JSON-LD
JSON-LD is een door W3C gestandaardiseerd formaat voor gestructureerde gegevens dat JSON-syntaxis gebruikt voor schema.org-markup. Ontdek hoe JSON-LD SEO verbet...
11 min lezen

Leer wat JSON-LD is en hoe je het implementeert voor SEO. Ontdek de voordelen van gestructureerde data markup voor Google, ChatGPT, Perplexity en zichtbaarheid in AI-zoekopdrachten.
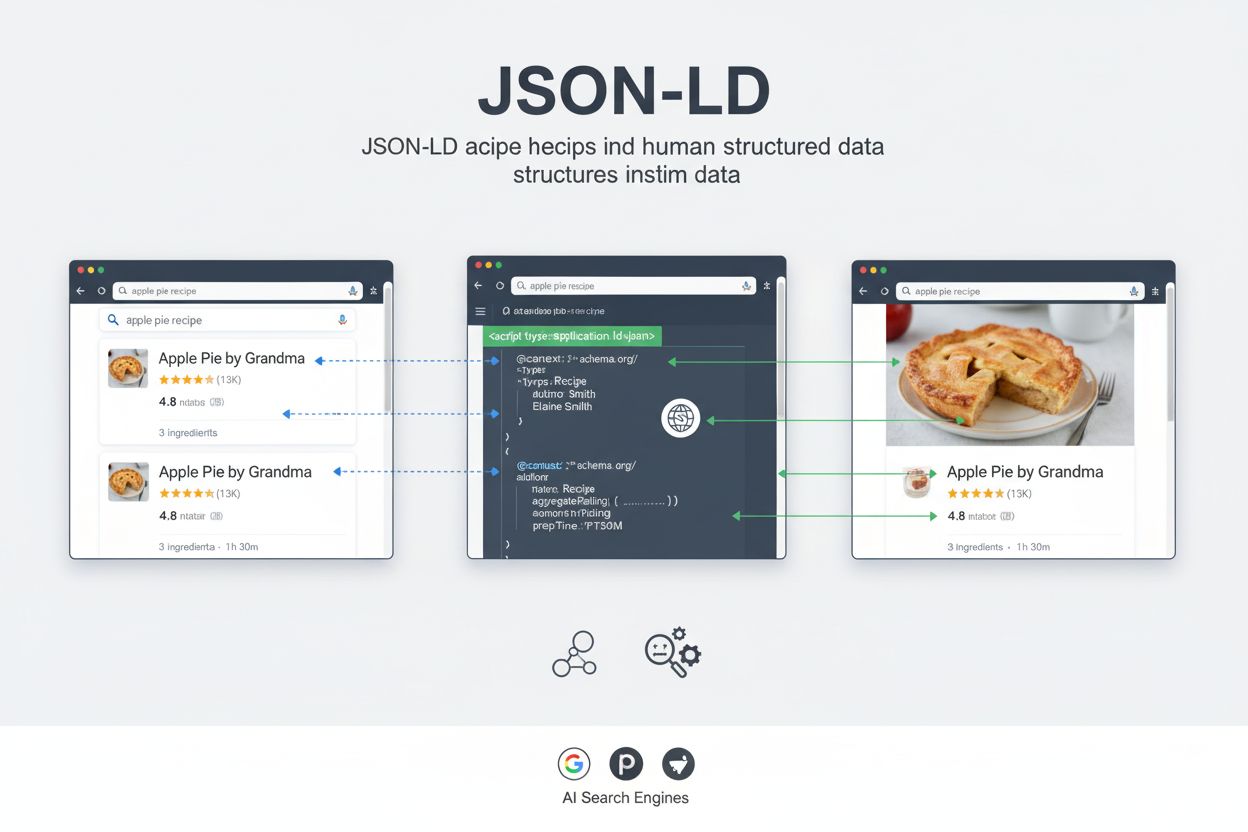
JSON-LD (JavaScript Object Notation for Linked Data) is een lichtgewicht, machineleesbaar dataformaat dat zoekmachines helpt om de inhoud van je website te begrijpen via gestructureerde markup. Geïmplementeerd via <script>-tags in HTML, maakt JSON-LD rijke zoekresultaten mogelijk, verbetert de zichtbaarheid bij AI, en is het door Google aanbevolen formaat voor de implementatie van schema.org gestructureerde data.
