
Semantische Volledigheid
Ontdek wat semantische volledigheid betekent voor contentoptimalisatie. Leer hoe volledige onderwerpsdekking AI-verwijzingen, zichtbaarheid in ChatGPT, Google A...
8 min lezen
Leer hoe semantische volledigheid zorgt voor zelfstandige antwoorden die door AI-systemen worden geciteerd. Ontdek de 3 pijlers van semantische volledigheid en implementeer GEO-strategieën die de AI-zichtbaarheid met 40% verhogen.
Semantische volledigheid in AI verwijst naar de mate waarin content voldoende context en informatie biedt om zelfstandig te worden begrepen door taalmodellen, zonder externe verwijzingen of aanvullende bronnen nodig te hebben. In tegenstelling tot traditionele SEO, die zich richt op zoekwoordranglijsten en doorklikpercentages, focust semantische volledigheid op het waarborgen dat AI-systemen individuele contentsecties kunnen extraheren, begrijpen en citeren als op zichzelf staande antwoorden op gebruikersvragen. Wanneer AI-platforms zoals ChatGPT, Perplexity en Google AI Overviews content evalueren, beoordelen ze of elk concept, feit en claim voldoende grondig wordt uitgelegd om als compleet antwoord te kunnen worden gepresenteerd. Dit onderscheid is belangrijk, omdat AI-systemen niet simpelweg pagina’s rangschikken—ze synthetiseren informatie uit meerdere bronnen en citeren de meest semantisch volledige antwoorden. Content die semantische volledigheid bereikt, wordt intrinsiek waardevoller voor AI-platforms omdat het de noodzaak vermindert voor AI om informatie uit verschillende bronnen te combineren, waardoor jouw content de voorkeur krijgt als citatie. De verschuiving van zoekwoordgerichte optimalisatie naar semantische volledigheid betekent een fundamentele verandering in hoe contentmakers digitale zichtbaarheid moeten benaderen in het tijdperk van generatieve AI.

AI-systemen gebruiken Retrieval-Augmented Generation (RAG)-processen om contentvolledigheid te beoordelen, waarbij relevante informatie uit kennisbanken wordt opgehaald, die informatie wordt gerangschikt op relevantie en autoriteit, en vervolgens antwoorden worden gegenereerd die de hoogste kwaliteit bronnen synthetiseren. In de retrieval-fase zetten AI-systemen gebruikersvragen om in semantische representaties en zoeken ze naar documenten die conceptueel overeenkomen, niet alleen via zoekwoorden. In de ranking-fase wordt semantische volledigheid cruciaal—AI-algoritmes beoordelen of opgehaalde content op zichzelf kan staan als volledig antwoord of dat aanvulling uit andere bronnen nodig is. Volgens onderzoek van Princeton University en Georgia Tech, dat meer dan 1 miljoen AI-antwoorden analyseerde, ontvangt content met semantische volledigheid 40% meer citaties dan gefragmenteerde content die synthese vereist. Het evaluatieproces geeft voorrang aan content die semantisch helder is, structureel georganiseerd met logische koppen en lijsten, feitelijk rijk aan statistieken en gegevenspunten, en gezaghebbend met juiste bronvermeldingen. AI-systemen herkennen dat semantisch volledige content de verwerkingslast verlaagt en de antwoordkwaliteit verhoogt, waardoor zulke content significant vaker wordt geselecteerd voor citatie.
