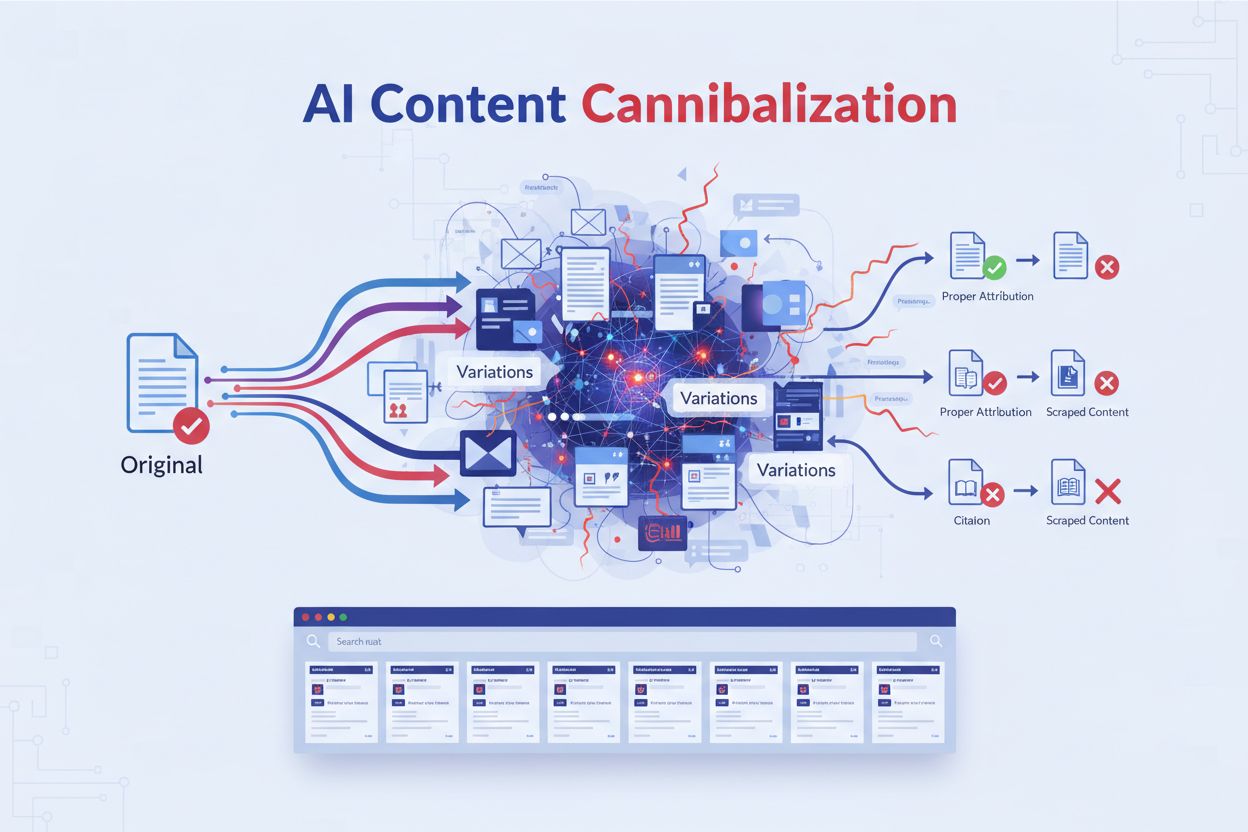
Wanneer meerdere stukken content concurreren om dezelfde AI-citaties. AI-systemen schrapen en herschrijven je originele content naar semantisch vergelijkbare variaties die concurreren met je originele pagina’s in zoekresultaten en AI-gegenereerde antwoorden, waardoor je zichtbaarheid en autoriteit verwateren zonder juiste bronvermelding.
AI-contentkannibalisatie
Wanneer meerdere stukken content concurreren om dezelfde AI-citaties. AI-systemen schrapen en herschrijven je originele content naar semantisch vergelijkbare variaties die concurreren met je originele pagina's in zoekresultaten en AI-gegenereerde antwoorden, waardoor je zichtbaarheid en autoriteit verwateren zonder juiste bronvermelding.
Wat is AI-contentkannibalisatie?
