
Wat is AI-zichtbaarheidsattributie en hoe beïnvloedt het uw merk?
Ontdek wat AI-zichtbaarheidsattributie is, hoe het verschilt van traditionele SEO en waarom het monitoren van de verschijning van uw merk in AI-gegenereerde ant...
10 min lezen
Een attentiemechanisme is een component van een neuraal netwerk dat dynamisch het belang van verschillende invoerelementen weegt, waardoor modellen zich kunnen richten op de meest relevante delen van data bij het doen van voorspellingen. Het berekent attentiegewichten via geleerde transformaties van queries, keys en values, waardoor deep learning-modellen lange-afstandsafhankelijkheden en contextbewuste relaties in sequentiële data kunnen vastleggen.
Een attentiemechanisme is een component van een neuraal netwerk dat dynamisch het belang van verschillende invoerelementen weegt, waardoor modellen zich kunnen richten op de meest relevante delen van data bij het doen van voorspellingen. Het berekent attentiegewichten via geleerde transformaties van queries, keys en values, waardoor deep learning-modellen lange-afstandsafhankelijkheden en contextbewuste relaties in sequentiële data kunnen vastleggen.
Attentiemechanisme is een machine learning-techniek die deep learning-modellen aanstuurt om (ofwel “aandacht te geven aan”) de meest relevante delen van invoergegevens te prioriteren bij het doen van voorspellingen. In plaats van alle invoerelementen gelijk te behandelen, berekenen attentiemechanismen attentiegewichten die de relatieve belangrijkheid van elk element voor de taak aangeven, en passen deze gewichten toe om specifieke invoer dynamisch te benadrukken of te verzwakken. Deze fundamentele innovatie is de hoeksteen geworden van moderne transformerarchitecturen en grote taalmodellen (LLM’s) zoals ChatGPT, Claude en Perplexity, waardoor ze sequentiële data met ongekende efficiëntie en nauwkeurigheid kunnen verwerken. Het mechanisme is geïnspireerd op menselijke cognitieve aandacht—het vermogen om selectief op opvallende details te focussen en irrelevante informatie te filteren—en vertaalt dit biologische principe naar een wiskundig streng en leerbaar component van neurale netwerken.
Het concept van attentiemechanismen werd voor het eerst geïntroduceerd door Bahdanau en collega’s in 2014 om kritieke beperkingen van recurrente neurale netwerken (RNN’s) voor machinevertaling aan te pakken. Voor de introductie van attentie vertrouwden Seq2Seq-modellen op een enkele contextvector om volledige bronszinnen te coderen, wat een informatieflessenhals creëerde die de prestaties op lange sequenties ernstig beperkte. Het oorspronkelijke attentiemechanisme stelde de decoder in staat om toegang te krijgen tot alle verborgen toestanden van de encoder in plaats van alleen de laatste, waarbij dynamisch werd geselecteerd welke delen van de invoer het meest relevant waren bij elke decodering stap. Deze doorbraak verbeterde de vertaalkwaliteit aanzienlijk, vooral bij langere zinnen. In 2015 introduceerden Luong en collega’s dot-product attentie, die de rekenintensieve additieve attentie verving door efficiënte matrixvermenigvuldiging. Het kantelpunt kwam in 2017 met de publicatie van “Attention is All You Need”, waarin de transformerarchitectuur werd geïntroduceerd die geheel afzag van recursiviteit ten gunste van zuivere attentiemechanismen. Dit artikel revolutioneerde deep learning en maakte de ontwikkeling van BERT, GPT-modellen en het hele moderne generatieve AI-ecosysteem mogelijk. Tegenwoordig zijn attentiemechanismen overal aanwezig in natural language processing, computer vision en multimodale AI-systemen, waarbij meer dan 85% van de state-of-the-art modellen een vorm van attentie-gebaseerde architectuur bevatten.
