Definitie van LSI-trefwoorden
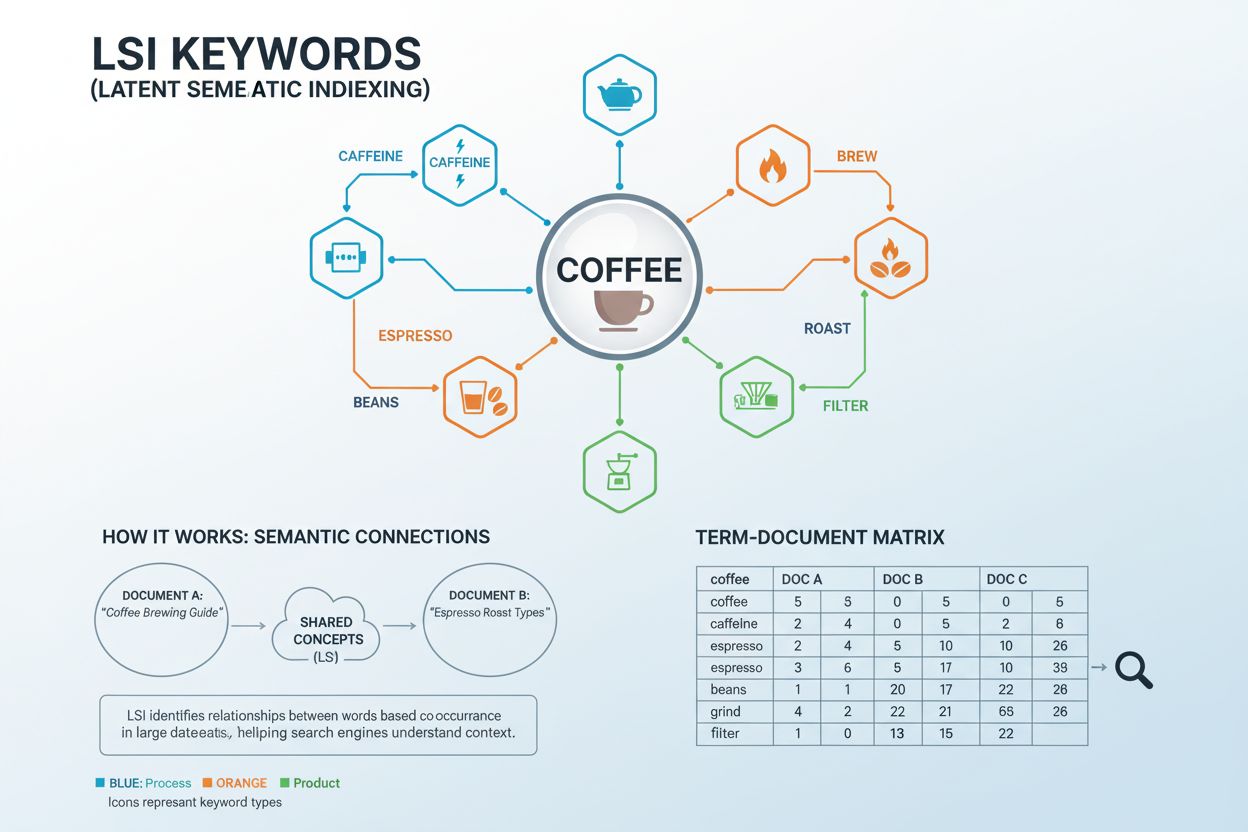
LSI-trefwoorden (Latent Semantic Indexing Keywords) zijn woorden en zinnen die conceptueel verwant zijn aan je doelzoekwoord en die vaak samen voorkomen in vergelijkbare contexten. De term komt voort uit een wiskundige techniek die in de jaren 80 is ontwikkeld om verborgen semantische relaties tussen woorden in grote documentverzamelingen te analyseren. In praktische SEO-termen zijn LSI-trefwoorden zoektermen die zoekmachines en AI-systemen helpen om de bredere context en het onderwerp van je content te begrijpen, en niet alleen op exacte zoekwoordcombinaties te letten. Bijvoorbeeld, als je hoofdzoekwoord “koffie” is, kunnen gerelateerde LSI-trefwoorden “cafeïne”, “zetten”, “espresso”, “bonen”, “branden” en “malen” zijn. Deze termen werken samen om aan zoekmachines te signaleren dat je content het onderwerp koffie volledig dekt en niet alleen het woord herhaaldelijk noemt.