JSON-LD (JavaScript Object Notation for Linked Data) is een lichtgewicht, machineleesbaar dataformaat waarmee zoekmachines en kunstmatige intelligentie systemen de betekenis en context van je webinhoud kunnen begrijpen. In tegenstelling tot traditionele HTML, die bedoeld is voor menselijke lezers, voorziet JSON-LD machines van expliciete semantische informatie die helpt bij het interpreteren van wat je inhoud vertegenwoordigt. Gestructureerde data via JSON-LD is essentieel geworden in het hedendaagse zoeklandschap, waarin zowel traditionele zoekmachines als AI-gestuurde systemen zoals Google AI Overviews, ChatGPT, Perplexity en Claude vertrouwen op duidelijke, machineleesbare signalen om je inhoud te begrijpen en te tonen. Google beveelt JSON-LD officieel aan als het voorkeursformaat voor de implementatie van schema.org gestructureerde data, waardoor het de industriestandaard is voor SEO-professionals en webontwikkelaars. Door JSON-LD correct toe te passen, geef je zoekmachines exact aan wat elk element op je pagina betekent—of het nu een productprijs, receptingrediënten, evenementdatums of de auteur van een artikel is—wat direct invloed heeft op je zichtbaarheid in zowel traditionele zoekresultaten als opkomende AI-zoekervaringen.
Gestructureerde data is geëvolueerd van een handige SEO-tactiek tot een cruciaal onderdeel van moderne webzichtbaarheid. Het W3C (World Wide Web Consortium) heeft JSON-LD in 2014 gestandaardiseerd als een W3C-aanbeveling, waarmee het het officiële formaat voor gelinkte data op het web werd. Sindsdien is de adoptie sterk toegenomen en ondersteunen grote zoekmachines zoals Google, Bing, Yahoo en Yandex allemaal JSON-LD markup. Onderzoek toont het tastbare effect van gestructureerde data: Rotten Tomatoes behaalde een 25% hogere doorklikratio op pagina’s met gestructureerde data ten opzichte van niet-gemarkeerde pagina’s, terwijl The Food Network 80% van hun pagina’s aanpaste om zoekfuncties mogelijk te maken en een toename van 35% in bezoeken zag. Nestlé constateerde dat pagina’s die als rich results werden getoond in zoekopdrachten een 82% hogere doorklikratio hadden dan pagina’s zonder rich results. Deze statistieken onderstrepen waarom JSON-LD-implementatie onmisbaar is voor concurrerende websites. Het belang van dit formaat is alleen maar toegenomen door de opkomst van AI-gestuurde zoekmachines, die sterk leunen op gestructureerde data om context te begrijpen en te bepalen of ze jouw pagina’s in hun antwoorden citeren.
| Aspect | JSON-LD | Microdata | RDFa |
|---|---|---|---|
| Implementatiemethode | Ingebed in <script>-tags | HTML-attributen en -tags | HTML5-extensie-attributen |
| Plaatsing | Head of body (flexibel) | Meestal in body | Head en body |
| Data-scheiding | Gescheiden van zichtbare inhoud | Verweven met HTML | Verweven met HTML |
| Nest-complexiteit | Uitstekend voor geneste data | Matig | Matig |
| Google-aanbeveling | Aanbevolen (primair) | Eveneens ondersteund | Eveneens ondersteund |
| Implementatiegemak | Het makkelijkst voor ontwikkelaars | Vereist HTML-aanpassing | Vereist HTML-aanpassing |
| Dynamische injectie | Ondersteunt JavaScript-injectie | Beperkte ondersteuning | Beperkte ondersteuning |
| Leercurve | Matig (kennis van JSON handig) | Steiler (HTML-attributen) | Steiler (RDF-concepten) |
| Onderhoud op schaal | Het makkelijkst te beheren | Meer foutgevoelig | Meer foutgevoelig |
| AI-zoekcompatibiliteit | Optimaal voor LLM’s | Goed | Goed |
Google geeft expliciet aan dat JSON-LD de eenvoudigste oplossing is voor website-eigenaren om op schaal te implementeren en te onderhouden, waardoor het minder gevoelig is voor gebruikersfouten dan alternatieven. Hoewel alle drie de formaten even geldig zijn voor Google Search, maakt de scheiding van gestructureerde data van zichtbare HTML-inhoud JSON-LD superieur voor complexe, geneste datastructuren—zoals het beschrijven van een evenementlocatie binnen een evenement, of verzenddetails van een product binnen een aanbieding.