| Evaluatiefactor | Impact op AI-citatie | Relevantie voor traditionele SEO |
|---|---|---|
| Semantische Helderheid | Kritisch (40% meer citaties) | Matig |
| Structurele Organisatie | Kritisch (maakt extractie mogelijk) | Hoog |
| Feitendichtheid | Hoog (verifieerbaarheidssignalen) | Matig |
| Autoriteitssignalen | Hoog (geloofwaardigheidsbeoordeling) | Hoog |
| Toegankelijkheid | Hoog (leesbaarheid telt) | Matig |
Semantische volledigheid rust op drie fundamentele pijlers die samenwerken om content maximaal waardevol te maken voor AI-systemen:
Gezaghebbende Bronvermeldingen: Elke claim, statistiek en bewering moet linken naar betrouwbare bronnen (.edu-domeinen, .gov-bronnen, peer-reviewed onderzoek, gevestigde branchepublicaties). Volgens onderzoek van Stanford en Princeton ontvangt content met gezaghebbende bronnen significant meer AI-citaties dan content zonder bronnen. Deze pijler signaleert onderzoeksrondheid en feitelijke onderbouwing, waardoor AI-systemen informatie onafhankelijk kunnen verifiëren en jouw content vol vertrouwen kunnen citeren.
Expertcitaten: Directe citaten van branche-experts, praktijkmensen en thought leaders dienen als geloofwaardigheidsmarkeringen die door AI-systemen worden herkend en geprefereerd. Wanneer content geciteerde expertinzichten met duidelijke referentie bevat, behandelen AI-algoritmes deze content als gezaghebbender en waardevoller voor citatie. Onderzoek toont aan dat content met expertcitaten aanzienlijk vaker wordt geciteerd omdat citaten specifieke, toewijsbare feiten bieden die AI-engines kunnen extraheren en presenteren als gevestigde kennis.
Statistische Bewijsvoering: Feitrijk content met kwantitatieve gegevenspunten, percentages en numeriek bewijs krijgt aanzienlijk meer AI-citaties dan algemene content. Uit analyse van AI-citatiepatronen blijkt dat content met elke 150-200 woorden een statistiek de optimale citatiefrequentie behaalt. Statistieken dienen een dubbel doel: ze beantwoorden de feitelijke vragen die gebruikers aan AI stellen, en ze signaleren expertise en onderzoeksdiepte aan AI-algoritmes die contentgeloofwaardigheid beoordelen.
Elke pijler versterkt semantische volledigheid op zichzelf, maar samen hebben ze een multiplicatief effect—content die alle drie de elementen bevat, bereikt het maximale citatiepotentieel op alle grote AI-platforms.
Semantisch chunking—content organiseren in zelfstandige secties die elk conceptueel op zichzelf kunnen staan—is essentieel voor AI-citatiesucces. Elke H2-sectie moet haar kop volledig behandelen zonder dat lezers eerdere secties hoeven te raadplegen voor context, zodat AI-systemen individuele secties als complete antwoorden kunnen extraheren. Directe antwoordformats moeten de kern van het antwoord in de eerste 40-60 woorden plaatsen, gevolgd door ondersteunende details en voorbeelden die het concept verder uitwerken. Bijvoorbeeld, bij de vraag “Wat is contentmarketing?”, moet de opening direct stellen: “Contentmarketing is een strategische benadering gericht op het creëren en distribueren van waardevolle, relevante content om een duidelijk gedefinieerd publiek aan te trekken en te behouden.” Dit directe antwoord is zelfstandig te extraheren, terwijl volgende alinea’s context, statistieken en voorbeelden bieden die het begrip verdiepen, maar niet strikt noodzakelijk zijn. Het principe van semantische onafhankelijkheid betekent dat een AI-systeem elke individuele sectie van je content kan citeren zonder verwarring, omdat elke sectie voldoende context biedt voor zelfstandig begrip. Deze structuur verbetert tegelijkertijd de prestaties in traditionele SEO doordat het aansluit bij Google’s richtlijnen voor behulpzame, goed georganiseerde informatie.
