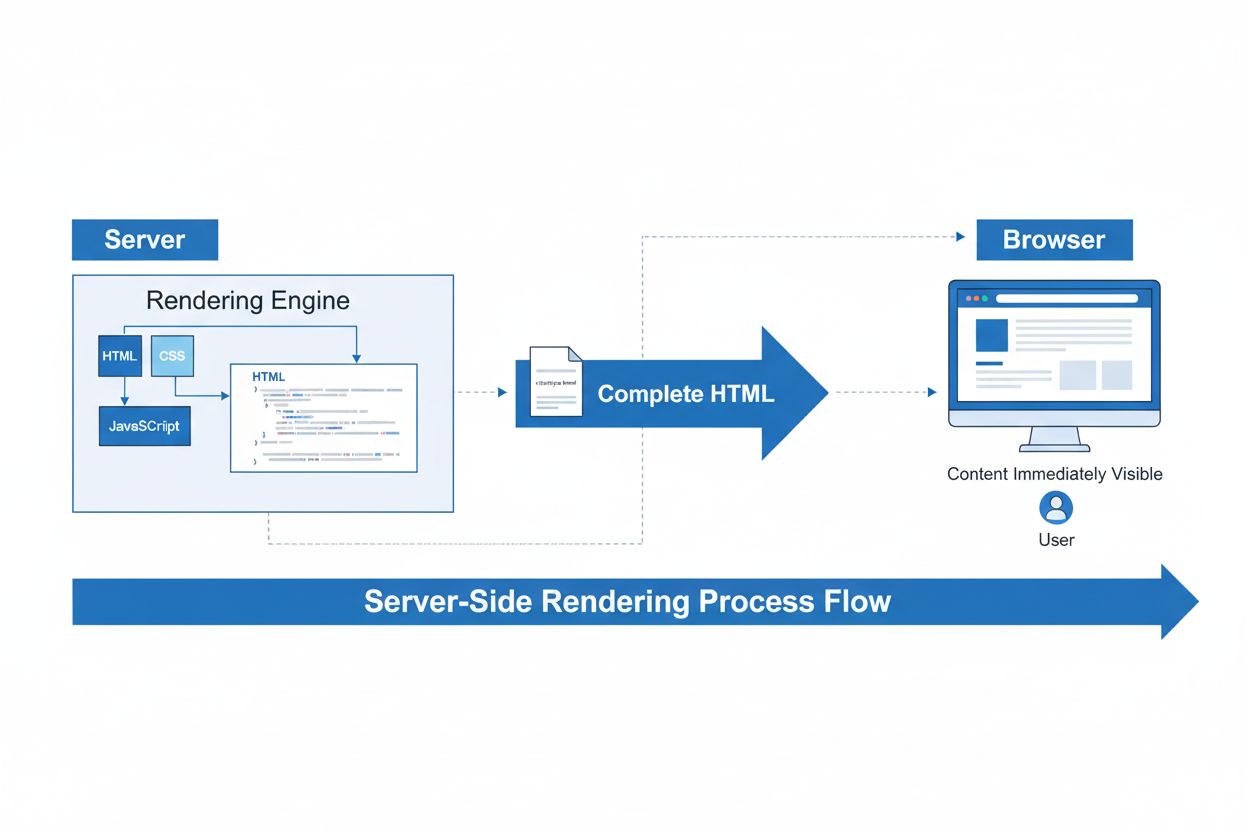
Server-Side Rendering (SSR)
Server-Side Rendering (SSR) is een webtechniek waarbij servers complete HTML-pagina's renderen voordat ze naar browsers worden gestuurd. Leer hoe SSR SEO, pagin...
11 min lezen

Ontdek hoe server-side rendering efficiënte AI-verwerking, modeluitrol en realtime-inferentie mogelijk maakt voor AI-gedreven applicaties en LLM-workloads.
Server-side rendering voor AI is een architecturale benadering waarbij kunstmatige intelligentiemodellen en inferentieverwerking op de server plaatsvinden in plaats van op clientapparaten. Dit maakt efficiënte afhandeling van rekenintensieve AI-taken mogelijk, garandeert consistente prestaties bij alle gebruikers en vereenvoudigt het uitrollen en bijwerken van modellen.
