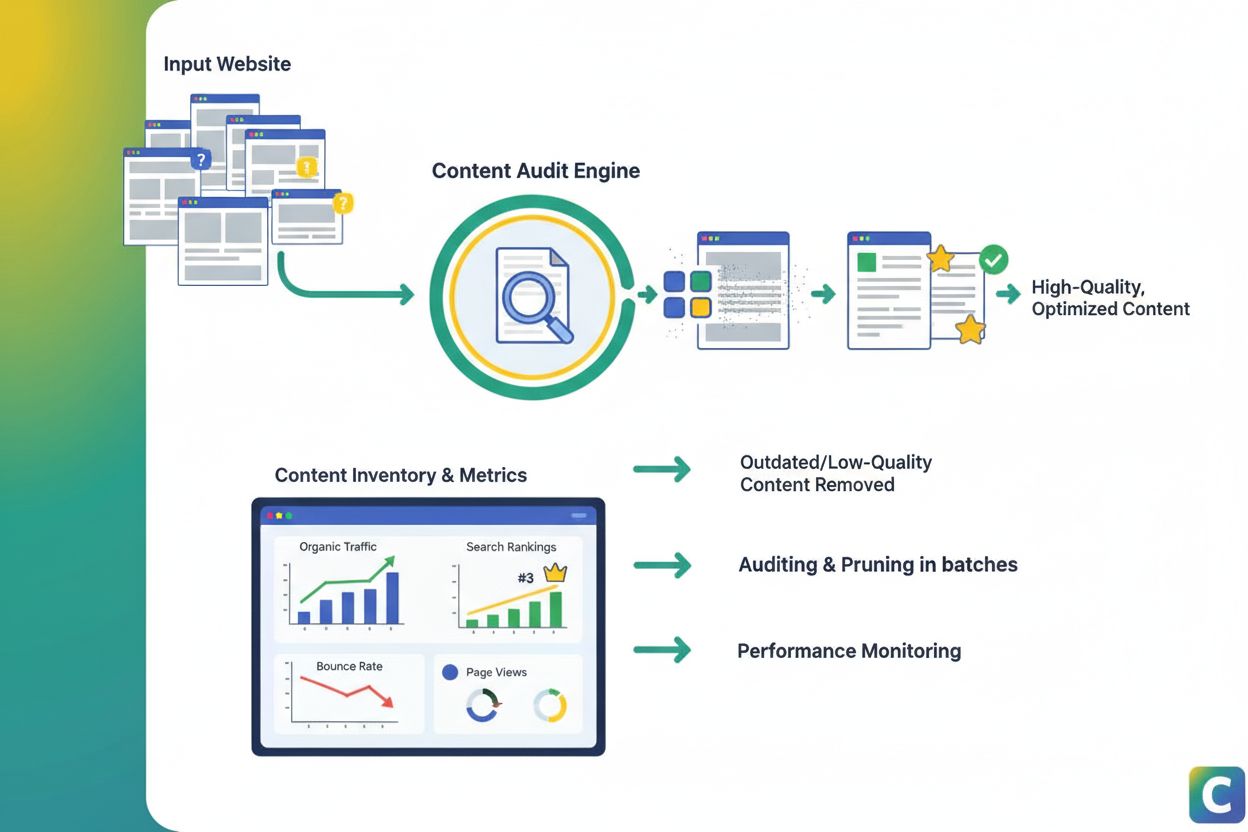
Content Pruning
Content pruning is het strategisch verwijderen of updaten van ondermaats presterende content om SEO, gebruikerservaring en zoekzichtbaarheid te verbeteren. Leer...
16 min lezen

Ontdek wat content pruning voor AI is, hoe het werkt, verschillende pruning-methoden en waarom het essentieel is voor het inzetten van efficiënte AI-modellen op edge devices en in omgevingen met beperkte middelen.
Content pruning voor AI is een techniek waarbij selectief overbodige of minder belangrijke parameters, gewichten of tokens uit AI-modellen worden verwijderd om hun omvang te verkleinen, de inferentiesnelheid te verbeteren en het geheugengebruik te verminderen, terwijl de prestatiekwaliteit behouden blijft.
