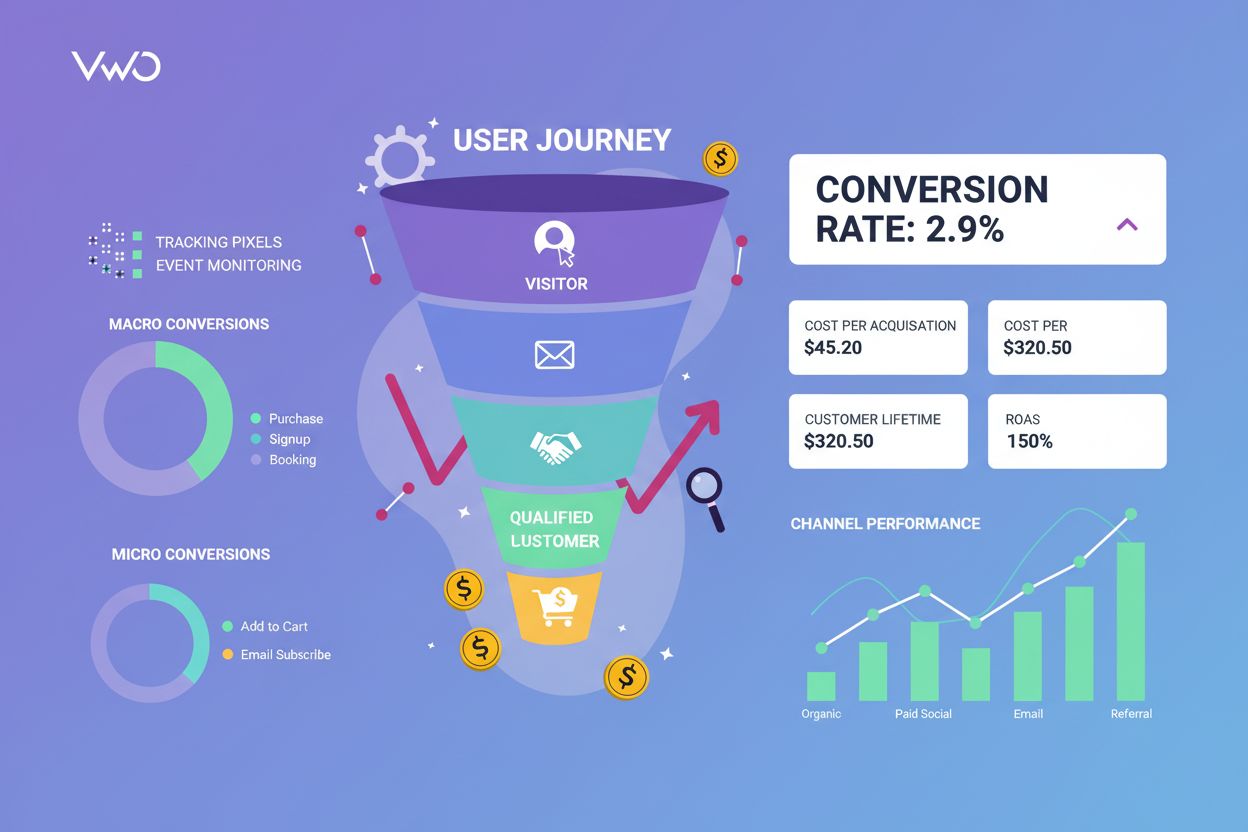
Conversietracking
Conversietracking monitort gebruikersacties richting bedrijfsdoelen. Leer hoe je conversies meet, metrics bijhoudt en marketing-ROI optimaliseert met uitgebreid...
