Paginering
Paginering verdeelt grote inhoudssets in beheersbare pagina's voor betere UX en SEO. Leer hoe paginering werkt, de impact op zoekresultaten en best practices vo...
9 min lezen

Leer hoe paginering AI-zichtbaarheid beïnvloedt. Ontdek waarom traditionele pagina-indeling AI-systemen helpt jouw content te vinden, terwijl oneindig scrollen deze juist verbergt, en hoe je paginering optimaliseert voor AI-antwoordgeneratoren.
Paginering is het opdelen van grote inhoudssets in meerdere gekoppelde pagina's. Ja, het heeft aanzienlijke invloed op AI-systemen—paginering creëert afzonderlijke, doorzoekbare URL's die AI-zoekmachines zoals ChatGPT, Perplexity en Google's SGE helpen jouw content effectiever te ontdekken en te indexeren, terwijl implementaties met oneindig scrollen vaak inhoud verbergen voor AI-crawlers.
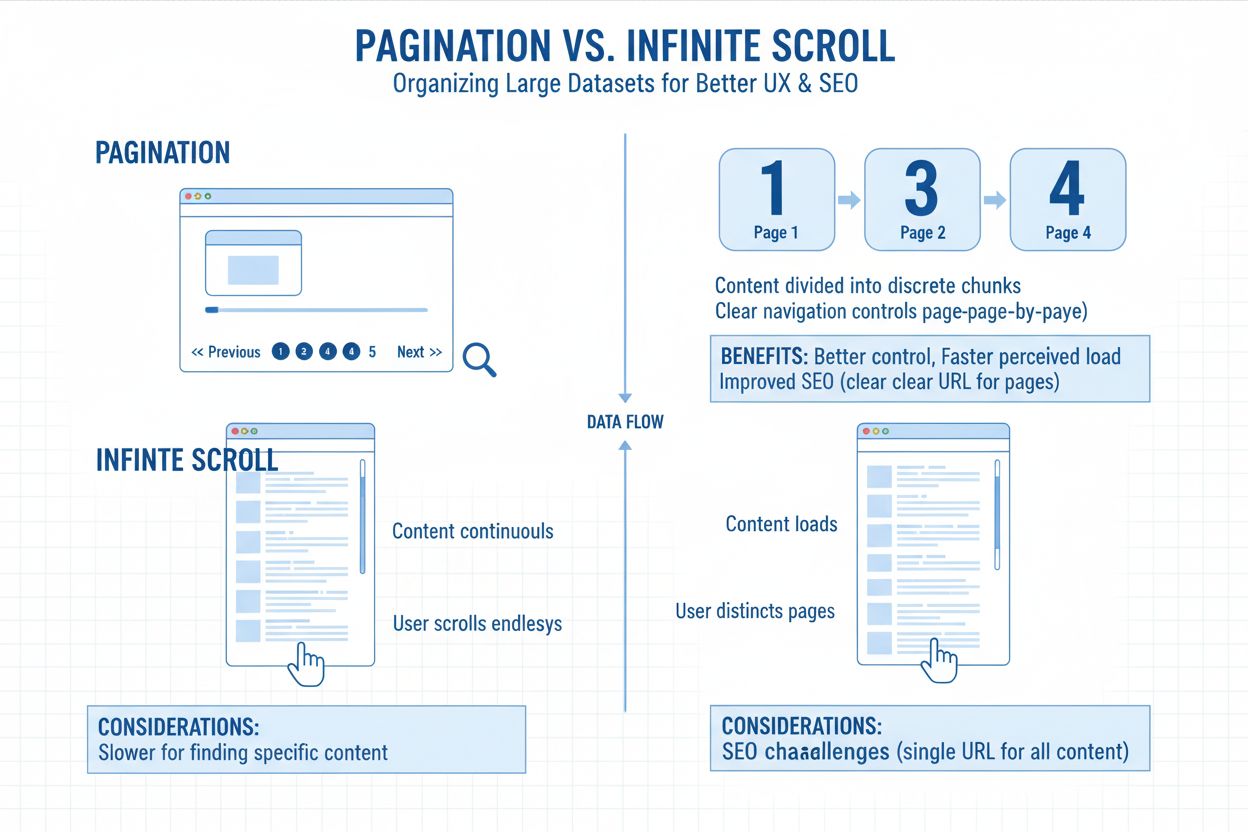
Paginering verwijst naar het opdelen van grote hoeveelheden content in meerdere gekoppelde pagina’s, in plaats van alles op één eindeloze pagina te tonen. Zie het als hoofdstukken in een boek—elke pagina bevat een beheersbaar deel van de totale inhoud, verbonden via genummerde links of “volgende/vorige” knoppen. Deze structuur zie je overal terug, van productoverzichten in webshops tot blogarchieven, forumberichten en zoekresultaten. De URL-structuur weerspiegelt deze indeling vaak via parameters als ?page=2 of nette paden zoals /categorie/pagina/2/, zodat zowel gebruikers als zoekmachines hun positie binnen de contentreeks begrijpen. Paginering is een fundamenteel hulpmiddel om balans te vinden tussen gebruikerservaring en technische eisen voor toegankelijkheid van content.
