
Token
Ontdek wat tokens zijn in taalmodellen. Tokens zijn fundamentele eenheden van tekstanalyse in AI-systemen, waarbij woorden, subwoorden of karakters als numeriek...
10 min lezen

Ontdek hoe tokenlimieten de prestaties van AI beïnvloeden en leer praktische strategieën voor contentoptimalisatie, waaronder RAG, chunking en samenvattingstechnieken.
Tokens zijn de fundamentele bouwstenen waarmee AI-modellen informatie verwerken en begrijpen. In plaats van te werken met volledige woorden of zinnen, breken grote taalmodellen tekst op in kleinere eenheden die tokens worden genoemd. Dit kunnen individuele karakters, subwoorden of complete woorden zijn, afhankelijk van het tokenisatie-algoritme. Elk token krijgt een uniek numeriek ID dat het model intern gebruikt voor berekeningen. Dit tokenisatieproces is essentieel omdat het AI-systemen in staat stelt efficiënter om te gaan met invoer van variabele lengte en consistente verwerking te waarborgen voor verschillende soorten content. Inzicht in tokens is cruciaal voor iedereen die met AI-systemen werkt, omdat ze direct de prestaties, kosten en de kwaliteit van de resultaten beïnvloeden.
Verschillende AI-modellen hebben sterk uiteenlopende tokenlimieten, die bepalen hoeveel informatie ze in één verzoek kunnen verwerken. Deze limieten zijn de afgelopen jaren drastisch toegenomen, waarbij nieuwere modellen aanzienlijk grotere contextvensters ondersteunen. De tokenlimiet omvat zowel inputtokens (je prompt en data) als outputtokens (het antwoord van het model), wat samen een gedeeld budget vormt dat zorgvuldig moet worden beheerd. Inzicht in deze limieten is essentieel bij het kiezen van het juiste model voor jouw toepassing en het plannen van de architectuur van je applicatie.
| Model | Tokenlimiet | Primaire gebruikstoepassing | Kostenniveau |
|---|---|---|---|
| GPT-3.5 Turbo | 4.096 | Korte gesprekken, snelle taken | Laag |
| GPT-4 | 8.192 | Standaardtoepassingen, gemiddelde complexiteit | Gemiddeld |
| GPT-4 Turbo | 128.000 | Lange documenten, complexe analyses | Hoog |
| Claude 3.5 Sonnet | 200.000 | Uitgebreide documenten, volledige analyse | Hoog |
| Gemini 1.5 Pro | 1.000.000 | Massale datasets, volledige boeken, video-analyse | Zeer hoog |
Belangrijke overwegingen bij het beoordelen van tokenlimieten:
Tokenlimieten vormen belangrijke beperkingen die direct invloed hebben op de nauwkeurigheid, betrouwbaarheid en kosteneffectiviteit van AI-toepassingen. Als je de tokenlimiet van een model overschrijdt, faalt de toepassing volledig—er is geen geleidelijke afbouw of gedeeltelijke verwerking mogelijk. Zelfs wanneer je binnen de limieten blijft, kunnen naïeve benaderingen zoals simpel afkappen de prestaties ernstig verslechteren doordat essentiële context verloren gaat die het model nodig heeft voor nauwkeurige antwoorden. Dit is vooral problematisch in sectoren als juridische analyse, medisch onderzoek en softwareontwikkeling, waar het missen van zelfs één belangrijk detail kan leiden tot verkeerde conclusies. De uitdaging wordt nog groter doordat verschillende soorten content tokens op verschillende snelheden verbruiken—gestructureerde data zoals code of JSON vereist aanzienlijk meer tokens dan gewone Engelse tekst vanwege symbolen en opmaak.