12 min lezen
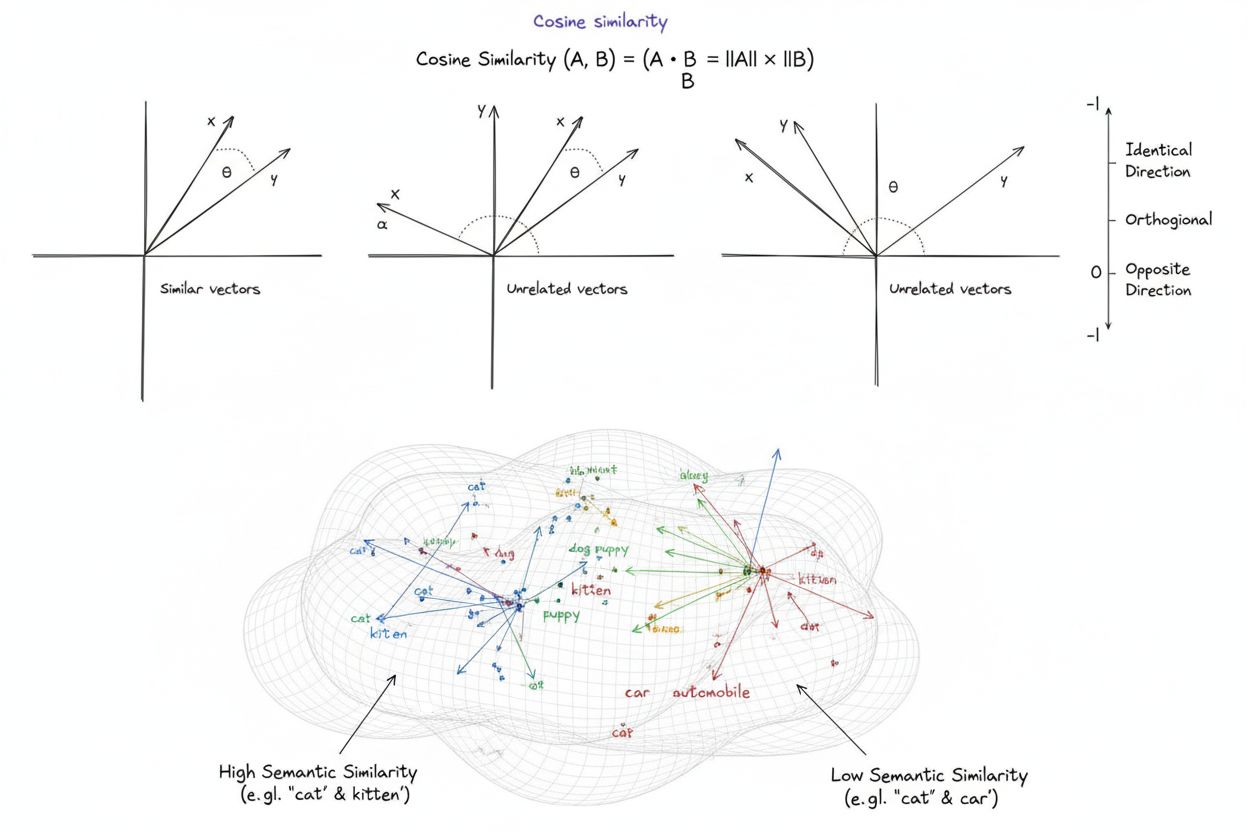
Cosinusovereenkomst is een wiskundige maatstaf die de overeenkomst tussen twee niet-nulvectoren berekent door de cosinus van de hoek ertussen te bepalen, wat een score oplevert tussen -1 en 1. Het wordt veel gebruikt in machine learning, natuurlijke taalverwerking en AI-systemen om semantische overeenkomst tussen tekstembeddings en vectorrepresentaties te meten, ongeacht de grootte van de vector.
Cosinusovereenkomst is een wiskundige maatstaf die de overeenkomst tussen twee niet-nulvectoren berekent door de cosinus van de hoek ertussen te bepalen, wat een score oplevert tussen -1 en 1. Het wordt veel gebruikt in machine learning, natuurlijke taalverwerking en AI-systemen om semantische overeenkomst tussen tekstembeddings en vectorrepresentaties te meten, ongeacht de grootte van de vector.
Cosinusovereenkomst is een wiskundige maatstaf die de overeenkomst tussen twee niet-nulvectoren berekent door de cosinus van de hoek ertussen te bepalen in een multidimensionale ruimte. De metriek levert een score op van -1 tot 1, waarbij een score van 1 aangeeft dat vectoren in identieke richtingen wijzen, 0 voor orthogonale (loodrechte) vectoren zonder richtingsrelatie, en -1 voor vectoren die exact tegengesteld zijn gericht. In praktische toepassingen is cosinusovereenkomst bijzonder waardevol omdat het de richtingsuitlijning meet in plaats van de absolute afstand, waardoor het onafhankelijk is van de grootte van de vector. Deze eigenschap maakt het uitzonderlijk geschikt voor het vergelijken van tekstembeddings, documentvectoren en semantische representaties waarbij de lengte of schaal van data geen invloed mag hebben op de overeenkomst. De metriek is fundamenteel geworden voor moderne kunstmatige intelligentie, natuurlijke taalverwerking en machine learning-systemen, en ondersteunt alles van zoekmachines tot aanbevelingsalgoritmen en toepassingen met grote taalmodellen.