Websites implementeren paginering vooral voor prestatie-optimalisatie en contentorganisatie. Honderden of duizenden items tegelijk laden zou servers overbelasten en zorgt voor trage laadtijden, wat de prestaties schaadt en zo ook de zoekrangschikking beïnvloedt. Gebruikers waarderen het om specifieke pagina’s te kunnen bookmarken, direct naar pagina 10 te springen, of te zien hoeveel content er nog beschikbaar is. Vanuit technisch oogpunt creëert het opdelen in pagina’s afzonderlijke URL’s die zoekmachines individueel kunnen indexeren, waardoor linkwaarde beter over je site wordt verdeeld. Deze duidelijkheid in structuur wordt steeds belangrijker naarmate AI-systemen beter begrijpen hoe content samenhangt en toegankelijk is.
De relatie tussen paginering en AI-zichtbaarheid is een van de belangrijkste technische SEO-overwegingen in het moderne zoeklandschap. Traditionele zoekmachines zoals Google begrijpen paginering al lange tijd door links te crawlen en sequentiële pagina’s te volgen. Maar AI-aangedreven zoekmachines en antwoordgeneratoren werken fundamenteel anders en vereisen een meer genuanceerde benadering van contentorganisatie. Grote taalmodellen zoals die achter ChatGPT, Perplexity en Google’s Search Generative Experience (SGE) crawlen pagina’s namelijk niet per se lineair of volgens traditionele navigatiehiërarchieën. Ze werken door tekstuele input te tokenizen en samen te vatten—vaak afkomstig uit openbare data, API’s of gestructureerde databases, niet uit dieptecrawls.
Wanneer jouw content verspreid is over meerdere, minimaal gestructureerde pagina’s, kunnen AI-engines dieper gelegen items overslaan of hun relatie met de bredere contentset verkeerd begrijpen. Als er weinig variatie is in metadata of zwakke semantische signalen, lijkt jouw gepagineerde content overbodig—of wordt deze helemaal overgeslagen. Dat zorgt voor een groot zichtbaarheidstekort: content die goed scoort in traditionele Google-zoekresultaten kan volledig onzichtbaar blijven voor AI-antwoordgeneratoren. Dat verschil is belangrijk, want AI-systemen geven de voorkeur aan gestructureerde, volledige en eenvoudig opvraagbare data. Ze “scrollen” niet als een gebruiker, maar parseren code, URL’s en metadata om content snel en nauwkeurig samen te vatten of te citeren. Als jouw pagina geen content toont via crawlbare URL’s of rijke metadata, kan AI deze niet opnemen in gegeneerde antwoorden.
De keuze tussen traditionele paginering en oneindig scrollen is bepalend geworden voor de vindbaarheid van content door AI. Oneindig scrollen laadt content pas via JavaScript na gebruikersinteractie, wat leidt tot een fundamenteel toegankelijkheidsprobleem voor AI-crawlers. De meeste infinite scroll-implementaties tonen geen content via afzonderlijke URL’s—alles laadt op één pagina via dynamische JavaScript-uitvoering. AI-crawlers, die geen echt gebruikersgedrag zoals scrollen of klikken nabootsen, missen daardoor alles buiten het eerste scherm. Als jouw pagina die extra content niet via crawlbare URL’s of metadata aanbiedt, kan AI die niet vinden. Je kunt 200 artikelen, 300 producten of tientallen casestudy’s hebben, maar als ze verborgen zijn achter JavaScript-triggers, ziet de AI er misschien maar 12. Of zelfs minder.
