
FAQ-schema voor AI implementeren: Complete Gids 2025
Leer hoe je FAQ-schema implementeert voor AI-zoekmachines. Stapsgewijze gids met JSON-LD-formaat, best practices, validatie en optimalisatie voor AI-platforms z...
10 min lezen
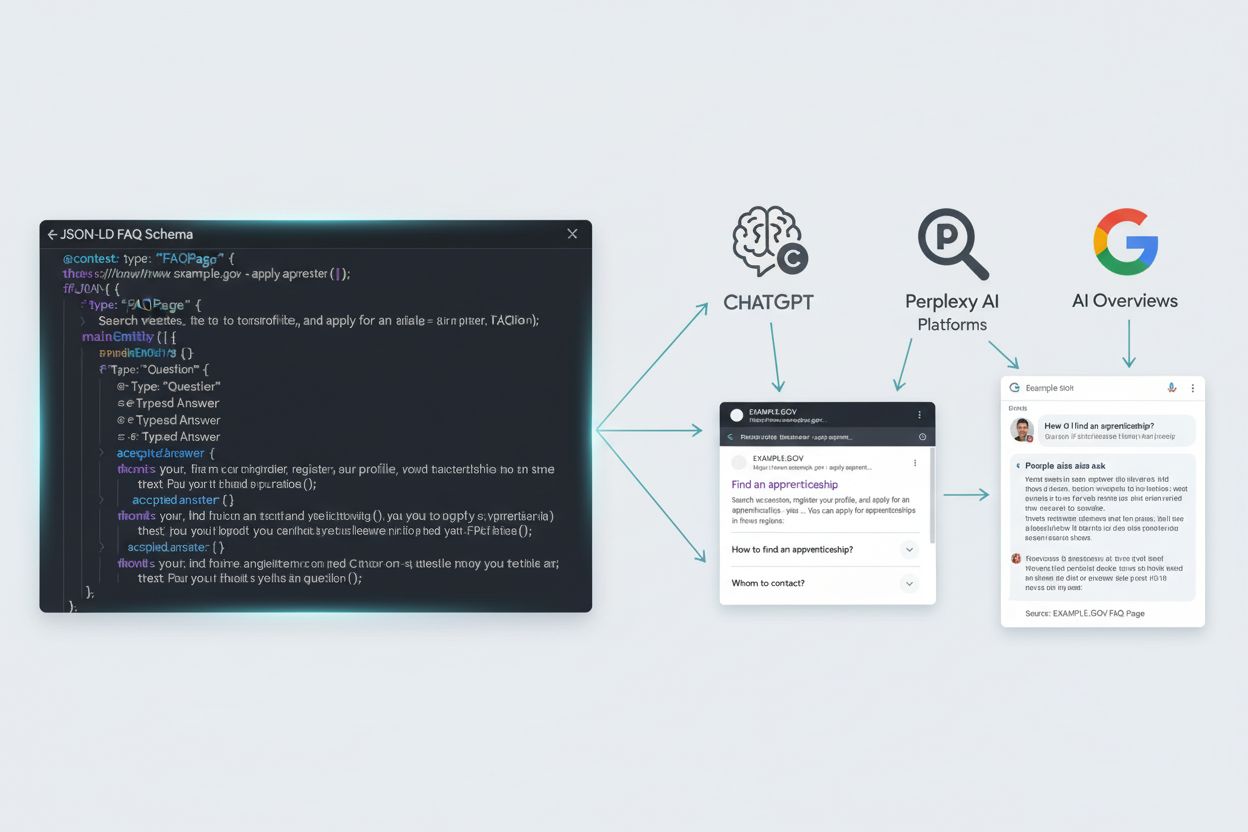
FAQ Schema (FAQPage) is gestructureerde data-opmaak die het JSON-LD-formaat gebruikt om zoekmachines en AI-platforms te helpen vraag-antwoordrelaties op webpagina’s te begrijpen. Hiermee kan content verschijnen in uitgebreide zoekresultaten en worden geciteerd door AI-systemen zoals ChatGPT, Perplexity en Google AI Overviews.
