
Wat zijn embeddings in AI-zoekopdrachten?
Leer hoe embeddings werken in AI-zoekmachines en taalmodellen. Begrijp vectorrepresentaties, semantisch zoeken en hun rol in AI-gegenereerde antwoorden.
8 min lezen

Ontdek hoe vector-embeddings AI-systemen in staat stellen semantische betekenis te begrijpen en content te koppelen aan zoekopdrachten. Verken de technologie achter semantisch zoeken en AI-contentmatching.

Vector-embeddings vormen het numerieke fundament achter moderne kunstmatige intelligentiesystemen, doordat ze ruwe data omzetten in wiskundige representaties die machines kunnen begrijpen en verwerken. In de kern zetten embeddings tekst, afbeeldingen, audio en andere soorten content om in reeksen getallen—meestal variërend van tientallen tot duizenden dimensies—die de semantische betekenis en contextuele relaties binnen die data vastleggen. Deze numerieke representatie is essentieel voor hoe AI-systemen contentmatching, semantisch zoeken en aanbevelingstaken uitvoeren. Zo begrijpen machines niet alleen welke woorden of afbeeldingen aanwezig zijn, maar ook wat ze daadwerkelijk betekenen. Zonder embeddings zouden AI-systemen moeite hebben om genuanceerde relaties tussen concepten te vatten, waardoor ze een onmisbare bouwsteen zijn voor elke moderne AI-toepassing.
De omzetting van ruwe data naar vector-embeddings gebeurt via geavanceerde neurale netwerkmodellen die zijn getraind op enorme datasets om betekenisvolle patronen en relaties te leren. Wanneer je tekst invoert in een embeddingmodel, doorloopt die tekst meerdere lagen van neurale netwerken die stapsgewijs semantische informatie extraheren, met uiteindelijk een vector van vaste grootte die de essentie van die content weergeeft. Populaire embeddingmodellen zoals Word2Vec, GloVE en BERT hanteren elk hun eigen aanpak—Word2Vec gebruikt ondiepe neurale netwerken geoptimaliseerd voor snelheid, GloVE combineert globale matrixfactorisatie met lokale contextvensters, terwijl BERT transformerarchitectuur inzet om bidirectionele context te begrijpen.
| Model | Gegevenstype | Dimensies | Primaire toepassing | Belangrijkste voordeel |
|---|---|---|---|---|
| Word2Vec | Tekst (woorden) | 100-300 | Woordrelaties | Snel, efficiënt |
| GloVE | Tekst (woorden) | 100-300 | Semantische relaties | Combineert globaal en lokaal context |
| BERT | Tekst (zinnen/docs) | 768-1024 | Contextueel begrip | Bidirectioneel contextbewustzijn |
| Sentence-BERT | Tekst (zinnen) | 384-768 | Zinsgelijkenis | Geoptimaliseerd voor semantisch zoeken |
| Universal Sentence Encoder | Tekst (zinnen) | 512 | Cross-linguale taken | Taalonafhankelijk |
Deze modellen produceren hoog-dimensionale vectoren (vaak 300 tot 1.536 dimensies), waarbij elke dimensie een ander aspect van betekenis vastlegt, van grammaticale eigenschappen tot conceptuele relaties. Het mooie van deze numerieke representatie is dat het wiskundige bewerkingen mogelijk maakt—je kunt vectoren optellen, aftrekken en vergelijken om relaties te ontdekken die in ruwe tekst onzichtbaar zouden blijven. Deze wiskundige basis maakt semantisch zoeken en intelligente contentmatching op grote schaal mogelijk.
De ware kracht van embeddings komt naar voren via semantische gelijkenis, het vermogen om te herkennen dat verschillende woorden of zinnen in vectorruimte in wezen hetzelfde kunnen betekenen. Wanneer embeddings effectief zijn gecreëerd, clusteren semantisch verwante concepten vanzelf in de hoog-dimensionale ruimte—“koning” en “koningin” zitten dicht bij elkaar, net als “auto” en “voertuig”, ook al zijn het verschillende woorden. Om deze gelijkenis te meten gebruiken AI-systemen afstandsmetingen zoals cosinusgelijkenis (de hoek tussen vectoren meten) of de dotproduct (grootte en richting meten), waarmee wordt gekwantificeerd hoe dicht twee embeddings bij elkaar liggen. Een zoekopdracht naar “automobieltransport” heeft bijvoorbeeld een hoge cosinusgelijkenis met documenten over “autoreizen”, waardoor het systeem content kan koppelen op betekenis in plaats van exacte trefwoordovereenkomst. Dit semantisch begrip onderscheidt moderne AI-zoekfuncties van simpele trefwoordmatching, waardoor systemen gebruikersintentie begrijpen en echt relevante resultaten kunnen bieden.
