Optimalisatiestrategieën: Trainingsdata versus Real-Time Retrieval
Vergelijk optimalisatiestrategieën van trainingsdata en real-time retrieval voor AI. Leer wanneer je fine-tuning of RAG gebruikt, kostenoverwegingen en hybride benaderingen voor optimale AI-prestaties.
Gepubliceerd op Jan 3, 2026.Laatst gewijzigd op Jan 3, 2026 om 3:24 am
Optimalisatie van trainingsdata en real-time retrieval zijn fundamenteel verschillende benaderingen om AI-modellen van kennis te voorzien. Optimalisatie van trainingsdata houdt in dat kennis direct in de parameters van een model wordt verwerkt via fine-tuning op domeinspecifieke datasets, waardoor statische kennis ontstaat die na afronding van de training vastligt. Real-time retrieval daarentegen houdt kennis buiten het model en haalt relevante informatie dynamisch op tijdens de voorspelling, waardoor toegang ontstaat tot dynamische informatie die tussen verzoeken kan veranderen. Het belangrijkste verschil ligt in wanneer kennis in het model wordt geïntegreerd: optimalisatie van trainingsdata vindt plaats vóór implementatie, terwijl real-time retrieval gebeurt bij elke voorspelling. Dit fundamentele verschil werkt door in elk aspect van de implementatie, van infrastructuurvereisten tot nauwkeurigheid en compliance. Dit onderscheid begrijpen is essentieel voor organisaties die moeten bepalen welke optimalisatiestrategie aansluit bij hun specifieke toepassingen en beperkingen.
Hoe optimalisatie van trainingsdata werkt
Optimalisatie van trainingsdata werkt door systematisch de interne parameters van een model aan te passen door blootstelling aan zorgvuldig samengestelde, domeinspecifieke datasets tijdens het fine-tuningproces. Wanneer een model trainingsvoorbeelden herhaaldelijk tegenkomt, internaliseert het geleidelijk patronen, terminologie en domeinexpertise via backpropagation en gradient updates die de leermechanismen van het model hervormen. Dit proces stelt organisaties in staat om gespecialiseerde kennis—zoals medische terminologie, juridische kaders of bedrijfslogica—direct in de gewichten en biases van het model te coderen. Het resulterende model wordt sterk gespecialiseerd voor het doelgebied en behaalt vaak prestaties die vergelijkbaar zijn met veel grotere modellen; onderzoek van Snorkel AI toonde aan dat fijn-afgestelde kleinere modellen even goed kunnen presteren als modellen die 1.400 keer groter zijn. Belangrijke kenmerken van optimalisatie van trainingsdata zijn:
