
Geciteerd worden in Wikipedia-artikelen: een niet-manipulatieve aanpak
Leer ethische strategieën om je merk op Wikipedia vermeld te krijgen. Begrijp Wikipedia's inhoudsbeleid, betrouwbare bronnen en hoe je citaties kunt benutten vo...
13 min lezen

Ontdek hoe Wikipedia-citaties AI-trainingsdata vormen en een rimpel-effect veroorzaken in LLM’s. Leer waarom jouw Wikipedia-aanwezigheid belangrijk is voor AI-vermeldingen en merkperceptie.
Wikipedia is uitgegroeid tot de fundamentele trainingsdataset voor vrijwel elk groot taalmodel dat vandaag de dag bestaat—van OpenAI’s ChatGPT en Google’s Gemini tot Anthropic’s Claude en Perplexity’s zoekmachine. In veel gevallen vormt Wikipedia de grootste bron van gestructureerde, hoogwaardige tekst in de trainingsdatasets van deze AI-systemen, vaak goed voor 5-15% van het totale trainingscorpus, afhankelijk van het model. Deze dominantie komt voort uit de unieke kenmerken van Wikipedia: het neutraliteitbeleid, grondige community-gedreven factchecking, gestructureerde opmaak en vrije licenties maken het een ongeëvenaarde bron om AI-systemen te leren redeneren, bronnen te citeren en accuraat te communiceren. Toch heeft deze relatie Wikipedia’s rol in het digitale ecosysteem fundamenteel veranderd—het is niet langer alleen een bestemming voor menselijke lezers die informatie zoeken, maar eerder de onzichtbare ruggengraat achter de conversatie-AI waarmee miljoenen dagelijks interacteren. Dit inzicht onthult een cruciaal rimpel-effect: de kwaliteit, bias en hiaten op Wikipedia bepalen direct de mogelijkheden en beperkingen van de AI-systemen die nu bemiddelen hoe miljarden mensen informatie vinden en begrijpen.

Wanneer grote taalmodellen informatie verwerken tijdens training, behandelen ze niet alle bronnen gelijk—Wikipedia neemt een uniek bevoorrechte positie in in hun besluitvorming. Tijdens het entiteitsherkenningsproces identificeren LLM’s belangrijke feiten en concepten, om deze vervolgens te controleren aan de hand van meerdere bronnen om geloofwaardigheidsscores vast te stellen. Wikipedia fungeert hierin als een “primaire autoriteitscontrole” vanwege de transparante bewerkingsgeschiedenis, community-verificatie en het neutraliteitbeleid, die samen betrouwbaarheid signaaleren aan AI-systemen. Het geloofwaardigheidsmultiplicator-effect versterkt dit voordeel: wanneer informatie consequent voorkomt op Wikipedia, gestructureerde kennisgrafieken zoals Google Knowledge Graph en Wikidata, en academische bronnen, kennen LLM’s exponentieel meer vertrouwen toe aan die informatie. Dit wegingssysteem verklaart waarom Wikipedia een speciale behandeling krijgt in training—het fungeert zowel als directe kennisbron als validatielaag voor feiten uit andere bronnen. Het resultaat is dat LLM’s Wikipedia niet als een van de vele datapunten behandelen, maar als een fundamenteel naslagwerk dat andere, minder gecontroleerde bronnen bevestigt of in twijfel trekt.