Het concept cosinusovereenkomst is ontstaan vanuit fundamentele lineaire algebra en trigonometrie, waarbij de cosinus van de hoek tussen twee vectoren een genormaliseerde maat geeft voor hun richtingsuitlijning. De wiskundige basis is gebaseerd op het dotproduct (inwendig product) van vectoren en hun groottes, waardoor een genormaliseerde metriek ontstaat die zowel computationeel efficiënt als theoretisch solide is. Historisch kreeg cosinusovereenkomst bekendheid in informatieopslag tijdens de jaren ‘70 en ‘80, toen onderzoekers efficiënte methoden zochten om documentvectoren in grote tekstcorpora te vergelijken. De adoptie van de metriek versnelde sterk met de opkomst van machine learning en deep learning in de jaren 2010, vooral toen neurale netwerken hoog-dimensionale vector-embeddings begonnen te genereren voor tekst, afbeeldingen en andere datatypes. Tegenwoordig blijkt uit onderzoek dat meer dan 78% van de bedrijven die AI-gestuurde systemen implementeren, cosinusovereenkomst of verwante vergelijkingsmetriek gebruiken in hun datapijplijnen. De wiskundige elegantie—de combinatie van eenvoud en computationele efficiëntie—heeft het tot de standaard gemaakt voor het meten van semantische overeenkomst in NLP-toepassingen, met grote platforms als OpenAI, Google en Anthropic die het opnemen in hun kernsystemen.
De berekening van cosinusovereenkomst volgt een nauwkeurige wiskundige formule: Cosinusovereenkomst = (A · B) / (||A|| × ||B||), waarbij A · B het dotproduct (inwendig product) is van vectoren A en B, en ||A|| en ||B|| hun respectievelijke groottes of Euclidische normen. Om het dotproduct te berekenen, wordt elke overeenkomstige component van de twee vectoren met elkaar vermenigvuldigd en worden alle producten opgeteld. Bijvoorbeeld, als vector A de waarden [3, 2, 0, 5] bevat en vector B [1, 0, 0, 0], dan is het dotproduct (3×1) + (2×0) + (0×0) + (5×0) = 3. De grootte van een vector wordt berekend als de vierkantswortel van de som van de gekwadrateerde componenten; voor vector A is dat √(3² + 2² + 0² + 5²) = √38 ≈ 6,16. De uiteindelijke cosinusovereenkomst-score wordt verkregen door het dotproduct te delen door het product van de groottes, wat een genormaliseerde waarde tussen -1 en 1 oplevert. Deze normalisatie is cruciaal omdat het de metriek onafhankelijk maakt van vectorlengte, waardoor eerlijke vergelijking tussen vectoren van zeer verschillende schalen mogelijk wordt. In hoog-dimensionale ruimtes—zoals de 1.536-dimensionale embeddings van het OpenAI text-embedding-ada-002 model—blijft cosinusovereenkomst computationeel haalbaar, waarbij alleen basisbewerkingen als vermenigvuldiging, optelling en vierkantswortel nodig zijn die moderne processors efficiënt kunnen uitvoeren, zelfs over miljoenen vectoren.
In de natuurlijke taalverwerking vormt cosinusovereenkomst de ruggengraat voor het meten van semantische relaties tussen tekstreprensentaties. Wanneer tekst wordt omgezet naar vector-embeddings met modellen zoals BERT, Word2Vec, GloVe of GPT-gebaseerde embeddings, wordt elk woord, zin of document een punt in een hoog-dimensionale ruimte waarin semantische betekenis is gecodeerd via de positie en richting van de vector. Cosinusovereenkomst meet vervolgens hoe sterk deze semantische representaties op elkaar zijn afgestemd, waardoor systemen begrijpen dat woorden als “arts” en “verpleegkundige” semantisch verwant zijn, ondanks dat het verschillende termen zijn. Deze mogelijkheid is essentieel voor semantisch zoeken, waarbij een gebruikersquery wordt omgezet in een vector en vergeleken met documentvectoren om de meest relevante resultaten te vinden, ongeacht exacte trefwoordovereenkomsten. In grote taalmodellen zoals ChatGPT, Claude en Perplexity ondersteunt cosinusovereenkomst de retrievalmechanismen die relevante context ophalen uit trainingsdata of externe kennisbanken. De ongevoeligheid voor grootte is vooral belangrijk in NLP, omdat de lengte van een document niet de relevantie mag bepalen—een kort, gefocust artikel kan semantisch meer lijken op een query dan een lang document, puur vanwege de inhoud. Onderzoek toont aan dat cosinusovereenkomst alternatieve metrieken zoals Euclidische afstand in ongeveer 85% van de NLP-benchmarks overtreft bij het vergelijken van tekstembeddings, waardoor het de voorkeurskeuze is voor semantisch begrip binnen de AI-industrie.