Content pruning voor AI is een fundamentele optimalisatietechniek die wordt gebruikt om de computationele complexiteit en het geheugengebruik van kunstmatige intelligentiemodellen te verminderen zonder dat dit ten koste gaat van hun prestaties. Dit proces houdt in dat systematisch overbodige of minder belangrijke componenten uit neurale netwerken worden geïdentificeerd en verwijderd, waaronder individuele gewichten, volledige neuronen, filters of zelfs tokens in taalmodellen. Het primaire doel is om slankere, snellere en efficiëntere modellen te creëren die effectief kunnen worden ingezet op apparaten met beperkte middelen, zoals smartphones, edge computing-systemen en IoT-apparaten.
Het concept van pruning is geïnspireerd op biologische systemen, specifiek op synaptische pruning in het menselijk brein, waarbij onnodige neurale verbindingen tijdens de ontwikkeling worden geëlimineerd. Op vergelijkbare wijze erkent AI-pruning dat getrainde neurale netwerken vaak veel parameters bevatten die minimaal bijdragen aan de uiteindelijke output. Door deze overbodige componenten te verwijderen, kunnen ontwikkelaars aanzienlijke verkleiningen van het model realiseren terwijl, door zorgvuldige fine-tuning, de nauwkeurigheid behouden of zelfs verbeterd kan worden.
Content pruning werkt op basis van het principe dat niet alle parameters in een neuraal netwerk even belangrijk zijn voor het doen van voorspellingen. Tijdens het trainingsproces ontwikkelen neurale netwerken complexe onderlinge verbindingen, waarvan er veel overbodig worden of slechts minimaal bijdragen aan het besluitvormingsproces van het model. Pruning identificeert deze minder kritische componenten en verwijdert ze, wat resulteert in een spaarzame netwerkarchitectuur die minder computationele middelen vereist.
De effectiviteit van pruning is afhankelijk van verschillende factoren, waaronder de gebruikte pruning-methode, de mate van agressiviteit van de strategie en het daaropvolgende fine-tuningproces. Verschillende pruning-benaderingen richten zich op verschillende aspecten van neurale netwerken. Sommige methoden richten zich op individuele gewichten (ongestructureerd pruning), terwijl andere volledige neuronen, filters of kanalen verwijderen (gestructureerd pruning). De gekozen methode heeft een aanzienlijke invloed op zowel de resulterende modelefficiëntie als de compatibiliteit met moderne hardwareversnellers.
| Type Pruning | Doelwit | Voordelen | Uitdagingen |
|---|---|---|---|
| Gewichtspruning | Individuele verbindingen/gewichten | Maximale compressie, spaarzame netwerken | Kan hardware-uitvoering niet versnellen |
| Gestructureerd Pruning | Neuronen, filters, kanalen | Hardwarevriendelijk, snellere inferentie | Minder compressie dan ongestructureerd |
| Dynamisch Pruning | Contextafhankelijke parameters | Adaptieve efficiëntie, realtime aanpassing | Complexe implementatie, hogere overhead |
| Laagpruning | Volledige lagen of blokken | Aanzienlijke verkleining | Risico op nauwkeurigheidsverlies, vereist zorgvuldige validatie |
Ongestructureerd pruning, ook bekend als gewichtspruning, werkt op het fijnmazige niveau door individuele gewichten uit de gewichtsmatrices van het netwerk te verwijderen. Deze aanpak gebruikt doorgaans criteria op basis van grootte, waarbij gewichten met waarden dicht bij nul als minder belangrijk worden beschouwd en worden geëlimineerd. Het resulterende netwerk wordt spaarzaam, wat betekent dat slechts een fractie van de oorspronkelijke verbindingen actief blijft tijdens inferentie. Hoewel ongestructureerd pruning indrukwekkende compressieratio’s kan bereiken—soms wordt het aantal parameters met 90% of meer verminderd—leiden de resulterende spaarzame netwerken niet altijd tot evenredige snelheidsverbeteringen op standaard hardware zonder gespecialiseerde ondersteuning voor spaarzame berekeningen.