Permanente kennisintegratie: Na training is de kennis onderdeel van het model en zijn er geen externe opvragingen nodig
Lage inference latency: Geen retrieval-overhead tijdens voorspellingen, waardoor snellere responstijden mogelijk zijn
Consistente stijl en opmaak: Modellen leren domeinspecifieke communicatiepatronen en conventies
Mogelijkheid tot offline gebruik: Modellen functioneren zelfstandig zonder externe databronnen
Hoge initiële computationele kosten: Vereist aanzienlijke GPU-middelen en voorbereiding van gelabelde trainingsdata
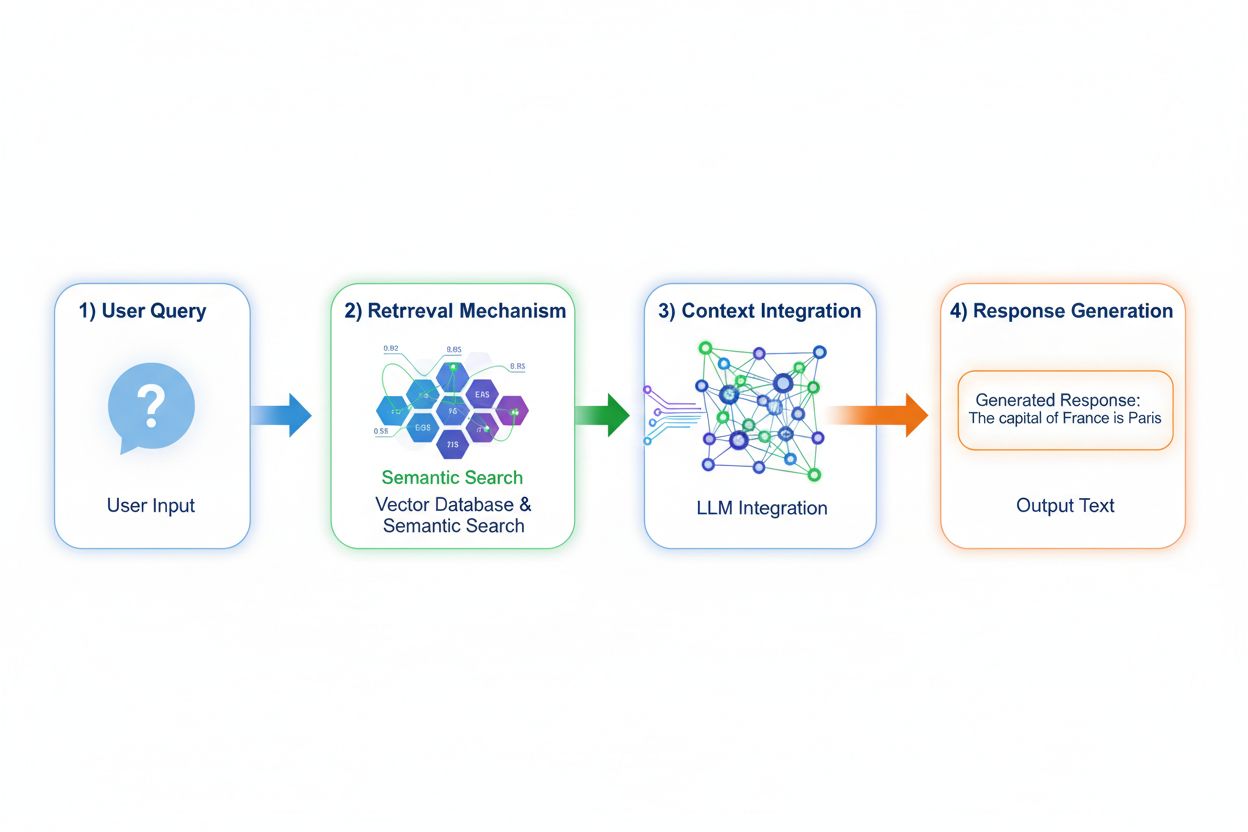
Retrieval Augmented Generation (RAG) verandert fundamenteel hoe modellen toegang krijgen tot kennis door een proces in vier fasen te implementeren: query-encoding, semantisch zoeken, context-ranking en generatie met onderbouwing. Wanneer een gebruiker een vraag indient, zet RAG deze eerst om in een dense vectorrepresentatie met embedding-modellen, en doorzoekt vervolgens een vector database met geïndexeerde documenten of kennisbronnen. De retrievalfase gebruikt semantisch zoeken om contextueel relevante passages te vinden in plaats van simpelweg op trefwoorden te zoeken, waarbij resultaten worden gerangschikt op relevantiescore. Ten slotte genereert het model antwoorden met expliciete verwijzingen naar de opgehaalde bronnen, waardoor de output wordt onderbouwd met feitelijke data in plaats van aangeleerde parameters. Dankzij deze architectuur kunnen modellen informatie raadplegen die tijdens de training nog niet bestond, waardoor RAG bijzonder waardevol is voor toepassingen die actuele informatie, eigendomsdata of vaak bijgewerkte kennisbanken vereisen. Het RAG-mechanisme transformeert het model van een statische kennisbank tot een dynamische informatiesynthesizer die nieuwe data kan verwerken zonder opnieuw trainen.