AI-contentkannibalisatie ontstaat wanneer kunstmatige intelligentiesystemen je originele content schrapen en herschrijven tot semantisch vergelijkbare variaties die concurreren met je originele pagina’s in zoekresultaten en AI-gegenereerde antwoorden. In tegenstelling tot traditionele dubbele content die tekst letterlijk kopieert, gebruiken AI-gegenereerde versies andere formuleringen met behoud van dezelfde betekenis, waardoor ze plagiaatdetectietools kunnen omzeilen. Dit creëert een bijzonder verraderlijk probleem in het AI-first zoeklandschap: jouw content voedt AI-modellen die vervolgens concurrerende antwoorden genereren zonder correcte bronvermelding. Wanneer Google AI Overviews en andere AI-zoeksystemen informatie synthetiseren, kunnen zij deze AI-gegenereerde klonen vaker citeren dan jouw originele werk, wat je zichtbaarheid en autoriteit verwatert. Het fundamentele probleem is dat semantische gelijkheid belangrijker is dan exacte duplicatie in AI-systemen—je unieke inzichten en onderzoek worden gerecycled in talloze variaties die allemaal strijden om dezelfde citaties en verkeer.
Hoe AI-contentkannibalisatie verschilt van traditionele dubbele content
Factor
Klassieke dubbele content
AI-contentkannibalisatie
Bron
Woord-voor-woord gekopieerd van je pagina
Hershreven of geparafraseerd door AI-tools in nieuwe variaties
Detectie
Makkelijk te herkennen met plagiaatfilters of handmatige controle
Veel moeilijker te detecteren omdat de bewoording uniek is maar semantisch vergelijkbaar
Verschijning
Lijkt op een directe kopie of mirrorsite
Lijkt ‘origineel’ voor zoekmachines en gebruikers, ook al is het gebaseerd op jouw werk
SEO-impact
Wordt meestal onderdrukt in SERP’s zodra als dubbel gemarkeerd
Verwatert thematische autoriteit, verwart zoekmachines en kan hoger ranken dan je originele pagina
Oplossing
DMCA-verwijdering indienen of verzoek tot verwijdering
Veel moeilijker op te treden; vaak moet je je eigen content versterken in plaats van verwijderen
Traditionele dubbele content is al jaren een bekend SEO-probleem—het is zichtbaar, te traceren en relatief eenvoudig op te lossen door verwijderingen of canonicalisatie. AI-contentkannibalisatie is fundamenteel anders en verraderlijker. De herschreven versies lijken geen directe kopieën, dus plagiaatcheckers slaan ze zelden aan. Voor zoekmachines kan de AI-gegenereerde pagina net zo relevant lijken als je originele, waardoor rankingsignalen worden gesplitst en je autoriteit afneemt. In de praktijk betekent dit dat je site stilletjes verkeer en rankings kan verliezen zonder duidelijke oorzaak. Tenzij je actief zoekresultaten monitort en semantische gelijkheid analyseert, blijft AI-kannibalisatie vaak onzichtbaar tot er al aanzienlijke schade is ontstaan.
