AI-misinformatiecorrectie
Leer hoe u onjuiste merkinformatie identificeert en corrigeert in AI-systemen zoals ChatGPT, Gemini en Perplexity. Ontdek monitoringtools, bron-niveau correctie...
8 min lezen

Leer hoe u correcties kunt aanvragen bij AI-platforms zoals ChatGPT, Perplexity en Claude. Begrijp correctiemechanismen, feedbackprocessen en strategieën om AI-gegenereerde antwoorden over uw merk te beïnvloeden.
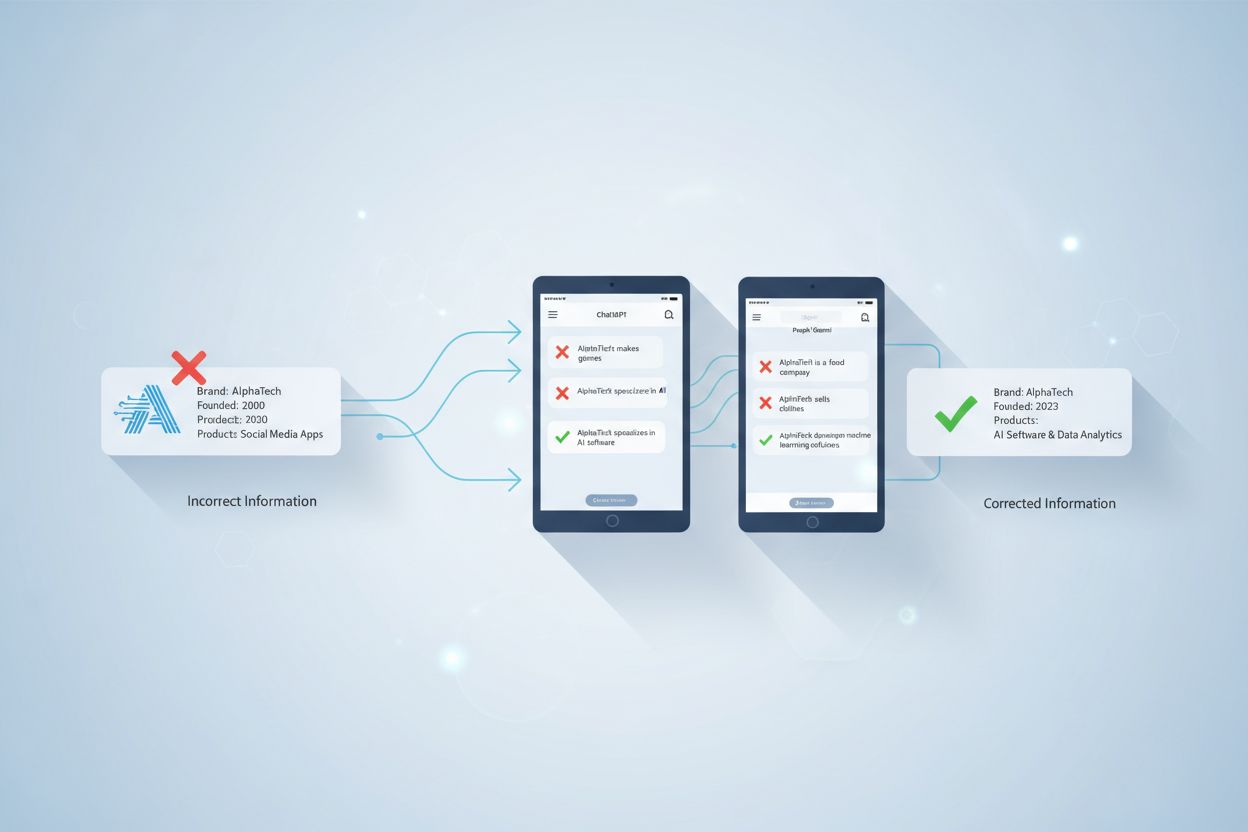
Hoewel u niet direct informatie uit AI-trainingsdata kunt verwijderen, kunt u correcties aanvragen via feedbackmechanismen, onnauwkeurigheden bij de bron aanpakken en toekomstige AI-antwoorden beïnvloeden door gezaghebbende positieve content te creëren en samen te werken met ondersteuningsteams van het platform.
Correcties aanvragen bij AI-platforms vereist inzicht in hoe deze systemen fundamenteel werken. In tegenstelling tot traditionele zoekmachines, waarbij u contact kunt opnemen met een website-eigenaar om content te verwijderen of bij te werken, leren AI-taalmodellen van trainingsdata tijdens specifieke trainingsfasen, waarin miljarden webpagina’s, nieuwsartikelen en tekstbronnen worden verwerkt. Zodra negatieve of onnauwkeurige informatie deel uitmaakt van deze trainingsdata, kunt u deze niet direct verwijderen of bewerken zoals bij een website-eigenaar. De AI heeft tijdens zijn trainingscyclus al patronen en associaties uit meerdere bronnen geleerd.