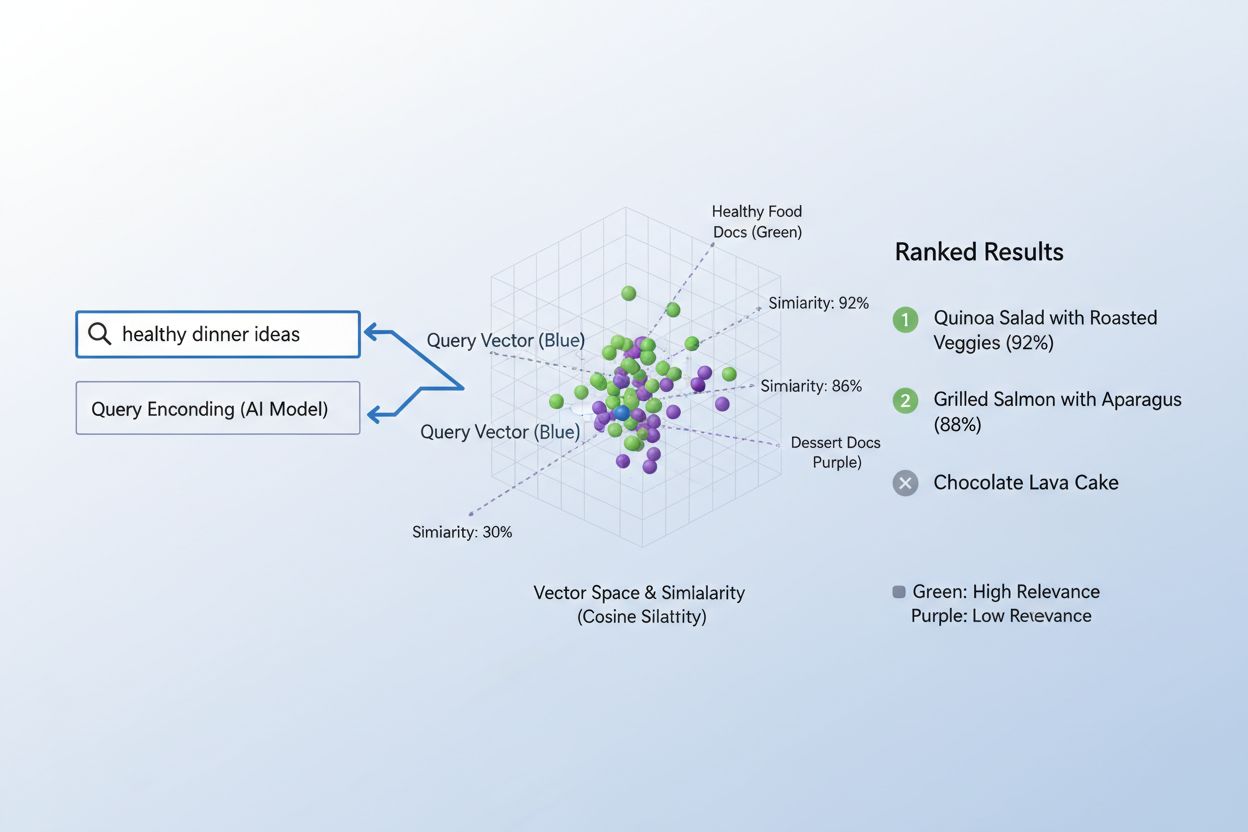
Het proces waarbij content aan zoekopdrachten wordt gekoppeld met embeddings volgt een elegante tweestapsworkflow die alles aandrijft van zoekmachines tot aanbevelingssystemen. Eerst worden zowel de zoekopdracht van de gebruiker als de beschikbare content onafhankelijk omgezet in embeddings met hetzelfde model—een vraag als “best practices voor machine learning” wordt een vector, net als elk artikel, document of product in de database van het systeem. Vervolgens berekent het systeem de gelijkenis tussen de zoekopdracht-embedding en elke content-embedding, meestal met cosinusgelijkenis, wat een score oplevert die aangeeft hoe relevant elk stuk content is voor de vraag. Deze gelijkenisscores worden gerangschikt, waarbij de content met de hoogste score aan de gebruiker wordt getoond als meest relevant. In een echte zoekmachine encodeert het systeem jouw zoekopdracht “hoe train je neurale netwerken”, vergelijkt deze met miljoenen document-embeddings, en toont artikelen over deep learning, modeloptimalisatie en trainingstechnieken—zonder dat exacte trefwoordovereenkomsten nodig zijn. Dit matchingproces gebeurt in milliseconden, waardoor het geschikt is voor real-time toepassingen die miljoenen gebruikers tegelijk bedienen.