Gestructureerd pruning volgt een andere benadering door volledige groepen parameters tegelijkertijd te verwijderen, zoals complete filters in convolutionele lagen, volledige neuronen in volledig verbonden lagen, of hele kanalen. Deze methode is bijzonder waardevol voor praktische implementatie omdat de resulterende modellen van nature compatibel zijn met moderne hardwareversnellers zoals GPU’s en TPU’s. Wanneer volledige filters uit convolutionele lagen worden verwijderd, worden de computationele besparingen direct gerealiseerd zonder dat gespecialiseerde spaarzame matrixbewerkingen nodig zijn. Onderzoek heeft aangetoond dat gestructureerd pruning de modelgrootte met 50-90% kan verminderen, terwijl de nauwkeurigheid vergelijkbaar blijft met de originele modellen.
Dynamisch pruning vertegenwoordigt een meer geavanceerde aanpak waarbij het pruning-proces zich tijdens de modelinferenz aanpast op basis van de specifieke input die wordt verwerkt. Deze techniek maakt gebruik van externe context, zoals sprekersembeddings, gebeurtenisaanwijzingen of taalspecifieke informatie om dynamisch aan te passen welke parameters actief zijn. In retrieval-augmented generation-systemen kan dynamisch pruning de contextgrootte met ongeveer 80% verminderen, terwijl tegelijkertijd de antwoordnauwkeurigheid wordt verbeterd door irrelevante informatie te filteren. Deze adaptieve benadering is vooral waardevol voor multimodale AI-systemen die efficiënt diverse inputtypen moeten verwerken.
Iteratief pruning en fine-tuning is een van de meest toegepaste benaderingen in de praktijk. Deze methode omvat een cyclisch proces: een deel van het netwerk wordt gepruned, de resterende parameters worden gefinetuned om verloren nauwkeurigheid te herstellen, de prestaties worden geëvalueerd, en het proces wordt herhaald. De iteratieve aard van deze aanpak stelt ontwikkelaars in staat om modelcompressie zorgvuldig in balans te brengen met het behoud van prestaties. In plaats van alle overbodige parameters in één keer te verwijderen—wat catastrofaal zou kunnen zijn voor de prestaties—vermindert iteratief pruning geleidelijk de netwerkcomplexiteit, terwijl het model kan leren welke resterende parameters het belangrijkst zijn.
One-shot pruning biedt een snellere alternatieve aanpak waarbij de volledige pruning-operatie in één stap na de training plaatsvindt, gevolgd door een fine-tuningfase. Hoewel deze aanpak computationeel efficiënter is dan iteratieve methoden, is er een groter risico op nauwkeurigheidsverlies als te veel parameters tegelijk worden verwijderd. One-shot pruning is vooral nuttig wanneer de computationele middelen voor iteratieve processen beperkt zijn, maar vereist doorgaans meer uitgebreide fine-tuning om de prestaties te herstellen.
Pruning op basis van gevoeligheidsanalyse gebruikt een geavanceerder rangschikkingsmechanisme door te meten hoeveel de verliesfunctie van het model toeneemt wanneer specifieke gewichten of neuronen worden verwijderd. Parameters die minimale impact hebben op de verliesfunctie worden geïdentificeerd als veilige kandidaten voor pruning. Deze datagedreven aanpak biedt genuanceerdere pruningbeslissingen dan simpele magnitude-gebaseerde methoden en resulteert vaak in een beter behoud van nauwkeurigheid bij eenzelfde compressieniveau.
De Lottery Ticket Hypothesis presenteert een intrigerend theoretisch kader dat suggereert dat binnen grote neurale netwerken een kleiner, spaarzaam sub-netwerk bestaat—het “winnende lot”—dat vergelijkbare nauwkeurigheid kan bereiken als het originele netwerk wanneer het vanaf dezelfde initiële waarden wordt getraind. Deze hypothese heeft grote gevolgen voor het begrip van redundantie in netwerken en heeft nieuwe pruning-methodologieën geïnspireerd die proberen deze efficiënte sub-netwerken te identificeren en te isoleren.
Content pruning is onmisbaar geworden in talloze AI-toepassingen waar computationele efficiëntie essentieel is. Inzet op mobiele en embedded apparaten is een van de belangrijkste use-cases, waarbij geprunde modellen geavanceerde AI-functionaliteit mogelijk maken op smartphones en IoT-apparaten met beperkte rekenkracht en batterijcapaciteit. Beeldherkenning, spraakassistenten en realtime vertaaltoepassingen profiteren allemaal van geprunde modellen die nauwkeurig blijven terwijl ze minimale middelen verbruiken.
