Citatieselectie-algoritme
Leer hoe AI-systemen bepalen welke bronnen ze citeren versus parafraseren. Begrijp citatieselectie-algoritmen, biaspatronen en strategieën om de zichtbaarheid v...
6 min lezen

Leer hoe AI-modellen zoals ChatGPT, Perplexity en Gemini bronnen selecteren om te citeren. Begrijp de citaatmechanismen, rangschikkingsfactoren en optimalisatiestrategieën voor AI-zichtbaarheid.
AI-modellen beslissen wat ze moeten citeren via Retrieval-Augmented Generation (RAG), waarbij ze bronnen beoordelen op domeinautoriteit, actualiteit van de content, semantische relevantie, informatiestructuur en feitendichtheid. Het beslissingsproces vindt plaats in milliseconden door vector-similariteitsmatching en multi-factor beoordelingsalgoritmen die geloofwaardigheid, expertise-signalen en contentkwaliteit beoordelen.
AI-modellen selecteren niet willekeurig bronnen om te citeren in hun antwoorden. In plaats daarvan gebruiken ze geavanceerde algoritmen die honderden signalen in milliseconden beoordelen om te bepalen welke bronnen het vermelden waard zijn. Dit proces, bekend als Retrieval-Augmented Generation (RAG), verschilt fundamenteel van hoe traditionele zoekmachines content rangschikken. Waar het algoritme van Google zich richt op het rangschikken van pagina’s voor zichtbaarheid in zoekresultaten, geven AI-citaatalgoritmen prioriteit aan bronnen die de meest gezaghebbende, relevante en betrouwbare informatie bieden om specifieke gebruikersvragen te beantwoorden. Dit verschil betekent dat zichtbaarheid in door AI gegenereerde antwoorden een geheel andere set optimalisatieprincipes vereist dan traditionele SEO.
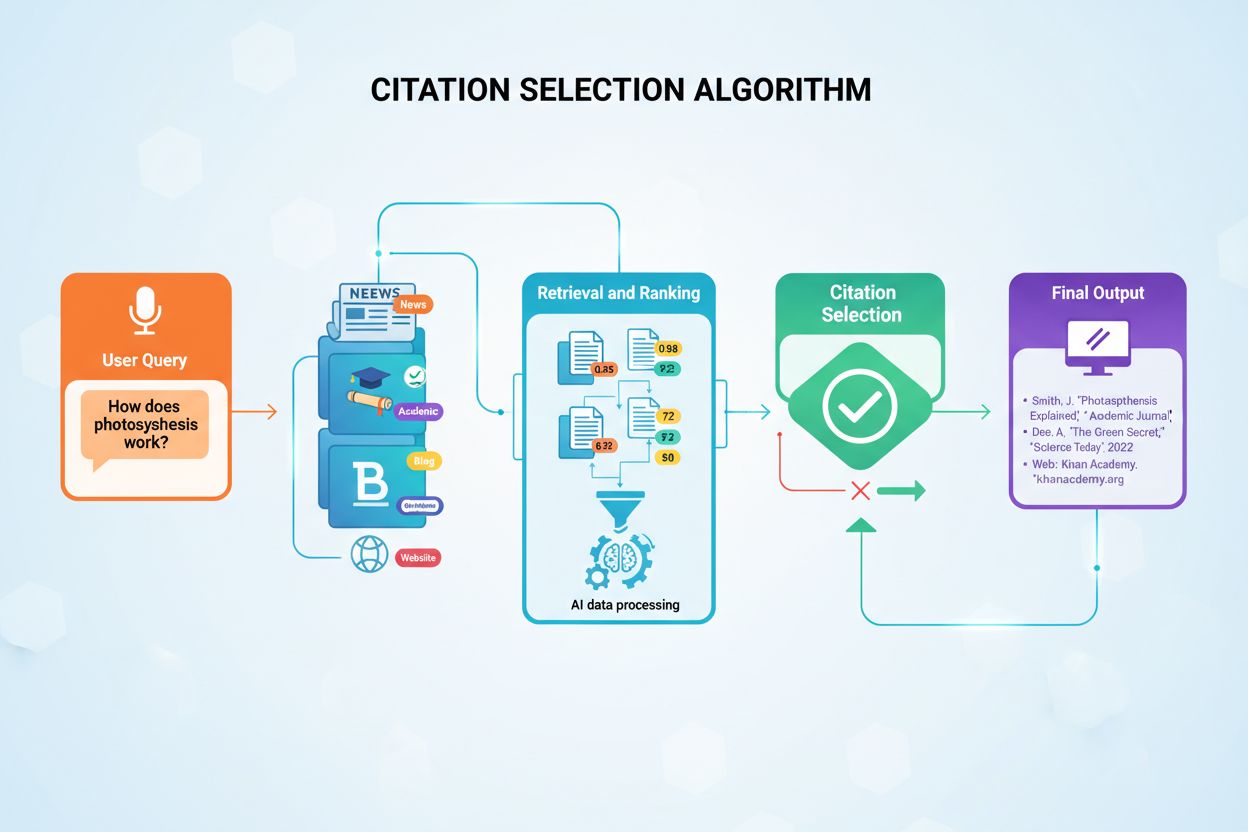
De citaatbeslissing vindt plaats via een meertrapsproces dat start zodra een gebruiker een vraag indient. Het AI-systeem zet de vraag van de gebruiker om in numerieke vectoren, zogenaamde embeddings, die de semantische betekenis van de vraag vertegenwoordigen. Deze embeddings zoeken vervolgens in geïndexeerde contentdatabases met miljoenen documenten naar semantisch vergelijkbare contentfragmenten. Het systeem haalt niet simpelweg de meest vergelijkbare content op; het past meerdere beoordelingscriteria tegelijk toe om potentiële bronnen te rangschikken op geschiktheid voor citatie. Dit parallelle beoordelingsproces zorgt ervoor dat de meest geloofwaardige, relevante en goed gestructureerde bronnen bovenaan de ranglijst belanden.