FAQ Schema (FAQPage) is gestructureerde data-opmaak die het JSON-LD-formaat gebruikt om zoekmachines en AI-platforms te helpen vraag-antwoordrelaties op webpagina's te begrijpen. Hiermee kan content verschijnen in uitgebreide zoekresultaten en worden geciteerd door AI-systemen zoals ChatGPT, Perplexity en Google AI Overviews.
FAQ Schema (formeel bekend als FAQPage binnen de Schema.org-vocabulaire) is een type gestructureerde data-opmaak dat expliciet vragen en antwoorden op webpagina’s labelt via het JSON-LD-formaat. Het helpt zoekmachines en AI-platforms de relatie tussen vragen en bijbehorende antwoorden te begrijpen, waardoor deze systemen jouw content nauwkeuriger kunnen extraheren, verifiëren en citeren. In tegenstelling tot ongestructureerde content waarbij AI-systemen relaties moeten interpreteren via natuurlijke taalverwerking, biedt FAQ Schema machineleesbare metadata die duidelijk aangeeft: “Dit is een vraag. Dit is het gezaghebbende antwoord. Deze elementen horen bij elkaar.” Deze expliciete labeling haalt de interpretatielast weg en vergroot de kans op correcte extractie en citatie door zoekmachines en AI-platforms aanzienlijk.
FAQ Schema werd in 2019 door Google geïntroduceerd als manier om zoekmachines veelgestelde vragen beter te laten begrijpen en weergeven in zoekresultaten. De opmaak werd snel populair in diverse sectoren—van e-commerce tot SaaS, gezondheidszorg tot financiën—omdat websites direct profiteerden van meer zichtbaarheid en hogere doorklikpercentages. In 2021 was FAQ Schema wereldwijd op miljoenen webpagina’s geïmplementeerd, waarmee het uitgroeide tot een van de populairste gestructureerde data-formaten onder SEO-professionals. Het schema betekende een grote verschuiving in hoe contentmakers zoekoptimalisatie benaderden: verder dan alleen keyword targeting, naar semantisch begrip van contentrelaties.
Het landschap veranderde echter drastisch in augustus 2023, toen Google een essentiële beperking aankondigde: FAQ rich results zouden worden beperkt tot “bekende, gezaghebbende overheids- en gezondheidswebsites.” Deze beslissing weerspiegelde Google’s zorgen over misbruik van de opmaak—keyword-stuffed vragen, irrelevante content en dubbele informatie die zoekers niet werkelijk hielp. Begin 2024 had Google FAQ rich results voor de meeste domeinen feitelijk stopgezet, hoewel de gestructureerde data zelf geldig bleef. Deze verschuiving betekende een kritisch omslagpunt in de rol van FAQ Schema binnen SEO, van traditionele zoekzichtbaarheid naar een essentieel element voor AI-zoekoptimalisatie.
Een correcte implementatie van FAQ Schema vereist inzicht in de specifieke JSON-LD-structuur die zoekmachines en AI-platforms herkennen. De opmaak bestaat uit drie primaire componenten: het FAQPage-type (dat aangeeft dat de pagina FAQ’s bevat), Question-objecten (met de “name”-eigenschap met de vraagtekst) en Answer-objecten (met de “text”-eigenschap met het antwoord). Elke Question moet exact één acceptedAnswer hebben, waarmee FAQ Schema verschilt van QAPage (voor community Q&A met meerdere antwoorden) of HowTo Schema (voor stapsgewijze instructies).