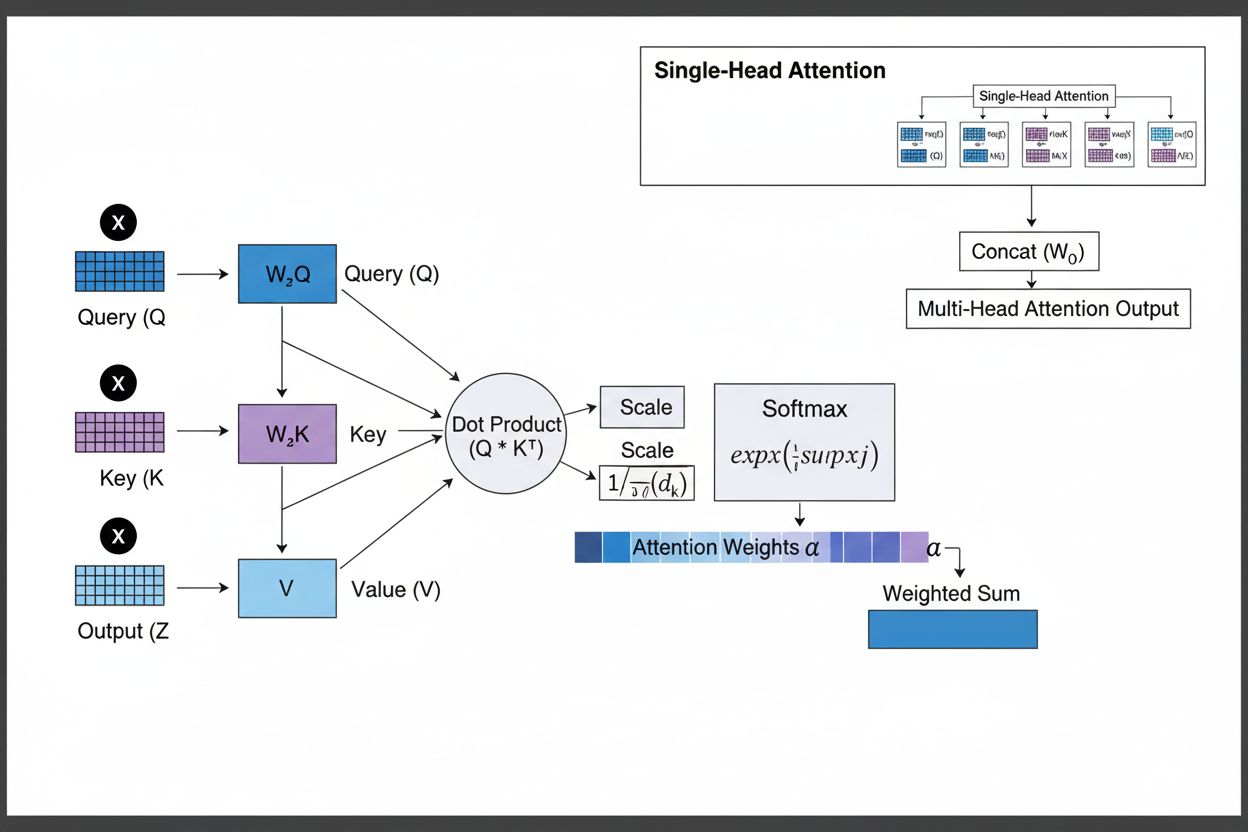
Het attentiemechanisme werkt via een verfijnde interactie van drie kernwiskundige componenten: queries (Q), keys (K) en values (V). Elk invoerelement wordt door geleerde lineaire projecties naar deze drie representaties getransformeerd, waarmee een database-achtige structuur ontstaat waarbij keys als identificatoren dienen en values de feitelijke informatie bevatten. Het mechanisme berekent alignmentscores door de gelijkenis tussen een query en alle keys te meten, meestal met behulp van geschaalde dot-product attentie, waarbij de score wordt berekend als QK^T/√d_k. Deze ruwe scores worden vervolgens genormaliseerd met de softmaxfunctie, die ze omzet in een kansverdeling waarbij alle gewichten samen 1 vormen, zodat elk element een gewicht tussen 0 en 1 krijgt. De laatste stap is het berekenen van een gewogen som van de valuevectoren met deze attentiegewichten, wat resulteert in een contextvector die de meest relevante informatie uit de volledige invoersequentie representeert. Deze contextvector wordt vervolgens gecombineerd met de oorspronkelijke invoer via residuele verbindingen en doorgegeven aan feedforward-lagen, waardoor het model zijn begrip van de invoer iteratief kan verfijnen. De wiskundige elegantie van dit ontwerp—met leerbare transformaties, gelijkenisberekeningen en probabilistische weging—stelt attentiemechanismen in staat om complexe afhankelijkheden vast te leggen en toch volledig differentieerbaar te blijven voor gradiëntgebaseerde optimalisatie.