AI-contentkannibalisatie schaadt je zoekzichtbaarheid op verschillende manieren:
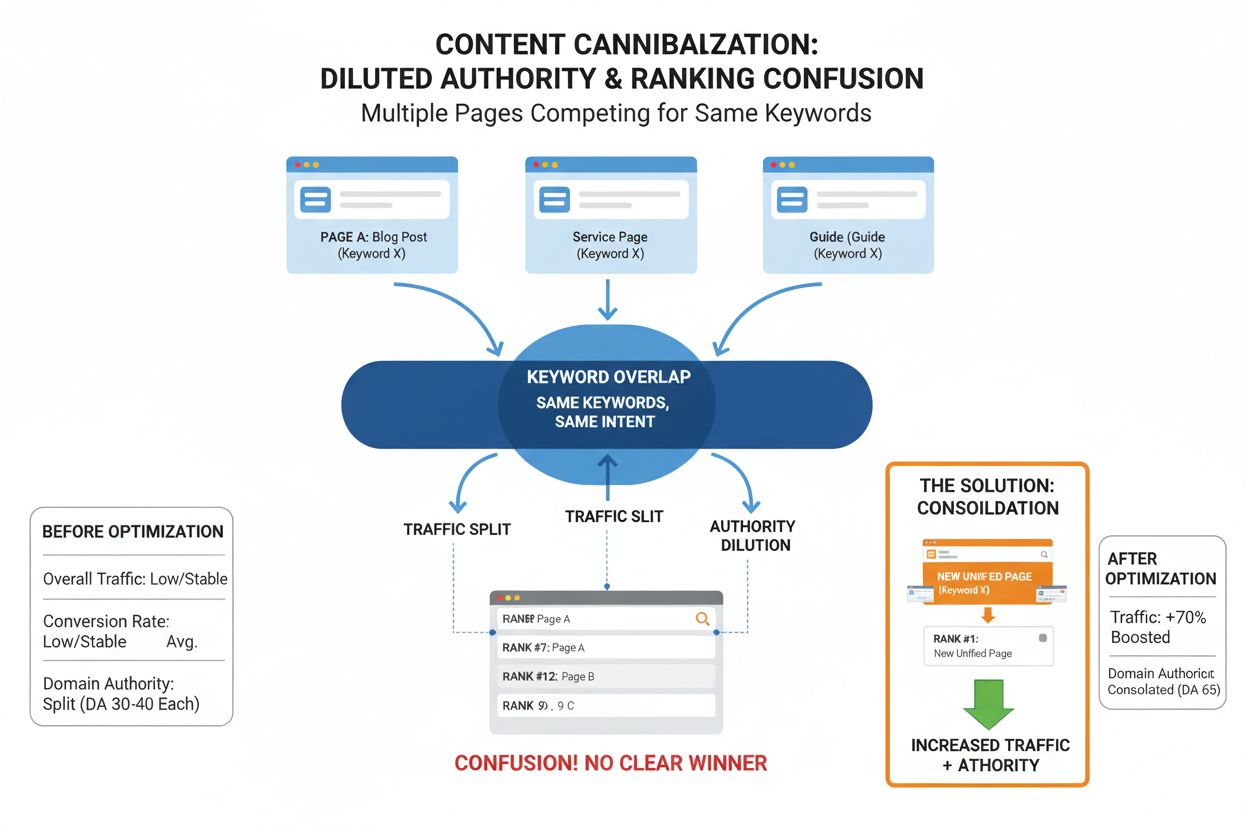
SERP-overspoeling: Zoekresultaten vullen zich met pagina’s die je idee herhalen in andere bewoordingen. Hierdoor wordt je origineel minder zichtbaar en moeten gebruikers kiezen uit meerdere vergelijkbare resultaten, waarvan geen enkele duidelijk als autoritatieve bron uitsteekt. Wanneer Google meerdere variaties van hetzelfde concept toont, verliest jouw origineel aan prominente positie.
Thematische verwarring: Google kan moeilijk bepalen wie de echte autoriteit op een onderwerp is. Het semantische gewicht wordt verdeeld over meerdere kopieën, waardoor het lastiger wordt voor zoekmachines om te bepalen welke pagina de hoogste ranking verdient. Deze verwarring verzwakt alle concurrerende pagina’s, inclusief je originele.
Klikverlies: Hershreven pagina’s vangen verkeer dat eigenlijk naar jouw origineel zou moeten gaan. Ze ogen nieuw voor gebruikers en beantwoorden de vraag, maar de bron ben jij niet. Iemand die zoekt op “beste SEO-tools” kan klikken op een AI-hershreven variant in plaats van jouw originele vergelijking, wat je verkeer en engagement kost.
Erosie in AI Overviews: Google AI Overviews gebruiken grote taalmodellen die getraind zijn op gerecyclede content. Je unieke formuleringen raken hun bronvermelding kwijt omdat AI-systemen semantisch vergelijkbare klonen vaker citeren dan je eigenlijke werk. Je content voedt AI-systemen zonder hiervoor correcte credits of verkeer te ontvangen.
Voorbeeld: Als je originele artikel zegt “Semrush is sterk voor audits. Ahrefs is sterk voor backlinks,” kan een AI-systeem dit herschrijven als “Ahrefs blinkt uit in linkanalyse. Semrush presteert beter voor technische audits.” De betekenis is identiek, beide worden geïndexeerd en de herschreven versie kan zelfs hoger ranken door een sterker domein van de kopieerder.