| Type bron | Geloofwaardigheid | Reden | AI-behandeling |
|---|---|---|---|
| Wikipedia | Zeer hoog | Neutraal, bewerkt door community, geverifieerd | Primaire referentie |
| Bedrijfswebsite | Gemiddeld | Zelfpromotie | Secundaire bron |
| Nieuwsartikelen | Hoog | Extern, maar mogelijk biased | Corroberende bron |
| Kennisgrafieken | Zeer hoog | Gestructureerd, geaggregeerd | Autoriteitsversterker |
| Sociale media | Laag | Ongecontroleerd, promotioneel | Minimale weging |
| Academische bronnen | Zeer hoog | Peer-reviewed, gezaghebbend | Hoog vertrouwen |
Wanneer een nieuwsorganisatie Wikipedia als bron citeert, ontstaat er wat wij de “citatieketen” noemen—een cascade waarbij geloofwaardigheid zich opstapelt via meerdere informatielagen. Een journalist die over klimaatwetenschap schrijft, kan een Wikipedia-artikel over opwarming van de aarde aanhalen, dat zelf weer peer-reviewed studies citeert; dat nieuwsartikel wordt vervolgens geïndexeerd door zoekmachines en opgenomen in kennisgrafieken, die daarna grote taalmodellen trainen die miljoenen gebruikers dagelijks bevragen. Zo ontstaat een krachtige feedbacklus: Wikipedia → Kennisgrafiek → LLM → Gebruiker, waarbij de framing en nadruk van het oorspronkelijke Wikipedia-artikel subtiel bepaalt hoe AI-systemen informatie presenteren aan eindgebruikers—vaak zonder dat gebruikers beseffen dat die informatie terug te voeren is op een crowdsourced encyclopedie. Stel u een concreet voorbeeld voor: als het Wikipedia-artikel over een farmaceutische behandeling bepaalde klinische studies benadrukt en andere onderbelicht, dan werkt die redactionele keuze door in nieuwsberichten, nestelt zich in kennisgrafieken, en beïnvloedt uiteindelijk hoe ChatGPT of vergelijkbare modellen patiëntvragen over behandelingen beantwoorden. Dit “rimpel-effect” betekent dat Wikipedia-beslissingen niet alleen invloed hebben op directe lezers, maar het gehele informatielandschap vormen dat AI-systemen aanleren en teruggeven aan miljarden gebruikers. De citatieketen maakt van Wikipedia feitelijk geen eindbestemming meer, maar een onzichtbare maar invloedrijke laag in de AI-trainingspipeline, waarbij nauwkeurigheid en bias aan de bron zich kunnen versterken in het hele ecosysteem.
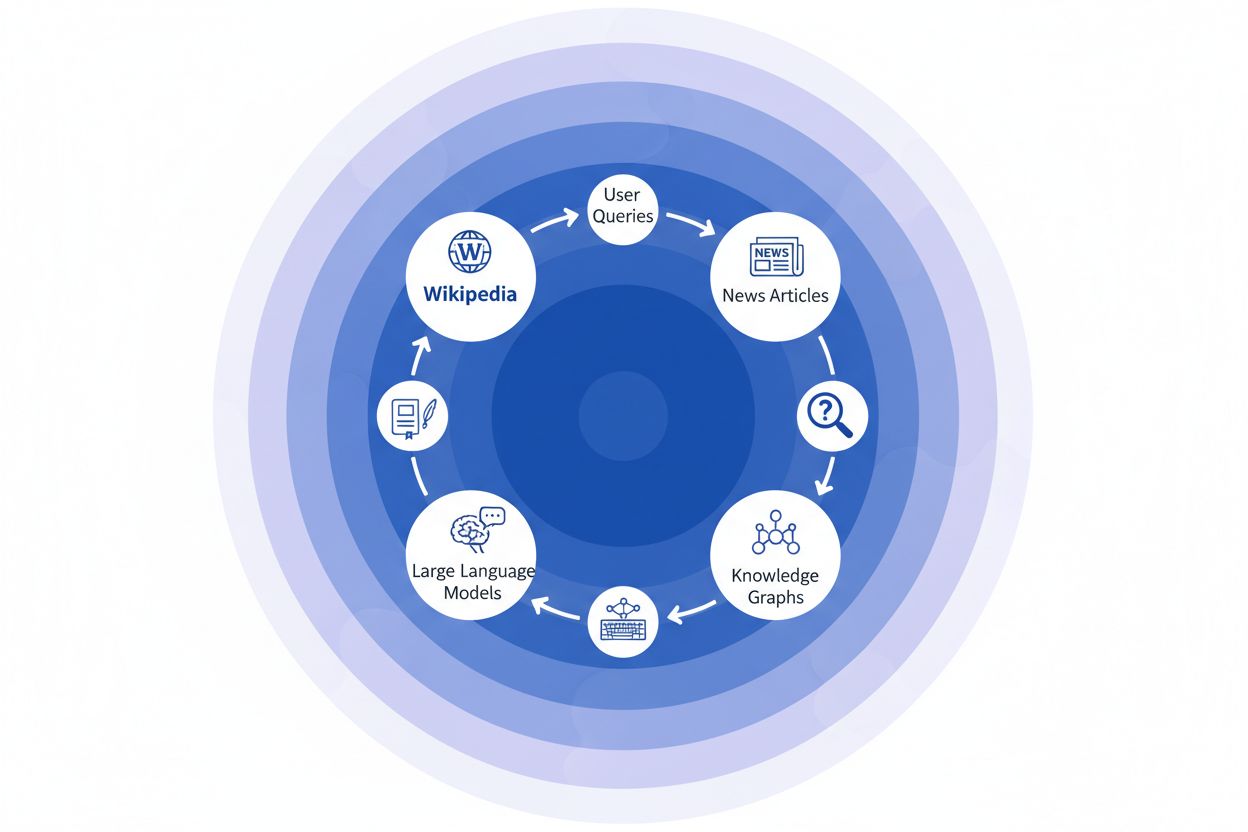
Het rimpel-effect in het Wikipedia-naar-AI-ecosysteem is misschien wel de belangrijkste dynamiek voor merken en organisaties om te begrijpen. Een enkele Wikipedia-bewerking verandert niet alleen één bron—het rolt door een onderling verbonden netwerk van AI-systemen, die elk deze informatie benutten en versterken op manieren die de impact exponentieel vergroten. Wanneer er een onjuistheid op een Wikipedia-pagina verschijnt, blijft die niet geïsoleerd; in plaats daarvan verspreidt deze zich door het hele AI-landschap en bepaalt hoe uw merk dagelijks wordt beschreven, begrepen en gepresenteerd aan miljoenen gebruikers. Dit multiplicatoreffect betekent dat investeren in Wikipedia-nauwkeurigheid niet alleen om één platform draait—het gaat om regie over uw narratief in het hele generatieve AI-ecosysteem. Voor digitale PR- en merkmanagers verandert deze realiteit fundamenteel waar tijd en middelen op gericht moeten worden.