Vergelijking van prestaties en nauwkeurigheid
De nauwkeurigheid en het hallucinatieprofiel van deze benaderingen verschillen aanzienlijk en beïnvloeden de praktische inzet. Optimalisatie van trainingsdata levert modellen met diepgaand domeinbegrip, maar beperkte erkenning van kennishiaten; wanneer een fine-tuned model vragen buiten zijn trainingsgebied tegenkomt, kan het met vertrouwen plausibel klinkende, maar onjuiste informatie genereren. RAG vermindert hallucinaties aanzienlijk door antwoorden te baseren op opgehaalde documenten—het model kan geen informatie claimen die niet in het bronmateriaal voorkomt, wat natuurlijke beperkingen oplegt aan verzinsels. RAG introduceert echter andere nauwkeurigheidsrisico’s: als de retrievalfase er niet in slaagt relevante bronnen te vinden of irrelevante documenten hoog rangschikt, genereert het model antwoorden op basis van slechte context. Data-actualiteit wordt cruciaal voor RAG-systemen; optimalisatie van trainingsdata legt een statisch momentopname vast bij de training, terwijl RAG voortdurend de actuele stand van brondocumenten weerspiegelt. Bronvermelding biedt een ander verschil: RAG maakt van nature citatie en verificatie van claims mogelijk, terwijl fine-tuned modellen geen specifieke bronnen voor hun kennis kunnen aanwijzen, wat factchecking en compliance compliceert.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Kosten en infrastructuurimplicaties
De economische profielen van deze benaderingen leiden tot verschillende kostenstructuren die organisaties zorgvuldig moeten evalueren. Optimalisatie van trainingsdata vereist aanzienlijke computationele kosten vooraf: GPU-clusters die dagen of weken nodig hebben om modellen te fine-tunen, data-annotatie om gelabelde trainingsdatasets te creëren, en ML-engineeringsexpertise voor het ontwerpen van effectieve trainingspijplijnen. Na training blijven de gebruikskosten relatief laag omdat inference alleen standaard modelinfrastructuur vereist zonder externe opvragingen. RAG-systemen draaien deze kostenstructuur om: lagere initiële trainingskosten omdat geen fine-tuning plaatsvindt, maar doorlopende infrastructuurkosten voor het onderhouden van vector databases, embedding-modellen, retrieval services en documentindexering. Belangrijke kostenfactoren zijn:
Fine-tuning: GPU-uren ($10.000-$100.000+ per model), data-annotatie ($0,50-$5 per voorbeeld), engineeringstijd
RAG-infrastructuur: Licenties voor vector databases, embedding model serving, documentopslag en indexering, optimalisatie van retrieval latency
Schaalbaarheid: Fine-tuned modellen schalen lineair met het aantal voorspellingen; RAG-systemen schalen met zowel voorspellingen als omvang van de kennisbank
Onderhoud: Fine-tuning vereist periodiek opnieuw trainen; RAG vereist continue documentupdates en indexonderhoud
Veiligheid en compliance-overwegingen
De veiligheids- en compliance-implicaties verschillen sterk tussen deze benaderingen en zijn van groot belang voor gereguleerde sectoren. Fine-tuned modellen creëren databeschermingsuitdagingen omdat trainingsdata in de modelgewichten wordt verwerkt; het extraheren of auditen van kennis in het model vereist geavanceerde technieken, en privacyproblemen ontstaan wanneer gevoelige trainingsdata het modelgedrag beïnvloedt. Compliance met regelgeving zoals de AVG wordt complex omdat het model trainingsdata ‘onthoudt’ op manieren die zich moeilijk laten verwijderen of aanpassen. RAG-systemen bieden een ander veiligheidsprofiel: kennis blijft in externe, controleerbare databronnen in plaats van in modelparameters, waardoor eenvoudige beveiligingscontroles en toegangsbeperkingen mogelijk zijn. Organisaties kunnen gedetailleerde rechten toepassen op retrievalbronnen, auditen welke documenten het model heeft geraadpleegd en snel gevoelige informatie verwijderen door brondocumenten te updaten zonder opnieuw te trainen. RAG introduceert echter veiligheidsrisico’s rond bescherming van vector databases, embedding model security en waarborging dat opgehaalde documenten geen gevoelige informatie lekken. HIPAA-gereguleerde zorg en Europese organisaties onder de AVG kiezen vaak voor RAG vanwege transparantie en controleerbaarheid, terwijl organisaties die modelportabiliteit en offline gebruik prioriteren de voorkeur geven aan de zelfvoorzienendheid van fine-tuning.