| Metriek | Berekeningsmethode | Bereik | Gevoeligheid voor grootte | Beste gebruikssituatie | Computationele complexiteit |
|---|---|---|---|---|---|
| Cosinusovereenkomst | (A·B) / ( | A | × | ||
| Euclidische afstand | √(Σ(Aᵢ - Bᵢ)²) | 0 tot ∞ | Ja (grootte-afhankelijk) | Ruimtelijke data, clustering, fysieke afstanden | O(n) - efficiënt |
| Dotproduct | Σ(Aᵢ × Bᵢ) | -∞ tot ∞ | Ja (schaalgevoelig) | Ruwe overeenkomensmeting, niet genormaliseerd | O(n) - zeer efficiënt |
| Jaccard-overeenkomst | |A ∩ B| / |A ∪ B| | 0 tot 1 | Nee (set-gebaseerd) | Categorische data, aanbevelingssystemen | O(n) - efficiënt |
| Manhattan afstand | Σ|Aᵢ - Bᵢ| | 0 tot ∞ | Ja (grootte-afhankelijk) | Rasterdata, kenmerkvergelijking | O(n) - efficiënt |
| Pearson-correlatie | Cov(A,B) / (σₐ × σᵦ) | -1 tot 1 | Nee (genormaliseerd) | Statistische relaties, tijdreeksen | O(n) - efficiënt |
Vectordatabases zoals Pinecone, Weaviate, Milvus en Qdrant zijn ontstaan als gespecialiseerde infrastructuur voor het opslaan en doorzoeken van hoog-dimensionale vectoren, waarbij cosinusovereenkomst de primaire metriek is. Deze databases zijn geoptimaliseerd om miljoenen of miljarden vectoren te verwerken, waardoor realtime semantisch zoeken op schaal mogelijk is. Wanneer een zoekopdracht wordt ingediend bij een vectordatabase, wordt deze omgezet in een embedding en vergeleken met alle opgeslagen vectoren via cosinusovereenkomst, waarbij de resultaten worden gerangschikt op overeenkomstscore. Om praktische prestaties te behalen bij enorme datasets, maken vectordatabases gebruik van benaderde dichtstbijzijnde buur (ANN) algoritmen zoals Hierarchical Navigable Small World (HNSW) en DiskANN, die perfecte nauwkeurigheid opofferen voor enorme snelheidswinst. Zo behaalt de Timescale pgvectorscale extensie, die StreamingDiskANN implementeert, 28x lagere latency en 16x hogere query-throughput in vergelijking met gespecialiseerde vectordatabases zoals Pinecone, terwijl 99% recall behouden blijft tegen 75% lagere kosten. In semantisch zoeken maakt cosinusovereenkomst het mogelijk om gebruikersintentie te begrijpen voorbij letterlijke trefwoordovereenkomst—een zoekopdracht naar “gezonde eetgewoonten” levert documenten over “voedingsadviezen” en “gebalanceerde diëten” op, omdat hun embeddings in vergelijkbare richtingen wijzen ondanks verschillende terminologie. Deze capaciteit heeft informatieopslag getransformeerd, zodat zoekmachines, documentatiesystemen en kennisbanken contextueel relevante resultaten kunnen bieden op basis van gebruikersintentie in plaats van alleen trefwoorden.