Verschillende AI-platforms geven prioriteit aan verschillende kenmerken van semantische volledigheid, waardoor genuanceerde optimalisatiestrategieën nodig zijn voor elk systeem. ChatGPT heeft een sterke voorkeur voor encyclopedische, gezaghebbende content naar het voorbeeld van Wikipedia, waarbij onderzoek uitwijst dat Wikipedia 47,9% van ChatGPT’s feitelijke citaties krijgt. Perplexity AI geeft de voorkeur aan recente content van maximaal 90 dagen oud en door de community gevalideerde bronnen, waarbij bijna 46,7% van de topcitaten afkomstig is van Reddit en andere communityplatforms. Google AI Overviews geeft prioriteit aan content die al goed scoort in de top 10 organische posities, met nadruk op E-E-A-T-signalen (Expertise, Ervaring, Autoriteit, Betrouwbaarheid) en de implementatie van gestructureerde data.
| Platform | Prioriteit Semantische Volledigheid | Citaties Voorkeur | Content Actualiteit |
|---|---|---|---|
| ChatGPT | Encyclopedische structuur, volledige dekking | Wikipedia-stijl, gezaghebbende bronnen | 6-12 maanden acceptabel |
| Perplexity | Recente voorbeelden, communityvalidatie | Reddit, actuele artikelen, praktijkcases | 90 dagen of nieuwer |
| Google AI Overviews | E-E-A-T-signalen, schema markup | Top 10 organische posities, featured snippets | Actueel/bijgewerkt |
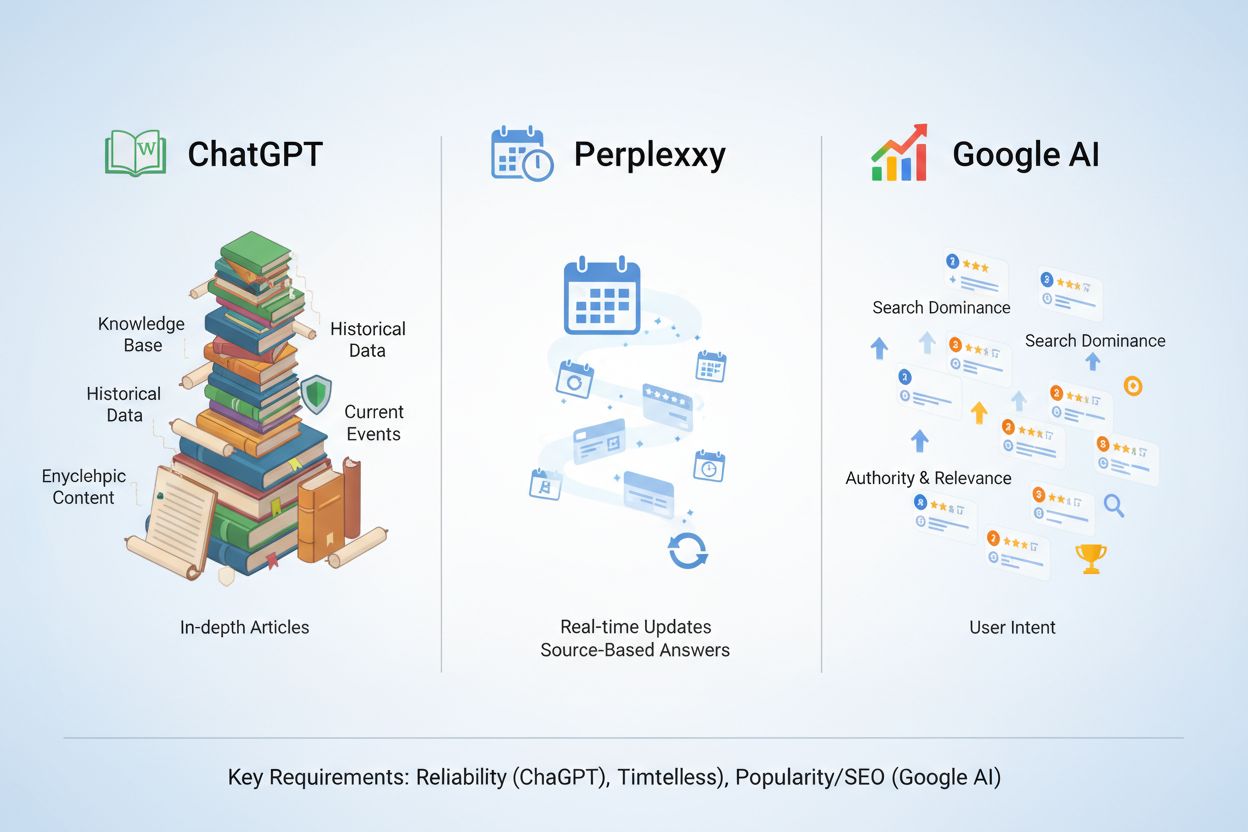
Succesvolle multi-platformoptimalisatie vereist het creëren van uitgebreide basiscontent (2.500-3.000 woorden) die aan alle platformvereisten voldoet, met encyclopedische definities voor ChatGPT, praktijkvoorbeelden voor Perplexity en sterke E-E-A-T-signalen voor Google AI Overviews.