De technische architectuur van FAQ Schema weerspiegelt hoe AI-systemen informatie verwerken. Met FAQPage-opmaak geef je expliciete semantische relaties die grote taalmodellen direct, zonder ambiguïteit, kunnen interpreteren. Onderzoek toont aan dat 78% van AI-gegenereerde antwoorden lijstformaten bevat, en FAQ Schema structureert content van nature als vraag-antwoordparen—precies het format dat AI-platforms aan gebruikers presenteren. Deze structurele overeenstemming maakt FAQ-content per definitie geschikt voor AI-citatie. Het schema ondersteunt HTML-opmaak binnen het antwoord, zoals links, lijsten en nadruk-tags, wat de leesbaarheid vergroot bij behoud van machineleesbaarheid.
| Aspect | FAQ Schema (FAQPage) | QA Page Schema | HowTo Schema | Article Schema |
|---|---|---|---|---|
| Beste Toepassing | Eén antwoord per vraag | Meerdere gebruikersantwoorden | Stapsgewijze instructies | Nieuws, blogs, artikelen |
| Antwoordstructuur | Eén geaccepteerd antwoord | Meerdere antwoorden mogelijk | Opeenvolgende stappen met acties | Narratieve contentopbouw |
| Toepassingsvoorbeeld | Productondersteuning-FAQ’s | Stack Overflow, Quora | Receptinstructies, tutorials | Nieuwsartikelen, blogs |
| AI-citatiegraad | Hoogste onder schema-types | Gemiddeld (community-afhankelijk) | Hoog (procedurele content) | Hoog (gezaghebbende bronnen) |
| Google Rich Results | Beperkt (alleen overheid/gezondheid) | Niet in aanmerking | In aanmerking | In aanmerking |
| Ideale antwoordlengte | 40-60 woorden | Variabel (gebruikersafhankelijk) | 100-200 woorden per stap | 150+ woorden per sectie |
| Platformvoorkeur | ChatGPT, Perplexity, Google AI | Beperkte AI-adoptie | Google Assistant, voice search | Alle grote AI-platforms |
| Zichtbaarheid in SERPs | Minimaal (na 2023) | Minimaal | Featured snippets | Featured snippets, carrousels |
De verschuiving van traditionele zoekopdrachten naar AI-aangedreven answer engines heeft contentstrategie en de rol van FAQ Schema daarin fundamenteel getransformeerd. AI-verwijzingssessies stegen met 527% tussen januari en mei 2025, aldus Search Engine Land, wat de manier waarop gebruikers informatie vinden radicaal verandert. In plaats van te klikken op zoekresultaten, krijgen gebruikers nu direct antwoorden van ChatGPT, Perplexity en Google’s AI Overviews—waarmee FAQ Schema de kritische brug vormt tussen jouw content en AI-citaties. Deze transformatie betekent een paradigmawijziging: succes wordt niet langer primair gemeten aan zoekposities en klikken, maar aan de frequentie van citaties in AI-gegenereerde antwoorden.
FAQ Schema heeft een van de hoogste citatiepercentages van alle schema-types in AI-gegenereerde antwoorden, omdat het vraag-antwoordformaat overeenkomt met hoe AI-platforms informatie presenteren. Wanneer AI-systemen correct gestructureerde FAQ-data tegenkomen, kunnen ze antwoorden direct extraheren zonder complexe natuurlijke taalverwerking. Deze betrouwbaarheid maakt FAQ-content inherent betrouwbaar voor AI-algoritmen. Bovendien moeten FAQ-antwoorden op zichzelf staan om effectief te werken in AI-zoekopdrachten—waar traditionele content context opbouwt per alinea, extraheren AI-platforms individuele Q&A’s zonder omliggende content. Deze eis verbetert de contentkwaliteit voor menselijke lezers ook, omdat schrijvers worden gedwongen om volledige, zelfstandige antwoorden te geven.