Afkappen is de eenvoudigste methode om met tokenlimieten om te gaan—je snijdt simpelweg overtollige content af wanneer deze de capaciteit van het model overschrijdt. Hoewel deze aanpak makkelijk te implementeren is, kleven er grote risico’s aan. Als je tekst afkapt, verlies je onvermijdelijk informatie, en het model weet niet wat er is verwijderd. Dit kan leiden tot onvolledige analyses, gemiste context en hallucinaties waarbij het model aannemelijk klinkende maar foutieve informatie genereert om gaten in zijn begrip op te vullen.
def truncate_text(text: str, max_tokens: int) -> str:
"""Simple truncation approach - not recommended for production"""
tokens = encode(text)
if len(tokens) > max_tokens:
truncated_tokens = tokens[:max_tokens]
return decode(truncated_tokens)
return text
# Example: Truncating to 4000 tokens
long_document = load_document("legal_contract.pdf")
truncated = truncate_text(long_document, 4000)
response = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[{"role": "user", "content": truncated}]
)
Een meer geavanceerde afkapstrategie maakt onderscheid tussen essentiële en optionele content. Je kunt prioriteit geven aan onmisbare elementen zoals de huidige gebruikersvraag en kerninstructies, en vervolgens optionele context zoals gespreksgeschiedenis alleen toevoegen als er ruimte over is. Deze aanpak bewaart kritieke informatie terwijl je toch binnen de tokenlimiet blijft.
In plaats van af te kappen, verdeelt chunking je content in kleinere, beheersbare stukken die onafhankelijk of selectief kunnen worden verwerkt. Chunking met vaste grootte deelt tekst op in uniforme segmenten, terwijl semantische chunking gebruikmaakt van embeddings om natuurlijke breekpunten te vinden op basis van betekenis in plaats van arbitraire tokenaantallen. Sliding windows met overlap behouden context tussen chunks, zodat belangrijke informatie die over chunkgrenzen reikt niet verloren gaat.
Hiërarchische chunking creëert meerdere abstractieniveaus—individuele alinea’s op het laagste niveau, secties op het volgende niveau en hoofdstukken op het hoogste niveau. Deze aanpak maakt geavanceerde retrievalstrategieën mogelijk waarbij je snel relevante secties kunt identificeren zonder het hele document te hoeven verwerken. In combinatie met vectordatabases en semantische zoekopdrachten wordt chunking een krachtig instrument voor het beheren van grote kennisbanken met behoud van relevantie en nauwkeurigheid.
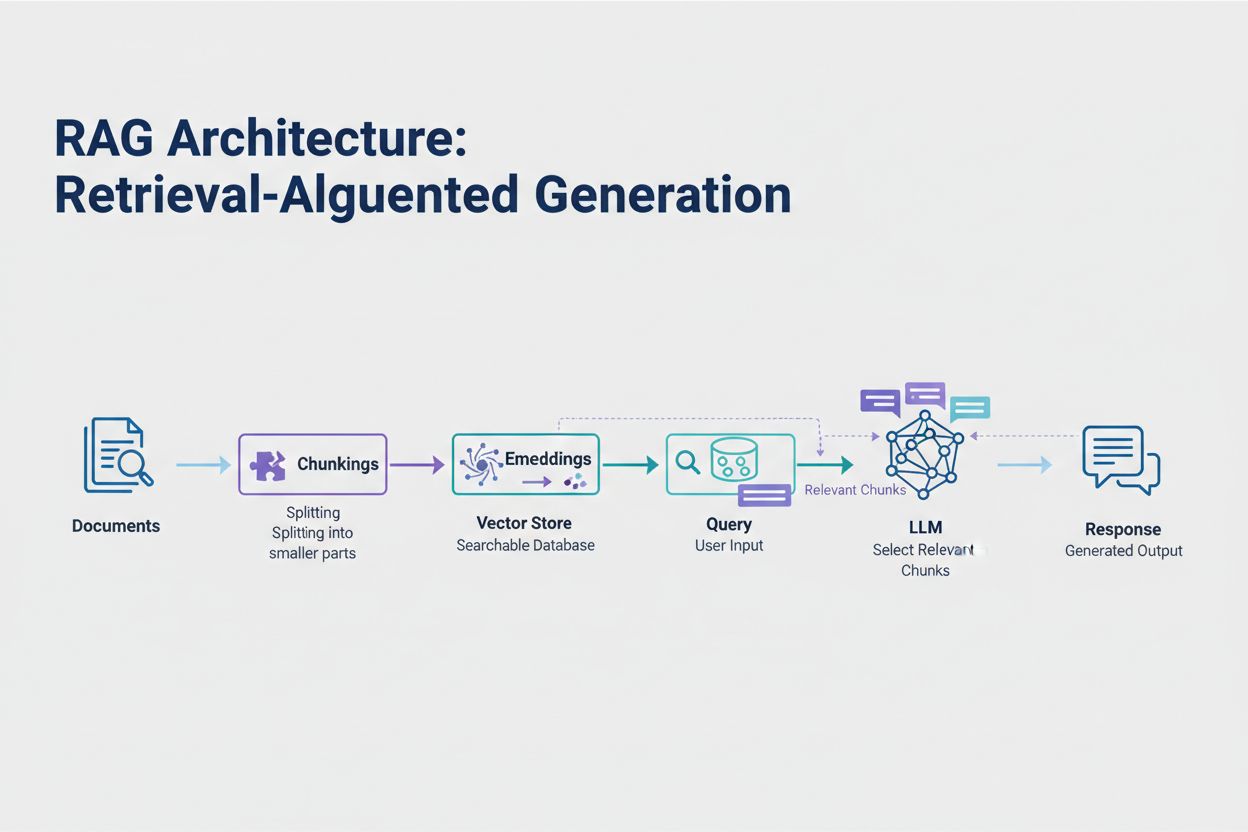