Het correctieproces verschilt aanzienlijk tussen statische en realtime AI-systemen. Statische modellen zoals GPT-4 zijn getraind op data tot een specifieke afkapdatum (bijvoorbeeld december 2023 voor GPT-4-turbo), en zodra ze getraind zijn, behouden ze die kennis tot de volgende trainingscyclus. Realtime AI-systemen zoals Perplexity en Claude.ai halen live webcontent op, waardoor correcties bij de bron direct effect kunnen hebben op hun antwoorden. Begrijpen met welk type AI-platform u te maken heeft, is cruciaal voor het bepalen van de meest effectieve correctiestrategie.
De meeste grote AI-platforms bieden ingebouwde feedbackmechanismen waarmee gebruikers onnauwkeurigheden kunnen melden. ChatGPT bevat bijvoorbeeld duim-omhoog en duim-omlaag knoppen bij antwoorden, waarmee gebruikers problematische antwoorden kunnen markeren. Wanneer u negatieve feedback geeft op een onnauwkeurig antwoord, wordt deze informatie verzameld en geanalyseerd door het platformteam. Deze feedbackloops helpen AI-systemen hun prestaties te verfijnen door te leren van zowel succesvolle als foutieve uitkomsten. De feedback die u indient, wordt onderdeel van de data die ontwikkelaars gebruiken om patronen in fouten te identificeren en de nauwkeurigheid van het model te verbeteren.
Perplexity en Claude bieden vergelijkbare feedbackopties binnen hun interfaces. U kunt doorgaans aangeven wanneer een antwoord onnauwkeurig, misleidend of verouderde informatie bevat. Sommige platforms stellen u in staat specifieke correcties of verduidelijkingen te geven. De effectiviteit van deze feedback hangt af van hoeveel gebruikers hetzelfde probleem melden en hoe significant de onnauwkeurigheid is. Platforms geven prioriteit aan correcties voor wijdverspreide problemen die veel gebruikers treffen. Dus als meerdere mensen dezelfde onnauwkeurigheid over uw merk melden, is de kans groter dat het platform dit onderzoekt en aanpakt.
De meest effectieve langetermijnstrategie voor het corrigeren van AI-gegenereerde desinformatie is het aanpakken van de oorspronkelijke bron van de onnauwkeurige informatie. Omdat AI-systemen leren van webcontent, nieuwsartikelen, Wikipedia-pagina’s en andere gepubliceerde materialen, beïnvloedt correctie van informatie bij deze bronnen hoe AI-platforms in toekomstige trainingscycli informatie presenteren. Vraag correcties of updates aan bij de oorspronkelijke uitgevers waar de onnauwkeurige informatie verschijnt. Als een nieuwsmedium onjuiste informatie over uw merk heeft gepubliceerd, neem dan contact op met de redactie met bewijs van de onjuistheid en vraag om een correctie of verduidelijking.
Wikipedia is een bijzonder belangrijke bron voor AI-trainingsdata. Als onnauwkeurige informatie over uw merk of domein op Wikipedia staat, werk dan via de juiste redactionele kanalen van het platform om dit aan te pakken. Wikipedia heeft specifieke processen voor het betwisten van informatie en het aanvragen van correcties, waarbij u hun neutraliteits- en verifieerbaarheidsrichtlijnen moet volgen. Bronnen met een hoge autoriteit, zoals Wikipedia, grote nieuwsorganisaties, onderwijsinstellingen en overheidswebsites, wegen zwaar in AI-trainingsdatasets. Correcties die bij deze bronnen worden doorgevoerd, worden waarschijnlijker opgenomen in toekomstige updates van AI-modellen.
Voor verouderde of onnauwkeurige informatie op uw eigen website of beheerde platforms, zorg dat u deze snel bijwerkt of verwijdert. Documenteer alle wijzigingen die u doorvoert, omdat deze updates kunnen worden meegenomen in toekomstige retrainingscycli. Wanneer u informatie op uw eigen domein corrigeert, levert u AI-systemen feitelijk nauwkeuriger bronmateriaal om in de toekomst van te leren.