JSON-LD werkt door een JavaScript objectnotatie-script direct in je HTML-document te plaatsen, meestal in de <head>-sectie of ergens in de <body>. Het formaat gebruikt een gestandaardiseerde vocabulaire van schema.org, dat definities biedt voor honderden entiteitstypen en eigenschappen. Wanneer Google’s crawlers JSON-LD-markup tegenkomen, parseren ze de gestructureerde data en gebruiken deze om de inhoud van je pagina beter te begrijpen, zodat ze rijke resultaten kunnen tonen met visuele elementen zoals sterbeoordelingen, prijsinformatie, afbeeldingen en interactieve functies. Het implementatieproces begint met het identificeren van het type inhoud dat je markeert—of het nu een artikel, product, recept, evenement, FAQ of lokaal bedrijf is—en vervolgens het juiste schema.org-type selecteren. Elk schema-type heeft verplichte eigenschappen (vereist voor rich results) en aanbevolen eigenschappen (die de zichtbaarheid en context verbeteren). De @context-eigenschap, ingesteld op “https://schema.org/"
, geeft aan dat je de schema.org-vocabulaire gebruikt, terwijl de @type-eigenschap het exacte entiteitstype specificeert dat je beschrijft.
Hier is een eenvoudig voorbeeld van JSON-LD voor een artikel:
<script type="application/ld+json">
{
"@context": "https://schema.org/",
"@type": "Article",
"headline": "JSON-LD begrijpen voor moderne SEO",
"author": {
"@type": "Person",
"name": "Sarah Johnson"
},
"datePublished": "2024-01-15",
"image": "https://example.com/article-image.jpg",
"description": "Een uitgebreide gids voor JSON-LD-implementatie"
}
</script>
Voor complexere structuren ondersteunt JSON-LD nesting, waarmee je gerelateerde objecten binnen ouderobjecten kunt plaatsen. Zo kan een Event-schema geneste Person-objecten bevatten voor artiesten en een Place-object voor de locatie, allemaal binnen één samenhangende datastructuur.
Hoewel de namen op elkaar lijken, dienen JSON en JSON-LD verschillende doelen en mogen ze niet met elkaar worden verward. JSON (JavaScript Object Notation) is een algemeen, lichtgewicht data-uitwisselingsformaat dat wordt gebruikt voor het verzenden en ontvangen van gestructureerde data tussen systemen en API’s. Het is een syntaxisstandaard voor het organiseren van data in key-value paren en arrays, maar draagt niet inherent semantische betekenis—de data kan alles voorstellen afhankelijk van de context. JSON-LD daarentegen is specifiek ontworpen voor gelinkte data op het web en gebruikt JSON-syntaxis gecombineerd met semantische context van schema.org-vocabularia. JSON-LD transformeert ruwe JSON-data in machinebegrijpbare informatie door context toe te voegen via de @context-eigenschap, die machines vertelt wat elk veld betekent. Deze semantische laag is cruciaal voor zoekmachines en AI-systemen: terwijl JSON simpelweg {"name": "John", "birthDate": "1990-05-15"} kan bevatten, geeft JSON-LD expliciet aan dat dit om een Person-entiteit gaat met specifieke eigenschappen, waardoor zoekmachines de relatie tussen de data en echte concepten begrijpen. Voor SEO-doeleinden is JSON-LD veel beter omdat het zoekmachines in staat stelt niet alleen je data te lezen, maar ook de betekenis en relevantie ervan voor gebruikersvragen te begrijpen.