Verschillende AI-zoekplatforms vertonen verschillende citatiepatronen en contentvoorkeuren die invloed hebben op de optimalisatie van FAQ Schema. ChatGPT vertoont een sterke voorkeur voor encyclopedische, goed gestructureerde content, met Wikipedia dat volgens GEO-onderzoek goed is voor 47,9% van de totale ChatGPT-citaties. Dit laat zien dat ChatGPT voorkeur geeft aan neutrale, gezaghebbende, volledig gestructureerde informatie. FAQ Schema sluit hier perfect bij aan, omdat het expliciet vragen en antwoorden labelt zoals Wikipedia dat met secties doet. Om FAQ-content te optimaliseren voor ChatGPT: hanteer een objectieve, informatieve toon, zorg dat elk antwoord zelfstandig is en volledige context biedt, en voeg specifieke statistieken, data en gekwantificeerde claims met correcte bronvermelding toe.
Perplexity AI volgt een duidelijk andere aanpak, met Reddit dat goed is voor 6,6% van de Perplexity-citaties—een veel hoger percentage dan bij andere AI-platforms. Dit wijst op Perplexity’s voorkeur voor authentieke, ervaringsgerichte, conversatiestijl content in plaats van zuiver encyclopedische informatie. Voor Perplexity-optimalisatie: formuleer vragen zoals mensen ze in het dagelijks leven stellen, neem concrete scenario’s en klantervaringen op in FAQ-antwoorden, hanteer een iets persoonlijkere, behulpzame toon (zoals een deskundige vriend die iets uitlegt) en leg nadruk op praktische toepasbaarheid met duidelijke vervolgstappen. Google AI Overviews kiest een domein-neutrale benadering en put uit featured snippet-content en pagina’s met sterke E-E-A-T-signalen. Optimalisatie moet zich richten op featured snippet-afstemming (antwoorden van 40-60 woorden), E-E-A-T-signalen (auteursgegevens, publicatiedata, externe citaties), mobile-first contentdesign en gecombineerde schema-types (FAQ + Article + Organization) voor meer autoriteit.
FAQ Schema effectief implementeren vereist het volgen van specifieke richtlijnen voor zowel zoekmachineherkenning als AI-platformcompatibiliteit. Eén antwoord per vraag is fundamenteel—FAQ Schema mag alleen worden gebruikt waar er één definitief antwoord is op elke vraag. Heb je een pagina met één vraag maar meerdere gebruikers die alternatieve antwoorden kunnen indienen (zoals bij een forum), gebruik dan QAPage Schema. Gebruik FAQ Schema niet voor ‘How To’-content—hoewel het toepasselijk lijkt, is FAQ Schema niet bedoeld voor stapsgewijze instructies. Gebruik voor dat doeleinde het HowTo-schema. Vermijd het gebruik van markup voor reclamedoeleinden—Schema is bedoeld om zoekmachines meer context te geven en gebruikers direct waardevolle informatie te bieden. Het inzetten van FAQ Schema voor promotionele doeleinden is in strijd met Google’s richtlijnen en zorgt dat AI-platforms jouw domein minder vertrouwen.
Vermijd herhaling van FAQ-content op meerdere pagina’s—verschijnen dezelfde vraag en antwoord op meerdere pagina’s, implementeer die specifieke FAQ Schema dan slechts één keer op de hele site. Een webcrawler helpt om deze dubbele vragen op te sporen. Zorg dat alle content zichtbaar is voor gebruikers—Google’s richtlijnen voor gestructureerde data verbieden markering van content die niet zichtbaar is voor gebruikers. Staat FAQ-content alleen in je schema-opmaak en wordt deze niet daadwerkelijk op de pagina getoond, dan kunnen AI-platforms het schema negeren of je domein als spam aanmerken. Accordion-style FAQ-secties waarbij vragen zichtbaar zijn en antwoorden uitklappen bij klikken zijn toegestaan; CSS display: none of visibility: hidden op FAQ-content niet. Beantwoord vragen volledig—schrijf zowel de vraag als het antwoord helemaal uit in je schema-code. Uiteindelijk kunnen vraag én antwoord als rich result of door AI worden weergegeven, dus mogen er geen fragmenten of onvolledige informatie zijn.