Traditionele SEO benadrukte zoekwoordinensiteit en plaatsing, in de veronderstelling dat zoekalgoritmes zoekwoorden in vragen matchen met zoekwoorden in content. Semantische volledigheid draait deze prioriteit om en focust op conceptuele helderheid en betekenis boven zoekwoordfrequentie. Een pagina die tientallen keren “generative engine optimization” noemt zonder conceptuele helderheid, verliest van een pagina die GEO grondig uitlegt met ondersteunende voorbeelden en duidelijke structuur, omdat AI-systemen concepten herkennen in plaats van zoekwoordinensiteit. Uit onderzoek van Frase en Single Grain blijkt dat semantisch zoeken concepten en relaties tussen ideeën identificeert, waardoor keyword stuffing contraproductief is in AI-citatiealgoritmes. Dit is praktisch van belang: content geoptimaliseerd voor semantische volledigheid bevat automatisch relevante zoekwoorden door contextueel gebruik, terwijl forceren van zoekwoordinensiteit vaak resulteert in onnatuurlijke zinnen die AI-systemen herkennen als minder betrouwbaar. Deze semantische benadering sluit aan bij Google’s richtlijnen voor behulpzame content, die expliciet keyword stuffing bestraffen en juist echt nuttige, goed georganiseerde informatie belonen. Voor contentmakers betekent dit: laat de spreadsheets voor zoekwoordinensiteit achterwege en richt je op het grondig uitleggen van concepten, het bieden van context en zorgen dat elke sectie zelfstandig als volledig antwoord kan functioneren.
Zelfstandige antwoordformats volgen een consistente structuur die de kans op AI-citatie maximaliseert: direct antwoord (10-15 woorden met het kernconcept), ondersteunend detail (20-30 woorden uitleg of context) en autoriteitsindicator (5-10 woorden met referentie naar expertise of bron). Bijvoorbeeld, bij de vraag “Hoe genereert contentmarketing ROI?”, zou de structuur zijn: “Contentmarketing genereert ROI door leadgeneratie, klantbehoud en het opbouwen van merkautoriteit (direct antwoord). Bedrijven die contentmarketing toepassen behalen 3x meer leads dan bedrijven die alleen adverteren (ondersteunend detail). Volgens onderzoek van het Content Marketing Institute 2024 (autoriteitsindicator).” Dit format van 35-55 woorden is optimaal voor AI-extractie, omdat het volledige informatie biedt zonder overbodige context. Elk antwoord moet zelfstandig begrijpelijk zijn—een lezer die alleen die alinea ziet, moet het concept volledig kunnen begrijpen. Voorbeelden versterken semantische volledigheid: “Een SaaS-bedrijf dat maandelijks 20 educatieve blogposts publiceert, kan jaarlijks 500 gekwalificeerde leads genereren, tegenover 150 leads met alleen betaalde advertenties.” Deze voorbeeldgerichte aanpak helpt AI-systemen praktische toepassingen begrijpen en versterkt de citatiewaardigheid met concreet bewijs.