Nesting in JSON-LD verwijst naar het organiseren van informatie in hiërarchische lagen, waarmee je relaties tussen meerdere entiteiten binnen één markup-structuur kunt beschrijven. Deze mogelijkheid is één van de grootste krachten van JSON-LD ten opzichte van andere gestructureerde dataformaten. Bij het nesten van objecten geef je in feite aan: “deze entiteit is onderdeel van die entiteit” of “deze eigenschap hoort bij dat object.” In een Event-schema kun je bijvoorbeeld een Person-object (de artiest) en een Place-object (de locatie) nesten binnen het Event-object zelf. Elk genest object behoudt zijn eigen @type en eigenschappen, waardoor een rijke, onderling verbonden datastructuur ontstaat die zoekmachines nauwkeurig kunnen parseren.
Bekijk dit voorbeeld van een muziekevenement met geneste informatie over de artiest en locatie:
<script type="application/ld+json">
{
"@context": "https://schema.org/",
"@type": "Event",
"name": "Summer Jazz Festival",
"startDate": "2024-07-15T18:00:00",
"location": {
"@type": "Place",
"name": "Central Park Amphitheater",
"address": {
"@type": "PostalAddress",
"streetAddress": "123 Park Avenue",
"addressLocality": "New York",
"addressRegion": "NY",
"postalCode": "10001"
}
},
"performer": {
"@type": "Person",
"name": "Jazz Quartet Ensemble"
}
}
</script>
Door deze nesting kunnen zoekmachines begrijpen dat de artiest bij dit specifieke evenement op deze specifieke locatie hoort. Deze gedetailleerde context is van onschatbare waarde voor AI-systemen die relaties tussen entiteiten moeten begrijpen. De onveranderlijke tags zoals @context en @type blijven gelijk over verschillende schematypen heen en vormen herbruikbare bouwstenen voor complexe markup-strategieën.
Zelfs ervaren ontwikkelaars maken fouten bij de implementatie van JSON-LD, en deze fouten kunnen ervoor zorgen dat je gestructureerde data niet wordt herkend door zoekmachines. Het begrijpen van veelvoorkomende valkuilen helpt je om ze te vermijden en ervoor te zorgen dat je markup geldig en effectief is. Syntaxisfouten zijn het meest voorkomend—gebruik van rechte aanhalingstekens in plaats van kromme, ontbrekende komma’s tussen eigenschappen of onjuiste plaatsing van haakjes zorgen ervoor dat het hele JSON-LD-blok niet geldig is. Veel ontwikkelaars kopiëren JSON-LD-code vanuit Microsoft Word of andere tekstverwerkers, die automatisch rechte aanhalingstekens omzetten naar kromme, wat de syntaxis breekt. Gebruik altijd een platte teksteditor of code-editor bij het werken met JSON-LD.
Verkeerd of niet-bestaand vocabulaire gebruiken is een andere kritische fout. Schema.org heeft specifieke eigenschapsnamen en types, en het gebruik van variaties of spelfouten zorgt ervoor dat zoekmachines je markup negeren. Bijvoorbeeld, “authorName” gebruiken in plaats van het juiste geneste “author”-object met een “name”-eigenschap wordt niet herkend. Raadpleeg altijd schema.org om de exacte eigenschapsnamen en vereiste structuur voor je gekozen schematype te verifiëren.
Onjuiste of misleidende data is vooral problematisch omdat dit in strijd is met Google’s beleid voor gestructureerde data. Je JSON-LD-markup moet de zichtbare inhoud op je pagina correct weerspiegelen. Als je pagina een productprijs van €29,99 weergeeft, moet je JSON-LD dezelfde prijs tonen—niet een andere prijs of een prijsklasse. Het markeren van inhoud die niet op de pagina bestaat (zoals beoordelingssterren toevoegen als er geen beoordelingen zichtbaar zijn) wordt als misleidend beschouwd en kan leiden tot handmatige acties tegen je site.
Formatteringsfouten ontstaan vaak wanneer ontwikkelaars JSON-LD handmatig opstellen zonder goede validatie. Ontbrekende sluitende accolades, niet-afgesloten strings of onjuist geformatteerde arrays veroorzaken validatiefouten. Gebruik altijd Google’s Rich Results Test of de Markup Validator van Schema.org om je implementatie te controleren voordat je deze live zet.