Retrieval-Augmented Generation (RAG) vormt de basisarchitectuur die AI-modellen überhaupt in staat stelt externe bronnen te citeren. In tegenstelling tot traditionele grote taalmodellen die uitsluitend vertrouwen op trainingsdata die tijdens hun ontwikkeling is gecodeerd, zoeken RAG-systemen actief in geïndexeerde documenten op het moment van de vraag en halen ze relevante informatie op voordat ze antwoorden genereren. Dit architecturale verschil verklaart waarom bepaalde platforms zoals Perplexity en Google AI Overviews consequent citaten geven, terwijl andere zoals het basis ChatGPT vaak antwoorden genereren zonder expliciete bronvermelding. Inzicht in RAG helpt te verklaren waarom sommige content wordt geciteerd terwijl even kwalitatieve content onzichtbaar blijft voor AI-systemen.
Het RAG-proces verloopt via vier verschillende fasen die bepalen welke bronnen uiteindelijk citaten ontvangen. Eerst worden documenten verdeeld in beheersbare fragmenten van 200-500 woorden, zodat AI-systemen specifieke, relevante informatie kunnen extraheren zonder complete artikelen te verwerken. Ten tweede worden deze fragmenten omgezet in numerieke vectoren (embeddings) met behulp van machine learning modellen die semantische betekenis begrijpen. Ten derde: wanneer een gebruiker een vraag stelt, zoekt het systeem naar semantisch vergelijkbare vectoren via vector-similariteitsmatching, waarmee content wordt geïdentificeerd die aansluit bij de kernconcepten van de vraag. Ten vierde genereert de AI een antwoord met de opgehaalde content als context, en de bronnen die het meest significant bijdragen aan het antwoord ontvangen de citaten. Deze architectuur verklaart waarom contentstructuur, duidelijkheid en semantische afstemming op veelvoorkomende vragen rechtstreeks invloed hebben op de kans op citatie.
