Waarom ChatGPT van Reddit Houdt: Inzicht in Bronvoorkeuren
Ontdek waarom Reddit 40,1% van alle ChatGPT-vermeldingen voor zijn rekening neemt. Leer hoe AI-bronvoorkeuren werken en wat dit betekent voor de zichtbaarheid v...
10 min lezen

Ontdek hoe Stack Overflow-inhoud AI-antwoorden vormgeeft en leer strategieën om je ontwikkelaarszichtbaarheid te maximaliseren in ChatGPT, Gemini en andere AI-platforms.
De 50 miljoen vragen en antwoorden van Stack Overflow zijn een hoeksteen geworden voor de ontwikkeling van grote taalmodellen. Grote AI-bedrijven zoals OpenAI, Google en Meta hebben Stack Overflow-data opgenomen in hun trainingsdatasets, omdat ontwikkelaarskennis tot de hoogste kwaliteit en door vakgenoten beoordeelde technische inhoud op internet behoort. Het ontwikkelen van geavanceerde AI-systemen kost honderden miljoenen euro’s, en een groot deel van die kosten komt door het verkrijgen en verwerken van trainingsdata. Historisch gezien werd deze data door AI-bedrijven gratis gescrapet, maar Stack Overflow-CEO Prashanth Chandrasekar kondigde in 2023 aan dat het platform grote AI-ontwikkelaars voortaan zou laten betalen voor toegang tot haar inhoud, in de erkenning dat door de community gegenereerde kennis gecompenseerd moet worden. Deze verschuiving weerspiegelt een bredere beweging in de industrie, waarbij platforms met waardevolle data eerlijke compensatie eisen van bedrijven die van hun inhoud profiteren.
Stack Overflow-inhoud valt onder de Creative Commons Attribution-ShareAlike 4.0 (CC BY-SA)-licentie, die wettelijk vereist dat iedereen die de inhoud gebruikt, toeschrijving geeft aan de oorspronkelijke auteurs. Dit licentiekader is niet-onderhandelbaar voor Stack Overflow, omdat het platform gelooft dat toeschrijving de basis vormt van het vertrouwen van ontwikkelaars in door AI gegenereerde inhoud. Wanneer AI-bedrijven modellen trainen op Stack Overflow-data zonder correcte toeschrijving, schenden ze technisch gezien de Creative Commons-licentie. Daarom verplicht Stack Overflow nu alle API-partners om attributievereisten in hun contracten op te nemen. Het belang hiervan kan niet worden overschat: volgens de Stack Overflow Developer Survey van 2024 noemt 65% van de ontwikkelaars ontbrekende of onjuiste toeschrijving als een belangrijk ethisch probleem bij AI-tools.
| Aspect | Vereiste | Impact |
|---|---|---|
| Licentietype | CC BY-SA 4.0 | Attributie verplicht |
| Vertrouwen ontwikkelaars | 72% gunstig | Cruciaal voor adoptie |
| AI-naleving | RAG-implementatie | Zorgt voor correcte bronvermelding |
| Citatiegraad | 65% bezorgd | Belangrijkste ethische kwestie |
| Inhoudseigendom | Gebruiker behoudt | Bescherming van de community |
Stack Overflow maakt bij AI-licenties onderscheid tussen gratis en commerciële gebruiksdoeleinden. Het platform blijft gratis toegang bieden tot haar API en datadumps voor niet-commerciële doeleinden, educatief gebruik en open source-projecten, waarmee haar betrokkenheid bij de ontwikkelaarscommunity wordt bevestigd. Bedrijven die echter grote taalmodellen ontwikkelen voor commerciële doeleinden, moeten licentieovereenkomsten sluiten met Stack Overflow. De prijsstelling is gebaseerd op factoren zoals modelgrootte, gebruiksvolume en gegenereerde omzet. Stack Overflow-CEO Chandrasekar benadrukte dat het bedrijf alleen compensatie vraagt van organisaties die LLM’s ontwikkelen voor “grote, commerciële doeleinden”, niet van individuele ontwikkelaars of kleine projecten. Dit duale licentiemodel stelt Stack Overflow in staat nieuwe inkomstenstromen te genereren en tegelijk de belangen van haar communityleden te beschermen, van wie velen bijdragen zonder directe betaling te verwachten. Het bedrijf heeft zich er ook toe verbonden licentie-inkomsten opnieuw te investeren in communitytools en -functies, wat een duurzaam model oplevert waarbij ontwikkelaarsbijdragen direct platformverbeteringen financieren.