Met correcte implementatie van JSON-LD kunnen je pagina’s verschijnen als rich results in Google Search—zoekresultaten die zijn verrijkt met extra visuele elementen en informatie bovenop de standaardtitel, URL en metabeschrijving. Rich results kunnen sterbeoordelingen, prijsinformatie, productafbeeldingen, evenementdetails, FAQ-uitklapsecties, broodkruimelnavigatie en meer bevatten. De visuele aantrekkingskracht van rich results maakt ze aanzienlijk aantrekkelijker: uit onderzoek blijkt dat rich results de doorklikratio met 30% of meer kunnen verhogen ten opzichte van standaard zoekresultaten.
Google ondersteunt meer dan 32 verschillende soorten rich results, elk met specifieke schema-eisen. Review-snippets tonen sterbeoordelingen en reviewaantallen en vergroten geloofwaardigheid en vertrouwen. Product rich results tonen prijzen, beschikbaarheid en beoordelingen direct in de zoekresultaten, zodat gebruikers aankoopbeslissingen kunnen nemen zonder je site te bezoeken. FAQ rich results tonen vragen en antwoorden in uitklapbare secties, ideaal om featured snippets en “Mensen vragen ook”-mogelijkheden te grijpen. Event rich results tonen evenementdatums, locaties en ticketinformatie, zodat gebruikers je evenementen eenvoudig kunnen ontdekken en bijwonen. Artikel rich results tonen auteursinformatie, publicatiedatum en uitgelichte afbeeldingen, wat autoriteit en actualiteit signaleert.
Voor lokale bedrijven maakt LocalBusiness-schema het mogelijk dat je bedrijfsinformatie verschijnt in lokale zoekresultaten en Google Maps, inclusief je adres, telefoonnummer, openingstijden en klantbeoordelingen. Job posting-schema maakt je vacatures geschikt om te verschijnen in de Google vacaturezoekfunctie, met een prominente plaats bovenaan de zoekresultaten. Elk van deze rich result-types vereist een specifieke JSON-LD-implementatie, maar de investering betaalt zich uit in zichtbaarheid en gebruikersbetrokkenheid.
De opkomst van AI-gestuurde zoekmachines heeft het belang van gestructureerde data fundamenteel veranderd. Google AI Overviews, ChatGPT Search, Perplexity AI en Claude Search vertrouwen allemaal op het begrijpen van je inhoud om te bepalen of ze deze citeren in hun antwoorden. Hoewel deze AI-systemen JSON-LD niet op exact dezelfde manier parseren als traditionele zoekmachines, vergroot gestructureerde data aanzienlijk je kans om opgenomen te worden in AI-gegenereerde antwoorden. Google’s documentatie geeft expliciet aan dat AI Overviews informatie halen uit “een reeks bronnen, inclusief informatie van het web,” en pagina’s met duidelijke, goed gestructureerde markup worden vaker geselecteerd als bron.
ChatGPT Search gebruikt de Bing-index als bron, wat betekent dat je Bing-geïndexeerde pagina’s met correcte schema-markup kans maken om als bron voor ChatGPT-antwoorden te dienen. Perplexity AI is een generatieve vraag-en-antwoordmachine die webbronnen noemt in de antwoorden, en profiteert duidelijk van gestructureerde data die je content makkelijker identificeerbaar maakt. Claude Search, geïntroduceerd begin 2025, haalt realtime informatie van geïndexeerde sites en biedt directe bronvermeldingen, waarmee gestructureerde data cruciaal wordt voor zichtbaarheid. De rode draad bij al deze AI-systemen is dat ze voorkeur geven aan content die duidelijk, gezaghebbend en goed geannoteerd is met gestructureerde data.
Met JSON-LD transformeer je je website tot een machineleesbare kennisgrafiek waar AI-systemen op kunnen terugvallen voor onderbouwde, contextuele informatie. Dit is vooral belangrijk voor FAQ- en HowTo-schema, die direct antwoorden geven in een formaat dat AI-systemen eenvoudig kunnen oppikken en citeren. Door semantische JSON-LD te gebruiken om je content-kennisgrafiek te ontwikkelen, creëer je AI-zoekklare content die meer kans heeft om te worden getoond in gegenereerde antwoorden op verschillende platforms.