Verschillende soorten embeddings dienen verschillende doelen, afhankelijk van wat je wilt matchen of begrijpen. Woordembeddings leggen de betekenis van individuele woorden vast en zijn geschikt voor taken die fijnmazig semantisch begrip vereisen, terwijl zinsembeddings en documentembeddings betekenis over langere tekstfragmenten aggregeren, waardoor ze ideaal zijn om volledige vragen aan complete artikelen of documenten te koppelen. Beeldembeddings representeren visuele content numeriek, zodat systemen visueel vergelijkbare afbeeldingen kunnen vinden of beelden kunnen matchen aan tekstbeschrijvingen, terwijl gebruikers- en productembeddings gedragsprofielen en kenmerken vastleggen, waarmee aanbevelingssystemen producten suggereren op basis van gebruikersvoorkeuren. De keuze tussen deze embeddingtypes brengt afwegingen met zich mee: woordembeddings zijn computationeel efficiënt maar verliezen context, terwijl documentembeddings volledige betekenis behouden maar meer rekenkracht vereisen. Domeinspecifieke embeddings, verfijnd op gespecialiseerde datasets zoals medische literatuur of juridische documenten, presteren vaak beter voor branchespecifieke toepassingen, maar vereisen extra trainingsdata en rekenkracht.
In de praktijk drijven embeddings enkele van de meest invloedrijke AI-toepassingen aan die we dagelijks gebruiken, van de zoekresultaten die je ziet tot de producten die je online worden aanbevolen. Semantische zoekmachines gebruiken embeddings om zoekintentie te begrijpen en relevante content te tonen ongeacht exacte trefwoorden, terwijl aanbevelingssystemen bij Netflix, Amazon en Spotify gebruikers- en itemembeddings inzetten om te voorspellen wat je daarna wilt kijken, kopen of beluisteren. Contentmoderatiesystemen gebruiken embeddings om schadelijke content te detecteren door gebruikersposts te vergelijken met embeddings van bekende beleidsinbreuken, terwijl vraag-en-antwoord-systemen gebruikersvragen koppelen aan relevante kennisartikelen door semantisch vergelijkbare content te vinden. Personalisatie-engines gebruiken embeddings om gebruikersvoorkeuren te begrijpen en ervaringen op maat te maken, en anomaliedetectiesystemen herkennen ongebruikelijke patronen door te signaleren wanneer nieuwe datapunten ver van verwachte embeddingclusters liggen. Bij AmICited zetten we embeddings in om te monitoren hoe AI-systemen op het internet worden gebruikt, door gebruikersvragen en content te matchen en zo te traceren waar AI-gegenereerde of AI-geassisteerde content verschijnt. Zo helpen we merken hun AI-voetafdruk te begrijpen en zorgen we voor correcte toeschrijving.
Effectieve implementatie van embeddings vraagt om aandacht voor diverse technische factoren die zowel prestaties als kosten beïnvloeden. Modelkeuze is cruciaal—je moet de semantische kwaliteit van embeddings afwegen tegen de benodigde rekenkracht, waarbij grotere modellen als BERT rijkere representaties leveren maar meer processing vereisen dan lichtere alternatieven. Dimensionaliteit vormt een belangrijke afweging: embeddings met meer dimensies vangen meer nuance, maar verbruiken meer geheugen en vertragen gelijkenisberekeningen, terwijl embeddings met minder dimensies sneller zijn maar mogelijk belangrijke semantiek missen. Voor efficiënte matching op grote schaal gebruiken systemen gespecialiseerde indexeringsstrategieën zoals FAISS (Facebook AI Similarity Search) of Annoy (Approximate Nearest Neighbors Oh Yeah), waarmee vergelijkbare embeddings in milliseconden gevonden worden door vectoren te organiseren in boomstructuren of via locality-sensitive hashing. Fijn-afstemmen van embeddingmodellen op domeinspecifieke data kan de relevantie voor specialistische toepassingen sterk verbeteren, maar vereist gelabelde trainingsdata en extra rekenkracht. Organisaties moeten voortdurend een balans vinden tussen snelheid en nauwkeurigheid, computationele kosten en semantische kwaliteit, en generieke modellen versus gespecialiseerde alternatieven, afhankelijk van hun gebruiksscenario’s en beperkingen.