Retrieval-Augmented Generation (RAG) is de meest effectieve moderne aanpak voor het omgaan met tokenlimieten. In plaats van te proberen alle data in het contextvenster van het model te proppen, haalt RAG alleen de meest relevante informatie op het moment van de vraag op. Het proces begint met het omzetten van je documenten in embeddings—numerieke representaties die semantische betekenis vastleggen. Deze embeddings worden opgeslagen in een vectordatabank, zodat snel op gelijkenis gezocht kan worden.
Wanneer een gebruiker een vraag stelt, embedt het systeem de vraag en haalt het de meest relevante documentchunks uit de vectorstore. Alleen deze relevante stukken worden samen met de vraag van de gebruiker in de prompt geplaatst, waardoor het tokenverbruik drastisch wordt verminderd en de nauwkeurigheid stijgt. Zo kan je bij het analyseren van een juridisch contract van 100 pagina’s met RAG volstaan met slechts 3-5 kernclausules in de prompt, vergeleken met de duizenden tokens die nodig zouden zijn voor het hele document.
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import FAISS
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.chat_models import ChatOpenAI
from langchain.chains import RetrievalQA
# Step 1: Load and chunk documents
documents = load_documents("knowledge_base/")
splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50)
chunks = splitter.split_documents(documents)
# Step 2: Create embeddings and vector store
embeddings = OpenAIEmbeddings()
vectorstore = FAISS.from_documents(chunks, embeddings)
# Step 3: Set up RAG chain
retriever = vectorstore.as_retriever(search_kwargs={"k": 5})
llm = ChatOpenAI(model="gpt-4", temperature=0)
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
retriever=retriever,
return_source_documents=True
)
# Step 4: Query the system
result = qa_chain.run("What are the key terms of this contract?")
Samenvatten condenseert lange content terwijl essentiële informatie behouden blijft, waardoor het tokenverbruik effectief wordt teruggedrongen. Extractieve samenvatting selecteert kernzinnen uit de originele tekst, terwijl abstractive samenvatting nieuwe, beknopte tekst genereert die de hoofdgedachten weergeeft. Hiërarchische samenvatting creëert meerdere niveaus van samenvattingen—eerst op sectieniveau, daarna gecombineerd tot hogere overzichten. Deze aanpak werkt vooral goed bij gestructureerde documenten zoals onderzoeksrapporten of technische rapportages.