Hoe AI-contentkannibalisatie te detecteren
AI-contentkannibalisatie detecteren vereist een gelaagde aanpak:
Gebruik semantische vergelijkbaarheidstools: Embeddingmodellen en clusteringalgoritmes kunnen herschreven duplicaten detecteren die plagiaatcheckers missen. Deze tools analyseren semantische betekenis in plaats van exacte tekstovereenkomsten, waardoor content die dezelfde informatie in andere woorden brengt, zichtbaar wordt. Tools als Semrush en Similarweb bieden hiervoor semantische analysefuncties.
Volg je toppagina’s in Google Search Console: Monitor je best presterende pagina’s op plotselinge verkeersdalingen zonder verlies van backlinks. Als een pagina die altijd goed scoorde ineens fors daalt, kan dat een teken zijn dat AI-variaties je zichtbaarheid kannibaliseren. Gebruik het tabblad Prestaties om op specifieke pagina’s te filteren en let op onverklaarbare veranderingen.
Bekijk AI Overview-resultaten voor je zoektermen: Zoek naar je doelzoekwoorden in Google AI Overviews en Perplexity. Zie je bewoording die sterk lijkt op die van jou zonder correcte bronvermelding, dan is dat een signaal dat je content wordt gekopieerd en herschreven. Let erop of je merk wordt genoemd of dat het AI-systeem juist concurrenten citeert.
Stel meldingen in voor gescrapete RSS-feeds: Veel AI-systemen trainen op gescrapete syndicatiefeeds. Monitor het gebruik van je RSS-feed en stel meldingen in bij ongeautoriseerde scraping. Tools als Google Alerts en gespecialiseerde feedmonitoringdiensten helpen te volgen waar je content wordt verspreid en mogelijk zonder toestemming hergebruikt.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Strategieën om je te beschermen tegen AI-contentkannibalisatie
Je content verdedigen vereist een proactieve, veelzijdige strategie:
Publiceer assets die AI niet kan namaken: Maak content die AI-systemen niet makkelijk kunnen kopiëren—originele datatabellen, enquête-uitkomsten, eigen onderzoek, interactieve calculators en maatwerktools. AI blinkt uit in generieke tekst, maar kan geen nieuwe data of unieke interactieve ervaringen verzinnen. Deze verdedigbare assets vormen je barrière tegen kannibalisatie en geven gebruikers een reden om je originele bron te bezoeken.
Bedenk originele termen en gebruik deze consequent: Als je een onderscheidende term als “AI-contentkannibalisatie” introduceert en die overal toepast, nemen kopieën dit over. Zo wordt de autoriteit aan jou als bedenker gekoppeld. Wanneer AI-systemen deze term citeren, versterken ze je merk als bron. Ontwikkel unieke terminologie voor je belangrijkste concepten en claim dat taaldomein.
Voeg schema markup toe: Implementeer FAQ-, HowTo- en Article-schema markup op je pagina’s. Gestructureerde data helpt Google bij het bepalen van bronautoriteit en laat AI-systemen je content beter begrijpen qua doel en geloofwaardigheid. Dit maakt het makkelijker voor zoekmachines om je originele te prioriteren boven kopieën.
Update je content regelmatig: Zoekmachines belonen actualiteit, terwijl AI-kopieën vaak bevriezen na hun publicatie. Door je content regelmatig te verrijken met nieuwe data, actuele voorbeelden en frisse inzichten, laat je zien dat jouw pagina de levende, gezaghebbende bron is. Dit actualiteitssignaal helpt je origineel te onderscheiden van statische AI-kopieën.
Voorzie visuals en data van watermerken: Voeg subtiele watermerken toe aan grafieken, infographics en eigen datavisualisaties. Hoewel niet waterdicht, bewijzen watermerken auteurschap bij geschillen en maken het moeilijker voor anderen om je werk toe te eigenen. Voeg copyrightvermeldingen en bronvereisten toe aan je gegevenspresentaties.