Hoewel Google FAQ rich results heeft beperkt, vergroot FAQ Schema nog steeds sterk je kans op featured snippets—de ‘positie nul’-antwoorden boven de organische resultaten. Onderzoek van Search Engine Land toont aan dat pagina’s met FAQ Schema vaker featured snippets winnen bij vraaggestuurde zoekopdrachten dan vergelijkbare pagina’s zonder gestructureerde Q&A-markup. Het schema helpt Google het beste antwoord te identificeren en weer te geven, en geeft effectief het signaal: “Dit is een volledig, gezaghebbend antwoord op deze specifieke vraag.” Featured snippets zijn om meerdere redenen waardevol: ze leveren voice search-antwoorden (cruciaal nu voice queries blijven groeien), staan prominent op mobiel waar schermruimte schaars is, vestigen autoriteit en vertrouwen, verhogen doorklik voor meer informatie en leveren data aan Google AI Overviews.
Voice search-optimalisatie via FAQ Schema wordt steeds belangrijker nu smart speakers en spraakassistenten toenemen. Wanneer iemand zijn apparaat een vraag stelt, zoekt de assistent naar compacte, zelfstandige antwoorden—precies wat goed gestructureerde FAQ Schema biedt. Spraakassistenten zoals Siri, Alexa en Google Assistant halen antwoorden uit gestructureerde FAQ-data, waardoor FAQ Schema essentieel is voor voice search-zichtbaarheid. Het vraag-antwoordformaat sluit van nature aan op hoe mensen vragen stellen aan voice assistants, waardoor FAQ-content bij uitstek geschikt is voor voice search-optimalisatie. Nu voice search blijft groeien—vooral bij lokale vragen, productinformatie en snelle antwoorden—wordt FAQ Schema een cruciaal onderdeel van een allesomvattende voice search-strategie.
FAQ-content voor gebruikers verbergen is een van de meest kritieke fouten die AI-citaties blokkeren. Google’s richtlijnen voor gestructureerde data verbieden expliciet schema-markup voor content die niet zichtbaar is voor gebruikers, en dit geldt ook voor AI-platformbehandeling van FAQ Schema. Staat FAQ-content alleen in je schema-markup en niet op de zichtbare pagina, dan kunnen AI-platforms het schema negeren of je domein als spammarkeren. Wat “verborgen” is omvat CSS display: none of visibility: hidden op FAQ-content, FAQ-tekst in schema die nergens in de zichtbare paginacontent voorkomt, content die alleen via JavaScript wordt geladen en die bots niet kunnen renderen, en FAQ-secties die ver buiten beeld staan of achter complexe interacties schuilgaan. Wat wel mag: accordion-style FAQ-secties waarbij vragen zichtbaar zijn en antwoorden uitklappen, tabinterfaces waarbij FAQ-content in de DOM aanwezig is maar per tab zichtbaar wordt, mobiele implementaties die content herschikken per scherm, en FAQ-content in de body van de pagina zelfs als deze niet in het menu staat.
FAQ Schema gebruiken voor marketingcontent in plaats van oprecht informatieve antwoorden is een andere kritieke fout. Google en AI-platforms maken onderscheid tussen echt informatieve FAQ-content en promotiemateriaal vermomd als vragen. Verboden FAQ-aanpakken zijn onder andere: “Waarom is [Jouw Bedrijf] de beste keuze?” met als antwoord een verkooppraatje, “Wat maakt [Jouw Product] revolutionair?” met marketingtekst als antwoord en FAQ-secties die alleen bestaan om zoekposities te manipuleren in plaats van gebruikers te helpen. Het onderscheid is duidelijk: informatieve FAQ’s beantwoorden vragen die gebruikers daadwerkelijk hebben over jouw product of dienst. Marketing-FAQ’s zijn verkapte advertenties met een vraagteken. Twijfel je, stel dan de vraag: “Zou dit FAQ-antwoord iemand tevreden stellen die objectief onderzoek doet, of is het alleen logisch als promotiemateriaal?” Implementeer schema alleen voor daadwerkelijk behulpzame antwoorden.