Autonome systemen, waaronder zelfrijdende voertuigen en drones, vereisen realtime beslissingen met minimale vertraging. Geprunde neurale netwerken stellen deze systemen in staat om sensordata te verwerken en cruciale beslissingen te nemen binnen strikte tijdslimieten. De verminderde computationele overhead vertaalt zich direct in snellere reactietijden, wat essentieel is voor toepassingen waar veiligheid voorop staat.
In cloud- en edge computing-omgevingen vermindert pruning zowel de computationele kosten als de opslagvereisten voor het inzetten van grootschalige modellen. Organisaties kunnen meer gebruikers bedienen met dezelfde infrastructuur, of hun computationele uitgaven aanzienlijk verlagen. Edge computing-scenario’s profiteren in het bijzonder van geprunde modellen, omdat ze geavanceerde AI-verwerking mogelijk maken op apparaten ver van gecentraliseerde datacenters.
Het evalueren van de effectiviteit van pruning vereist een zorgvuldige afweging van meerdere prestatiemetingen naast het simpelweg tellen van minder parameters. Inferentielatentie—de tijd die een model nodig heeft om output te genereren uit input—is een kritieke maatstaf die direct de gebruikerservaring in realtime toepassingen beïnvloedt. Effectieve pruning zou de inferentielatentie aanzienlijk moeten verminderen, waardoor eindgebruikers sneller respons ervaren.
Modelnauwkeurigheid en F1-scores moeten tijdens het hele pruningproces behouden blijven. De fundamentele uitdaging bij pruning is om aanzienlijke compressie te bereiken zonder voorspellende prestaties op te offeren. Goed ontworpen pruningstrategieën behouden de nauwkeurigheid binnen 1-5% van het originele model terwijl ze 50-90% parameterreductie realiseren. Vermindering van geheugengebruik is even belangrijk, omdat dit bepaalt of modellen kunnen worden ingezet op apparaten met beperkte middelen.
Onderzoek dat grote-spaarzame modellen (grote netwerken waarvan veel parameters zijn verwijderd) vergelijkt met kleine-dichte modellen (kleinere netwerken die vanaf nul zijn getraind) met een identiek geheugenprofiel, toont consequent aan dat grote-spaarzame modellen beter presteren dan hun kleine-dichte tegenhangers. Deze bevinding benadrukt het voordeel van het starten met grotere, goed getrainde netwerken en deze vervolgens strategisch te prunen, in plaats van direct te proberen kleinere netwerken te trainen.
Nauwkeurigheidsverlies blijft de grootste uitdaging bij content pruning. Agressief pruning kan de modelprestaties aanzienlijk verminderen, waardoor zorgvuldige kalibratie van de intensiteit nodig is. Ontwikkelaars moeten het optimale punt vinden waarop de compressiewinst maximaal is zonder onaanvaardbaar nauwkeurigheidsverlies. Dit balanspunt varieert afhankelijk van de specifieke toepassing, modelarchitectuur en acceptabele prestatiegrenzen.
Hardwarecompatibiliteit kan de praktische voordelen van pruning beperken. Terwijl ongestructureerd pruning spaarzame netwerken met minder parameters creëert, is moderne hardware geoptimaliseerd voor dichte matrixbewerkingen. Spaarzame netwerken draaien mogelijk niet significant sneller op standaard GPU’s zonder gespecialiseerde spaarzame rekensoftware en hardware-ondersteuning. Gestructureerd pruning ondervangt deze beperking door dichte berekeningspatronen te behouden, zij het met minder agressieve compressie.
Computationele overhead van pruning-methoden zelf kan aanzienlijk zijn. Iteratief pruning en op gevoeligheidsanalyse gebaseerde methoden vereisen meerdere trainingscycli en zorgvuldige evaluatie, wat aanzienlijke rekenmiddelen vergt. Ontwikkelaars moeten de eenmalige kosten van pruning afwegen tegen de blijvende voordelen van het inzetten van efficiëntere modellen.