De rol van AI-citatiemonitoring
AI-citatiemonitoring is het actief volgen waar, hoe en waarom je merkcontent als bron wordt genoemd in AI-gegenereerde antwoorden via tools als ChatGPT, Perplexity, Google AI Overviews en andere AI-zoekplatformen. Dit vormt een fundamentele verschuiving ten opzichte van traditionele SEO, waar je keyword rankings en backlinks volgde. In AI-first zoekopdrachten concurreer je nu om geciteerd, gesynthetiseerd en getoond te worden door taalmodellen in plaats van voor vaste posities in zoekresultaten.
Citatiemonitoring verschilt op cruciale punten van traditionele SEO-zichtbaarheid. Terwijl je met traditionele SEO je ranking op specifieke zoekwoorden meet, meet citatiemonitoring hoe AI-systemen je content kiezen als referentie bij het genereren van antwoorden. Een citaat in een AI-antwoord levert mogelijk niet meteen verkeer op, maar het signaleert je invloed en autoriteit binnen een vakgebied. Uitgevers gebruiken citatiemonitoring steeds vaker om zichtbaarheidshiaten te ontdekken, te bepalen welke content het vaakst wordt geciteerd en hun invloed in AI-antwoorden te meten. Tools als Semrush, Similarweb en gespecialiseerde AI-monitoringplatformen bieden nu citatiemonitoring, waarmee je kunt zien welke pagina’s in AI-antwoorden verschijnen en hoe vaak ze worden genoemd vergeleken met concurrenten. Deze data geeft inzicht in welke content aanslaat bij AI-systemen en stuurt je contentstrategie voor het AI-tijdperk.
Toekomstperspectief en semantische deduplicatie
Google ontwikkelt geleidelijk semantische deduplicatiesystemen die herkennen wanneer content inhoudelijk hetzelfde is, ook als deze herschreven is. Deze systemen zijn bedoeld om semantiek-equivalente content te identificeren en rankings te bundelen rond de originele bron. De grote uitdaging is echter snelheid: AI-gegenereerde content groeit veel sneller dan Google’s filters zich ontwikkelen. Tegen de tijd dat deze deduplicatiesystemen volwassen zijn, bestaan er al duizenden nieuwe AI-varianten die zijn aangemaakt en geïndexeerd.
De winnaars in dit landschap zijn uitgevers die hun niche bezitten via eigen data en onderzoek, onderscheidende formats en kaders, en unieke first-party inzichten die AI niet makkelijk kan synthetiseren. Deze uitgevers creëren verdedigbare barrières die AI-systemen niet kunnen repliceren. Ze bedenken originele terminologie, publiceren exclusieve data en bouwen echte expertise op die niet na te maken is. De verliezers zijn zij die vertrouwen op generieke, alleen tekstuele content zonder verdedigbaar voordeel. Naarmate AI de productie versnelt, worden originaliteit, expertise en merkauthoriteit de doorslaggevende factoren voor sites die doorgroeien versus verdwijnen. De toekomst is aan uitgevers die begrijpen dat in een AI-first wereld unieke waarde en authentieke expertise de enige duurzame concurrentievoordelen zijn. Content die makkelijk herschreven en hergebruikt kan worden, wordt een commodity, terwijl content met origineel onderzoek, eigen data en echte autoriteit premium zichtbaarheid krijgt in zowel traditionele zoekresultaten als AI-gegenereerde antwoorden.
Veelgestelde vragen
Wat is AI-contentkannibalisatie precies?
AI-contentkannibalisatie ontstaat wanneer kunstmatige intelligentiesystemen je originele content schrapen en herschrijven naar semantisch vergelijkbare variaties die concurreren met je originele pagina's in zoekresultaten en AI-gegenereerde antwoorden. In tegenstelling tot traditionele dubbele content die tekst letterlijk kopieert, gebruiken AI-gegenereerde versies andere bewoordingen met behoud van dezelfde betekenis, waardoor ze plagiaatdetectietools kunnen omzeilen.
Hoe verschilt AI-contentkannibalisatie van dubbele content?
AI-kannibalisatie betreft herschreven content die plagiaatchecks doorstaat maar toch autoriteit verwatert, terwijl dubbele content exacte kopieën zijn die makkelijker te detecteren en onderdrukken zijn. AI-gegenereerde pagina's lijken 'origineel' voor zoekmachines, ook al zijn ze gebaseerd op jouw werk, waardoor ze veel moeilijker te identificeren en te corrigeren zijn dan traditionele duplicaten.