Historische context en evolutie van LSI-trefwoorden
Latent Semantic Indexing werd geïntroduceerd in een baanbrekend onderzoek uit 1988 als “een nieuwe aanpak voor het vocabulaireprobleem in mens-computerinteractie”. De technologie was ontworpen om een fundamenteel probleem op te lossen: zoekmachines waren te afhankelijk van exacte zoekwoordovereenkomsten, waardoor relevante documenten vaak niet werden gevonden als gebruikers andere termen of synoniemen gebruikten. In 2004 implementeerde Google LSI-concepten in zijn zoekalgoritme, wat een belangrijke verschuiving betekende in hoe zoekmachines content begrepen. Dankzij deze update kon Google verder kijken dan eenvoudige analyse van zoekwoordfrequentie en begon het context, betekenis en conceptuele relaties tussen termen te begrijpen. Volgens eigen onderzoek van Google is meer dan 15% van de dagelijkse zoekopdrachten bij Google een nieuwe term die nooit eerder is gezocht, waardoor contextueel begrip via gerelateerde termen steeds belangrijker wordt. De evolutie van LSI naar moderne semantische analyse is een van de belangrijkste verschuivingen in zoekmachinetechnologie en heeft de manier waarop contentmakers optimaliseren fundamenteel veranderd.
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
LSI-trefwoorden versus gerelateerde terminologie: Vergelijkingstabel
| Term | Definitie | Focus | Relatie tot hoofdzoekwoord | Impact op moderne SEO |
|---|
| LSI-trefwoorden | Woorden die samen met het hoofdzoekwoord voorkomen op basis van wiskundige analyse | Patronen in woordfrequentie en co-occurrence | Directe contextuele relatie | Beperkt (Google gebruikt LSI-algoritme niet) |
| Semantische trefwoorden | Conceptueel verwante termen die inspelen op gebruikersintentie en diepgang | Betekenis en gebruikersintentie | Brede thematische relatie | Hoog (essentieel voor moderne SEO) |
| Synoniemen | Woorden met identieke of zeer vergelijkbare betekenis | Directe woordvervanging | Zelfde betekenis, ander woord | Gemiddeld (nuttig, maar niet het hoofdfocuspunt) |
| Long-tail zoekwoorden | Langere, specifiekere zoekwoordzinnen | Zoekvolume en specificiteit | Meer specifieke versie van hoofdzoekwoord | Hoog (minder concurrentie, hogere intentie) |
| Gerelateerde zoekwoorden | Termen die vaak samen met het hoofdzoekwoord worden gezocht | Zoekgedragspatronen | Zoekpatronen van gebruikers | Hoog (geeft gebruikersintentie aan) |
| Entity-trefwoorden | Genaamd entities en concepten gerelateerd aan het onderwerp | Entity-relaties en kennisgrafen | Conceptuele en categorische relatie | Zeer hoog (AI-systemen geven prioriteit aan entities) |
De wiskundige basis: Hoe werken LSI-trefwoorden?