FAQ-schema markup, geïmplementeerd met JSON-LD, geeft AI-systemen expliciet aan welke contentsecties veelgestelde vragen beantwoorden, wat de kans op citatie voor die vragen aanzienlijk vergroot. Volgens onderzoek van Passionfruit en GetPassionFruit verhoogt implementatie van FAQ-schema de frequentie van AI-citaties doordat AI snel vraag-antwoordparen kan identificeren en extraheren zonder omliggende context te hoeven parsen. De JSON-LD-structuur voor FAQ-schema omvat een FAQPage-entiteit met daarin een array van Question-items, elk met een accepted Answer-property met het volledige antwoord. Google raadt JSON-LD expliciet aan voor gestructureerde data, vanwege het gemak van onderhoud en minder implementatiefouten dan andere markupformaten. Het FAQ-schema heeft een dubbel doel: het geeft semantische signalen aan AI-systemen over de organisatie van je content en maakt je in aanmerking voor featured snippets in de klassieke Google-zoekresultaten, wat zorgt voor extra zichtbaarheid. Let bij implementatie van FAQ-schema op dat alle gemarkeerde content zichtbaar is voor gebruikers op de pagina (verborgen of dynamisch geladen content is niet toegestaan), elke pagina unieke FAQ-content bevat die relevant is voor het onderwerp, en dat antwoorden zelfstandig en zonder extra context te begrijpen zijn. De impact op AI-citaties is groot—pagina’s met correct geïmplementeerde FAQ-schema krijgen voorrang van AI-systemen die content beoordelen op citatiewaardigheid, omdat het schema expliciet semantische volledigheid signaleert.
Succes op het gebied van semantische volledigheid meet je aan de hand van zowel traditionele als nieuwe AI-specifieke prestatie-indicatoren die direct met bedrijfsresultaten samenhangen. Citatiepercentage—berekend als (Merkcitaties in AI-antwoorden / Totaal relevante geteste vragen) × 100—is de meest directe maat voor effectiviteit van semantische volledigheid, waarbij succesvolle implementaties doorgaans 30-50% citatie behalen op doelvragen binnen 6 maanden. GA4-segmentatie maakt het mogelijk AI-botverkeer te volgen door te filteren op user agents zoals “ChatGPT-User,” “PerplexityBot” en “Claude-Web,” al vangt dit alleen herkenbaar botverkeer en moet het richtinggevend worden gezien. Citatiescontextanalyse houdt in dat je AI-platforms maandelijks handmatig bevraagt met 10-15 kernvragen die je content moet beantwoorden, bijhoudt welke bronnen worden geciteerd en de citatiefrequentie over tijd volgt. Verwachte tijdlijnen tonen de eerste citatiewinsten binnen 4-8 weken na publicatie van geoptimaliseerde content, met aanhoudende groei over 6-12 maanden naarmate je content autoriteit opbouwt en AI-platforms je domein als betrouwbare bron gaan zien. Share of AI voice—berekend als (Jouw merkcitaties / Totaal branchecitaties) × 100—maakt concurrentieanalyse mogelijk en laat zien of je citatieaandeel groeit of daalt ten opzichte van concurrenten. Deze metrics samen tonen het succes van semantische volledigheid aan en rechtvaardigen verdere investering in AI-optimalisatiestrategieën.
Zeven cruciale fouten verhinderen dat content semantische volledigheid bereikt en verkleinen de kans op AI-citatie:
Onvolledige Antwoorddekking - Alleen de hoofdvraag beantwoorden zonder gerelateerde of vervolgvragen te behandelen die gebruikers waarschijnlijk stellen, waardoor AI-systemen informatie uit meerdere bronnen moeten combineren in plaats van jouw volledige antwoord te citeren.
Vage Marketingtaal - Abstracte beschrijvingen gebruiken zoals “uitmuntende keuken geïnspireerd door gedurfde smaken” in plaats van specifieke, feitelijke uitspraken zoals “authentieke streetstyle taco’s en burrito bowls vers bereid,” waardoor AI jouw content niet vol vertrouwen kan extraheren en citeren.
Ontbrekende Brontoewijzing - Claims maken zonder gezaghebbende bronnen te noemen, wat AI-algoritmen het signaal geeft dat je content onvoldoende onderbouwd is en minder citatievertrouwen biedt.