AI-citaatalgoritmen beoordelen bronnen op vijf kernaspecten die gezamenlijk bepalen in hoeverre een bron het waard is om te worden geciteerd. Deze factoren werken samen om tot een algehele beoordeling van de bronkwaliteit te komen, waarbij elke dimensie bijdraagt aan de totale citaatscore.
| Citaatfactor | Invloedniveau | Belangrijkste indicatoren |
|---|---|---|
| Domeinautoriteit | Zeer Hoog (25-30%) | Backlinkprofiel, domeinleeftijd, aanwezigheid in kennisgrafiek, vermeldingen op Wikipedia |
| Contentactualiteit | Hoog (20-25%) | Publicatiedatum, updatefrequentie, versheid van statistieken en data |
| Semantische Relevantie | Hoog (20-25%) | Afstemming vraag-content, topicspecificiteit, aanwezigheid van direct antwoord |
| Informatiestructuur | Middel-Hoog (15-20%) | Koppenhiërarchie, scanbaar format, implementatie van schema markup |
| Feitendichtheid | Middel (10-15%) | Specifieke datapunten, statistieken, expertcitaten, citaatketens |
Autoriteit is de zwaarst meewegende factor bij AI-citaatbeslissingen. Onderzoek naar 150.000 AI-citaties toont aan dat Reddit en Wikipedia respectievelijk goed zijn voor 40,1% en 26,3% van alle LLM-citaties, wat aantoont hoe gevestigde autoriteit de selectie sterk beïnvloedt. AI-systemen beoordelen autoriteit op basis van meerdere vertrouwenssignalen, waaronder domeinleeftijd, kwaliteit van het backlinkprofiel, aanwezigheid in kennisgrafieken en validatie door derden. Websites met een domeinautoriteitsscore boven de 60 zien consequent hogere citatiepercentages bij ChatGPT, Perplexity en Gemini. Autoriteit draait echter niet alleen om domeinmetrics; ook auteursspecifieke geloofwaardigheid speelt mee, waarbij content met een naam van een expert met verifieerbare referenties voorkeur krijgt boven anonieme bijdragen.
Actualiteit fungeert als een kritische tijdsfilter die bepaalt of content nog in aanmerking komt voor citatie. Content die binnen 48-72 uur is gepubliceerd of geüpdatet, krijgt een voorkeursrangschikking, terwijl content direct begint te verouderen en de zichtbaarheid binnen 2-3 dagen meetbaar afneemt zonder updates. Deze actualiteitsvoorkeur weerspiegelt de inzet van AI-platforms om actuele informatie te bieden, vooral bij snel veranderende onderwerpen waar verouderde informatie gebruikers kan misleiden. Evergreen content met recente updates kan echter beter presteren dan nieuwe, oppervlakkige content, wat suggereert dat de combinatie van solide kwaliteit en actualiteit belangrijker is dan één van beide factoren apart. Organisaties die hun content elk kwartaal of jaarlijks herzien, behouden hogere citatiepercentages dan organisaties die eenmalig publiceren en daarna niets meer doen.
Relevantie meet de semantische overeenstemming tussen gebruikersvragen en documentinhoud. Bronnen die direct de kernvraag beantwoorden met minimale uitweidingen scoren hoger dan allesomvattende maar onsamenhangende bronnen. AI-systemen beoordelen relevantie via embedding-similariteit, waarbij de numerieke representatie van de vraag wordt vergeleken met die van contentfragmenten. Dit betekent dat content geschreven in gesprekstaal die aansluit bij natuurlijke zoekvragen beter presteert dan content die geoptimaliseerd is voor traditionele zoekwoorden. FAQ-achtige content en vraag-antwoordparen sluiten van nature aan op hoe AI-systemen vragen verwerken, waardoor dit format bijzonder geschikt is voor citatie.