| Attentietype | Rekenmethode | Rekencomplexiteit | Beste Toepassing | Belangrijkste Voordeel |
|---|---|---|---|---|
| Additieve Attentie | Feed-forward netwerk + tanh activatie | O(n·d) per query | Kortere sequenties, variabele dimensies | Kan verschillende query/key-dimensies aan |
| Dot-Product Attentie | Eenvoudige matrixvermenigvuldiging | O(n·d) per query | Standaard sequenties | Computationeel efficiënt |
| Geschaalde Dot-Product | QK^T/√d_k + softmax | O(n·d) per query | Moderne transformers | Voorkomt verdwijnende gradiënten |
| Multi-Head Attentie | Meerdere parallelle attentie-heads | O(h·n·d) waarbij h=heads | Complexe relaties | Legt diverse semantische aspecten vast |
| Zelf-Attentie | Queries, keys, values uit dezelfde sequentie | O(n²·d) | Intra-sequentie relaties | Maakt parallelle verwerking mogelijk |
| Cross-Attentie | Queries uit de ene sequentie, keys/values uit een andere | O(n·m·d) | Encoder-decoder, multimodaal | Lijnt verschillende modaliteiten uit |
| Grouped Query Attentie | Deelt keys/values tussen query-heads | O(n·d) | Efficiënte inferentie | Vermindert geheugen en rekenkracht |
| Sparse Attentie | Beperkte attentie tot lokale/gestride posities | O(n·√n·d) | Zeer lange sequenties | Geschikt voor extreem lange sequenties |
Het attentiemechanisme functioneert door een nauwkeurig georkestreerde reeks wiskundige transformaties die neurale netwerken in staat stellen zich dynamisch te richten op relevante informatie. Bij het verwerken van een invoersequentie wordt elk element eerst geprojecteerd naar een hoog-dimensionale vectorruimte, waarin semantische en syntactische informatie wordt vastgelegd. Deze embeddings worden vervolgens via geleerde gewichten geprojecteerd naar drie afzonderlijke ruimtes: de queryruimte (wat wordt gezocht), de keyruimte (welke informatie elk element bevat) en de valueruimte (de feitelijke te aggregeren informatie). Voor elke querypositie berekent het mechanisme een gelijkenisscore met iedere key door hun dot-product te nemen, wat een vector van ruwe alignmentscores oplevert. Deze scores worden geschaald door te delen door de wortel uit de key-dimensie (√d_k)—een cruciale stap die voorkomt dat dot-producten te groot worden bij hoge dimensies, wat anders tot verdwijnende gradiënten zou leiden. De geschaalde scores worden vervolgens door een softmaxfunctie gehaald, die elke score exponentieert en normaliseert zodat ze samen 1 vormen, waardoor een kansverdeling over alle invoerposities ontstaat. Tot slot worden deze attentiegewichten gebruikt om een gewogen gemiddelde van de valuevectoren te berekenen, waarbij posities met hogere attentiegewichten sterker bijdragen aan de uiteindelijke contextvector. Deze contextvector wordt gecombineerd met de oorspronkelijke invoer via residuele verbindingen en verwerkt door feedforward-lagen, zodat het model zijn representaties iteratief kan verfijnen. Het hele proces is differentieerbaar, waardoor het model optimale attentiepatronen kan leren via gradiëntafdalingsalgoritmen tijdens training.