Retrieval-Augmented Generation (RAG) betekent een paradigmaverschuiving in hoe grote taalmodellen toegang krijgen tot en gebruikmaken van informatie, en cosinusovereenkomst staat centraal in deze architectuur. In een typische RAG-pijplijn, wanneer een gebruiker een vraag indient, zet het systeem de vraag eerst om in een vector-embedding met hetzelfde embeddingmodel als waarmee de kennisbank werd gevectoriseerd. Cosinusovereenkomst vergelijkt vervolgens deze queryvector met alle documentvectoren in de kennisbank, en rangschikt documenten op relevantiescore. De hoogst gerangschikte documenten—met de hoogste cosinusovereenkomst-scores—worden opgehaald en als context aan de LLM doorgegeven, die dan een antwoord genereert op basis van deze informatie. Deze aanpak ondervangt de belangrijkste beperkingen van op zichzelf staande LLM’s: hun vaste kennisafkapdatum, neiging tot hallucinatie of het genereren van aannemelijk klinkende maar onjuiste informatie, en onvermogen tot toegang tot realtime of eigen data. Door cosinusovereenkomst te gebruiken voor intelligente retrieval, zorgen RAG-systemen ervoor dat LLM’s antwoorden genereren op basis van geverifieerde, actuele informatie. Grote implementaties van RAG zijn onder meer OpenAI’s ChatGPT met plugins, Anthropic’s Claude met retrieval, Google’s AI Overviews en Perplexity’s antwoordsysteem. Onderzoek toont aan dat RAG-systemen die cosinusovereenkomst gebruiken voor retrieval de antwoordnauwkeurigheid met ongeveer 40-60% verbeteren ten opzichte van op zichzelf staande LLM’s, terwijl hallucinatie met tot 70% wordt verminderd. De efficiëntie van cosinusovereenkomst-berekeningen is vooral belangrijk in RAG-systemen, omdat zij gelijktijdig overeenkomsten moeten berekenen tussen mogelijk miljoenen documenten in realtime, en door de computationele eenvoud van cosinusovereenkomst is dit haalbaar op grote schaal.
Een effectieve implementatie van cosinusovereenkomst vereist aandacht voor een aantal kritische factoren. Allereerst is datapreprocessing essentieel—vectoren moeten worden genormaliseerd voor de berekening om schaalconsistentie en geldige resultaten te waarborgen, vooral bij gebruik van hoog-dimensionale inputs uit diverse bronnen. Organisaties dienen nulvectoren (vectoren met uitsluitend nullen) te verwijderen of te markeren, omdat cosinusovereenkomst wiskundig ongedefinieerd is voor nulvectoren; dit zou deling-door-nul fouten veroorzaken tijdens de berekening. Bij implementatie van cosinusovereenkomst in productiesystemen is het raadzaam deze te combineren met aanvullende metrieken zoals Jaccard-overeenkomst of Euclidische afstand wanneer meerdere dimensies van overeenkomst nodig zijn, in plaats van uitsluitend te vertrouwen op cosinusovereenkomst. Testen in productie-achtige omgevingen vóór uitrol is cruciaal, vooral voor realtime systemen zoals API’s en zoekmachines waar prestaties en nauwkeurigheid direct invloed hebben op de gebruikerservaring. Populaire libraries maken implementatie eenvoudig: Scikit-learn biedt sklearn.metrics.pairwise.cosine_similarity(), NumPy maakt directe implementatie van de formule mogelijk met np.dot() en np.linalg.norm(), TensorFlow en PyTorch bieden GPU-versnelde implementaties voor grootschalige berekeningen, en PostgreSQL met pgvector biedt native cosinusovereenkomst-operatoren voor databasequery’s. Voor organisaties die AI-vermeldingen en merkpresences volgen op platforms als ChatGPT, Perplexity en Google AI Overviews, maakt cosinusovereenkomst nauwkeurige tracking mogelijk van hoe AI-systemen hun content benoemen en citeren door query-embeddings te vergelijken met opgeslagen merk- en domeinvectoren.
Ondanks de wijdverbreide adoptie kent cosinusovereenkomst verschillende uitdagingen waar praktijkmensen rekening mee moeten houden. De metriek is ongedefinieerd voor nulvectoren, waardoor zorgvuldige datapreprocessing en validatie nodig zijn om runtimefouten te voorkomen. Cosinusovereenkomst kan misleidend hoge scores opleveren voor vectoren die weliswaar in dezelfde richting wijzen, maar semantisch niet gerelateerd zijn, vooral bij slecht getrainde embeddings of als trainingsdata weinig diversiteit en context bevatten. Dit risico op valse overeenkomst is vooral problematisch in toepassingen als AI-monitoring, waar onjuiste beoordeling kan leiden tot gemiste merkvermeldingen of valse positieven. De symmetrie van de metriek—het onvermogen om de volgorde van vergelijking te onderscheiden—kan ongewenst zijn in toepassingen waar richting belangrijk is. Bovendien duidt een cosinusovereenkomst-score van 0 niet altijd op volledige ongelijkheid in realistische contexten; in genuanceerde domeinen als taal kunnen orthogonale vectoren toch subtiele semantische relaties delen die de metriek niet oppikt. De afhankelijkheid van correcte normalisatie betekent dat onjuist geschaalde data de resultaten kan vertekenen, en organisaties moeten zorgen voor consistente preprocessing van alle vectoren in hun systemen. Ten slotte is cosinusovereenkomst alleen mogelijk onvoldoende voor complexe evaluaties; combineren met andere metrieken en domeinspecifieke validatieregels levert vaak robuustere resultaten op.