Vage of onvolledige antwoorden schrijven verlaagt de kans op citatie aanzienlijk. AI-platforms geven de voorkeur aan feitelijke, specifieke, met data onderbouwde content. Vage FAQ-antwoorden zoals “Het is heel nuttig”, “Veel experts raden het aan” of “Je zult aanzienlijke verbeteringen zien” bieden geen feiten die AI-platforms kunnen citeren. Specifieke, citeerbare antwoorden bevatten gekwantificeerde claims met gezaghebbende bronnen en links. Onvolledige antwoorden die direct vervolgvragen oproepen, zijn ook ineffectief. Laat je FAQ-antwoord gebruikers met nieuwe vragen achter, dan is het onvolledig. Zorg dat antwoorden zelfstandig zijn met volledige informatie, specifieke data en externe citaties waar relevant—niet afhankelijk van omliggende content voor begrip.
Het meten van FAQ Schema-succes is fundamenteel verschoven van traditionele SEO-metrics naar AI-zoekmetrics. Traditioneel werd FAQ Schema-succes gemeten via FAQ rich result-impressies in Google Search Console en doorklikpercentages vanuit zoekresultaten. AI-zoekmetrics richten zich op citatiefrequentie in ChatGPT-, Perplexity- en AI Overview-antwoorden. Dit betekent een paradigmawisseling in hoe contentteams FAQ Schema-ROI moeten beoordelen. In plaats van te vragen “Hoeveel rich result-impressies kregen we?”, moeten teams vragen “Hoe vaak werd onze FAQ-content geciteerd in AI-gegenereerde antwoorden?” en “Welk percentage AI-antwoorden over ons onderwerp bevat onze content?”
AI-citaties bijhouden vereist andere tools en methodes dan traditionele SEO-monitoring. Platforms zoals AmICited stellen merken in staat te volgen waar hun FAQ-content verschijnt in ChatGPT, Perplexity, Google AI Overviews en Claude—voor directe zichtbaarheid van AI-zoekprestaties. Door citatiefrequentie over tijd te volgen, meten contentteams het directe effect van FAQ Schema-implementatie op AI-zichtbaarheid. Ook het monitoren van featured snippet-verschijningen blijft waardevol, omdat deze data leveren aan Google AI Overviews en een dubbel voordeel bieden: meer zichtbaarheid in traditionele zoekresultaten EN grotere kans op AI-citatie. Voor teams met meerdere FAQ-implementaties helpen vragenonderzoekstools te bepalen welke vragen maximale AI-citatiepotentie hebben op basis van zoekvolume en relevantie.
De toekomst van FAQ Schema is onlosmakelijk verbonden met de evolutie van AI-zoekopdrachten en de verdere ontwikkeling van generatieve engines. Nu steeds meer gebruikers antwoorden zoeken via ChatGPT, Perplexity en Google AI Overviews in plaats van traditionele zoekresultaten, wordt FAQ Schema een basisvoorwaarde voor contentzichtbaarheid. De verschuiving van “klikken” naar “citaten” als primaire succesmaatstaf voor content is al begonnen en zal versnellen. Vroege signalen tonen dat dubbele optimalisatie—content maken die zowel goed scoort in traditionele zoekresultaten ALS AI-citaties oplevert—samengestelde resultaten biedt. Content die in Google’s top 10 rankt en goed FAQ Schema heeft, verschijnt in blauwe links, featured snippets én AI Overviews, en domineert zo het zoeklandschap voor doelzoekopdrachten.