Latent Semantic Indexing werkt via een geavanceerd wiskundig proces genaamd Singular Value Decomposition (SVD), dat de relaties tussen woorden in grote documentverzamelingen analyseert. Het systeem begint met het opstellen van een Term Document Matrix (TDM)—een tweedimensionaal raster dat bijhoudt hoe vaak elk woord in verschillende documenten voorkomt. Stopwoorden (veelvoorkomende woorden zoals “de”, “en”, “is”) worden verwijderd om inhoudsdragende termen te isoleren. Vervolgens past het algoritme wegingen toe om co-occurrence-patronen te identificeren—gevallen waarin specifieke woorden samen met vergelijkbare frequentie in meerdere documenten voorkomen. Wanneer woorden consequent samen in vergelijkbare contexten verschijnen, herkent het systeem ze als semantisch verwant. Bijvoorbeeld, de woorden “koffie”, “zetten”, “espresso” en “cafeïne” komen vaak samen voor in documenten over dranken, wat hun semantische relatie aangeeft. Dankzij deze wiskundige aanpak kunnen computers begrijpen dat “espresso” en “koffie” gerelateerde concepten zijn zonder dat daar expliciete regels voor nodig zijn. De SVD-vectoren die uit deze analyse voortkomen, voorspellen de betekenis nauwkeuriger dan het analyseren van losse termen, waardoor zoekmachines content op een dieper conceptueel niveau kunnen begrijpen dan alleen op basis van zoekwoorden.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Waarom Google geen LSI gebruikt (maar nog steeds waarde hecht aan semantisch begrip)
Ondanks de theoretische elegantie van Latent Semantic Indexing heeft Google expliciet verklaard dat het LSI niet gebruikt in zijn rankingalgoritme. John Mueller, een Google-vertegenwoordiger, bevestigde in 2019: “Er bestaat niet zoiets als LSI-trefwoorden—iedereen die anders beweert heeft het mis, sorry.” Er zijn verschillende redenen waarom Google LSI heeft verlaten voor modernere benaderingen. Ten eerste was LSI ontworpen voor kleinere, statische documentverzamelingen, niet voor het dynamische, voortdurend uitbreidende World Wide Web. Het originele LSI-octrooi, toegekend aan Bell Communications Research in 1989, verliep in 2008, maar Google was toen al verder ontwikkeld. Belangrijker nog, Google ontwikkelde veel geavanceerdere systemen zoals RankBrain (geïntroduceerd in 2015), dat machine learning gebruikt om tekst om te zetten in wiskundige vectoren die computers kunnen begrijpen. Later introduceerde Google BERT (Bidirectional Encoder Representations from Transformers) in 2019, dat woorden bidirectioneel analyseert—alle woorden vóór en na een specifieke term worden meegenomen om de context te begrijpen. In tegenstelling tot LSI, dat stopwoorden verwijdert, herkent BERT dat kleine woorden zoals “vind” in “Waar kan ik een lokale tandarts vinden?” cruciaal zijn voor het begrijpen van zoekintentie. Tegenwoordig gebruikt Google MUM (Multitask Unified Model) en AI Overviews om contextuele samenvattingen direct in de zoekresultaten te genereren, wat een evolutie is die ver voorbij gaat aan wat LSI ooit kon bereiken.
Semantische SEO: De moderne evolutie van LSI-concepten
Hoewel LSI-trefwoorden als specifieke technologie verouderd zijn, blijft het onderliggende principe—dat zoekmachines de context en betekenis van inhoud moeten begrijpen—fundamenteel voor moderne SEO. Semantische SEO is de evolutie van dit concept, met de focus op gebruikersintentie, thematische autoriteit en volledige dekking van onderwerpen in plaats van op patronen in zoekwoordfrequentie. Volgens gegevens uit 2025 bestaat circa 74% van alle zoekopdrachten nu uit long-tail zinnen, waardoor semantisch begrip cruciaal is om diverse doelgroepen te bereiken. Semantische SEO benadrukt het creëren van content die een onderwerp grondig vanuit meerdere invalshoeken behandelt, waarbij gerelateerde concepten en antwoorden op gerelateerde vragen op natuurlijke wijze worden geïntegreerd. Deze aanpak sluit aan bij hoe moderne AI-systemen zoals ChatGPT, Perplexity, Google AI Overviews en Claude bronmateriaal beoordelen. Deze systemen geven prioriteit aan content die expertise, volledigheid en duidelijke thematische autoriteit aantoont—kwaliteiten die vanzelf ontstaan als je semantisch gerelateerde termen en concepten opneemt. De verschuiving van LSI naar semantische SEO betekent een volwassenwording van zoektechnologie, waarbij wordt overgestapt van wiskundige patroonherkenning naar daadwerkelijk contextueel begrip dankzij neurale netwerken en machine learning.