Stack Overflow-inhoud verschijnt nu prominent in AI-gegenereerde antwoorden op grote platforms zoals ChatGPT, Google Gemini, Perplexity en Microsoft Copilot. Google’s Gemini Cloud Assist geeft expliciet attributie aan Stack Overflow-antwoorden bij het bieden van codeoplossingen; het toont de oorspronkelijke vraag, het antwoord en de auteursinformatie direct in het AI-antwoord. OpenAI’s ChatGPT toont Stack Overflow-links in gesprekken over codeeronderwerpen, en SearchGPT—OpenAI’s zoekprototype—neemt Stack Overflow-resultaten op in zowel conversatieantwoorden als zoekresultaten. Deze zichtbaarheid is cruciaal voor ontwikkelaars omdat het verkeer naar hun antwoorden genereert en hen als erkende experts in hun vakgebied positioneert. Niet alle AI-platforms bieden echter gelijke attributie, en ontwikkelaars worstelen vaak om te begrijpen welke van hun antwoorden worden geciteerd, hoe vaak en in welke context op verschillende AI-systemen.
De Stack Overflow Developer Survey van 2024 laat een groeiende kloof zien tussen AI-adoptie en vertrouwen: terwijl 76% van de ontwikkelaars AI-tools gebruikt of overweegt te gebruiken (tegenover 70% in 2023), is de gunstscore van AI gedaald van 77% naar 72%. Slechts 43% van de ontwikkelaars vertrouwt de nauwkeurigheid van AI-tools, en het onderzoek identificeerde drie essentiële ethische zorgen die ontwikkelaars prioriteren:
Dit vertrouwensdeficit beïnvloedt rechtstreeks hoe AI-bedrijven omgaan met data-acquisitie en modeltraining. Ontwikkelaars eisen steeds vaker dat AI-systemen hun bronnen citeren, communitybijdragen erkennen en nauwkeurigheidsstandaarden hanteren die de door vakgenoten beoordeelde aard van Stack Overflow-inhoud weerspiegelen. De druk om betrouwbare AI-systemen te bouwen heeft geleid tot een grotere urgentie voor het gebruik van hoogwaardige trainingsdata, waardoor de geverifieerde, door de community samengestelde kennis van Stack Overflow waardevoller is dan ooit.
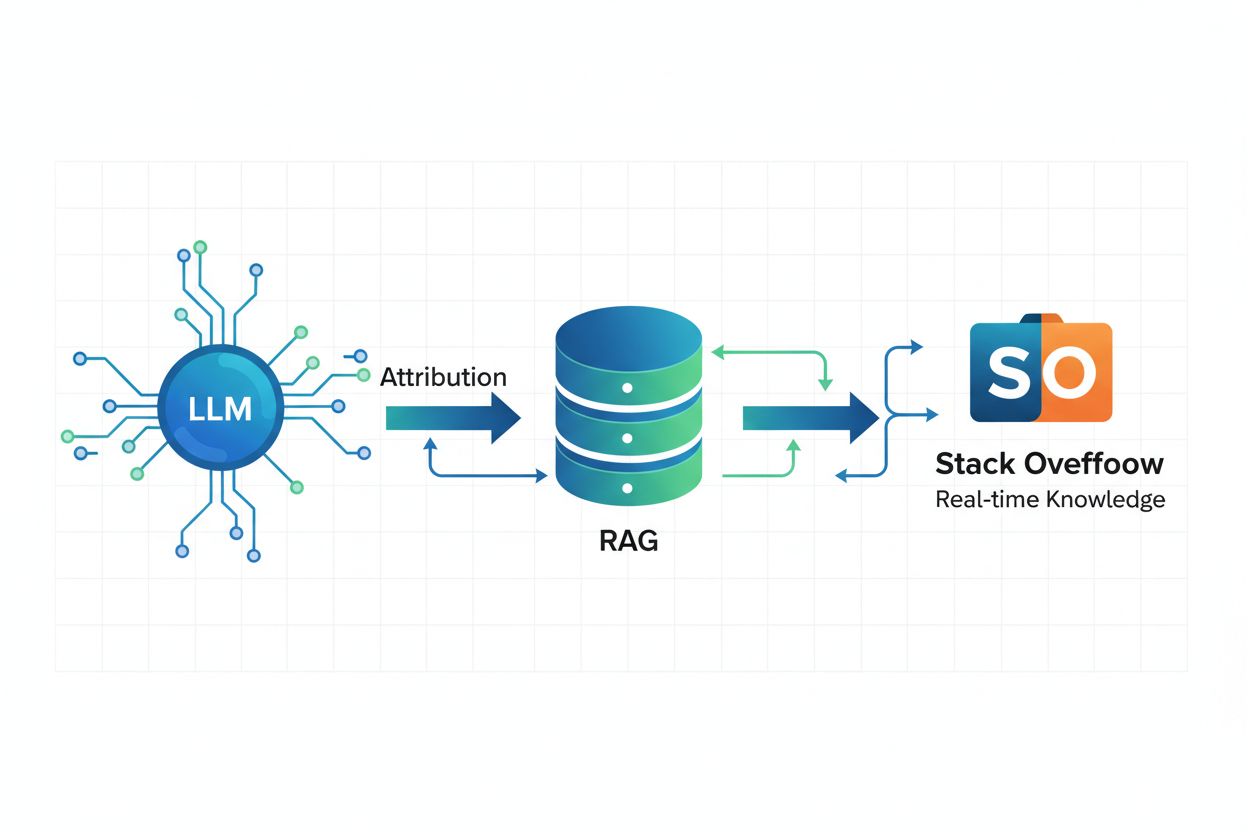
Retrieval Augmented Generation (RAG) is een AI-framework dat grote taalmodellen combineert met traditionele informatieretrievalsystemen om actuele, nauwkeurige en correct toegeschreven antwoorden te bieden. In plaats van uitsluitend te vertrouwen op trainingsdata die op een bepaald moment is bevroren, stelt RAG AI-systemen in staat realtime informatie op te halen uit externe bronnen zoals Stack Overflow, zodat antwoorden de laatste kennis en best practices weergeven. Alle OverflowAPI-partners van Stack Overflow hebben RAG geïmplementeerd om correcte toeschrijving te garanderen. Dit betekent dat wanneer een AI-systeem een antwoord genereert met Stack Overflow-inhoud, het de specifieke berichten kan identificeren en citeren die het antwoord beïnvloeden. Deze technologie is vooral krachtig voor domeinspecifieke kennis waarbij nauwkeurigheid en actualiteit belangrijk zijn—bijvoorbeeld: een AI-systeem C#-code laten schrijven aan de hand van specifieke voorbeelden uit je codebase zorgt ervoor dat de gegenereerde code voldoet aan de standaarden en conventies van je team. RAG vermindert het risico op hallucinatie door AI-antwoorden te baseren op vertrouwde, geverifieerde feiten die gebruikers expliciet identificeren, waardoor het de technische basis vormt voor verantwoordelijke AI-ontwikkeling.