Attentiemechanismen vormen het fundamentele bouwblok van transformerarchitecturen, die de dominante standaard in deep learning zijn geworden. In tegenstelling tot RNN’s die sequenties sequentieel verwerken en CNN’s die werken met vaste lokale vensters, gebruiken transformers zelf-attentie zodat elke positie direct alle andere posities tegelijk kan bekijken, wat massale parallelisatie over GPU’s en TPU’s mogelijk maakt. De transformerarchitectuur bestaat uit afwisselende lagen van multi-head zelf-attentie en feedforward-netwerken, waarbij elke attentielaag het model in staat stelt zijn begrip van de invoer te verfijnen door selectief op verschillende aspecten te focussen. Multi-head attentie voert meerdere attentiemechanismen parallel uit, waarbij elke head leert zich te richten op verschillende typen relaties—de ene head kan zich specialiseren in grammaticale afhankelijkheden, een andere in semantische relaties, en een derde in langeafstandscoreferentie. De uitkomsten van alle heads worden samengevoegd en geprojecteerd, zodat het model zich gelijktijdig bewust is van verschillende linguïstische fenomenen. Deze architectuur is bijzonder effectief gebleken voor grote taalmodellen zoals GPT-4, Claude 3 en Gemini, die decoder-only transformerarchitecturen gebruiken waarbij elke token alleen mag letten op voorgaande tokens (causale masking) om het autoregressieve genereren te behouden. Het vermogen van het attentiemechanisme om lange-afstandsafhankelijkheden vast te leggen zonder de verdwijnende gradiëntenproblemen van RNN’s, is van cruciaal belang geweest om deze modellen contextvensters van 100.000+ tokens te laten verwerken, waarbij coherentie en consistentie over grote hoeveelheden tekst behouden blijven. Onderzoek toont aan dat ongeveer 92% van de state-of-the-art NLP-modellen nu vertrouwt op transformerarchitecturen aangedreven door attentiemechanismen, wat hun fundamentele belang voor moderne AI-systemen aantoont.
In de context van AI-zoekplatformen zoals ChatGPT, Perplexity, Claude en Google AI Overviews spelen attentiemechanismen een cruciale rol bij het bepalen welke delen van opgehaalde documenten en kennisbanken het meest relevant zijn voor gebruikersvragen. Wanneer deze systemen antwoorden genereren, wegen hun attentiemechanismen verschillende bronnen en passages dynamisch op relevantie, zodat ze samenhangende antwoorden uit meerdere bronnen kunnen synthetiseren en tegelijkertijd feitelijke nauwkeurigheid behouden. De attentiegewichten die tijdens de generatie worden berekend, kunnen worden geanalyseerd om te begrijpen welke informatie het model prioriteerde, wat inzicht geeft in hoe AI-systemen vragen interpreteren en beantwoorden. Voor merkmonitoring en GEO (Generative Engine Optimization) is inzicht in attentiemechanismen essentieel, omdat ze bepalen welke content en bronnen nadruk krijgen in AI-gegenereerde antwoorden. Content die is gestructureerd op een manier die aansluit bij hoe attentiemechanismen informatie wegen—door duidelijke entiteitdefinities, gezaghebbende bronnen en contextuele relevantie—zal eerder worden geciteerd en prominent worden weergegeven in AI-antwoorden. AmICited gebruikt inzichten uit attentiemechanismen om te volgen hoe merken en domeinen verschijnen op AI-platformen, in de wetenschap dat attentiegewogen citaties de meest invloedrijke vermeldingen in AI-gegenereerde content vertegenwoordigen. Naarmate bedrijven steeds vaker hun aanwezigheid in AI-antwoorden volgen, wordt het begrijpen dat attentiemechanismen de citatiepatronen aansturen cruciaal voor het optimaliseren van contentstrategie en het waarborgen van merkzichtbaarheid in het generatieve AI-tijdperk.