Generaliseringsproblemen ontstaan wanneer er te agressief wordt gepruned. Modellen die te veel zijn gepruned presteren mogelijk goed op trainings- en validatiedata, maar generaliseren slecht naar nieuwe, ongeziene data. Goede validatiestrategieën en grondige tests op diverse datasets zijn essentieel om ervoor te zorgen dat geprunde modellen goede prestaties blijven leveren in productieomgevingen.
Succesvol content pruning vereist een systematische aanpak gebaseerd op best practices uit uitgebreid onderzoek en praktijkervaring. Begin met grotere, goed getrainde netwerken in plaats van te proberen kleinere netwerken vanaf nul te trainen. Grotere netwerken bieden meer redundantie en flexibiliteit voor pruning, en onderzoek toont consequent aan dat geprunde grote netwerken beter presteren dan kleine netwerken die vanaf het begin zijn getraind.
Gebruik iteratief pruning met zorgvuldige fine-tuning om de netwerkcomplexiteit geleidelijk te verminderen terwijl de prestaties behouden blijven. Deze aanpak biedt meer controle over de afweging tussen nauwkeurigheid en efficiëntie en stelt het model in staat zich aan te passen aan het verwijderen van parameters. Voer gestructureerd pruning toe voor praktische inzet wanneer hardwareversnelling belangrijk is, omdat dit modellen oplevert die efficiënt draaien op standaard hardware zonder gespecialiseerde spaarzame rekenondersteuning.
Valideer uitgebreid op diverse datasets om ervoor te zorgen dat geprunde modellen goed generaliseren buiten de trainingsdata. Monitor meerdere prestatiemetingen zoals nauwkeurigheid, inferentielatentie, geheugengebruik en stroomverbruik om de effectiviteit van pruning volledig te evalueren. Houd rekening met de beoogde inzetomgeving bij het kiezen van pruning-strategieën, aangezien verschillende apparaten en platforms hun eigen optimalisatiekenmerken hebben.
Het vakgebied van content pruning ontwikkelt zich voortdurend met nieuwe technieken en methodologieën. Contextually Adaptive Token Pruning (CATP) is een geavanceerde aanpak die semantische afstemming en feature-diversiteit gebruikt om alleen de meest relevante tokens in taalmodellen selectief te behouden. Deze techniek is vooral waardevol voor grote taalmodellen en multimodale systemen waar contextbeheer cruciaal is.
Integratie met vectordatabases zoals Pinecone en Weaviate maakt geavanceerdere contextpruningstrategieën mogelijk door efficiënt relevante informatie op te slaan en op te halen. Deze integraties ondersteunen dynamische pruningbeslissingen op basis van semantische gelijkenis en relevantiescores, wat zowel efficiëntie als nauwkeurigheid verbetert.
Combinatie met andere compressietechnieken zoals kwantisatie en knowledge distillation zorgt voor synergetische effecten, waardoor nog agressievere modelcompressie mogelijk wordt. Modellen die tegelijkertijd worden gepruned, gekwantiseerd en gedistilleerd kunnen compressieratio’s van 100x of meer bereiken terwijl de prestaties acceptabel blijven.
Nu AI-modellen steeds complexer worden en de inzetscenario’s diverser, zal content pruning een essentiële techniek blijven om geavanceerde AI toegankelijk en praktisch te maken in het volledige spectrum van computeromgevingen, van krachtige datacenters tot apparaten aan de rand met beperkte middelen.
Ontdek hoe AmICited u helpt bij het volgen wanneer uw content verschijnt in AI-gegenereerde antwoorden op ChatGPT, Perplexity en andere AI-zoekmachines. Zorg voor uw merkzichtbaarheid in de AI-gedreven toekomst.
Content pruning is het strategisch verwijderen of updaten van ondermaats presterende content om SEO, gebruikerservaring en zoekzichtbaarheid te verbeteren. Leer...

Leer hoe je uitgebreide content maakt die geoptimaliseerd is voor AI-systemen, inclusief dieptevereisten, structuur best practices en opmaakrichtlijnen voor AI-...
Leer hoe je je content kunt consolideren en optimaliseren voor AI-zoekmachines zoals ChatGPT, Perplexity en Gemini. Ontdek best practices voor contentstructuur,...
Cookie Toestemming
We gebruiken cookies om uw browse-ervaring te verbeteren en ons verkeer te analyseren. See our privacy policy.