Praktische implementatie: Waar en hoe gerelateerde trefwoorden te gebruiken
Het opnemen van LSI-trefwoorden en semantisch gerelateerde termen in je content vereist strategische plaatsing en natuurlijke integratie. De meest effectieve plekken voor deze termen zijn title-tags en H1-koppen, die zwaar meewegen in de beoordeling door zoekmachines. H2- en H3-subkoppen bieden uitstekende mogelijkheden om gerelateerde concepten op natuurlijke wijze te introduceren en je content logisch te structureren. Afbeelding-alt-tekst is een andere waardevolle plek, waarmee je de thematische relevantie versterkt en de toegankelijkheid verbetert. In de hoofdtekst moeten gerelateerde termen op een natuurlijke manier in zinnen en paragrafen worden verweven, zodat ze het hoofdverhaal ondersteunen zonder het te onderbreken. Meta descriptions kunnen gerelateerde trefwoorden bevatten om de doorklikratio uit zoekresultaten te verbeteren. Interne link-anchor-tekst biedt extra kansen om semantische relaties tussen gerelateerde pagina’s op je site te versterken. Het belangrijkste principe is natuurlijke integratie—als een gerelateerde term niet natuurlijk in je content past, moet je hem niet forceren. Onderzoek toont aan dat content met één LSI-trefwoord per 200-300 woorden de optimale balans biedt tussen semantische rijkdom en leesbaarheid. Deze verhouding is geen harde regel, maar een nuttige richtlijn om voldoende thematische dekking te bieden zonder keyword stuffing.
LSI-trefwoorden en AI-zoekzichtbaarheid
Voor merken en contentmakers die zich richten op AI-zoekzichtbaarheid en citaties op platforms zoals AmICited, wordt inzicht in LSI-trefwoorden en semantische relaties steeds belangrijker. AI-systemen die antwoorden genereren voor ChatGPT, Perplexity, Google AI Overviews en Claude beoordelen bronmateriaal op thematische volledigheid en signalen van expertise. Wanneer je content semantisch gerelateerde termen en concepten bevat, geeft dat deze AI-systemen het signaal dat je een onderwerp grondig hebt behandeld. Deze volledige dekking vergroot de kans dat je content wordt geselecteerd als bron voor AI-gegenereerde antwoorden. Daarnaast helpen semantische trefwoorden bij het opbouwen van entity-relaties—verbindingen tussen concepten die AI-systemen gebruiken om kennisdomeinen te begrijpen. Bijvoorbeeld, content over “koffie” waarin gerelateerde entiteiten als “cafeïne”, “espressomachines”, “koffiebonen” en “zetmethoden” aan bod komen, toont een bredere expertise dan content die alleen het hoofdzoekwoord noemt. Deze entity-rijke content wordt eerder geciteerd door AI-systemen die uitgebreide antwoorden genereren. Naarmate AI-zoek verder evolueert, wordt het vermogen om thematische autoriteit aan te tonen via semantische rijkdom een cruciaal concurrentievoordeel voor zichtbaarheid en citaties.