Ontwikkelaars die bijdragen aan Stack Overflow zouden actief moeten monitoren hoe hun inhoud verschijnt in AI-gegenereerde antwoorden op verschillende platforms. Tools zoals AmICited.com, XFunnel, Profound en anderen bieden nu zichtbaarheidstracking die speciaal ontworpen is om ontwikkelaars te tonen waar hun antwoorden worden geciteerd, hoe vaak en in welke context in ChatGPT, Gemini, Perplexity en andere AI-systemen. Belangrijke statistieken om te volgen zijn citatiefrequentie (hoe vaak je inhoud wordt genoemd), sentiment (of vermeldingen positief of neutraal zijn), platformverdeling (welke AI-systemen je het meest citeren) en bronvermelding (of de juiste erkenning wordt gegeven). Door deze statistieken te monitoren, kunnen ontwikkelaars ontdekken welke van hun antwoorden de meeste waarde bieden aan AI-systemen, begrijpen welke onderwerpen het meest in trek zijn en hun bijdragestijl daarop aanpassen. Bovendien helpt het volgen van zichtbaarheid ontwikkelaars om onjuiste of onvolledige citaties te signaleren, zodat ze hun oorspronkelijke antwoorden kunnen updaten of AI-bedrijven kunnen benaderen voor correcties. Deze proactieve benadering verandert passieve inhoudsbijdrage in een actieve strategie om autoriteit en invloed op te bouwen binnen het door AI aangedreven informatiesysteem.
Om zichtbaarheid te maximaliseren in AI-zoekresultaten en te zorgen dat je Stack Overflow-bijdragen correct worden geciteerd, kun je het beste uitgebreide, goed gedocumenteerde antwoorden geven die de volledige vraag behandelen met duidelijke uitleg en werkende codevoorbeelden. Houd je antwoorden actueel door ze periodiek te herzien en up-to-date te maken naarmate technologieën veranderen, omdat AI-systemen recentere inhoud prioriteren—gemiddeld is inhoud die in AI-resultaten wordt geciteerd 25,7% recenter dan wat in Google scoort. Bouw autoriteit op door consequent hoogwaardige antwoorden te geven over meerdere gerelateerde onderwerpen; ontwikkelaars in de top 25% qua webvermeldingen ontvangen 10x meer AI-citaties dan anderen. Neem deel aan het bredere ontwikkelaarsecosysteem door discussies aan te gaan, vervolgvragen te beantwoorden en andere communityleden te helpen hun bijdragen te verbeteren. Denk tenslotte na over hoe je antwoorden door AI-systemen gebruikt kunnen worden: structureer je antwoorden met duidelijke koppen, voeg relevante codefragmenten toe en geef context over wanneer en waarom bepaalde benaderingen geschikt zijn, zodat je inhoud bruikbaarder is voor zowel menselijke lezers als AI-systemen die informatie moeten extraheren en correct toeschrijven.