Slechte Structurele Organisatie - Informatie presenteren in lange tekstblokken zonder duidelijke koppen, opsommingen of logische hiërarchie, waardoor het voor AI-systemen lastig is zelfstandige secties te extraheren.
Verouderde Statistieken - Gegevens ouder dan 12 maanden gebruiken zonder te updaten, vooral problematisch voor Perplexity en Google AI Overviews die sterk actuele content prefereren.
Gebrek aan Expertattributie - Content publiceren zonder auteurstitels of expertinzichten, waardoor je kansen mist om autoriteitssignalen te versterken die AI-systemen gebruiken voor citatiebeslissingen.
Onvoldoende Feitendichtheid - Geen statistieken, percentages of numeriek bewijs elke 150-200 woorden toevoegen, waardoor de content te algemeen blijft en specifieke, verifieerbare informatie ontbreekt die AI-systemen juist prioriteren voor citaties.
Vereisten voor semantische volledigheid verschillen per contenttype en vragen om maatwerk voor maximale AI-citatiewaarde. Blogposts moeten openen met een direct antwoord in de eerste 40-60 woorden, gevolgd door ondersteunend bewijs en voorbeelden, met FAQ-secties voor veelgestelde vervolgvragen. Handleidingen vereisen een stapsgewijze opbouw waarbij elke stap zelfstandig is en specifieke details, maten en verwachte uitkomsten bevat, zodat AI-systemen losse stappen als complete instructies kunnen extraheren. FAQ-pagina’s moeten 5-10 vraag-antwoordparen bevatten met het juiste FAQ-schema, waarbij elk antwoord 40-60 woorden telt en zelfstandig te begrijpen is. Productpagina’s profiteren van semantische volledigheid door duidelijke featurebeschrijvingen, specifieke use cases en directe antwoorden op veelgestelde aankoopvragen, al zullen AI-systemen productpagina’s zelden direct citeren—meestal citeren ze ondersteunende educatieve content die aankoopbeslissingen beïnvloedt. Casestudy’s bereiken semantische volledigheid door specifieke metrics, tijdlijnen, uitdagingen, oplossingen en resultaten te bieden in duidelijk gelabelde secties, zodat AI-systemen losse case-elementen als bewijs voor bredere claims kunnen extraheren. Elk contenttype vereist dezelfde basisprincipes—directe antwoorden, zelfstandige secties, feitendichtheid en autoriteitssignalen—maar de structuur verschilt afhankelijk van het doel en de gebruikersintentie.
Semantische volledigheid wordt steeds belangrijker voor digitale zichtbaarheid naarmate AI-zoekopdrachten toenemen en AI-platforms hun citatie-algoritmes verfijnen. Nieuwe trends laten zien dat multimodale AI-systemen die tekst, beeld, video en audio tegelijk kunnen verwerken, semantische volledigheid in meerdere formaten vereisen—niet alleen geschreven tekst. Volgens onderzoek van Semrush zal AI-verkeerd verkeer naar verwachting traditionele Google-organische zoekopdrachten begin 2028 overtreffen, waardoor optimalisatie voor semantische volledigheid een essentiële langetermijninvestering wordt. Vroege aanpassers die nu semantische volledigheid in hun contentbibliotheken aanbrengen, genieten op de lange termijn een voordeel, omdat AI-platforms “bronvoorkeursbias” vertonen—een bron die betrouwbaar blijkt op een onderwerp, krijgt de voorkeur bij verwante vragen, wat een cumulatief citatievoordeel oplevert. Naarmate de concurrentie om AI-citaties toeneemt, wordt semantische volledigheid de belangrijkste onderscheidende factor tussen merken die citatieaandeel veroveren en zij die onzichtbaar blijven in AI-antwoorden. Organisaties die nu investeren in semantische volledigheid bouwen een citatiemuur waar concurrenten moeilijk overheen kunnen, en vestigen autoriteitsposities die in de loop der tijd cumuleren. De toekomst van search is conversatiegericht, AI-gestuurd en citatiegebaseerd; semantische volledigheid wordt daarmee de basisvaardigheid voor contentmakers die zichtbaar willen blijven in het komende decennium van digitale marketing.