AI-platforms zullen waarschijnlijk blijven verfijnen hoe ze FAQ-content extraheren en citeren, mogelijk met meer geavanceerde methodes voor het identificeren van hoogwaardige, gezaghebbende FAQ-bronnen. Naarmate AI-systemen beter worden in het detecteren en bestraffen van lage kwaliteit of manipulerende FAQ-implementaties, wordt het belang van oprechte, gebruikersgerichte FAQ-content alleen maar groter. Daarnaast zal het vraag-antwoordformaat, naarmate voice search en conversatie-AI-vragen toenemen, nog centraler worden voor de interactie van gebruikers met zoeksystemen. Organisaties die nu investeren in hoogwaardige FAQ Schema-implementatie, zijn goed gepositioneerd voor zichtbaarheid op alle grote AI-platforms naarmate deze technologieën verder ontwikkelen.
FAQ Schema is gestructureerde data-opmaak in JSON-LD-formaat die vragen en antwoorden op webpagina’s expliciet labelt, zodat zoekmachines en AI-platforms contentrelaties begrijpen.
AI-citatiegraad is het hoogst voor FAQ Schema onder gestructureerde datatypes: pagina’s met FAQPage-markup verschijnen veel vaker in ChatGPT, Perplexity en Google AI Overviews dan ongestructureerde content.
Google beperkte FAQ rich results in augustus 2023 tot overheids- en gezondheidswebsites, maar FAQ Schema blijft onmisbaar voor featured snippets, voice search en vooral AI-zoekoptimalisatie.
Platform-specifieke optimalisatie is belangrijk—ChatGPT heeft voorkeur voor neutrale, gezaghebbende content met citaties; Perplexity voor conversatiestijl, ervaringsgerichte antwoorden; Google AI Overviews legt de nadruk op E-E-A-T-signalen en mobile optimalisatie.
Ideale FAQ-antwoorden zijn 40-60 woorden, zelfstandig met volledige context, specifieke data en externe citaties—niet afhankelijk van omliggende content.
Veelgemaakte fouten zijn FAQ-content verbergen voor gebruikers, FAQ Schema gebruiken voor marketing, vage antwoorden schrijven en schema-markup niet valideren voor publicatie.
Succesmeting is verschoven van traditionele SEO-metrics (rich result-impressies) naar AI-zoekmetrics (citatie in AI-gegenereerde antwoorden).
De toekomst van FAQ Schema is verbonden met AI-zoekevolutie—nu AI-verwijzingssessies exponentieel blijven groeien, wordt FAQ Schema-implementatie steeds essentiëler voor contentzichtbaarheid.
FAQ Schema (FAQPage) is gestructureerde data-opmaak die het JSON-LD-formaat gebruikt om vragen en de bijbehorende antwoorden op webpagina's expliciet te labelen. Het helpt zoekmachines en AI-platforms de vraag-antwoordrelatie te begrijpen, waardoor deze systemen jouw content gemakkelijker kunnen extraheren, verifiëren en citeren in gegenereerde antwoorden. Het schema fungeert als metadata die machines kunnen lezen om de Q&A-structuur te identificeren, ongeacht het paginadesign of variaties in opmaak.
Ja, maar de waarde is verschoven van traditionele SEO naar AI-zoekoptimalisatie. Google beperkte FAQ rich results tot overheids- en gezondheidswebsites in augustus 2023, waardoor zichtbare FAQ-snippets voor de meeste bedrijven afnamen. FAQ Schema blijft echter cruciaal voor featured snippets, voice search en vooral AI-zoekplatforms zoals ChatGPT en Perplexity, die sterk vertrouwen op gestructureerde FAQ-data voor citaties. Het schema werd belangrijker voor generatieve engine-optimalisatie, ook al werd het minder zichtbaar in traditionele SERP's.
FAQ Schema heeft een van de hoogste citatiepercentages onder schema-types in AI-gegenereerde antwoorden, omdat het vraag-antwoordformaat aansluit bij hoe AI-platforms informatie presenteren. Gestructureerde FAQ-data haalt de interpretatielast weg bij natuurlijke taalverwerking, waardoor AI direct antwoorden kan extraheren en bronnen nauwkeurig kan citeren. Pagina's met FAQ Schema zijn 3,2x vaker te zien in Google AI Overviews dan pagina's zonder FAQ-gestructureerde data, volgens de analyse van Search Engine Land uit 2024.