Belangrijke rimpel-effecten om te monitoren:
Recent onderzoek van de IUP-studie door Vetter et al. heeft een kritieke kwetsbaarheid in onze AI-infrastructuur blootgelegd: de duurzaamheid van Wikipedia als trainingsbron wordt steeds meer bedreigd door de technologie die zij mede aandrijft. Naarmate grote taalmodellen zich verspreiden en worden getraind op steeds grotere datasets vol LLM-gegenereerde content, ontstaat het groeiende probleem van “model collapse”, waarbij kunstmatige output de trainingsdatabronnen vervuilt en de modelkwaliteit over generaties heen afneemt. Dit fenomeen is extra prangend omdat Wikipedia—een encyclopedie gebouwd op menselijke expertise en vrijwilligerswerk—een fundamentele pijler is geworden voor de training van geavanceerde AI-systemen, vaak zonder expliciete naamsvermelding of compensatie voor de bijdragers. De ethische implicaties zijn diepgaand: terwijl AI-bedrijven waarde onttrekken aan Wikipedia’s vrij gedeelde kennis en tegelijk het informatielandschap overspoelen met synthetische content, komen de prikkels die de vrijwilligersgemeenschap van Wikipedia al meer dan twintig jaar draaiende houden, onder ongekende druk te staan. Zonder doelgerichte maatregelen om door mensen gegenereerde inhoud als afzonderlijke, beschermde bron te behouden, riskeren we een feedbacklus waarin AI-gegenereerde tekst geleidelijk authentieke menselijke kennis verdringt—en daarmee de basis ondermijnt waarop moderne taalmodellen gebouwd zijn. De duurzaamheid van Wikipedia is daarom niet alleen een zorg voor de encyclopedie zelf, maar een cruciale kwestie voor het hele informatie-ecosysteem en de toekomstige levensvatbaarheid van AI-systemen die afhankelijk zijn van authentieke menselijke kennis.
Nu AI-systemen steeds meer vertrouwen op Wikipedia als fundamentele kennisbron, is het voor moderne organisaties essentieel om te monitoren hoe uw merk in deze AI-gegenereerde antwoorden verschijnt. AmICited.com is gespecialiseerd in het volgen van Wikipedia-citaties terwijl deze door AI-systemen vloeien, en biedt merken inzicht in hoe hun Wikipedia-aanwezigheid zich vertaalt naar AI-vermeldingen en aanbevelingen. Waar alternatieven zoals FlowHunt.io algemene webmonitoring bieden, richt AmICited zich specifiek op de Wikipedia-naar-AI-citatieketen en legt het precies vast wanneer AI-systemen uw Wikipedia-vermelding gebruiken en hoe dit hun antwoorden beïnvloedt. Dit inzicht is cruciaal, want Wikipedia-citaties wegen zwaar in AI-trainingsdata en het genereren van antwoorden—een goed onderhouden Wikipedia-aanwezigheid informeert niet alleen menselijke lezers, maar vormt hoe AI-systemen uw merk waarnemen en presenteren aan miljoenen gebruikers. Door uw Wikipedia-vermeldingen via AmICited te monitoren, krijgt u bruikbare inzichten in uw AI-footprint, zodat u uw Wikipedia-aanwezigheid gericht kunt optimaliseren met volledig zicht op het effect stroomafwaarts op AI-ontdekking en merkperceptie.