Semantische volledigheid betekent dat je content zelfstandig en volledig te begrijpen is zonder dat lezers externe bronnen of eerdere secties hoeven te raadplegen. Voor AI-systemen betekent het dat elke sectie onafhankelijk kan worden geëxtraheerd en geciteerd omdat deze alle benodigde context en informatie bevat om een specifieke vraag volledig te beantwoorden.
Traditionele SEO optimaliseert volledige pagina's voor ranking in zoekresultaten, met de focus op zoekwoorden en backlinks. Semantische volledigheid optimaliseert individuele secties en feiten voor AI-extractie en citatie. Waar SEO vraagt 'Zal deze pagina ranken?', vraagt GEO 'Kan AI deze specifieke sectie zelfstandig extraheren en citeren?'
AI-systemen die RAG (Retrieval-Augmented Generation) gebruiken, halen specifieke secties uit meerdere bronnen om antwoorden te synthetiseren. Zelfstandige secties stellen AI in staat je content vol vertrouwen te citeren zonder omliggende context nodig te hebben, waardoor je content eerder wordt geselecteerd voor citaties.
Onderzoek toont aan dat optimale zelfstandige antwoorden bestaan uit een opening van 40-60 woorden (direct antwoord), 20-30 woorden ondersteunend detail en 5-10 woorden autoriteitsindicator, totaal 35-55 woorden. Langere secties (100-200 woorden) kunnen ook zelfstandig zijn als ze logisch volledig zijn en geen externe context vereisen.
Lees elke H2-sectie losstaand zonder omliggende content te lezen. Als je het volledige concept begrijpt en de vraag van de sectie kunt beantwoorden zonder externe context, is het semantisch volledig. Je kunt dit ook direct aan AI-systemen vragen—als zij je sectie citeren zonder omliggende context nodig te hebben, heb je semantische volledigheid bereikt.
Ja. Content die is gestructureerd voor semantische volledigheid—met duidelijke koppen, directe antwoorden en logische opbouw—presteert doorgaans ook beter in traditionele SEO. Google's richtlijnen voor behulpzame content belonen duidelijke, goed gestructureerde content die direct antwoord geeft op gebruikersvragen, wat perfect aansluit bij de principes van semantische volledigheid.
Werk kerncontent elke 90-180 dagen bij, vooral statistieken, voorbeelden en tijdgebonden informatie. Perplexity en Google AI Overviews geven sterk de voorkeur aan actuele content. De semantische structuur zelf (hoe secties zijn georganiseerd) blijft echter stabiel—richt je updates op het actueel houden van feiten in plaats van herstructureren.
Ja. Blogposts, handleidingen, FAQ's, productpagina's, casestudy's en branche-rapporten kunnen allemaal profiteren van semantische volledigheid. Het principe blijft hetzelfde: elke sectie moet zelfstandig te begrijpen zijn. De uitvoering verschilt per contenttype—FAQ's sluiten van nature aan bij semantische volledigheid, terwijl blogposts bewuste sectiestructuur vereisen.
Volg hoe AI-systemen zoals ChatGPT, Perplexity en Google AI jouw merk citeren. Krijg realtime inzicht in je prestaties op het gebied van semantische volledigheid en je concurrentiële citatie-aandeel.
Ontdek wat semantische volledigheid betekent voor contentoptimalisatie. Leer hoe volledige onderwerpsdekking AI-verwijzingen, zichtbaarheid in ChatGPT, Google A...

Ontdek wat inhoudelijke volledigheid betekent voor AI-systemen zoals ChatGPT, Perplexity en Google AI Overviews. Leer hoe je complete, op zichzelf staande antwo...
Ontdek hoe semantisch begrip de nauwkeurigheid van AI-citaties, bronvermelding en betrouwbaarheid in AI-gegenereerde content beïnvloedt. Leer de rol van context...
Cookie Toestemming
We gebruiken cookies om uw browse-ervaring te verbeteren en ons verkeer te analyseren. See our privacy policy.