Voor traditionele SEO was FAQ Schema gericht op rich results en featured snippets in de Google-zoekresultaten. Voor GEO (Generative Engine Optimization) en AEO (Answer Engine Optimization) stelt FAQ Schema AI-platforms in staat jouw content te extraheren, begrijpen en te citeren in gegenereerde antwoorden via ChatGPT, Perplexity en Google AI Overviews. De focus verschoof van klikken genereren via zichtbare rich results naar citaties verdienen in AI-gegenereerde antwoorden die gebruikers lezen zonder door te klikken naar bronsites.
Plaats 5-10 FAQ-vragen per pagina voor pijlercontent. Minder dan 5 biedt beperkte waarde voor gebruikers en AI-extractiemogelijkheden; meer dan 10 kan de focus verwateren en lezers overweldigen. Kwaliteit is belangrijker dan kwantiteit—beantwoord echte gebruikersvragen volledig met antwoorden van 40-60 woorden die specifieke data, externe citaties en volledige context bevatten. Gebruik vragenonderzoekstools om te bepalen welke vragen daadwerkelijk zoekvraag hebben voordat je het schema implementeert.
Ja, zolang de FAQ's echt informatief en niet promotioneel zijn. Google's richtlijnen voor gestructureerde data verbieden FAQ Schema voor reclame- of marketinginhoud. Richt je op het beantwoorden van echte klantvragen over functies, prijzen, verzending, gebruik, compatibiliteit of ondersteuning. Acceptabele vragen zijn bijvoorbeeld 'Welke functies zijn inbegrepen?' of 'Hoe werkt de verzending?' Onacceptabele vragen zijn bijvoorbeeld 'Waarom zou je nu kopen?' of 'Waarom zijn wij de beste?'
40-60 woorden is ideaal voor AI-extractie, featured snippets en gebruikerservaring. Kortere antwoorden (onder 30 woorden) bieden vaak onvoldoende context om op zichzelf te staan. Langere antwoorden (meer dan 80 woorden) zijn moeilijker voor AI-platforms om als één geheel te extraheren en lastig voor gebruikers om snel te scannen. Zorg dat antwoorden op zichzelf staan met volledige informatie, specifieke data en externe citaties waar nodig—en niet afhankelijk zijn van omliggende content voor begrip.
Gebruik de Google Rich Results Test om JSON-LD-syntaxis te valideren, ontbrekende eigenschappen te detecteren en te bekijken hoe Google jouw opmaak interpreteert. Controleer daarnaast mobiele weergave (waar spraakassistenten werken), zorg dat vragen exact overeenkomen met zichtbare paginakoppen, test of antwoorden op zichzelf staan en volledig zijn, en monitor of jouw FAQ-content verschijnt in AI-gegenereerde antwoorden gedurende 2-4 weken na implementatie. Periodieke her-validatie na site-updates voorkomt regressie en waarborgt blijvende compatibiliteit.
Begin met het volgen van hoe AI-chatbots uw merk vermelden op ChatGPT, Perplexity en andere platforms. Krijg bruikbare inzichten om uw AI-aanwezigheid te verbeteren.
Leer hoe je FAQ-schema implementeert voor AI-zoekmachines. Stapsgewijze gids met JSON-LD-formaat, best practices, validatie en optimalisatie voor AI-platforms z...
Discussie in de community over het implementeren van FAQ-schema voor AI-zichtbaarheid. Technische SEO-professionals delen ervaringen, beste implementatiepraktij...
Ontdek waarom FAQ-schema de hoogste citatiepercentages heeft voor AI-zoekopdrachten. Complete gids voor FAQPage gestructureerde data voor ChatGPT, Perplexity en...
Cookie Toestemming
We gebruiken cookies om uw browse-ervaring te verbeteren en ons verkeer te analyseren. See our privacy policy.