De 50 miljoen vragen en antwoorden van Stack Overflow zijn opgenomen in grote taalmodellen omdat ze hoogwaardige, door vakgenoten beoordeelde technische inhoud vertegenwoordigen. AI-bedrijven zoals OpenAI, Google en Meta gebruiken deze data om hun modellen beter te laten begrijpen en genereren van code en technische oplossingen. Historisch werd deze data gratis gescrapet, maar Stack Overflow vereist nu dat commerciële AI-ontwikkelaars de data afnemen via betaalde overeenkomsten.
Stack Overflow biedt gratis API-toegang voor niet-commercieel gebruik, educatieve doeleinden en open source-projecten. Bedrijven die grote taalmodellen ontwikkelen voor commerciële doeleinden moeten echter betaalde licentieovereenkomsten afsluiten. De prijsstelling is gebaseerd op factoren zoals modelgrootte, gebruiksvolume en gegenereerde omzet, zodat bijdragen van de community correct worden gecompenseerd.
Maak uitgebreide, goed gedocumenteerde antwoorden met duidelijke uitleg en werkende codevoorbeelden. Houd je antwoorden actueel door ze te updaten naarmate technologieën veranderen, omdat AI-systemen recentere inhoud voorrang geven. Bouw autoriteit op door consequent hoogwaardige antwoorden te geven over meerdere onderwerpen, en structureer je antwoorden met duidelijke koppen en relevante codefragmenten die AI-systemen eenvoudig kunnen extraheren en toeschrijven.
Retrieval Augmented Generation (RAG) is een AI-framework dat taalmodellen combineert met informatieretrievalsystemen om actuele, nauwkeurige en correct toegeschreven antwoorden te leveren. RAG stelt AI-systemen in staat realtime informatie op te halen uit bronnen zoals Stack Overflow en de specifieke berichten te citeren die het antwoord beïnvloedden, wat correcte toeschrijving garandeert en het risico op hallucinatie verkleint.
Tools zoals AmICited.com, XFunnel, Profound en anderen bieden zichtbaarheidstracking die speciaal is ontworpen om ontwikkelaars te tonen waar hun antwoorden worden geciteerd in ChatGPT, Gemini, Perplexity en andere AI-systemen. Deze tools volgen citatiefrequentie, sentiment, platformverdeling en bronvermelding, zodat je begrijpt welke van je antwoorden de meeste waarde bieden aan AI-systemen.
Volgens de Stack Overflow Developer Survey van 2024 hebben ontwikkelaars drie belangrijke ethische zorgen: risico op desinformatie (79% bezorgd), ontbrekende of onjuiste toeschrijving (65% bezorgd) en bias die geen diverse gezichtspunten vertegenwoordigt (50% bezorgd). Deze zorgen onderstrepen de noodzaak voor correcte licenties, toeschrijvingsvereisten en hoogwaardige trainingsdata uit geverifieerde bronnen zoals Stack Overflow.
Stack Overflow-inhoud valt onder de Creative Commons Attribution-ShareAlike 4.0 (CC BY-SA)-licentie, die wettelijk vereist dat iedereen die de inhoud gebruikt, toeschrijving geeft aan de oorspronkelijke auteurs. Stack Overflow verplicht nu alle API-partners om attributievereisten in hun contracten op te nemen, zodat ontwikkelaars de juiste erkenning krijgen wanneer hun antwoorden door AI-systemen worden gebruikt.
Er zijn verschillende tools beschikbaar voor het volgen van AI-citaties, waaronder AmICited.com (gespecialiseerd in AI-monitoring), XFunnel (enterprise LLM-monitoring), Profound (geavanceerde GEO-tracking), Semrush AI Toolkit, BrightEdge en anderen. Deze tools helpen je te volgen welke AI-platforms je citeren, hoe vaak, in welke context en of correcte toeschrijving wordt gegeven.
Volg hoe je technische expertise wordt geciteerd in ChatGPT, Gemini, Perplexity en andere AI-platforms. Krijg realtime inzichten in je ontwikkelaarszichtbaarheid en optimaliseer je community-aanwezigheid.
Ontdek waarom Reddit 40,1% van alle ChatGPT-vermeldingen voor zijn rekening neemt. Leer hoe AI-bronvoorkeuren werken en wat dit betekent voor de zichtbaarheid v...

Leer Reddit Thread Optimalisatie strategieën om AI-zichtbaarheid te vergroten op ChatGPT, Perplexity en Google AI Overviews. Ontdek hoe je citerenwaardige conte...

Discussie binnen de gemeenschap over de cruciale rol van Wikipedia als AI-trainingsdata. Echte ervaringen van AI-ontwikkelaars, onderzoekers en contentstrategen...
Cookie Toestemming
We gebruiken cookies om uw browse-ervaring te verbeteren en ons verkeer te analyseren. See our privacy policy.