Succesvolle JSON-LD-implementatie vereist het volgen van beproefde best practices, zodat je markup geldig, onderhoudbaar en effectief is voor zowel zoekmachines als AI-systemen. Gebruik uitsluitend JSON-LD voor nieuwe implementaties, aangezien Google het aanbeveelt boven Microdata en RDFa. Plaats je JSON-LD in een <script type="application/ld+json">-tag, doorgaans in de <head>-sectie, hoewel het overal in het document mag staan. Deze plaatsing houdt je gestructureerde data gescheiden van zichtbare HTML, waardoor het eenvoudiger te beheren is en minder snel breekt bij HTML-wijzigingen.
Kies relevante schematypen die precies overeenkomen met je inhoud. Forceer geen schematypen op content waar ze niet voor bedoeld zijn—gebruik FAQPage alleen op echte FAQ-pagina’s, HowTo alleen bij stapsgewijze handleidingen en Product-schema alleen op productpagina’s. Onjuist gebruik van schematypen is in strijd met de richtlijnen van Google en kan leiden tot handmatige acties. Valideer je markup met de Google Rich Results Test vóór livegang. Deze gratis tool controleert je JSON-LD op syntaxisfouten en laat zien voor welke rich result-typen je pagina in aanmerking komt. Controleer na livegang je gestructureerde data met het Rich Results-rapport in Google Search Console om te zorgen dat je markup geldig blijft.
Richt je op verplichte en aanbevolen eigenschappen in plaats van proberen elke mogelijke eigenschap in te vullen. Google’s documentatie benadrukt dat het beter is minder maar complete en correcte aanbevolen eigenschappen te gebruiken dan alle mogelijke eigenschappen met onvolledige of onjuiste data. Zorg er op een productpagina bijvoorbeeld voor dat je accurate prijs, beschikbaarheid en minimaal één hoogwaardige afbeelding hebt voordat je optionele eigenschappen toevoegt zoals verzenddetails of garantie-informatie.
Houd je data actueel en gesynchroniseerd met de zichtbare pagina-inhoud. Je JSON-LD moet weergeven wat gebruikers daadwerkelijk op de pagina zien. Als je productprijzen, reviewaantallen of evenementdatums wijzigt, pas je JSON-LD dan direct aan. Verouderde of onjuiste gestructureerde data schaadt het vertrouwen en kan handmatige acties uitlokken. Implementeer dynamisch waar nodig met JavaScript, wat door JSON-LD beter wordt ondersteund dan door andere formaten. Als je content via JavaScript-frameworks wordt geladen, kan JSON-LD nog steeds in de DOM worden geïnjecteerd en door zoekmachines worden herkend.
Het valideren van je JSON-LD-implementatie is essentieel voor en na livegang. Google’s Rich Results Test is de belangrijkste tool om JSON-LD op geldigheid te controleren en te bepalen voor welke rich result-typen je pagina in aanmerking komt. Plak simpelweg je URL of JSON-LD-code in de tool en deze geeft eventuele fouten, waarschuwingen of ontbrekende aanbevolen eigenschappen aan. De test geeft gedetailleerde feedback over wat goed gaat en wat verbetering behoeft.
Schema.org’s Markup Validator biedt schema-onafhankelijke validatie zonder Google-specifieke waarschuwingen, handig om te beoordelen of je markup voldoet aan schema.org, los van Google’s eisen. Het Rich Results-rapport in Google Search Console monitort de prestaties van je gestructureerde data op je site in de tijd, toont welke pagina’s geldige markup hebben en welke rich result-typen verschijnen in de zoekresultaten. Deze monitoring is cruciaal om na livegang fouten op te sporen, bijvoorbeeld als template-aanpassingen je JSON-LD per ongeluk breken.
Structured data testing tools zoals BrightEdge’s SearchIQ kunnen de schema-implementaties van je concurrenten analyseren en laten zien welke schematypen het meest voorkomen in jouw branche, zodat je weet welke markup je het eerst moet implementeren. Deze inzichten helpen om de meest impactvolle schema’s voor jouw niche te kiezen.