Server-side rendering voor AI verwijst naar een architectuurpatroon waarbij kunstmatige intelligentiemodellen, inferentieverwerking en rekentaken op back-endservers worden uitgevoerd in plaats van op clientapparaten zoals browsers of mobiele telefoons. Deze aanpak verschilt fundamenteel van traditionele client-side rendering, waarbij JavaScript in de browser van de gebruiker draait om content te genereren. In AI-toepassingen betekent server-side rendering dat grote taalmodellen (LLM’s), machine learning-inferentie en AI-gedreven contentgeneratie centraal plaatsvinden op krachtige serverinfrastructuur voordat de resultaten naar gebruikers worden gestuurd. Deze architecturale verschuiving is steeds belangrijker geworden naarmate AI-capaciteiten rekenintensiever en centraler zijn geworden voor moderne webapplicaties.
Het concept ontstond uit het besef dat er een kritische mismatch is tussen wat moderne AI-toepassingen vereisen en wat clientapparaten realistisch kunnen bieden. Traditionele webontwikkelingsframeworks zoals React, Angular en Vue.js maakten client-side rendering populair tijdens de jaren 2010, maar deze aanpak creëert aanzienlijke uitdagingen bij AI-intensieve workloads. Server-side rendering voor AI pakt deze uitdagingen aan door gebruik te maken van gespecialiseerde hardware, gecentraliseerd modelbeheer en geoptimaliseerde infrastructuur die clientapparaten simpelweg niet kunnen evenaren. Dit vormt een fundamentele paradigmaverschuiving in de manier waarop ontwikkelaars AI-gedreven applicaties ontwerpen.
De rekenvereisten van moderne AI-systemen maken server-side rendering niet alleen voordelig, maar vaak noodzakelijk. Clientapparaten, met name smartphones en budgetlaptops, missen het rekenvermogen om realtime AI-inferentie efficiënt uit te voeren. Wanneer AI-modellen op clientapparaten draaien, ervaren gebruikers merkbare vertragingen, verhoogd batterijverbruik en inconsistente prestaties afhankelijk van hun hardware. Server-side rendering elimineert deze problemen door AI-verwerking te centraliseren op infrastructuur uitgerust met GPU’s, TPU’s en gespecialiseerde AI-accelerators die een veelvoud aan prestaties leveren vergeleken met consumentapparaten.
Naast pure prestaties biedt server-side rendering voor AI belangrijke voordelen op het gebied van modelbeheer, beveiliging en consistentie. Wanneer AI-modellen op servers draaien, kunnen ontwikkelaars nieuwe versies direct updaten, fine-tunen en uitrollen zonder dat gebruikers updates hoeven te downloaden of lokaal verschillende modelversies beheren. Dit is vooral belangrijk voor grote taalmodellen en machine learning-systemen die zich snel ontwikkelen met frequente verbeteringen en beveiligingspatches. Bovendien voorkomt het houden van AI-modellen op servers ongeoorloofde toegang, modelextractie en diefstal van intellectueel eigendom die mogelijk worden als modellen naar clientapparaten worden verspreid.
| Aspect | Client-side AI | Server-side AI |
|---|---|---|
| Verwerkingslocatie | Browser of apparaat van gebruiker | Back-endservers |
| Hardwarevereisten | Beperkt tot apparaatmogelijkheden | Gespecialiseerde GPU’s, TPU’s, AI-accelerators |
| Prestaties | Variabel, afhankelijk van apparaat | Consistent, geoptimaliseerd |
| Modelupdates | Vereist downloads door gebruiker | Directe uitrol |
| Beveiliging | Modellen blootgesteld aan extractie | Modellen beschermd op servers |
| Latentie | Afhankelijk van apparaatkracht | Geoptimaliseerde infrastructuur |
| Schaalbaarheid | Beperkt per apparaat | Hoog schaalbaar over gebruikers heen |
| Ontwikkelcomplexiteit | Hoog (apparaatfragmentatie) | Lager (gecentraliseerd beheer) |
Netwerkoverhead en latentie vormen aanzienlijke uitdagingen in AI-toepassingen. Moderne AI-systemen vereisen constante communicatie met servers voor modelupdates, ophalen van trainingsdata en hybride verwerkingsscenario’s. Ironisch genoeg verhoogt client-side rendering het aantal netwerkverzoeken ten opzichte van traditionele applicaties, wat de prestatievoordelen die client-side verwerking zou moeten bieden, vermindert. Server-side rendering consolideert deze communicatie, vermindert round-trip vertragingen en maakt realtime AI-functies zoals live vertaling, contentgeneratie en computer vision-verwerking mogelijk zonder de latentieproblemen van client-side inferentie.