Traditionele paginering wint nog steeds overtuigend voor AI-indexering omdat het schone, doorzoekbare URL’s oplevert (bijvoorbeeld /blog/pagina/4), waardoor engines jouw content volledig kunnen ontdekken en segmenteren. Het geeft structuur aan je onderwerpen via interne links, met standaardlinks als “Volgende pagina” of “Vorige pagina”, zodat engines begrijpen hoe content samenhangt. Paginering beperkt afhankelijkheid van JavaScript, waardoor jouw content altijd laadt voor crawlers, ongeacht hoe een gebruiker de pagina gebruikt. Deze heldere structuur vertaalt zich direct naar betere AI-zichtbaarheid—wanneer ChatGPT of Perplexity jouw site crawlt, kunnen ze gepagineerde content veel effectiever ontdekken en indexeren dan content die verborgen is achter infinite scroll.
| Aspect | Paginering | Oneindig scrollen |
|---|---|---|
| Crawl-toegankelijkheid | Unieke URL’s maken diepe indexering mogelijk | Content vaak verborgen achter JS-ladingen |
| AI-vindbaarheid | Meerdere pagina’s kunnen onafhankelijk ranken | Doorgaans slechts één pagina geïndexeerd |
| Gestructureerde data | Makkelijk toe te wijzen per pagina | Vaak afwezig of verwaterd |
| Directe links | Makkelijk naar specifieke content linken | Moeilijk om diepe links te maken |
| Sitemap-compatibiliteit | Compatibel en volledig | Laat vaak diepe content buiten beschouwing |
| URL-structuur | Duidelijke, unieke URL’s per pagina | Eén URL met dynamische lading |
| Contentzichtbaarheid | Alle content toegankelijk voor crawlers | Content vereist JS-uitvoering |
De technische architectuur van infinite scroll vormt fundamentele barrières voor AI-contentontdekking. Als content alleen via JavaScript laadt en geen URL’s die nieuwe content weerspiegelen, ziet een AI-engine het simpelweg niet. Voor een crawler bestaat de rest van jouw lijst niet. Dit is geen beperking van AI-systemen—het is het gevolg van de manier waarop infinite scroll meestal wordt geïmplementeerd. De meeste infinite scroll-oplossingen stellen de gebruikerservaring boven technische toegankelijkheid, door content dynamisch te laden zonder bijbehorende URL’s of metadata die AI-systemen kunnen lezen.
Een praktijkvoorbeeld: een wereldwijde modewinkel vernieuwde haar site met een strakke infinite scroll-interface. De laadsnelheid verbeterde, engagementmetrics zagen er goed uit, maar het verkeer uit AI-samenvattingen daalde drastisch. Hun artikelen leken te verdwijnen uit conversatiezoektools. Na een architectuuraudit werd duidelijk: de hele catalogus zat verborgen achter infinite scroll zonder doorzoekbare alternatieven. Geen secundaire pagina-URL’s. Geen aanvullende links. Gewoon één lange, onzichtbare productlijst. Google SGE en ChatGPT konden niets na de eerste dozijn producten per categorie vinden. Hoe mooi de site er ook uitzag, voor AI-systemen was de vindbaarheid kapot.
Juiste implementatie van paginering vraagt aandacht voor verschillende technische factoren die samen bepalen of AI-systemen jouw content kunnen vinden en citeren. De basis begint bij schone, logische URL-structuren die de volgorde duidelijk aangeven. Of je nu queryparameters (?page=2) of padstructuren (/pagina/2/) gebruikt, consistentie is belangrijker dan het exacte formaat. Beide werken even goed voor AI-systemen mits goed geïmplementeerd. Het gaat erom dat elke gepagineerde URL unieke content laadt en bereikbaar is via standaard HTML-links, zonder dat JavaScript nodig is.