Belangrijke aspecten van LSI-trefwoorden en semantische optimalisatie
- Contextuele relaties: Gerelateerde termen die vaak samen in vergelijkbare contexten voorkomen, waardoor zoekmachines de betekenis van content begrijpen, voorbij exacte zoekwoordovereenkomsten
- Co-occurrence-patronen: Woorden die consequent samen in meerdere documenten voorkomen, signaleren semantische relaties aan zoekalgoritmes
- Thematische autoriteit: Volledige dekking van een onderwerp via gerelateerde concepten, waardoor je expertise en betrouwbaarheid toont aan zowel zoekmachines als AI-systemen
- Natuurlijke integratie: Vloeiende opname van gerelateerde termen in content die natuurlijk leest voor mensen en tegelijk relevantie signaleert aan zoekmachines
- Afstemming op zoekintentie: Gebruik van semantisch gerelateerde termen die aansluiten bij waar gebruikers daadwerkelijk naar zoeken, wat de relevantie en doorklikratio verbetert
- Entity-herkenning: Identificeren en opnemen van benoemde entiteiten en concepten die met je hoofdonderwerp te maken hebben, essentieel voor beoordeling door AI-systemen
- Semantische rijkdom: De diepgang en breedte van conceptueel gerelateerde content, wat volledige thematische dekking aangeeft
- Long-tail zoekwoordvariaties: Langere, specifiekere zinnen die gerelateerde zoekintenties vangen en de concurrentie verlagen
- Inhoudelijke volledigheid: Behandelen van meerdere invalshoeken en subonderwerpen gerelateerd aan je hoofdzoekwoord, wat de algehele contentkwaliteit verbetert
- AI-citatiepotentieel: Expertise tonen via semantische dekking vergroot de kans om geciteerd te worden door AI-systemen zoals ChatGPT en Perplexity
De toekomst van semantisch begrip in zoeken
De ontwikkeling van zoektechnologie wijst duidelijk op steeds geavanceerder semantisch begrip, aangedreven door kunstmatige intelligentie en machine learning. LSI-trefwoorden als specifieke technologie waren een vroege poging om het semantische begrip te verbeteren, maar moderne benaderingen zijn deze mogelijkheden ruimschoots voorbijgestreefd. Toekomstige zoeksystemen zullen waarschijnlijk nog meer vertrouwen op neurale netwerken, transformermodelen en grote taalmodellen om niet alleen te begrijpen wat er in content staat, maar ook wat het betekent in bredere contexten. De opkomst van Generative Engine Optimization (GEO) als discipline weerspiegelt deze verschuiving—marketeers moeten nu niet alleen optimaliseren voor traditionele zoekmachines, maar ook voor AI-systemen die antwoorden genereren. Deze AI-systemen beoordelen bronmateriaal op volledigheid, expertise en thematische autoriteit—kwaliteiten die vanzelf ontstaan uit semantische optimalisatie. Nu AI Overviews steeds vaker in zoekresultaten verschijnen, wordt het aantonen van thematische expertise via semantisch rijke content steeds waardevoller. De toekomst zal waarschijnlijk een nog nauwere integratie brengen tussen traditionele SEO en AI-optimalisatie, waarbij semantisch begrip de brug vormt tussen deze disciplines. Contentmakers die de principes van semantische optimalisatie begrijpen en toepassen, behouden zichtbaarheid als zoektechnologie zich verder ontwikkelt.
Conclusie: Van LSI-trefwoorden naar semantische autoriteit
Hoewel LSI-trefwoorden als specifieke algoritmische aanpak niet meer door Google worden gebruikt, blijft het onderliggende principe—dat zoekmachines de context en betekenis van content moeten begrijpen—relevanter dan ooit. De evolutie van LSI naar semantische SEO en moderne AI-optimalisatie is een logische voortgang in de manier waarop zoektechnologie content begrijpt en beoordeelt. Voor contentmakers en merken die zich richten op zichtbaarheid in zoekmachines en AI-platforms is de praktische les duidelijk: maak volledige, thematisch rijke content die op natuurlijke wijze gerelateerde concepten opneemt en expertise aantoont. Deze aanpak voldoet zowel aan de eisen van traditionele zoekmachines als aan de beoordelingscriteria van AI-systemen zoals ChatGPT, Perplexity, Google AI Overviews en Claude. Door de relaties te begrijpen tussen je hoofdzoekwoord en semantisch gerelateerde termen kun je content creëren die goed scoort in traditionele zoekresultaten én wordt geciteerd als gezaghebbende bron door AI-systemen. De toekomst van zoekzichtbaarheid is voorbehouden aan wie semantische optimalisatie beheerst—niet door keyword stuffing of geforceerde termopname, maar door echte expertise en volledige dekking van onderwerpen, waarbij gerelateerde concepten op natuurlijke wijze worden geïntegreerd en blijk wordt gegeven van diepgaand begrip van het vakgebied.