Synchronisatiecomplexiteit ontstaat wanneer AI-toepassingen gelijktijdig de status consistent moeten houden tussen meerdere AI-diensten. Moderne applicaties gebruiken vaak embedding-diensten, completion-modellen, fijn-afgestelde modellen en gespecialiseerde inferentie-engines die met elkaar moeten samenwerken. Het beheren van deze gedistribueerde status op clientapparaten introduceert aanzienlijke complexiteit en creëert kans op datainconsistentie, vooral bij realtime samenwerkingsfuncties op basis van AI. Server-side rendering centraliseert dit statusbeheer, zodat alle gebruikers consistente resultaten zien en de ontwikkelbelasting van complexe client-side status-synchronisatie verdwijnt.
Apparaatfragmentatie levert grote ontwikkeluitdagingen op voor client-side AI. Verschillende apparaten beschikken over uiteenlopende AI-mogelijkheden zoals Neural Processing Units, GPU-versnelling, WebGL-ondersteuning en geheugenbeperkingen. Consistente AI-ervaringen creëren in dit gefragmenteerde landschap vereist veel ontwikkelwerk, strategieën voor geleidelijke degradatie en meerdere codepaden voor verschillende apparaatmogelijkheden. Server-side rendering elimineert deze fragmentatie volledig door te zorgen dat alle gebruikers toegang hebben tot dezelfde geoptimaliseerde AI-verwerkingsinfrastructuur, ongeacht hun apparaat.
Server-side rendering maakt vereenvoudigde en beter onderhoudbare AI-applicatiearchitecturen mogelijk door kritieke functionaliteit te centraliseren. In plaats van AI-modellen en inferentielogica te verspreiden over duizenden clientapparaten, beheren ontwikkelaars één enkele, geoptimaliseerde implementatie op servers. Deze centralisatie biedt directe voordelen, zoals snellere uitrolcycli, eenvoudiger debuggen en directere prestatieoptimalisatie. Wanneer een AI-model moet worden verbeterd of een bug wordt ontdekt, lossen ontwikkelaars het eenmaal op de server op, in plaats van updates te moeten pushen naar miljoenen apparaten met verschillende adoptiegraad.
Resource-efficiëntie verbetert aanzienlijk met server-side rendering. Serverinfrastructuur maakt efficiënt delen van resources over alle gebruikers heen mogelijk, met connection pooling, cachingstrategieën en load balancing om hardware optimaal te benutten. Eén GPU op een server kan inferentieverzoeken van duizenden gebruikers achter elkaar verwerken, terwijl dezelfde capaciteit op clientapparaten miljoenen GPU’s zou vereisen. Deze efficiëntie vertaalt zich in lagere operationele kosten, minder milieubelasting en betere schaalbaarheid naarmate applicaties groeien.
Beveiliging en bescherming van intellectueel eigendom worden aanzienlijk eenvoudiger met server-side rendering. AI-modellen vertegenwoordigen grote investeringen in onderzoek, trainingsdata en rekenkracht. Door modellen op servers te houden, worden modelextractie-aanvallen, ongeautoriseerde toegang en diefstal van intellectueel eigendom voorkomen die mogelijk zijn als modellen naar clientapparaten worden verspreid. Bovendien maakt server-side verwerking fijngranulaire toegangscontrole, audit logging en compliance monitoring mogelijk, iets wat niet afdwingbaar is op verspreide clientapparaten.