De rol van cosinusovereenkomst in AI-systemen ontwikkelt zich verder naarmate embeddingmodellen geavanceerder worden en vectorgebaseerde architecturen machine learning domineren. Opkomende trends zijn de integratie van cosinusovereenkomst met hybride zoekmethoden die vectorovereenkomst combineren met traditionele full-text search, waardoor systemen zowel semantisch begrip als trefwoordmatching kunnen benutten. Multimodale embeddings—waarbij tekst, afbeeldingen, audio en video in een gedeelde vectorruimte worden gerepresenteerd—rekenen in toenemende mate op cosinusovereenkomst om crossmodale relaties te meten, wat toepassingen mogelijk maakt als beeld-naar-tekst zoeken en videoanalyse. De ontwikkeling van efficiëntere benaderde dichtstbijzijnde buur-algoritmen zoals DiskANN en HNSW verbetert de schaalbaarheid van cosinusovereenkomst-zoekopdrachten, zodat realtime semantisch zoeken op ongekende schaal mogelijk wordt. Kwantisatietechnieken die de vectordimensionaliteit verlagen terwijl cosinusovereenkomst-relaties behouden blijven, maken grootschalig zoeken op edge devices en in omgevingen met beperkte middelen mogelijk. In het kader van AI-monitoring en merkbewaking wordt cosinusovereenkomst steeds belangrijker naarmate organisaties willen begrijpen hoe AI-systemen als ChatGPT, Perplexity, Claude en Google AI Overviews hun content benoemen en citeren. Toekomstige ontwikkelingen kunnen adaptieve cosinusovereenkomst-metriek omvatten die zich aanpassen aan domeinspecifieke kenmerken, en integratie met uitlegbaarheidskaders die gebruikers inzicht geven in waarom bepaalde vectoren als vergelijkbaar worden beschouwd. Naarmate vectordatabases volwassen worden en standaard infrastructuur worden voor AI-toepassingen, zal cosinusovereenkomst waarschijnlijk de dominante metriek blijven voor semantische vergelijking, al zal het mogelijk worden aangevuld met domeinspecifieke metrieken voor bepaalde toepassingen.
Voor platforms zoals AmICited die merk- en domeinvermeldingen volgen in AI-systemen, is cosinusovereenkomst een cruciale technische basis. Bij het monitoren van hoe ChatGPT, Perplexity, Google AI Overviews en Claude specifieke domeinen of merken benoemen, maakt cosinusovereenkomst het mogelijk om semantische relevantie tussen gebruikersvragen en AI-antwoorden nauwkeurig te meten. Door merkvermeldingen, domein-URL’s en query-inhoud om te zetten in vectorembeddings, kan cosinusovereenkomst bepalen of een AI-respons daadwerkelijk een merk citeert of benoemt, of slechts gerelateerde concepten noemt. Deze mogelijkheid is essentieel voor organisaties die hun zichtbaarheid in door AI gegenereerde content willen begrijpen en willen volgen hoe hun intellectueel eigendom wordt toegeschreven of geciteerd door AI-systemen. De efficiëntie van de metriek maakt realtime monitoring van miljoenen AI-interacties uitvoerbaar, zodat organisaties direct meldingen ontvangen wanneer hun content wordt benoemd. Bovendien maakt cosinusovereenkomst vergelijkende analyses mogelijk—organisaties kunnen niet alleen volgen of ze genoemd worden, maar ook hoe hun vermeldingsfrequentie en relevantie zich verhouden tot concurrenten, wat concurrentie-informatie oplevert over AI-gedrag en contentbronnen.
Een cosinusovereenkomstscore van 1 geeft aan dat twee vectoren exact in dezelfde richting wijzen, wat betekent dat ze perfect vergelijkbaar zijn. Een score van 0 betekent dat de vectoren orthogonaal (loodrecht) zijn, wat aangeeft dat er geen richtingsrelatie of overeenkomst is. Een score van -1 geeft aan dat de vectoren precies in tegenovergestelde richting wijzen, wat totale ongelijkheid vertegenwoordigt. In praktische NLP-toepassingen duiden scores dichter bij 1 op semantisch vergelijkbare teksten, terwijl scores rond 0 wijzen op niet-gerelateerde inhoud.