Het vakgebied van attentiemechanismen ontwikkelt zich snel, waarbij onderzoekers steeds geavanceerdere varianten ontwikkelen om computationele beperkingen aan te pakken en prestaties te verbeteren. Sparse attentiepatronen beperken attentie tot lokale buurten of gestride posities, waardoor de complexiteit van O(n²) naar O(n·√n) wordt verlaagd terwijl prestaties op zeer lange sequenties behouden blijven. Efficiënte attentiemechanismen zoals FlashAttention optimaliseren de geheugenbenutting bij attentierekeningen, waardoor 2-4x snelheidswinst wordt behaald via betere GPU-utilisatie. Grouped query attentie en multi-query attentie verminderen het aantal key-value heads met behoud van prestaties, wat het geheugenverbruik tijdens inferentie aanzienlijk verlaagt—cruciaal voor het inzetten van grote modellen in productie. Mixture of Experts-architecturen combineren attentie met sparse routing, zodat modellen kunnen schalen tot triljoenen parameters met behoud van computationele efficiëntie. Opkomend onderzoek onderzoekt geleerde attentiepatronen die zich dynamisch aanpassen op basis van invoerkenmerken, en hiërarchische attentie die op meerdere abstractieniveaus werkt. De integratie van attentiemechanismen met retrieval-augmented generation (RAG) stelt modellen in staat om dynamisch relevante externe kennis te raadplegen, wat de feitelijkheid verbetert en hallucinaties vermindert. Naarmate AI-systemen steeds vaker in kritieke toepassingen worden ingezet, worden attentiemechanismen uitgebreid met uitlegbaarheidsfuncties die meer inzicht geven in beslissingen van het model. De toekomst zal waarschijnlijk hybride architecturen brengen die attentie combineren met alternatieven zoals state-space modellen (zoals Mamba), die lineaire complexiteit bieden met behoud van concurrerende prestaties. Inzicht in deze evoluerende attentiemechanismen is essentieel voor ontwikkelaars van de volgende generatie AI-systemen en voor organisaties die hun aanwezigheid in AI-content monitoren, omdat de mechanismen die citatiepatronen en contentprominentie bepalen blijven verbeteren.
Voor organisaties die AmICited gebruiken om merkzichtbaarheid in AI-antwoorden te monitoren, biedt inzicht in attentiemechanismen cruciale context bij het interpreteren van citatiepatronen. Wanneer ChatGPT, Claude of Perplexity uw domein citeren in hun antwoorden, bepaalden de attentiegewichten die tijdens de generatie zijn berekend dat uw content het meest relevant was voor de gebruikersvraag. Hoogwaardige, goed gestructureerde content die entiteiten duidelijk definieert en gezaghebbende informatie biedt, krijgt vanzelfsprekend hogere attentiegewichten en wordt dus vaker geciteerd. De attentievisualisatie-functies op sommige AI-platformen laten zien welke bronnen de meeste aandacht kregen tijdens het genereren van het antwoord, waarmee u feitelijk kunt zien welke citaties het meest invloedrijk waren. Dit inzicht stelt organisaties in staat hun contentstrategie te optimaliseren, in de wetenschap dat attentiemechanismen helderheid, relevantie en gezaghebbende bronnen belonen. Naarmate AI-zoek verder groeit—met meer dan 60% van de ondernemingen die nu investeren in generatieve AI-initiatieven—wordt het kunnen begrijpen en optimaliseren voor attentiemechanismen steeds waardevoller voor het behouden van merkzichtbaarheid en het waarborgen van een accurate representatie in AI-gegenereerde content. Het snijvlak van attentiemechanismen en merkmonitoring vormt een nieuw terrein binnen GEO, waar inzicht in de wiskundige basis van hoe AI-systemen informatie wegen en citeren direct leidt tot meer zichtbaarheid en invloed in het generatieve AI-ecosysteem.
Traditionele RNN's verwerken sequenties serieel, waardoor het moeilijk is om lange-afstandsafhankelijkheden vast te leggen, terwijl CNN's vaste lokale receptieve velden hebben die hun vermogen om verre relaties te modelleren beperken. Attentiemechanismen overwinnen deze beperkingen door relaties tussen alle invoerposities gelijktijdig te berekenen, waardoor parallelle verwerking mogelijk is en afhankelijkheden ongeacht de afstand kunnen worden vastgelegd. Deze flexibiliteit in zowel tijd als ruimte maakt attentiemechanismen aanzienlijk efficiënter en effectiever voor complexe sequentiële en ruimtelijke data.
Queries vertegenwoordigen welke informatie het model op dat moment zoekt, keys vertegenwoordigen de informatie-inhoud die elk invoerelement bevat, en values bevatten de daadwerkelijke data die geaggregeerd moet worden. Het model berekent gelijkenisscores tussen queries en keys om te bepalen welke values het zwaarst moeten wegen. Deze door databases geïnspireerde terminologie, gepopulariseerd door het artikel 'Attention is All You Need', biedt een intuïtief raamwerk om te begrijpen hoe attentiemechanismen selectief relevante informatie ophalen en combineren uit invoersequenties.