Structuur omvat zowel informatiearchitectuur als technische implementatie. Een duidelijke hiërarchische opbouw met beschrijvende koppen, logische opbouw en scanbaar format helpt AI-systemen om contentgrenzen te herkennen en relevante informatie te extraheren. Gestructureerde gegevens via schema markup zoals FAQ-schema, Artikel-schema en Organisatie-schema kunnen de kans op citatie tot 10% verhogen. Content die is ingericht als beknopte samenvattingen, bullet-pointlijsten, vergelijkingstabellen en vraag-antwoordparen krijgt de voorkeur boven dichtgetikte paragrafen met verborgen inzichten. Deze structurele voorkeur weerspiegelt hoe AI-systemen getraind zijn om goed georganiseerde informatie te herkennen die volledige, contextuele antwoorden biedt.
Feitendichtheid verwijst naar de concentratie van specifieke, verifieerbare informatie in content. Bronnen met concrete datapunten, statistieken, data en voorbeelden presteren beter dan louter conceptuele content. Belangrijker nog: bronnen die gezaghebbende referenties citeren creëren vertrouwensketens, waarbij AI-systemen vertrouwen overnemen van de geciteerde bronnen. Content met onderbouwing en verwijzingen naar primaire bronnen laat hogere citatiepercentages zien dan beweringen zonder bewijs. Deze eis van feitendichtheid betekent dat elke significante claim moet worden voorzien van een bronvermelding naar gezaghebbende bronnen met publicatiedata en expertreferenties.
Verschillende AI-platforms hanteren uiteenlopende citaatstrategieën die hun architecturale verschillen en ontwerpfilosofieën weerspiegelen. Inzicht in deze platformspecifieke voorkeuren helpt contentmakers te optimaliseren voor meerdere AI-systemen tegelijk.
ChatGPT-citaatpatronen tonen een sterke voorkeur voor encyclopedische en gezaghebbende bronnen. Wikipedia verschijnt in ongeveer 35% van de ChatGPT-citaties, wat het vertrouwen van het model in gevestigde, door de community geverifieerde informatie weerspiegelt. Het platform vermijdt forums met door gebruikers gegenereerde content, tenzij er expliciet naar communitymeningen wordt gevraagd, en geeft de voorkeur aan bronnen met duidelijke attributieketens en verifieerbare feiten boven opinie-inhoud. Deze conservatieve aanpak weerspiegelt de training van ChatGPT op hoogwaardige bronnen en de ontwerpfilosofie waarbij nauwkeurigheid boven volledigheid gaat. Organisaties die ChatGPT-citaties nastreven, profiteren van aanwezigheid in kennisgrafieken, het opbouwen van Wikipedia-pagina’s en het creëren van content met encyclopedische diepgang en neutraliteit.
Google AI-systemen, waaronder Gemini en AI Overviews, nemen meer diverse bronsoorten op, wat de bredere indexeringsfilosofie van Google weerspiegelt. Reddit-posts zijn goed voor ongeveer 5% van de AI Overviews-citaties, terwijl het platform de voorkeur geeft aan content die in de top van de organische zoekresultaten verschijnt, wat synergie creëert tussen traditionele SEO en AI-citatiepercentages. Google’s AI-systemen tonen meer bereidheid om nieuwere en door gebruikers gegenereerde bronnen te citeren dan ChatGPT, mits deze bronnen relevantie en autoriteit aantonen. Dit platformvoorkeur betekent dat sterke prestaties in traditionele SEO correleren met AI-citatiesucces op de platformen van Google, hoewel de correlatie niet perfect is.