Praktisch besliskader
De keuze tussen deze benaderingen vereist een evaluatie van organisatorische beperkingen en use case-eigenschappen. Organisaties kiezen bij voorkeur voor fine-tuning wanneer kennis stabiel is en zelden verandert, inference latency kritisch is, modellen offline of in afgesloten omgevingen moeten werken, of wanneer consistente stijl en domeinspecifieke opmaak belangrijk zijn. Real-time retrieval is de voorkeur bij regelmatig veranderende kennis, wanneer bronvermelding en controleerbaarheid relevant zijn voor compliance, wanneer de kennisbank te groot is om efficiënt in modelparameters te coderen, of wanneer organisaties informatie willen bijwerken zonder het model opnieuw te trainen. Specifieke use cases illustreren deze verschillen:
Fine-tuning: Klantenservicebots voor stabiele productinformatie, gespecialiseerde medische diagnoseassistenten, analyse van juridische documenten voor gevestigde jurisprudentie
RAG: Nieuwssamenvatting met actuele gebeurtenissen, klantenservice met regelmatig bijgewerkte productcatalogi, onderzoeksassistenten die dynamische wetenschappelijke literatuur raadplegen
Besliskader: Evalueer kennisstabiliteit, compliance-eisen, latency, updatefrequentie en infrastructuurmogelijkheden
Hybride benaderingen en gecombineerde strategieën
Hybride benaderingen combineren fine-tuning en RAG om de voordelen van beide strategieën te benutten en individuele beperkingen te verminderen. Organisaties kunnen modellen fine-tunen op domeinbasis en communicatiepatronen, terwijl ze RAG gebruiken voor actuele en gedetailleerde informatie—het model leert hoe over het domein te denken en haalt welke specifieke feiten het moet verwerken. Deze gecombineerde strategie is bijzonder effectief voor toepassingen die zowel gespecialiseerde expertise als actuele informatie vereisen: een financiële adviesbot die getraind is op beleggingsprincipes en terminologie kan realtime marktdata en bedrijfsinformatie ophalen via RAG. Hybride implementaties in de praktijk zijn onder meer zorgsystemen die fine-tunen op medische kennis en protocollen en patiëntdata via RAG ophalen, en juridische onderzoeksplatformen die fine-tunen op juridische redeneringen en actuele jurisprudentie ophalen. De synergievoordelen zijn onder meer minder hallucinaties (onderbouwing met opgehaalde bronnen), beter domeinbegrip (door fine-tuning), snellere inference op veelvoorkomende vragen (gecachede kennis), en flexibiliteit om specialistische informatie te actualiseren zonder opnieuw te trainen. Steeds meer organisaties kiezen deze optimalisatie naarmate computationele middelen toegankelijker worden en de complexiteit van toepassingen zowel diepgang als actualiteit vereist.
Monitoring van AI-antwoorden en citatietracking
Het realtime monitoren van AI-antwoorden wordt steeds belangrijker naarmate organisaties deze optimalisatiestrategieën op schaal inzetten, zeker om te begrijpen welke aanpak voor specifieke toepassingen de beste resultaten oplevert. AI-monitoringsystemen volgen outputs van modellen, retrievalkwaliteit en gebruikerswaarderingsstatistieken, zodat organisaties kunnen meten of fine-tuned modellen of RAG-systemen hun toepassingen beter ondersteunen. Citatietracking onthult cruciale verschillen: RAG-systemen genereren van nature citaties en bronverwijzingen, waardoor een audittrail ontstaat van welke documenten elk antwoord beïnvloeden, terwijl fine-tuned modellen geen ingebouwd mechanisme bieden voor antwoordmonitoring of toewijzing. Dit verschil is van groot belang voor merkintegriteit en concurrentie-inzicht—organisaties moeten begrijpen hoe AI-systemen hun concurrenten citeren, hun producten noemen of informatie aan bronnen toeschrijven. Tools zoals AmICited.com vullen deze leemte door te monitoren hoe AI-systemen merken en bedrijven citeren bij verschillende optimalisatiestrategieën, met realtime tracking van citatiepatronen en frequentie. Door uitgebreide monitoring kunnen organisaties meten of hun gekozen optimalisatiestrategie (fine-tuning, RAG of hybride) daadwerkelijk de citatienauwkeurigheid verbetert, hallucinaties over concurrenten vermindert en juiste bronvermelding aan gezaghebbende bronnen waarborgt. Deze datagedreven aanpak maakt continue verfijning van optimalisatiestrategieën mogelijk op basis van daadwerkelijke prestaties in plaats van aannames.