Moderne frameworks zijn geëvolueerd om server-side rendering voor AI-workloads effectief te ondersteunen. Next.js loopt hierin voorop met Server Actions waarmee naadloze AI-verwerking direct vanuit servercomponenten mogelijk wordt. Ontwikkelaars kunnen AI-API’s aanroepen, grote taalmodellen verwerken en antwoorden terugstreamen naar clients met minimale boilerplate-code. Het framework beheert de complexiteit van server-clientcommunicatie, zodat ontwikkelaars zich kunnen richten op AI-logica in plaats van infrastructuur.
SvelteKit biedt een performance-first benadering van server-side AI-rendering met zijn load-functies die op de server uitvoeren vóór het renderen. Hiermee wordt AI-data vooraf verwerkt, aanbevelingen gegenereerd en AI-verrijkte content voorbereid voordat HTML naar de client wordt gestuurd. De resulterende applicaties hebben een minimale JavaScript-footprint, maar behouden volledige AI-functionaliteit, wat zorgt voor uitzonderlijk snelle gebruikerservaringen.
Gespecialiseerde tools zoals de Vercel AI SDK abstraheren de complexiteit van het streamen van AI-antwoorden, token-telling en het omgaan met verschillende AI-provider-API’s. Deze tools stellen ontwikkelaars in staat om geavanceerde AI-applicaties te bouwen zonder diepgaande infrastructuurkennis. Infrastructuuropties zoals Vercel Edge Functions, Cloudflare Workers en AWS Lambda bieden wereldwijd verspreide server-side AI-verwerking, waardoor de latentie wordt verlaagd door verzoeken dichter bij gebruikers te verwerken, terwijl gecentraliseerd modelbeheer behouden blijft.
Effectieve server-side AI-rendering vereist geavanceerde cachingstrategieën om rekenkosten en latentie te beheersen. Redis caching slaat veelgevraagde AI-antwoorden en gebruikerssessies op, waardoor dubbele verwerking voor vergelijkbare verzoeken wordt voorkomen. CDN-caching verspreidt statische, AI-gegenereerde content wereldwijd, zodat gebruikers antwoorden ontvangen van geografisch nabijgelegen servers. Edge caching-strategieën verspreiden door AI verwerkte content over edge-netwerken, wat ultrasnelle reacties mogelijk maakt terwijl gecentraliseerd modelbeheer behouden blijft.
Deze cachingbenaderingen werken samen om efficiënte AI-systemen te creëren die schaalbaar zijn tot miljoenen gebruikers zonder evenredige toename van rekenkosten. Door AI-antwoorden op meerdere niveaus te cachen, kunnen applicaties het merendeel van de verzoeken uit cache bedienen en hoeven alleen nieuwe antwoorden te berekenen voor echt nieuwe vragen. Dit verlaagt de infrastructuurkosten drastisch en verbetert de gebruikerservaring door snellere reactietijden.
De evolutie richting server-side rendering betekent een volwassenwording van webontwikkeling als reactie op AI-eisen. Nu AI centraal komt te staan in webapplicaties, vereisen de rekenrealiteiten een servergerichte architectuur. De toekomst bestaat uit geavanceerde hybride benaderingen die automatisch bepalen waar gerenderd wordt op basis van contenttype, apparaatmogelijkheden, netwerkcondities en AI-verwerkingseisen. Frameworks zullen applicaties steeds verder verrijken met AI-mogelijkheden, zodat kernfunctionaliteit universeel werkt en ervaringen waar mogelijk worden verbeterd.
Deze paradigmaverschuiving neemt lessen mee uit het Single Page Application-tijdperk en pakt AI-native applicatie-uitdagingen aan. De tools en frameworks zijn klaar voor ontwikkelaars om de voordelen van server-side rendering in het AI-tijdperk te benutten, en zo de volgende generatie intelligente, responsieve en efficiënte webapplicaties mogelijk te maken.
Volg hoe jouw domein en merk verschijnen in AI-gegenereerde antwoorden in ChatGPT, Perplexity en andere AI-zoekmachines. Krijg realtime inzicht in jouw AI-zichtbaarheid.