Contextcompressie volgt een andere benadering door redundantie en overbodige content te verwijderen, terwijl de oorspronkelijke formulering behouden blijft. Kennisgraafbenaderingen extraheren entiteiten en relaties uit tekst en reconstrueren vervolgens de context met enkel de meest relevante feiten. Met deze technieken kun je 40-60% minder tokens gebruiken zonder semantische nauwkeurigheid te verliezen, wat ze waardevol maakt voor kostenoptimalisatie in productieomgevingen.
Tokenbeheer heeft direct effect op de kosten van je AI-toepassing. Elk token dat tijdens inferentie wordt verbruikt, brengt kosten met zich mee en de kosten schalen lineair mee met het tokengebruik. Het monitoren van het tokenverbruik is essentieel om je kostenstructuur te begrijpen en optimalisatiemogelijkheden te ontdekken. Veel AI-platformen bieden nu hulpmiddelen om tokens te tellen en realtime dashboards die gebruikspatronen bijhouden, zodat je kunt zien welke vragen of functies de meeste tokens verbruiken.
Effectieve monitoring brengt optimalisatiemogelijkheden aan het licht—misschien overschrijden bepaalde soorten vragen consequent de tokenlimieten of verbruiken specifieke functies onevenredig veel middelen. Door deze patronen te volgen, kun je weloverwogen besluiten nemen over welke optimalisatiestrategie je inzet. Sommige toepassingen profiteren van het routeren van grote verzoeken naar krachtigere (maar duurdere) modellen, terwijl andere meer baat hebben bij het implementeren van RAG of samenvatting. Het belangrijkste is om daadwerkelijke prestaties en kosten te meten om je optimalisatiekeuze te valideren.
De juiste strategie voor tokenbeheer hangt af van je specifieke use case, prestatie-eisen en kostenbeperkingen. Toepassingen die hoge nauwkeurigheid met onderbouwde antwoorden vereisen, profiteren het meest van RAG, dat de informatienauwkeurigheid behoudt bij efficiënt tokenbeheer. Langlopende conversatietoepassingen hebben baat bij geheugenbufferingstechnieken die de gespreksgeschiedenis samenvatten en belangrijke beslissingen en context behouden. Documentintensieve toepassingen, zoals juridische analyse of onderzoekstools, profiteren vaak van hiërarchische samenvatting gecombineerd met semantische chunking.
Testen en valideren zijn cruciaal voordat je een strategie voor tokenbeheer in productie brengt. Maak testcases die je modeltokenlimieten overschrijden en evalueer hoe verschillende strategieën de nauwkeurigheid, latentie en kosten beïnvloeden. Meet metrics zoals relevantie van antwoorden, feitelijke juistheid en tokefficiëntie om te waarborgen dat je aanpak aan je eisen voldoet. Veelvoorkomende valkuilen zijn te agressief samenvatten waardoor belangrijke details verloren gaan, retrievalsystemen die relevante informatie missen en chunkingstrategieën die content op semantisch ongeschikte plekken opdelen.
Tokenlimieten blijven toenemen naarmate modellen geavanceerder en efficiënter worden. Opkomende technieken zoals sparse attention-mechanismen en efficiënte transformers beloven de rekenkosten voor het verwerken van grote contextvensters te verlagen. Multimodale modellen die tekst, afbeeldingen, audio en video tegelijkertijd verwerken, introduceren nieuwe uitdagingen en kansen voor tokenisatie. Reasoning tokens—speciale tokens waarmee modellen complexe problemen “doordenken”—vormen een nieuwe categorie van tokenverbruik die geavanceerdere probleemoplossing mogelijk maakt, maar zorgvuldig beheer vereist.
De trend is duidelijk: naarmate contextvensters groeien en tokenverwerking efficiënter wordt, verschuift de bottleneck van pure capaciteit naar intelligente contentselectie. De toekomst is aan systemen die effectief de meest relevante informatie uit enorme kennisbanken kunnen selecteren en ophalen, in plaats van systemen die simpelweg grotere hoeveelheden data verwerken. Dit maakt technieken als RAG en semantische zoekopdrachten steeds belangrijker bij het bouwen van schaalbare, kostenefficiënte AI-toepassingen.