Ja, elke grote LLM, waaronder ChatGPT, Gemini, Claude en Perplexity, bevat Wikipedia in zijn trainingsdata. Wikipedia is vaak de grootste bron van gestructureerde, geverifieerde informatie in LLM-trainingsdatasets en vormt doorgaans 5-15% van het totale trainingscorpus.
Wikipedia fungeert als geloofwaardigheidscontrolepunt voor AI-systemen. Wanneer een LLM informatie over uw merk genereert, wordt Wikipedia's beschrijving zwaarder gewogen dan andere bronnen, waardoor uw Wikipedia-pagina een kritieke invloed heeft op hoe AI-systemen u weergeven in ChatGPT, Gemini, Claude en andere platforms.
Het rimpel-effect verwijst naar hoe een enkele Wikipedia-citaat of bewerking gevolgen stroomafwaarts creëert in het hele AI-ecosysteem. Eén Wikipedia-wijziging kan invloed hebben op kennisgrafieken, die AI-overzichten beïnvloeden, wat weer bepaalt hoe meerdere AI-systemen uw merk beschrijven aan miljoenen gebruikers.
Ja. Omdat LLM's Wikipedia als zeer geloofwaardig beschouwen, zal onjuiste informatie op uw Wikipedia-pagina zich verspreiden via AI-systemen. Dit kan van invloed zijn op hoe ChatGPT, Gemini en andere AI-platforms uw organisatie beschrijven en mogelijk uw merkperceptie schaden.
Tools zoals AmICited.com volgen hoe uw merk wordt geciteerd en genoemd in AI-systemen zoals ChatGPT, Perplexity en Google AI Overviews. Dit helpt u het rimpel-effect van uw Wikipedia-aanwezigheid te begrijpen en hierop te optimaliseren.
Wikipedia heeft strikte regels tegen zelfpromotie. Elke bewerking moet voldoen aan de richtlijnen van Wikipedia en gebaseerd zijn op betrouwbare, externe bronnen. Veel organisaties werken samen met Wikipedia-specialisten om naleving te waarborgen en toch een accurate aanwezigheid te behouden.
LLM's worden getraind op momentopnames van data, dus wijzigingen hebben tijd nodig om door te werken. Kennisgrafieken worden echter vaker bijgewerkt, dus het rimpel-effect kan binnen enkele weken tot maanden beginnen, afhankelijk van het AI-systeem en het hertrainingsmoment.
Wikipedia is een primaire bron die direct wordt gebruikt in LLM-training. Kennisgrafieken zoals Google's Knowledge Graph verzamelen informatie uit meerdere bronnen, waaronder Wikipedia, en leveren die aan AI-systemen, waardoor er een extra laag van invloed ontstaat op hoe AI-systemen informatie begrijpen en presenteren.
Volg hoe Wikipedia-citaties doorwerken in ChatGPT, Gemini, Claude en andere AI-systemen. Begrijp uw AI-footprint en optimaliseer uw Wikipedia-aanwezigheid met AmICited.
Leer ethische strategieën om je merk op Wikipedia vermeld te krijgen. Begrijp Wikipedia's inhoudsbeleid, betrouwbare bronnen en hoe je citaties kunt benutten vo...

Ontdek hoe Wikipedia dient als een cruciale AI-trainingsdataset, de impact op modelnauwkeurigheid, licentieovereenkomsten en waarom AI-bedrijven ervan afhankeli...
Ontdek hoe Wikipedia AI-verwijzingen beïnvloedt in ChatGPT, Perplexity en Google AI. Leer waarom Wikipedia de meest vertrouwde bron is voor AI-training en hoe d...
Cookie Toestemming
We gebruiken cookies om uw browse-ervaring te verbeteren en ons verkeer te analyseren. See our privacy policy.