Toekomsttrends en opkomende patronen
De sector ontwikkelt zich richting meer geavanceerde hybride en adaptieve benaderingen die dynamisch tussen optimalisatiestrategieën wisselen op basis van vraagkarakteristieken en kennisbehoeften. Opkomende best practices omvatten retrieval-augmented fine-tuning, waarbij modellen worden fine-tuned op het effectief gebruiken van opgehaalde informatie in plaats van feiten te onthouden, en adaptieve routersystemen die vragen naar fine-tuned modellen sturen voor stabiele kennis en naar RAG-systemen voor dynamische informatie. Trends laten toenemende adoptie zien van gespecialiseerde embedding-modellen en vector databases geoptimaliseerd voor specifieke domeinen, wat zorgt voor preciezere semantische zoekopdrachten en minder retrievalruis. Organisaties ontwikkelen patronen voor continue modelverbetering, waarbij periodieke fine-tuning wordt gecombineerd met real-time RAG-aanvulling, zodat systemen over tijd verbeteren en toch actuele informatie behouden. De evolutie van optimalisatiestrategieën weerspiegelt het besef dat geen enkele aanpak alle toepassingen optimaal bedient; toekomstige systemen zullen waarschijnlijk slimme selectiemechanismen implementeren die dynamisch kiezen tussen fine-tuning, RAG en hybride aanpak op basis van de context van de vraag, kennisstabiliteit, latency-eisen en compliance. Naarmate deze technologieën volwassen worden, verschuift het concurrentievoordeel van het kiezen van één aanpak naar het deskundig implementeren van adaptieve systemen die de kracht van elke strategie benutten.
Veelgestelde vragen
Wat is het belangrijkste verschil tussen optimalisatie van trainingsdata en real-time retrieval?
Optimalisatie van trainingsdata verwerkt kennis direct in de parameters van een model door middel van fine-tuning, waardoor statische kennis ontstaat die na training vastligt. Real-time retrieval laat kennis extern en haalt relevante informatie dynamisch op tijdens de voorspelling, waardoor toegang tot dynamische informatie mogelijk is die tussen aanvragen kan veranderen. Het kernverschil is wanneer kennis wordt geïntegreerd: optimalisatie van trainingsdata vindt plaats vóór uitrol, terwijl real-time retrieval gebeurt bij elke voorspelling.
Wanneer moet ik fine-tuning gebruiken in plaats van RAG?
Gebruik fine-tuning wanneer kennis stabiel is en waarschijnlijk niet vaak verandert, wanneer inference latency cruciaal is, wanneer modellen offline moeten werken, of wanneer een consistente stijl en domeinspecifieke opmaak essentieel zijn. Fine-tuning is ideaal voor gespecialiseerde taken zoals medische diagnoses, analyse van juridische documenten of klantenservice met stabiele productinformatie. Echter, fine-tuning vereist aanzienlijke initiële computationele middelen en wordt onpraktisch als informatie vaak verandert.
Kan ik optimalisatie van trainingsdata combineren met real-time retrieval?
Ja, hybride benaderingen combineren fine-tuning en RAG om de voordelen van beide strategieën te benutten. Organisaties kunnen modellen fine-tunen op de basis van het domein en RAG gebruiken om actuele, gedetailleerde informatie op te halen. Deze aanpak is bijzonder effectief voor toepassingen die zowel gespecialiseerde expertise als actuele informatie vereisen, zoals financiële adviesbots of zorgsystemen die zowel medische kennis als patiëntspecifieke data nodig hebben.
Hoe vermindert RAG hallucinaties in vergelijking met fine-tuning?