In plaats van u uitsluitend te richten op het verwijderen van negatieve of onnauwkeurige informatie, ontwikkel sterke tegen-narratieven met gezaghebbende positieve content. AI-modellen wegen informatie deels op basis van frequentie- en autoriteitspatronen in hun trainingsdata. Als u aanzienlijk meer positieve, nauwkeurige en gezaghebbende content creëert dan er onnauwkeurige informatie bestaat, zal de AI bij het samenstellen van antwoorden over uw merk veel meer positieve informatie tegenkomen.
| Contenttype | Autoriteitsniveau | Impact op AI | Tijdlijn |
|---|---|---|---|
| Professionele biografiepagina’s | Hoog | Directe invloed op antwoorden | Weken tot maanden |
| Branchepublicaties & thought leadership | Zeer hoog | Sterke weging in AI-antwoorden | Maanden |
| Persberichten via grote wire services | Hoog | Significante invloed op narratieven | Weken tot maanden |
| Case studies en succesverhalen | Midden-hoog | Contextuele ondersteuning voor positieve claims | Maanden |
| Academische of onderzoeks-publicaties | Zeer hoog | Langdurige invloed in trainingsdata | Maanden tot jaren |
| Wikipedia-pagina’s | Zeer hoog | Cruciaal voor toekomstige AI-trainingscycli | Maanden tot jaren |
Ontwikkel uitgebreide content op meerdere geloofwaardige platforms om te garanderen dat AI-systemen gezaghebbende positieve informatie tegenkomen. Deze content-saturatie-aanpak is bijzonder effectief omdat het de kernoorzaak van AI-desinformatie aanpakt: een tekort aan positieve informatie om onnauwkeurige beweringen te compenseren. Wanneer AI-systemen toegang hebben tot meer positieve, goed onderbouwde informatie uit gezaghebbende bronnen, genereren ze vanzelf positievere antwoorden over uw merk.
Verschillende AI-platforms hebben verschillende architecturen en updatecycli, wat aangepaste correctiebenaderingen vereist. ChatGPT en andere GPT-gebaseerde systemen richten zich op platforms die vóór trainingsafkap zijn opgenomen: grote nieuwssites, Wikipedia, professionele directories en breed geciteerde webcontent. Omdat deze modellen niet realtime updaten, beïnvloeden correcties die u vandaag aanbrengt toekomstige trainingscycli, meestal 12-18 maanden later. Perplexity en realtime AI-zoeksystemen integreren live webcontent, dus een sterke SEO en voortdurende perszichtbaarheid hebben direct effect. Wanneer u content van het live web verwijdert of corrigeert, stopt Perplexity doorgaans binnen enkele dagen tot weken met het refereren eraan.
Claude en Anthropic-systemen geven prioriteit aan feitelijke, goed onderbouwde informatie. Anthropic legt de nadruk op feitelijke betrouwbaarheid, dus zorg dat positieve content over uw merk verifieerbaar is en gekoppeld aan betrouwbare bronnen. Wanneer u correcties aanvraagt bij Claude, focus dan op het verstrekken van op bewijs gebaseerde verduidelijkingen en verwijs naar gezaghebbende bronnen die de juiste informatie ondersteunen. De kern is dat elk platform verschillende databronnen, updatefrequenties en kwaliteitsnormen heeft. Pas uw correctiestrategie hierop aan.
Regelmatig testen hoe AI-systemen uw naam of merk omschrijven is essentieel om de effectiviteit van correcties te volgen. Stel vragen aan ChatGPT, Claude, Perplexity en andere platforms met zowel positieve als negatieve bewoordingen (bijvoorbeeld “Is [merk] betrouwbaar?” versus “[merk] prestaties”). Noteer resultaten in de tijd en volg de voortgang om onnauwkeurigheden te identificeren en te meten of uw correctie-inspanningen het narratief veranderen. Deze monitoring stelt u in staat nieuwe onnauwkeurigheden snel te signaleren en te reageren. Als u merkt dat een AI-platform nog steeds verouderde of foutieve informatie noemt weken nadat u de bron heeft gecorrigeerd, kunt u het probleem escaleren via de supportkanalen van het platform.
Documenteer alle correcties die u aanvraagt en de reacties die u ontvangt. Deze documentatie dient meerdere doelen: het levert bewijs als u zaken moet escaleren, het helpt patronen te identificeren in hoe verschillende platforms correcties behandelen, en het toont uw inspanningen om juiste informatie te waarborgen. Houd bij wanneer u feedback heeft ingediend, welke onnauwkeurigheid u heeft gemeld en eventuele reacties van het platform.