Het veroorzaakt SERP-overspoeling (meerdere vergelijkbare resultaten concurreren), thematische verwarring (zoekmachines kunnen de autoriteit niet bepalen), klikverlies (verkeer gaat naar AI-gegenereerde kopieën) en vermindert je zichtbaarheid in AI Overviews. Je content voedt AI-modellen die vervolgens concurrerende antwoorden genereren zonder juiste bronvermelding, waardoor rankingsignalen worden opgesplitst en je autoriteit afneemt.
Hoe kan ik detecteren of mijn content wordt gekannibaliseerd door AI?
Gebruik semantische vergelijkbaarheidstools en embeddingmodellen om herschreven duplicaten te detecteren, monitor Google Search Console op onverklaarbare verkeersdalingen, bekijk AI Overview-resultaten voor niet-toegeschreven bewoordingen die op die van jou lijken, en stel meldingen in voor gescrapete RSS-feeds. Tools zoals Semrush en Similarweb bieden semantische analysecapaciteiten speciaal hiervoor.
Wat is de beste manier om mijn content te beschermen tegen AI-kannibalisatie?
Publiceer eigen data en originele inzichten die AI niet makkelijk kan repliceren, bedenk unieke termen en gebruik deze consequent, voeg schema markup toe (FAQ, HowTo, Article), update regelmatig om actualiteit te signaleren en voorzie visuele en data-elementen van watermerken. Deze verdedigbare assets vormen een barrière tegen kannibalisatie en geven gebruikers een reden om jouw originele bron te bezoeken.
Welke rol speelt AI-citatiemonitoring bij contentkannibalisatie?
Citatiemonitoring helpt je te volgen waar je content verschijnt in AI-gegenereerde antwoorden, je zichtbaarheid in AI-systemen te begrijpen en te identificeren wanneer AI-systemen concurrenten in plaats van jou citeren. Deze data geeft inzicht in welke content aanslaat bij AI-systemen en stuurt je strategie voor het AI-tijdperk.
Gaat Google het probleem van AI-contentkannibalisatie oplossen?
Google ontwikkelt semantische deduplicatiesystemen die herkennen wanneer content inhoudelijk hetzelfde is, zelfs als deze herschreven is. Maar AI-contentgeneratie groeit sneller dan de filters zich ontwikkelen. De beste verdediging is het creëren van verdedigbare, originele content die AI-systemen niet makkelijk kunnen namaken.
Hoe verhoudt AI-contentkannibalisatie zich tot contentdistributiestrategie?
Het onderstreept het belang van strategische contentdistributie over meerdere kanalen en ervoor zorgen dat je originele content geciteerd en toegeschreven wordt in AI-systemen. Uitgevers moeten nu concurreren om geciteerd te worden door AI-systemen in plaats van alleen te ranken in traditionele zoekresultaten, waardoor contentkwaliteit en originaliteit belangrijker zijn dan ooit.
Monitor je AI-citaties met AmICited
Bescherm je merkzichtbaarheid in AI-gestuurde zoekopdrachten. Volg hoe AI-systemen je content citeren via Google AI Overviews, ChatGPT, Perplexity en meer. Begrijp waar je content verschijnt in AI-gegenereerde antwoorden en zorg voor correcte bronvermelding.
Wat is Contentkannibalisatie in AI-zoekopdrachten en Hoe Beïnvloedt Het de Rankings
Ontdek wat contentkannibalisatie in AI-zoekopdrachten betekent, hoe het de zichtbaarheid van je merk in AI-antwoorden beïnvloedt en waarom het monitoren van ove...
Keyword-Cannibalisatie Oplossen voor AI-zoekmachines
Leer hoe je keyword-cannibalisatie opspoort en oplost die je zichtbaarheid in AI-zoekmachines zoals ChatGPT, Perplexity en Gemini beïnvloedt. Ontdek consolidati...
Content cannibalisatie is wanneer meerdere webpagina's concurreren op dezelfde zoekwoorden, waardoor autoriteit en rankings verwateren. Leer hoe je dit kritieke...
10 min lezen
Cookie Toestemming We gebruiken cookies om uw browse-ervaring te verbeteren en ons verkeer te analyseren. See our privacy policy.