Verschillende contenttypes vereisen verschillende schema-implementaties, elk met specifieke verplichte en aanbevolen eigenschappen. Artikel-schema is essentieel voor blogposts en nieuwscontent, en vereist headline, author, datePublished en image. Door dateModified toe te voegen signaleer je actualiteit, terwijl articleBody extra context kan bieden. Product-schema vereist minimaal name, image en description, met aanbevolen eigenschappen zoals prijs, beschikbaarheid en aggregateRating. Voor e-commerce-websites verbeteren gedetailleerde Offer- en Review-objecten de kans op rich results aanzienlijk.
FAQ-schema (FAQPage) is krachtig om featured snippets en “Mensen vragen ook”-mogelijkheden te grijpen. Het vereist een mainEntity-array van Question-objecten, elk met acceptedAnswer-eigenschappen. HowTo-schema werkt vergelijkbaar, met stapsgewijze instructies gemarkeerd met HowToStep-objecten. Event-schema vereist name, startDate en location, met aanbevolen eigenschappen als description, image en performer-informatie. LocalBusiness-schema is essentieel voor fysieke bedrijven en vereist name, address, telephone en openingstijden.
Recipe-schema vereist name, image, recipeIngredient en recipeInstructions, met aanbevolen eigenschappen zoals prepTime, cookTime, recipeYield en voedingsinformatie. Organization-schema moet sitebreed worden toegepast om je merkidentiteit te vestigen, inclusief name, logo, contactinformatie en socialmediaprofielen. Het implementeren van meerdere schematypen op één pagina is gebruikelijk en wordt aangeraden—zo kan een artikelpagina tegelijk Article-, Organization- en Author (Person)-schema bevatten.
De koers van gestructureerde data is duidelijk: naarmate AI-zoekmachines volwassen worden en aan terrein winnen, zal gestructureerde data steeds centraler komen te staan voor webzichtbaarheid. Zoekmachines en AI-systemen bewegen richting een semantische laag, waarbij gestructureerde data de basis biedt die generatieve modellen nodig hebben om accurate, verifieerbare antwoorden te produceren. Deze verschuiving betekent dat investeren in JSON-LD vandaag niet alleen gaat om traditionele SEO—het draait om het bouwen van het semantische fundament waar toekomstige AI-tools op vertrouwen.
We kunnen verwachten dat de schema.org-vocabulaire wordt uitgebreid met nieuwe types en eigenschappen, speciaal ontworpen voor AI-toepassingen. Opkomende schematypen zoals QAPage, Speakable en sector-specifieke schema’s bieden steeds fijnmazigere manieren om content te annoteren voor AI-consumptie. De integratie van gestructureerde data met kennisgrafieken wordt dieper, zodat AI-systemen niet alleen individuele pagina’s, maar ook relaties tussen entiteiten binnen je hele website en het bredere web begrijpen. Voor digitale marketeers en SEO-professionals blijft gestructureerde data daarom een strategische prioriteit. Organisaties die vandaag uitgebreide, accurate JSON-LD-markup implementeren, hebben straks een groot voordeel wanneer AI-zoekopdrachten verder groeien en marktaandeel winnen van traditionele zoekmachines.
De samensmelting van traditionele SEO en AI-zichtbaarheid via gestructureerde data betekent een fundamentele verandering in hoe websites met machines communiceren. Door nu JSON-LD-implementatie te beheersen, maak je je digitale aanwezigheid toekomstbestendig voor het AI-zoeklandschap dat zich al aan het ontvouwen is.
Volg hoe je gestructureerde data verschijnt in AI-aangedreven zoekresultaten zoals Google AI Overviews, ChatGPT, Perplexity en Claude. AmICited monitort de zichtbaarheid van je domein op alle grote AI-platforms.
JSON-LD is een door W3C gestandaardiseerd formaat voor gestructureerde gegevens dat JSON-syntaxis gebruikt voor schema.org-markup. Ontdek hoe JSON-LD SEO verbet...

Communitydiscussie over JSON-LD-implementatie voor AI-zoekzichtbaarheid. Ontwikkelaars en SEO's delen hoe gestructureerde data AI-citaties beïnvloeden en best p...
Leer hoe u Organization schema markup implementeert voor AI-zichtbaarheid. Stapsgewijze gids voor het toevoegen van JSON-LD gestructureerde data, het verbeteren...
Cookie Toestemming
We gebruiken cookies om uw browse-ervaring te verbeteren en ons verkeer te analyseren. See our privacy policy.