Zelfverwijzende canonical tags zijn cruciaal in je pagineringsstrategie. Elke gepagineerde pagina moet een canonical tag bevatten die naar zichzelf verwijst, zodat elke pagina als de voorkeursversie van zichzelf wordt gezien. Zo behouden sequentiële URL’s hun onafhankelijkheid en kunnen ze zelfstandig ranken op basis van hun specifieke content en relevantie. Vermijd de ouderwetse praktijk om alle gepagineerde pagina’s naar pagina één te canonicaliseren—dit bundelt signalen, maar voorkomt dat individuele pagina’s onafhankelijk kunnen ranken in AI-systemen. Door alles naar pagina één te canonicaliseren, geef je AI-systemen expliciet het signaal waardevolle pagina’s met unieke producten, content of informatie te negeren.
Unieke metadata voor elke pagina is essentieel voor AI-zichtbaarheid. Gebruik geen generieke titels als “Pagina 2” of herhaalde beschrijvingen. Schrijf juist pagina-specifieke, zoekwoordrijke metadata die de focus van elke pagina weergeeft. Bijvoorbeeld, in plaats van “Producten - Pagina 2” gebruik je “Dames sportschoenen onder €100 - Pagina 2” of “AI-trends in retail – casusarchief (pagina 2).” Deze duidelijkheid vergroot de zichtbaarheid, omdat AI-systemen context begrijpen en beter kunnen bepalen wanneer jouw content relevant is voor specifieke vragen. Elk metadatasegment moet voldoen aan de eisen van helderheid, uniciteit en zoekwoordafstemming. Het doel is dat het doel van elke pagina duidelijk is voor zowel AI-systemen als menselijke lezers.
Interne linkarchitectuur bepaalt of AI-systemen sequentiële pagina’s kunnen vinden en efficiënt kunnen doorlopen. Een lineaire structuur (pagina 1 → 2 → 3) creëert lange crawl-paden waarbij diepe pagina’s veel klikken van de homepage verwijderd zijn en zo onopgemerkt kunnen blijven. Slimme implementaties bevatten aanvullende links zoals “Bekijk alles”-opties of categoriehubs die direct naar belangrijke pagina’s linken, zodat crawl-diepte afneemt en linkwaarde gelijkmatiger wordt verdeeld. De relatie tussen gefacetteerde navigatie en sequentiële pagina’s voegt extra complexiteit toe, omdat filtercombinaties duizenden URL-variaties kunnen opleveren. Goede interne linkstructuur zorgt dat prioriteitspagina’s voldoende aandacht krijgen van crawlers, terwijl minder belangrijke combinaties via noindex-tags of canonieke signalen worden gedeprioriteerd.
Strategische interne linkketens van hoofdpagina’s naar specifieke gepagineerde pagina’s leiden AI-systemen door jouw contentstructuur. Link vanaf je hoofdcategoriepagina direct naar specifieke gepagineerde pagina’s met ankertekst die AI helpt de context te begrijpen. Bijvoorbeeld: “Ontdek meer e-commerce succesverhalen in onze casestudy-serie – pagina 3.” Maak het signaal betekenisvol en gemakkelijk vindbaar. Zo leren AI-systemen hoe jouw content samenhangt en ontdekt moet worden. Wanneer AI-crawlers deze contextuele links volgen, begrijpen ze de relatie tussen pagina’s en kunnen ze beter bepalen welke content het meest relevant is voor specifieke zoekopdrachten.
Problemen met dubbele content ontstaan wanneer meerdere URL’s identieke of vrijwel identieke inhoud tonen zonder duidelijke verschillen. Dit gebeurt als sequentiële pagina’s geen unieke elementen bevatten behalve de lijstitems, of wanneer URL-parameters meerdere paden naar dezelfde content genereren. Zoekmachines en AI-systemen weten dan niet welke versie ze moeten ranken, wat de zichtbaarheid over meerdere URL’s kan versnipperen. Daarnaast, als gepagineerde pagina’s vooral standaardteksten, headers en footers bevatten met weinig unieke inhoud, kunnen ze als “dunne” pagina’s worden gezien. Oplossen doe je met zorgvuldige canonical tags, unieke metabeschrijvingen per pagina en voldoende unieke waarde per pagina buiten navigatie- en sjabloonelementen.
