionele schema was gericht op rich results (sterren, snippets). Voor AI draait schema om entiteithelderheid, relaties en kennisgrafen. AI-systemen gebruiken schema om op semantisch niveau te begrijpen waar je content over gaat, niet alleen voor visuele verbeteringen.
Welke schema types zijn het belangrijkst voor LLM-zichtbaarheid?
Organization, Product, Article, Person en FAQPage zijn fundamenteel. Voor SaaS: voeg SoftwareApplication en Service toe. Voor lokaal/zorg: LocalBusiness en MedicalOrganization. Het belang verschilt per branche en gebruikersintentie.
Moet ik alle schema types implementeren?
Nee. Begin met Organization en je meest waardevolle pagina’s (producten, diensten, belangrijkste artikelen). Breid geleidelijk uit op basis van je bedrijfsmodel en waar AI-antwoorden het meeste opleveren.
Hoe lang duurt het voor ik resultaat zie van schema-optimalisatie?
Schema-wijzigingen kunnen AI-citaties binnen enkele weken beïnvloeden, maar de relatie is probabilistisch. Plan kwartaalreviews en monitor continu op meerdere AI-platforms om de impact te volgen.
Wat is het verschil tussen sameAs en about properties?
sameAs koppelt je entiteit aan canonieke profielen (Wikipedia, LinkedIn) om verwarring met naamgenoten te voorkomen. about/mentions verduidelijkt waar je pagina echt op focust, wat modellen helpt nuance en context te begrijpen.
Kan schema markup alleen AI-zichtbaarheid verbeteren?
Nee. Schema werkt het best in combinatie met hoogwaardige, goed gestructureerde on-page content. Modellen hebben zowel gestructureerde data als verhalende context nodig om je pagina’s vol vertrouwen te citeren.
Hoe meet ik of schema-wijzigingen helpen met AI-zichtbaarheid?
Monitor AI-antwoorden op platforms (ChatGPT, Gemini, Perplexity, Bing) voor je doelzoekopdrachten. Volg entiteitsvermeldingen, URL-citaties, feitelijke juistheid en merkbeschrijving. Let op trends over weken/maanden.
Moet ik JSON-LD, microdata of RDFa gebruiken voor schema markup?
JSON-LD is het aanbevolen formaat voor de meeste toepassingen. Het is eenvoudiger te implementeren, te onderhouden en verstoort HTML niet. Microdata en RDFa komen minder vaak voor in moderne implementaties.
Monitor Je Merk in AI-Antwoorden
Volg hoe AI-systemen jouw merk noemen in ChatGPT, Gemini, Perplexity en Google AI Overviews. Krijg inzicht in welke schema types voor zichtbaarheid zorgen.
Welke schema markup helpt bij AI-zoekopdrachten? Complete gids voor 2025
Ontdek welke schema markup-types je zichtbaarheid vergroten in AI-zoekmachines zoals ChatGPT, Perplexity en Gemini. Leer implementatiestrategieën voor JSON-LD v...
Schema markup is gestandaardiseerde code die zoekmachines helpt inhoud te begrijpen. Leer hoe gestructureerde data SEO verbetert, rijke resultaten mogelijk maak...
Ontdek hoe rich results en gestructureerde data de zichtbaarheid van content beïnvloeden in AI-zoekmachines, LLM's en AI-gestuurde antwoorden van ChatGPT, Perpl...
11 min lezen
Cookie Toestemming We gebruiken cookies om uw browse-ervaring te verbeteren en ons verkeer te analyseren. See our privacy policy.