De toekomst van embeddings beweegt richting meer verfijning, efficiëntie en integratie met bredere AI-systemen, wat nog krachtigere contentmatching en -begrip mogelijk maakt. Multimodale embeddings die tegelijkertijd tekst, afbeeldingen en audio verwerken zijn in opkomst, waardoor systemen over verschillende contenttypes heen kunnen matchen—bijvoorbeeld afbeeldingen vinden bij tekstvragen—en zo compleet nieuwe mogelijkheden voor contentontdekking en begrip openen. Onderzoekers ontwikkelen steeds efficiëntere embeddingmodellen die vergelijkbare semantische kwaliteit leveren met veel minder parameters, zodat geavanceerde AI-mogelijkheden ook voor kleinere organisaties en edge-apparaten binnen handbereik komen. De integratie van embeddings met grote taalmodellen levert systemen op die niet alleen content semantisch kunnen koppelen, maar ook context, nuance en intentie op ongekende niveaus begrijpen. Naarmate AI-systemen steeds verder doordringen in het internet, wordt het steeds belangrijker om te kunnen traceren, monitoren en begrijpen hoe content wordt gekoppeld en gebruikt—hierbij zetten platforms als AmICited embeddings in om organisaties te helpen hun merkzichtbaarheid te monitoren, AI-gebruikspatronen te volgen en te zorgen dat hun content correct wordt toegeschreven en verantwoord wordt gebruikt. De convergentie van betere embeddings, efficiëntere modellen en geavanceerde monitoringtools creëert een toekomst waarin AI-systemen transparanter, beter te verantwoorden en meer in lijn met menselijke waarden zijn.
Een vector-embedding is een numerieke representatie van data (tekst, afbeeldingen, audio) in een hoog-dimensionale ruimte die semantische betekenis en relaties vastlegt. Het zet abstracte data om in reeksen getallen die machines wiskundig kunnen verwerken en analyseren.
Embeddings zetten abstracte data om in getallen die machines kunnen verwerken, waardoor AI patronen, overeenkomsten en relaties tussen verschillende stukken content kan herkennen. Deze wiskundige representatie stelt AI-systemen in staat betekenis te begrijpen in plaats van alleen maar op trefwoorden te matchen.
Trefwoordmatching zoekt naar exacte woordovereenkomsten, terwijl semantische gelijkenis de betekenis begrijpt. Hierdoor kunnen systemen gerelateerde content vinden zonder identieke woorden—bijvoorbeeld 'automobiel' koppelen aan 'auto' op basis van semantische relatie in plaats van exacte tekstovereenkomst.
Ja, embeddings kunnen tekst, afbeeldingen, audio, gebruikersprofielen, producten en meer representeren. Verschillende embeddingmodellen zijn geoptimaliseerd voor verschillende datatypes, van Word2Vec voor tekst tot CNN's voor beelden tot spectrogrammen voor audio.
AmICited gebruikt embeddings om te begrijpen hoe AI-systemen jouw merk semantisch koppelen en vermelden op verschillende AI-platforms en in reacties. Dit helpt bij het volgen van de aanwezigheid van jouw content in AI-gegenereerde antwoorden en zorgt voor juiste toeschrijving.
Belangrijke uitdagingen zijn het kiezen van het juiste model, het beheersen van computatiekosten, omgaan met hoog-dimensionale data, fijn afstemmen op specifieke domeinen en het balanceren van snelheid versus nauwkeurigheid in gelijkenisberekeningen.
Embeddings maken semantisch zoeken mogelijk, waarbij gebruikersintentie wordt begrepen en relevante resultaten op basis van betekenis worden getoond in plaats van alleen maar op trefwoorden. Hierdoor kunnen zoeksystemen content vinden die conceptueel gerelateerd is, zelfs als deze niet exact de zoektermen bevat.
Grote taalmodellen gebruiken intern embeddings om tekst te begrijpen en te genereren. Embeddings zijn fundamenteel voor hoe deze modellen informatie verwerken, content koppelen en contextueel passende antwoorden genereren.
Vector-embeddings drijven AI-systemen aan zoals ChatGPT, Perplexity en Google AI Overviews. AmICited volgt hoe deze systemen jouw content citeren en refereren, zodat jij inzicht krijgt in de aanwezigheid van jouw merk in AI-gegenereerde antwoorden.
Leer hoe embeddings werken in AI-zoekmachines en taalmodellen. Begrijp vectorrepresentaties, semantisch zoeken en hun rol in AI-gegenereerde antwoorden.

Leer wat embeddings zijn, hoe ze werken en waarom ze essentieel zijn voor AI-systemen. Ontdek hoe tekst wordt omgezet in numerieke vectoren die semantische bete...

Vector search maakt gebruik van wiskundige vectorrepresentaties om vergelijkbare data te vinden door semantische relaties te meten. Leer hoe embeddings, afstand...
Cookie Toestemming
We gebruiken cookies om uw browse-ervaring te verbeteren en ons verkeer te analyseren. See our privacy policy.