Alleen-JavaScript-implementaties zijn misschien wel de meest voorkomende fout waardoor content voor AI-systemen verborgen blijft. Als jouw site frameworks als React of Angular gebruikt om de paginering clientside te renderen zonder server-side rendering, ontdekken AI-crawlers mogelijk nooit content na pagina één. Zorg ervoor dat navigatielinks aanwezig zijn in de initiële HTML die AI-systemen ontvangen, en niet alleen via JavaScript na het laden van de pagina. Gebruik progressieve verbetering—basis HTML-links die JavaScript kan verrijken met soepelere interacties en animaties. Test je implementatie met tools die tonen wat crawlers zien versus wat browsers met JavaScript tonen. Zo ontdek je gaten in crawlbaarheid die je AI-zichtbaarheid kunnen kosten.
Het volgen van de effectiviteit van paginering vraagt om monitoring van hoe AI-systemen omgaan met jouw meerpagina’s-content. Anders dan bij traditionele SEO, waar Google Search Console directe inzichten biedt, vraagt AI-zichtbaarheid om andere methoden. Tools als Screaming Frog SEO Spider kunnen je site crawlen op een manier die lijkt op hoe AI-systemen dat zouden doen, zodat je pagineringstructuren en verweesde pagina’s of crawl-diepteproblemen kunt identificeren. DeepCrawl en Sitebulk bieden geavanceerde analyses en visualisatie van pagerelaties. Google Search Console geeft inzichten vanuit Google, zoals welke gepagineerde URL’s worden geïndexeerd en hoe vaak ze worden gecrawld.
Belangrijke prestatie-indicatoren voor gepagineerde content zijn onder andere of diepe pagina’s voorkomen in AI-antwoordteksten, hoe vaak AI-systemen jouw gepagineerde content citeren, en of verschillende pagina’s ranken op verschillende longtail-zoekopdrachten. Monitor je merkvermeldingen in AI-antwoorden—als AI-systemen consequent alleen jouw eerste pagina noemen en nooit diepere pagina’s, moet je je pagineringsstructuur optimaliseren. Houd bij welke gepagineerde pagina’s het meeste verkeer uit AI-bronnen genereren. Deze data laten zien of je pagineringsstrategie content effectief blootstelt aan AI-systemen, of dat herstructurering nodig is. Regelmatige audits signaleren problemen voordat ze de zichtbaarheid beïnvloeden, zeker na site-updates of frameworkmigraties.
Het landschap van AI-gestuurde zoekoplossingen ontwikkelt zich razendsnel, met nieuwe systemen en mogelijkheden die voortdurend ontstaan. Pagineringsstrategieën die nu werken, blijven waarschijnlijk effectief naarmate AI-systemen geavanceerder worden, maar voorop blijven lopen vereist inzicht in opkomende trends. AI-gestuurde zoekalgoritmen worden steeds beter in het begrijpen van contentrelaties en bepalen welke gepagineerde pagina’s prioriteit voor indexering verdienen. Google’s neural matching en BERT-gebaseerde algoritmes helpen zoekmachines te herkennen dat pagina twee van een categorie andere producten biedt dan pagina één, zelfs als de omliggende tekst grotendeels gelijk is. Deze verbeterde interpretatie betekent dat goed gestructureerde paginering met duidelijke verschillen tussen pagina’s nu meer dan ooit profiteert van onafhankelijke indexering.
Tegelijkertijd herkent AI ook beter echt dunne of dubbele content op gepagineerde pagina’s, waardoor het moeilijker wordt om het systeem te “bespelen” met nauwelijks verschillende pagina’s. Machine learning-algoritmes voorspellen gebruikersintentie nauwkeuriger en tonen diepe paginering voor specifieke longtail-zoekopdrachten wanneer deze het beste aansluiten bij de zoekintentie. De praktische implicatie is: zorg dat elke gepagineerde pagina écht unieke waarde biedt—onderscheidende producten, andere content, of betekenisvolle variaties—en niet slechts mechanische opdelingen van identieke informatie. Terwijl AI-systemen zich blijven ontwikkelen, blijven de kernprincipes onveranderd: unieke URL’s, crawlbare links, unieke waarde per pagina en heldere metadata blijven bepalend voor de effectiviteit van paginering voor AI-zichtbaarheid.
Volg hoe jouw content verschijnt in AI-gegenereerde antwoorden op ChatGPT, Perplexity en andere AI-zoekmachines. Zorg dat jouw merk wordt geciteerd wanneer AI-systemen vragen over jouw branche beantwoorden.