Zelf-attentie berekent relaties binnen één enkele invoersequentie, waarbij queries, keys en values allemaal uit dezelfde bron komen, zodat het model kan begrijpen hoe verschillende elementen zich tot elkaar verhouden. Cross-attentie daarentegen gebruikt queries uit de ene sequentie en keys/values uit een andere sequentie, waardoor het model informatie uit meerdere bronnen kan afstemmen en combineren. Cross-attentie is essentieel in encoder-decoder-architecturen zoals machinale vertaling en in multimodale modellen zoals Stable Diffusion die tekst en beeldinformatie combineren.
Geschaalde dot-product attentie gebruikt vermenigvuldiging in plaats van optelling om alignmentscores te berekenen, waardoor het computationeel efficiënter is via matrixoperaties die GPU-parallelisatie benutten. De schaalfactor 1/√dk voorkomt dat dot-producten te groot worden als de key-dimensie hoog is, wat ervoor zou zorgen dat de gradiënten verdwijnen tijdens backpropagatie. Hoewel additieve attentie soms beter presteert dan dot-product attentie bij zeer grote dimensies, maken de superieure computationele efficiëntie en praktische prestaties van geschaalde dot-product attentie het tot de standaard in moderne transformerarchitecturen.
Multi-head attentie voert meerdere attentiemechanismen parallel uit, waarbij elke head leert zich te richten op verschillende aspecten van de invoer, zoals grammaticale relaties, semantische betekenis of lange-afstandsafhankelijkheden. Elke head werkt op verschillende lineaire projecties van de invoer, waardoor het model gelijktijdig diverse soorten relaties kan vastleggen. De uitkomsten van alle heads worden samengevoegd en geprojecteerd, zodat het model uitgebreid bewustzijn van meerdere linguïstische en contextuele kenmerken tegelijkertijd kan behouden, wat de representatiekwaliteit en prestaties op vervolgopdrachten aanzienlijk verbetert.
Softmax normaliseert de ruwe alignmentscores die tussen queries en keys zijn berekend tot een kansverdeling waarbij alle gewichten samen 1 vormen. Deze normalisatie zorgt ervoor dat attentiegewichten interpreteerbaar zijn als belangscores, waarbij hogere waarden op meer relevantie wijzen. De softmaxfunctie is differentieerbaar, waardoor gradiëntgebaseerd leren van het attentiemechanisme tijdens training mogelijk is, en de exponentiële aard ervan benadrukt verschillen tussen scores, waardoor de focus van het model selectiever en beter interpreteerbaar wordt.
Attentiemechanismen stellen deze modellen in staat om verschillende delen van de invoerprompt dynamisch te wegen op basis van relevantie voor de huidige generatiestap. Bij het genereren van een antwoord gebruikt het model attentie om te bepalen welke eerdere tokens en invoerelementen de volgende tokenvoorspelling het meest moeten beïnvloeden. Deze contextbewuste weging stelt de modellen in staat om samenhang te behouden, entiteiten over lange documenten te volgen, ambiguïteiten op te lossen en antwoorden te genereren die op de juiste manier verwijzen naar specifieke delen van de invoer, waardoor hun uitkomsten nauwkeuriger en contextueel passend zijn.
Begin met het volgen van hoe AI-chatbots uw merk vermelden op ChatGPT, Perplexity en andere platforms. Krijg bruikbare inzichten om uw AI-aanwezigheid te verbeteren.
Ontdek wat AI-zichtbaarheidsattributie is, hoe het verschilt van traditionele SEO en waarom het monitoren van de verschijning van uw merk in AI-gegenereerde ant...

Lees meer over AI Visibility Attribution Models - raamwerken die machine learning gebruiken om krediet toe te wijzen aan marketingcontactpunten in klantreizen. ...

Leer hoe u uw merksentiteit opbouwt en optimaliseert voor AI-herkenning. Implementeer schema markup, entity linking en gestructureerde data om de zichtbaarheid ...
Cookie Toestemming
We gebruiken cookies om uw browse-ervaring te verbeteren en ons verkeer te analyseren. See our privacy policy.