Cosinusovereenkomst heeft de voorkeur voor tekstembeddings omdat het de hoek tussen vectoren meet in plaats van hun absolute afstand, waardoor het ongevoelig is voor de grootte van de vector. Dit is cruciaal voor NLP omdat de lengte van een document geen invloed mag hebben op de semantische overeenkomst—een korte zoekopdracht en een lang artikel kunnen even relevant zijn. Euclidische afstand daarentegen is gevoelig voor grootte en presteert slecht in hoog-dimensionale ruimtes waar vectoren neigen samen te vallen. Cosinusovereenkomst is ook computationeel efficiënter en van nature begrensd tussen -1 en 1, wat overloopproblemen voorkomt.
In RAG-systemen ondersteunt cosinusovereenkomst de retrieval-fase door query-embeddings te vergelijken met documentembeddings in een vectordatabase. Wanneer een gebruiker een zoekopdracht indient, wordt deze omgezet in een vector met hetzelfde embeddingmodel als de opgeslagen documenten. Cosinusovereenkomst rangschikt vervolgens documenten op relevantie, waarbij hogere scores op betere overeenkomsten duiden. De hoogst gerangschikte documenten worden opgehaald en als context aan de LLM doorgegeven, waardoor nauwkeurigere en feitelijk onderbouwde antwoorden mogelijk zijn. Dit proces stelt RAG-systemen in staat om beperkingen van LLM's, zoals verouderde kennis en hallucinaties, te overwinnen.
Cosinusovereenkomst kent verschillende beperkingen: het is ongedefinieerd wanneer vectoren een grootte van nul hebben, waardoor voorbewerking nodig is om nulvectoren te verwijderen. Het kan misleidend hoge overeenkomstencores opleveren voor richtingsuitgelijnde maar semantisch niet-gerelateerde vectoren, vooral bij slecht getrainde embeddings. De metriek is ook symmetrisch, wat betekent dat het de volgorde van vergelijking niet kan onderscheiden, wat in sommige toepassingen problematisch kan zijn. Bovendien geeft een overeenkomenscore van 0 niet altijd totale ongelijkheid aan in realistische contexten, met name in genuanceerde domeinen zoals taal, waar orthogonale vectoren toch semantische relaties kunnen delen.
Cosinusovereenkomst wordt berekend met de formule: (A · B) / (||A|| × ||B||), waarbij A · B het inwendig product (dotproduct) is van vectoren A en B, en ||A|| en ||B|| hun groottes (Euclidische normen) zijn. Het dotproduct wordt berekend door overeenkomende vectorcomponenten met elkaar te vermenigvuldigen en de resultaten op te tellen. De grootte van een vector is de vierkantswortel van de som van de kwadraten van de componenten. Deze formule levert een genormaliseerde score op tussen -1 en 1, waardoor het onafhankelijk is van de lengte van de vector en geschikt voor vergelijking van vectoren van verschillende grootte.
In AI-monitoringplatforms zoals AmICited is cosinusovereenkomst essentieel voor het volgen van merk- en domeinvermeldingen in AI-systemen zoals ChatGPT, Perplexity en Google AI Overviews. Door merkvermeldingen en zoekopdrachten om te zetten in vectorembeddings, meet cosinusovereenkomst hoe goed AI-gegenereerde antwoorden aansluiten bij de gevolgde inhoud. Dit stelt organisaties in staat te monitoren of hun domeinen voorkomen in AI-antwoorden, de semantische relevantie van vermeldingen te beoordelen en te volgen hoe AI-systemen hun inhoud benoemen in vergelijking met concurrenten. De efficiëntie van de metriek maakt real-time monitoring van miljoenen AI-interacties praktisch uitvoerbaar.
Belangrijke AI-platforms en tools die cosinusovereenkomst benutten zijn onder andere OpenAI's embeddingmodellen, Google's semantische zoekalgoritmen, het antwoordsysteem van Perplexity en de retrievalmechanismen van Claude. Vectordatabases zoals Pinecone, Weaviate en Milvus gebruiken cosinusovereenkomst als hun primaire metriek. Open-sourcelibraries zoals Scikit-learn, TensorFlow, PyTorch en NumPy bieden ingebouwde functies voor cosinusovereenkomst. PostgreSQL met de pgvector-extensie maakt grootschalige berekeningen van cosinusovereenkomst mogelijk. Deze tools vormen samen de basis van aanbevelingssystemen, chatbots, semantische zoekmachines en RAG-toepassingen binnen het AI-ecosysteem.