Perplexity AI-voorkeuren leggen nadruk op transparantie en directe bronvermelding. Het platform biedt doorgaans 3-5 bronnen per antwoord met directe links en geeft de voorkeur aan branchespecifieke reviewsites, expertpublicaties en data-gedreven content. Domeinautoriteit weegt zwaar mee, waarbij gevestigde publicaties voorrang krijgen, terwijl communitycontent slechts in ongeveer 1% van de citaties voorkomt, voornamelijk bij productaanbevelingen. De ontwerpfilosofie van Perplexity is gericht op het gebruikersgemak bij verificatie van informatie door duidelijke bronvermelding, waardoor het platform waardevol is voor merkzichtbaarheidstracking. Organisaties die optimaliseren voor Perplexity doen er goed aan data-rijke content, branchespecifieke bronnen en door experts geschreven artikelen met duidelijke autoriteit te creëren.
Domeinautoriteit fungeert als een betrouwbaarheidssignaal in AI-algoritmen, waarmee wordt aangegeven dat een bron zich door de tijd heen als geloofwaardig heeft bewezen. Systemen beoordelen autoriteit op basis van meerdere vertrouwenssignalen, die ongeveer 5% van de totale citeerkans vertegenwoordigen, hoewel dit percentage aanzienlijk stijgt voor YMYL-onderwerpen (Your Money, Your Life) die betrekking hebben op gezondheid, financiën of veiligheidsbeslissingen. Belangrijke autoriteitsindicatoren zijn domeinleeftijd, SSL-certificaten, privacybeleid en compliance-markeringen zoals SOC 2- of GDPR-certificering. Deze technische signalen versterken elkaar wanneer ze worden gecombineerd met contentkwaliteitsmetrics, waardoor technisch solide sites met uitstekende content beter presteren dan technisch zwakke sites, ongeacht de contentkwaliteit.
Backlinkprofielen hebben een aanzienlijke invloed op de bronperceptie in AI-algoritmen. AI-modellen beoordelen de autoriteit van linkende domeinen, de relevantie van de linkcontext en de diversiteit van het backlinkportfolio. Onderzoek toont aan dat tien backlinks van grote publicaties beter presteren dan 100 backlinks van sites met lage autoriteit, waarmee wordt aangetoond dat linkkwaliteit veel belangrijker is dan kwantiteit. Expertattributie vergroot de kans op citatie substantieel, waarbij content met een naamsvermelding van een auteur met verifieerbare referenties significant beter presteert dan anonieme content. Auteurschema-markup en gedetailleerde bio’s helpen AI-systemen expertise te valideren, terwijl validatie door derden via vermeldingen in branchespecifieke publicaties de geloofwaardigheid versterkt. Organisaties die autoriteit willen opbouwen, moeten zich richten op het verkrijgen van backlinks van bronnen met hoge autoriteit, het opbouwen van auteurreferenties en het verkrijgen van vermeldingen in branchepublicaties.
Aanwezigheid op Wikipedia en in kennisgrafieken verbetert de citatiepercentages aanzienlijk, ongeacht andere factoren. Bronnen die op Wikipedia zijn genoemd, hebben een groot voordeel omdat kennisgrafieken dienen als gezaghebbende bronnen die AI-modellen herhaaldelijk raadplegen bij diverse vragen. Informatie uit het Google Knowledge Panel voedt direct hoe AI-modellen entiteitsrelaties en autoriteit begrijpen. Organisaties zonder Wikipedia-aanwezigheid ondervinden moeite om consistente citaties te behalen, zelfs met hoogwaardige content, wat suggereert dat ontwikkeling van kennisgrafieken prioriteit moet krijgen voor serieuze AI-zichtbaarheidsstrategieën. Dit creëert een fundamentele vertrouwenslaag waar taalmodellen op terugvallen tijdens retrieval, waardoor kennisgrafiekvermeldingen als gezaghebbende bron fungeren.