Server-Side Rendering (SSR) is een webtechniek waarbij servers complete HTML-pagina's renderen voordat ze naar browsers worden gestuurd. Leer hoe SSR SEO, pagin...
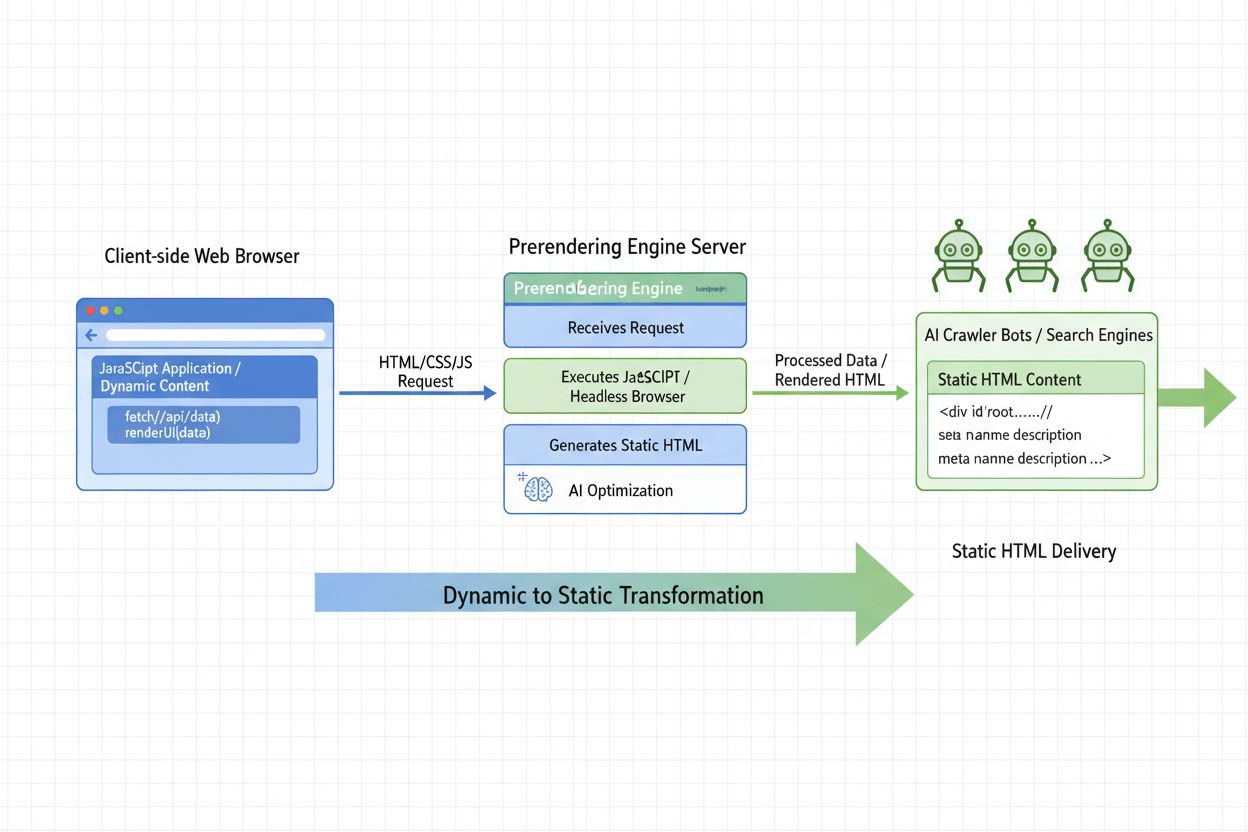
Ontdek wat AI-prerendering is en hoe server-side renderingstrategieën je website optimaliseren voor zichtbaarheid bij AI-crawlers. Leer implementatiestrategieën...

Ontdek hoe dynamische rendering AI-crawlers, ChatGPT, Perplexity en Claude beïnvloedt. Leer waarom AI-systemen geen JavaScript kunnen renderen en hoe je optimal...
Cookie Toestemming
We gebruiken cookies om uw browse-ervaring te verbeteren en ons verkeer te analyseren. See our privacy policy.