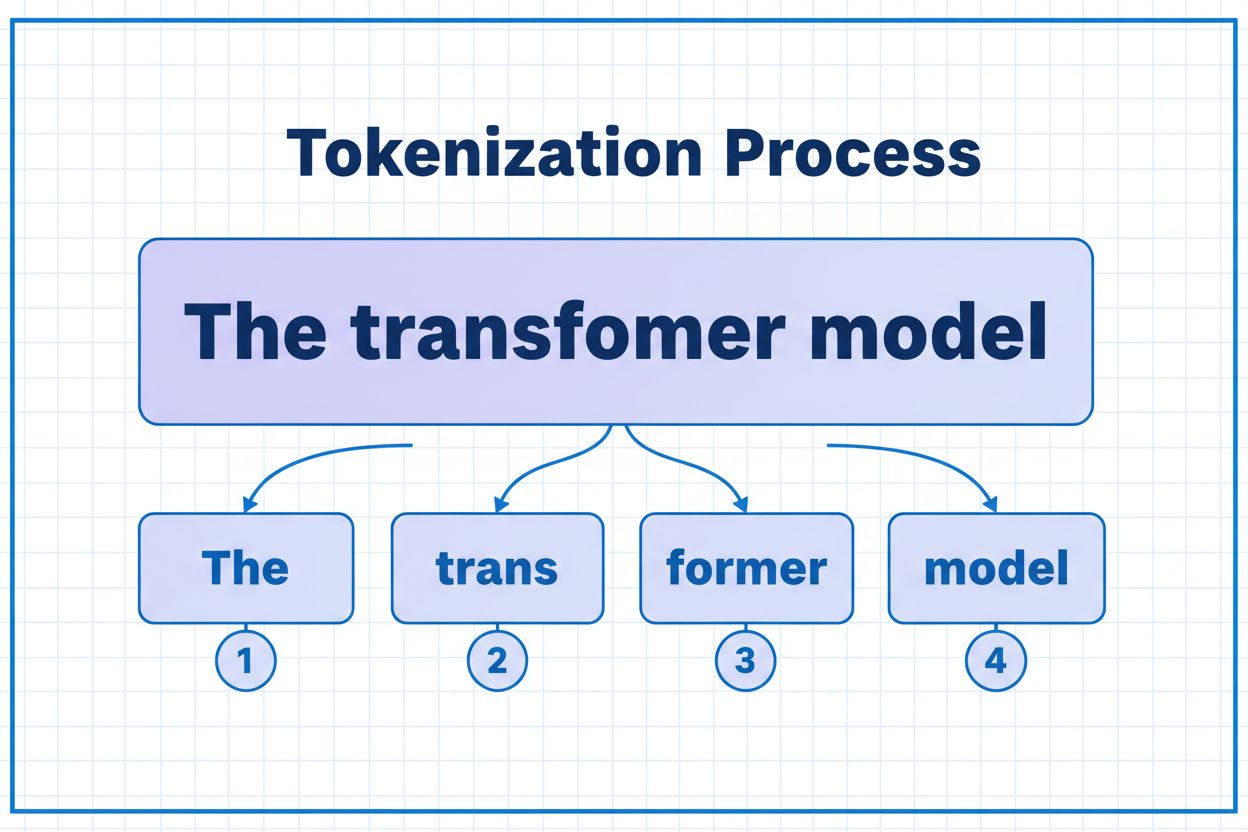
Een token is de kleinste eenheid van data die een AI-model verwerkt. Tokens kunnen individuele karakters, subwoorden of volledige woorden zijn afhankelijk van het tokenisatie-algoritme. Bijvoorbeeld, het woord 'transformer' kan worden opgesplitst in 'trans' en 'former' als twee afzonderlijke tokens. Elk token krijgt een unieke numerieke identificatie die het model intern gebruikt voor berekeningen.