RAG vermindert hallucinaties aanzienlijk door antwoorden te baseren op opgehaalde documenten—het model kan geen informatie claimen die niet in het bronmateriaal voorkomt, wat natuurlijke beperkingen oplegt aan verzinsels. Fine-tuned modellen daarentegen kunnen vol vertrouwen plausibel klinkende maar onjuiste informatie genereren bij vragen buiten hun trainingsdistributie. RAG's bronvermelding maakt het ook mogelijk claims te verifiëren, terwijl fine-tuned modellen niet naar specifieke bronnen voor hun kennis kunnen verwijzen.
Wat zijn de kostenimplicaties van elke aanpak?
Fine-tuning vereist hoge initiële kosten: GPU-uren ($10.000-$100.000+ per model), data-annotatie ($0,50-$5 per voorbeeld) en engineeringstijd. Na training blijven de gebruikskosten relatief laag. RAG-systemen hebben lagere initiële kosten, maar doorlopende infrastructuurkosten voor vector databases, embedding-modellen en retrieval services. Fine-tuned modellen schalen lineair met het aantal voorspellingen, terwijl RAG-systemen schalen met zowel het aantal voorspellingen als de omvang van de kennisbank.
Hoe helpt real-time retrieval bij AI-citatiemonitoring?
RAG-systemen genereren van nature citaties en bronverwijzingen, waardoor een audittrail ontstaat van welke documenten elk antwoord hebben beïnvloed. Dit is cruciaal voor merkintegriteit en concurrentie-inzicht—organisaties kunnen volgen hoe AI-systemen hun concurrenten citeren en hun producten genoemd worden. Tools zoals AmICited.com monitoren hoe AI-systemen merken citeren bij verschillende optimalisatiestrategieën en bieden realtime inzicht in citatiepatronen en frequentie.
Welke aanpak is beter voor sterk gereguleerde sectoren?
RAG is over het algemeen beter voor sterk gereguleerde sectoren zoals de gezondheidszorg en financiën. Kennis blijft in externe, controleerbare databronnen in plaats van in de parameters van het model, waardoor eenvoudige beveiligingscontroles en toegangsbeperkingen mogelijk zijn. Organisaties kunnen gedetailleerde permissies implementeren, auditen welke documenten het model heeft geraadpleegd en snel gevoelige informatie verwijderen zonder opnieuw te trainen. Voor HIPAA-gereguleerde zorg en organisaties onder de AVG heeft RAG de voorkeur vanwege transparantie en controleerbaarheid.
Hoe monitor ik de effectiviteit van mijn gekozen optimalisatiestrategie?
Implementeer AI-monitoringsystemen die modeloutputs, retrievalkwaliteit en gebruikerswaarderingsstatistieken bijhouden. Voor RAG-systemen monitor je retrievalnauwkeurigheid en citatiekwaliteit. Voor fine-tuned modellen volg je nauwkeurigheid op domeintaken en het aantal hallucinaties. Gebruik tools zoals AmICited.com om te monitoren hoe jouw AI-systemen informatie citeren en vergelijk prestaties van verschillende optimalisatiestrategieën op basis van echte resultaten.
Monitor hoe AI-systemen jouw merk citeren
Volg realtime citaties in GPT's, Perplexity en Google AI Overzichten. Begrijp welke optimalisatiestrategieën jouw concurrenten toepassen en hoe ze worden genoemd in AI-antwoorden.
Hoe optimaliseer je jouw content voor AI-trainingsdata en AI-zoekmachines
Leer hoe je jouw content optimaliseert voor opname in AI-trainingsdata. Ontdek best practices om je website vindbaar te maken voor ChatGPT, Gemini, Perplexity e...
Trainingsdata vs Live Search: Hoe AI-systemen informatie benaderen
Begrijp het verschil tussen AI-trainingsdata en live search. Leer hoe kennis-afkaps, RAG en realtime retrieval invloed hebben op AI-zichtbaarheid en contentstra...
Ontdek hoe realtime zoeken in AI werkt, de voordelen voor gebruikers en bedrijven, en hoe het verschilt van traditionele zoekmachines en statische AI-modellen.
12 min lezen
Cookie Toestemming We gebruiken cookies om uw browse-ervaring te verbeteren en ons verkeer te analyseren. See our privacy policy.