Gespreksmatige Vraagafstemming betekent een fundamentele verschuiving ten opzichte van traditionele SEO-optimalisatie. Content die is gestructureerd als vraag-antwoordparen presteert beter in retrieval-algoritmen dan content die is geoptimaliseerd voor zoekwoorden. FAQ-pagina’s en content die natuurlijke taalvragen weerspiegelt krijgen de voorkeur omdat AI-systemen zijn getraind op gespreksdata en natuurlijke taalpatronen beter begrijpen dan zoekwoordstrings. Dit betekent dat content geschreven alsof je een vriend antwoord geeft, beter presteert dan content geschreven voor zoekmachine-algoritmen. Organisaties zouden hun content moeten toetsen op gespreksmatige toon, directe antwoorden op veelvoorkomende vragen en natuurlijke taal die aansluit bij hoe gebruikers daadwerkelijk vragen stellen.
Citatiewaarde Binnen Content creëert vertrouwensketens die verder reiken dan individuele bronnen. AI-systemen beoordelen of beweringen zijn onderbouwd met data en bewijs. Content die gezaghebbende referenties citeert, erft vertrouwen van die bronnen, wat een multiplicatief effect op geloofwaardigheid heeft. Bronnen die ondersteunend bewijs en links naar primaire bronnen bevatten, laten hogere citatiepercentages zien dan beweringen zonder onderbouwing. Dit betekent dat elke significante bewering moet worden voorzien van een bronvermelding naar gezaghebbende bronnen met publicatiedata en expertreferenties. Organisaties die content willen maken die het waard is om geciteerd te worden, moeten minimaal 5-8 gezaghebbende bronnen citeren, 2-3 expertquotes met volledige referenties opnemen en 3-5 recente statistieken met publicatiedata toevoegen.
Consistentie Over Platformen beïnvloedt hoe AI-systemen bronbetrouwbaarheid beoordelen. Wanneer AI consistente informatie vindt over meerdere bronnen, neemt het vertrouwen toe om een individuele bron uit dat cluster te citeren. Bronnen die de bredere consensus tegenspreken krijgen lagere prioriteit, tenzij ze overtuigend tegenbewijs leveren. Deze consistentievoorkeur betekent dat het opbouwen van samenhangende boodschappen via eigen, verdiende en gedeelde mediakanalen de citeerbaarheid van individuele bronnen versterkt. Organisaties die AI-reputatiemanagementstrategieën ontwikkelen, moeten consistente communicatie over alle digitale eigendommen handhaven, zodat de informatie op corporate websites, sociale media, branchepublicaties en externe platforms op elkaar aansluit en kernboodschappen versterkt.
Updatefrequentie-strategie is belangrijker in het AI-tijdperk dan bij traditionele SEO. De publicatiefrequentie heeft direct invloed op citatiepercentages, waarbij AI-platforms een sterke voorkeur tonen voor recent geüpdatete content. Organisaties zouden bestaande content elke 48-72 uur moeten updaten om actualiteitssignalen te behouden, hoewel dit geen complete herschrijvingen vereist. Nieuwe datapunten toevoegen, statistieken bijwerken of gedeelten uitbreiden met recente ontwikkelingen houdt content geschikt voor citatie. Contentmanagementsystemen die updatefrequentie en contentactualiteit bijhouden, dragen bij aan competitieve citatiepercentages nu AI-platforms steeds zwaarder leunen op actualiteitssignalen. Deze continue updateaanpak verschilt fundamenteel van traditionele SEO, waarbij content soms jarenlang zonder aanpassing kon scoren.
Strategische Plaatsing op Aggregatorsites creëert meerdere ontdekkingstrajecten voor AI-systemen. In branche-overzichten, expertlijsten of reviewsites verschijnen, genereert extra kansen bovenop wat de oorspronkelijke bron alleen bereikt. Eén vermelding in een vaak geciteerde publicatie creëert meerdere paden voor AI-systemen om je content tegen te komen. Mediapartnerships en contentrelaties worden waardevoller voor AI-zichtbaarheid, net als strategische plaatsing in branchegerichte databases en directories. Organisaties zouden aanwezigheid in branche-overzichten, expertlijsten en reviewsites moeten nastreven als onderdeel van hun AI-zichtbaarheidsstrategie.