Tokenlimieten bepalen de maximale hoeveelheid informatie die je AI-model in één verzoek kan verwerken. Wanneer je deze limiet overschrijdt, faalt je toepassing volledig. Zelfs als je binnen de limieten blijft, kunnen naïeve benaderingen zoals afkappen de nauwkeurigheid verminderen doordat essentiële context wordt verwijderd. Tokenlimieten hebben ook direct invloed op de kosten, omdat je meestal per verbruikt token betaalt.
Inputtokens zijn de tokens in je prompt en data die je naar het model stuurt, terwijl outputtokens de tokens zijn die het model genereert in zijn antwoord. Deze delen een gecombineerd budget dat wordt bepaald door het contextvenster van het model. Als je input 90% gebruikt van een venster van 128K tokens, heb je nog maar 10% over voor de output van het model.
Afkappen is eenvoudig te implementeren maar risicovol. Het verwijdert informatie zonder dat het model weet wat er verloren is gegaan, wat leidt tot onvolledige analyses en mogelijke hallucinaties. Hoewel het als laatste redmiddel bruikbaar is, zijn betere benaderingen zoals RAG, chunking of samenvatting effectiever omdat ze de informatienauwkeurigheid behouden terwijl het tokenverbruik beter wordt beheerd.
Retrieval-Augmented Generation (RAG) haalt alleen de meest relevante informatie op tijdens het stellen van een vraag in plaats van volledige documenten op te nemen. Je documenten worden omgezet in embeddings en opgeslagen in een vectordatabank. Wanneer een gebruiker een vraag stelt, haalt het systeem alleen relevante stukken op en voegt deze toe aan de prompt, waardoor het tokenverbruik aanzienlijk wordt verminderd en de nauwkeurigheid wordt verhoogd.
De meeste AI-platformen bieden hulpmiddelen voor het tellen van tokens en realtime dashboards om gebruikspatronen te volgen. Monitor welke vragen of functies de meeste tokens verbruiken en implementeer vervolgens optimalisatiestrategieën zoals RAG voor documentintensieve toepassingen, samenvatting voor lange gesprekken of het doorsturen naar grotere modellen voor complexe taken. Meet de daadwerkelijke prestaties en kosten om je keuzes te valideren.
AI-diensten rekenen doorgaans per verbruikt token. De kosten schalen lineair met het tokenverbruik, waardoor tokenoptimalisatie direct invloed heeft op je uitgaven. Een daling van 20% in tokenverbruik vertaalt zich in 20% kostenbesparing. Begrip van tokefficiëntie helpt je de juiste optimalisatiestrategie te kiezen binnen je budgettaire grenzen.
Tokenlimieten blijven toenemen naarmate modellen geavanceerder worden. Opkomende technieken zoals sparse attention-mechanismen beloven de rekencapaciteit voor het verwerken van grote contexten te verlagen. De toekomst richt zich op intelligente contentselectie en -opvraging in plaats van alleen maar op ruwe verwerkingscapaciteit, waardoor technieken zoals RAG steeds belangrijker worden voor schaalbare AI-toepassingen.
Begrijp tokefficiëntie en volg hoe AI-modellen je merk citeren met het uitgebreide AI-citatiemonitoringsplatform van AmICited.
Ontdek wat tokens zijn in taalmodellen. Tokens zijn fundamentele eenheden van tekstanalyse in AI-systemen, waarbij woorden, subwoorden of karakters als numeriek...

Ontdek hoe AI-modellen tekst verwerken via tokenisatie, embeddings, transformer-blokken en neurale netwerken. Begrijp de volledige pijplijn van invoer naar uitv...
Leer hoe je de leesbaarheid van inhoud optimaliseert voor AI-systemen, ChatGPT, Perplexity en AI-zoekmachines. Ontdek best practices voor structuur, opmaak en d...
Cookie Toestemming
We gebruiken cookies om uw browse-ervaring te verbeteren en ons verkeer te analyseren. See our privacy policy.