Paginering verdeelt grote inhoudssets in beheersbare pagina's voor betere UX en SEO. Leer hoe paginering werkt, de impact op zoekresultaten en best practices vo...
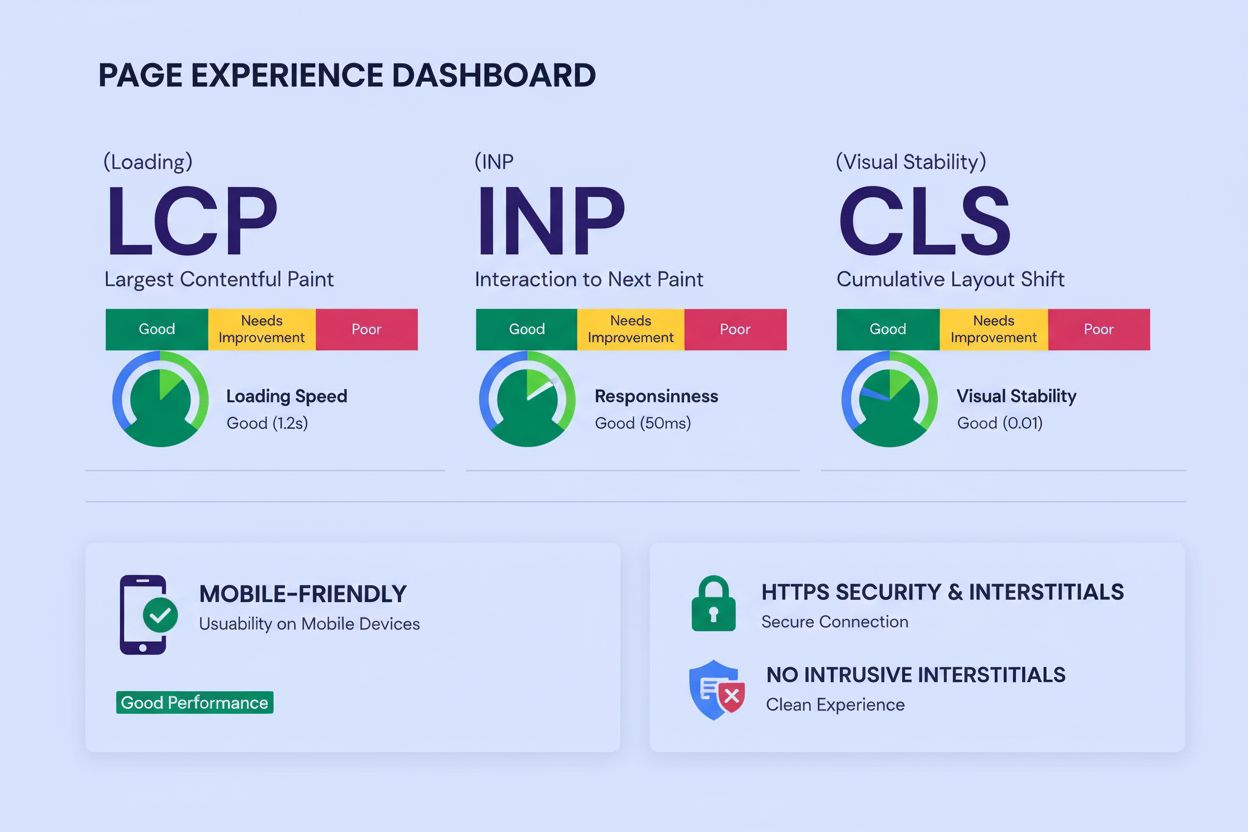
Pagina-ervaring meet de kwaliteit van gebruikersinteractie via Core Web Vitals, mobielvriendelijkheid, HTTPS-beveiliging en opdringerige interstitials. Ontdek h...

Pagina snelheid meet hoe snel een webpagina laadt. Leer over Core Web Vitals, waarom pagina snelheid belangrijk is voor SEO en conversies, en hoe je de laadtijd...
Cookie Toestemming
We gebruiken cookies om uw browse-ervaring te verbeteren en ons verkeer te analyseren. See our privacy policy.