Implementatie van Gestructureerde Data verbetert de kans op citatie door content machineleesbaar te maken. Schema markup in AI-vriendelijke formaten helpt AI-platforms specifieke feiten te begrijpen en te extraheren zonder ongestructureerde tekst te hoeven parsen. Het FAQ-schema, Artikel-schema met auteurinformatie en Organisatie-schema geven machineleesbare signalen die retrieval-algoritmen prioriteren. JSON-LD gestructureerde data stelt AI in staat om efficiënt specifieke feiten te extraheren, wat zowel de kans op citatie als de nauwkeurigheid van geciteerde informatie verbetert. Organisaties die uitgebreide schema markup implementeren, zien meetbare verbeteringen in citatiepercentages op meerdere AI-platforms.
Ontwikkeling van Wikipedia en Kennisgrafieken levert cumulatieve voordelen op, ondanks dat het doorlopende inspanning vereist. Een Wikipedia-aanwezigheid opbouwen vereist neutrale, goed onderbouwde bijdragen die voldoen aan de redactionele standaarden van Wikipedia. Tegelijkertijd het optimaliseren van profielen op Wikidata, Google Knowledge Panel en branchegerichte databases creëert de fundamentele vertrouwenslaag waar AI-systemen herhaaldelijk op terugvallen. Deze kennisgrafiekvermeldingen fungeren als gezaghebbende bronnen die modellen bij diverse vragen raadplegen, waardoor kennisgrafiekontwikkeling een strategische prioriteit is voor organisaties die streven naar blijvende AI-zichtbaarheid.
Organisaties moeten de citatiefrequentie bijhouden door relevante queries handmatig te testen op ChatGPT, Google AI Overviews, Perplexity en andere platforms. Regelmatige prompttesten laten zien welke content daadwerkelijk citaties oplevert en waar nog hiaten zitten in AI-representatie. Deze testmethodologie biedt directe zichtbaarheid in citatieprestaties en helpt optimalisatiemogelijkheden te identificeren. AI-citaatalgoritmen zijn continu in ontwikkeling naarmate trainingsdata uitbreidt en retrievalstrategieën veranderen, waardoor contentstrategieën moeten worden aangepast op basis van prestatiegegevens. Wanneer content geen citaties meer ontvangt ondanks eerder succes, is het zaak de content te updaten met recente informatie of te herstructureren voor betere semantische afstemming.
Meerdere bronnen kunnen citaties krijgen voor één query, waardoor co-citatiekansen ontstaan in plaats van zero-sum-concurrentie. Organisaties profiteren van het creëren van uitgebreide content die bestaande, veelgeciteerde bronnen aanvult in plaats van dupliceert. Analyse van het concurrentielandschap onthult welke merken AI-zichtbaarheid domineren in specifieke categorieën, zodat organisaties hiaten en kansen kunnen identificeren. Door de citatieprestaties over tijd bij te houden, worden trends en succesvolle URL’s zichtbaar, waardoor organisaties winnende strategieën kunnen repliceren en succesvolle aanpakken kunnen opschalen.
Volg waar uw content verschijnt in door AI gegenereerde antwoorden op ChatGPT, Perplexity, Google AI Overviews en andere AI-platforms. Krijg realtime inzichten in uw AI-zichtbaarheid en citatieprestaties.
Leer hoe AI-systemen bepalen welke bronnen ze citeren versus parafraseren. Begrijp citatieselectie-algoritmen, biaspatronen en strategieën om de zichtbaarheid v...

Leer hoe door AI gegenereerde content presteert in AI-zoekmachines zoals ChatGPT, Perplexity en Google AI Overviews. Ontdek rankingfactoren, optimalisatiestrate...

Ontdek hoe AI-engines ultieme gidsen en long-form content citeren. Leer citatiepatronen over ChatGPT, Gemini, Perplexity en Google AI Overviews om de zichtbaarh...
Cookie Toestemming
We gebruiken cookies om uw browse-ervaring te verbeteren en ons verkeer te analyseren. See our privacy policy.