Volledige verwijdering van onnauwkeurige informatie uit AI-zoekresultaten is zelden mogelijk, maar verdunning en contextopbouw zijn haalbare doelen. De meeste AI-bedrijven werken trainingsdata periodiek bij, doorgaans elke 12-18 maanden voor grote taalmodellen. Acties die u nu onderneemt, beïnvloeden toekomstige iteraties, maar u moet rekening houden met een aanzienlijke tijdsvertraging tussen het aanvragen van een correctie en het verschijnen ervan in AI-gegenereerde antwoorden. Succes vereist geduld en consistentie. Door te focussen op gezaghebbende contentcreatie, onnauwkeurigheden bij de bron aan te pakken en geloofwaardigheid op te bouwen, kunt u sturen hoe AI-platforms uw merk op termijn presenteren.
Realtime AI-zoekplatforms zoals Perplexity kunnen binnen weken of maanden resultaten tonen, terwijl statische modellen zoals ChatGPT 12-18 maanden kunnen duren voordat correcties worden verwerkt in het basismodel. Echter, zelfs bij statische modellen kunt u sneller verbeteringen zien als het platform bijgewerkte versies uitbrengt of specifieke onderdelen van het model bijstelt. De tijdslijn hangt ook af van hoe wijdverspreid de onnauwkeurigheid is en hoeveel gebruikers deze melden. Wijdverspreide onnauwkeurigheden die veel gebruikers treffen, krijgen sneller aandacht dan problemen die slechts enkelen raken.
In sommige rechtsgebieden heeft u juridische middelen voor onnauwkeurige of lasterlijke informatie. Als een AI-platform valse, lasterlijke of schadelijke informatie over uw merk genereert, heeft u mogelijk juridische gronden om actie te ondernemen. Wetten rond het recht om vergeten te worden in relevante rechtsgebieden, met name onder de AVG in Europa, bieden extra opties. Deze wetten stellen u in staat om verwijdering van bepaalde persoonlijke informatie uit zoekresultaten en in sommige gevallen uit AI-trainingsdata aan te vragen.
Neem contact op met het juridische team van het AI-platform als u denkt dat de informatie hun servicevoorwaarden of toepasselijke wetgeving schendt. De meeste platforms hebben processen voor het behandelen van juridische klachten en verwijderingsverzoeken. Lever duidelijk bewijs van de onnauwkeurigheid en leg uit waarom het de wet of het beleid van het platform schendt. Documenteer alle communicatie met het platform, zodat u een dossier heeft van uw inspanningen om het probleem op te lossen.
De meest duurzame manier om uw reputatie in AI-zoekopdrachten te beheren is negatieve informatie voorbijstreven met consistente, gezaghebbende positiviteit. Publiceer doorlopend deskundige content, onderhoud actieve professionele profielen, zorg voor regelmatige mediacoverage, bouw netwerken die prestaties versterken en benadruk maatschappelijke betrokkenheid. Deze langetermijnaanpak zorgt ervoor dat eventuele negatieve of onnauwkeurige berichtgeving verwatert tot een voetnoot in het bredere verhaal over uw merk.
Voer strategische SEO uit voor toekomstige AI-training door ervoor te zorgen dat gezaghebbende content hoog scoort in zoekmachines. Gebruik gestructureerde data markup en schema om context te verduidelijken, handhaaf consistente NAP-gegevens (naam, adres, telefoonnummer) en bouw hoogwaardige backlinks naar betrouwbare, positieve content. Deze inspanningen vergroten de kans dat positieve informatie het dominante verhaal wordt in toekomstige AI-hertrainingscycli. Naarmate AI-systemen geavanceerder en meer geïntegreerd in het dagelijks leven worden, zal het belang van accurate, gezaghebbende informatie op het web alleen maar toenemen. Investeer nu in uw digitale aanwezigheid om te zorgen dat AI-platforms jaren vooruit beschikken over juiste informatie over uw merk.
Houd bij hoe uw merk, domein en URL's verschijnen in ChatGPT, Perplexity en andere AI-zoekmachines. Ontvang meldingen wanneer correcties nodig zijn en meet het effect van uw inspanningen.
Leer hoe u onjuiste merkinformatie identificeert en corrigeert in AI-systemen zoals ChatGPT, Gemini en Perplexity. Ontdek monitoringtools, bron-niveau correctie...

Compleet overzicht van het afmelden voor AI-trainingsgegevensverzameling bij ChatGPT, Perplexity, LinkedIn en andere platforms. Leer stapsgewijze instructies om...

Ontdek realtime AI-aanpassing – de technologie waarmee AI-systemen continu leren van actuele gebeurtenissen en data. Verken hoe adaptieve AI werkt, de toepassin...
Cookie Toestemming
We gebruiken cookies om uw browse-ervaring te verbeteren en ons verkeer te analyseren. See our privacy policy.