Begin met het volgen van hoe AI-chatbots uw merk vermelden op ChatGPT, Perplexity en andere platforms. Krijg bruikbare inzichten om uw AI-aanwezigheid te verbeteren.
Conversietracking monitort gebruikersacties richting bedrijfsdoelen. Leer hoe je conversies meet, metrics bijhoudt en marketing-ROI optimaliseert met uitgebreid...
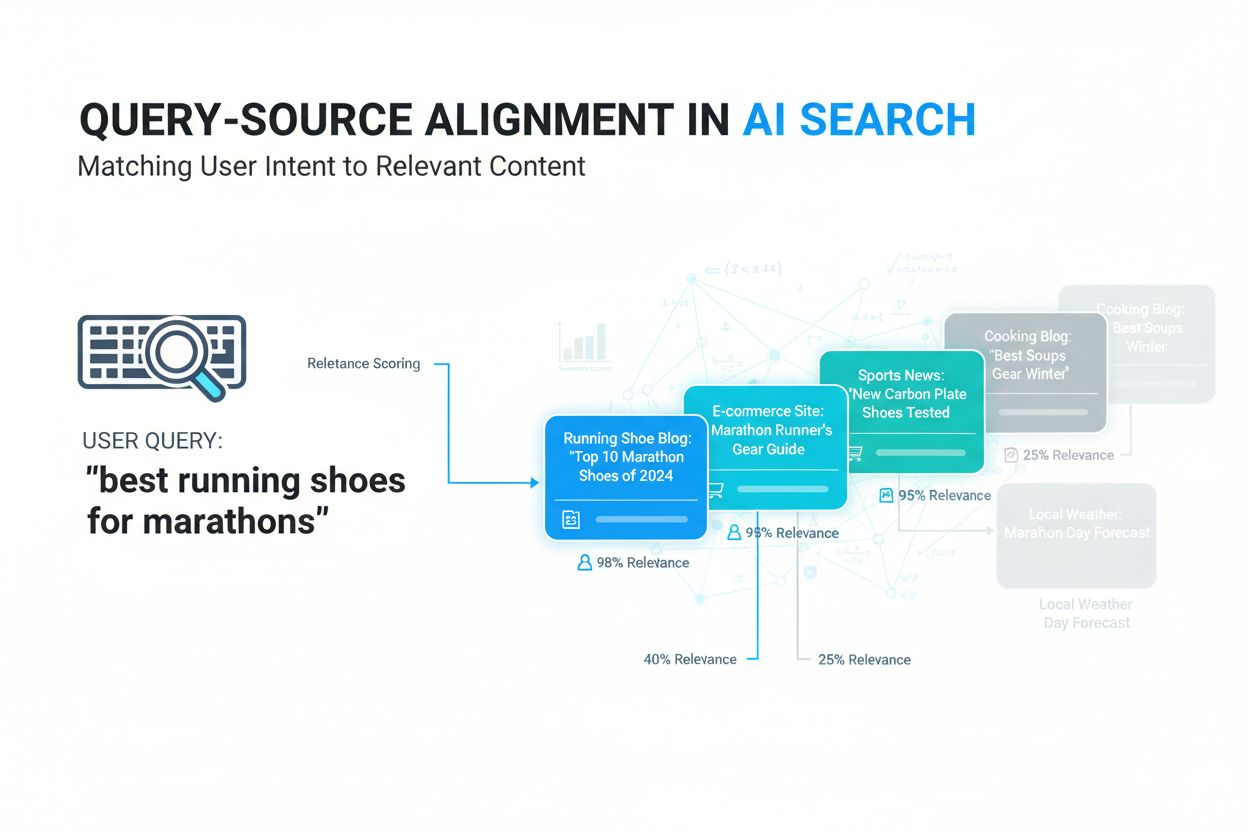
Ontdek wat query-source alignment is, hoe AI-systemen gebruikerszoekopdrachten koppelen aan relevante bronnen en waarom dit belangrijk is voor contentzichtbaarh...
Co-occurrence is wanneer gerelateerde termen samen in content voorkomen, wat semantische relevantie signaleert aan zoekmachines en AI-systemen. Leer hoe dit con...
Cookie Toestemming
We gebruiken cookies om uw browse-ervaring te verbeteren en ons verkeer te analyseren. See our privacy policy.