
Meta AI Optimalisatie: De AI-assistent van Facebook en Instagram
Ontdek hoe Meta AI-optimalisatie Facebook- en Instagram-advertenties transformeert met AI-gedreven automatisering, realtime bieden en intelligente doelgroepbepa...
6 min lezen
Meta-ExternalAgent is de webcrawler-bot van Meta, gelanceerd in juli 2024 om publiek beschikbare content te verzamelen voor het trainen van AI-modellen zoals LLaMA. De bot identificeert zich met de User-Agent-string meta-externalagent/1.1 en bepaalt of content verschijnt in Meta AI-antwoorden op Facebook, Instagram en WhatsApp. Uitgevers kunnen de bot blokkeren via robots.txt of serverinstellingen, hoewel naleving vrijwillig is en niet juridisch bindend.
Meta-ExternalAgent is de webcrawler-bot van Meta, gelanceerd in juli 2024 om publiek beschikbare content te verzamelen voor het trainen van AI-modellen zoals LLaMA. De bot identificeert zich met de User-Agent-string meta-externalagent/1.1 en bepaalt of content verschijnt in Meta AI-antwoorden op Facebook, Instagram en WhatsApp. Uitgevers kunnen de bot blokkeren via robots.txt of serverinstellingen, hoewel naleving vrijwillig is en niet juridisch bindend.
Meta-ExternalAgent is een webcrawler beheerd door Meta Platforms, gelanceerd in juli 2024 om gegevens te verzamelen voor het trainen van kunstmatige intelligentiemodellen. Deze crawler is te herkennen aan de User-Agent-string meta-externalagent/1.1 en verschilt van Meta’s oudere facebookexternalhit-crawler, die voornamelijk werd gebruikt voor linkvoorbeelden en sociale deelmogelijkheden. Meta-ExternalAgent betekent een belangrijke verschuiving in hoe Meta trainingsdata verzamelt voor AI-initiatieven, waaronder de LLaMA-taalmodellen en de Meta AI-chatbot die is geïntegreerd in Facebook, Instagram en WhatsApp. In tegenstelling tot eerdere Meta-crawlers werkt deze bot met minimale transparantie en werd hij geïntroduceerd zonder formele publieke aankondiging.

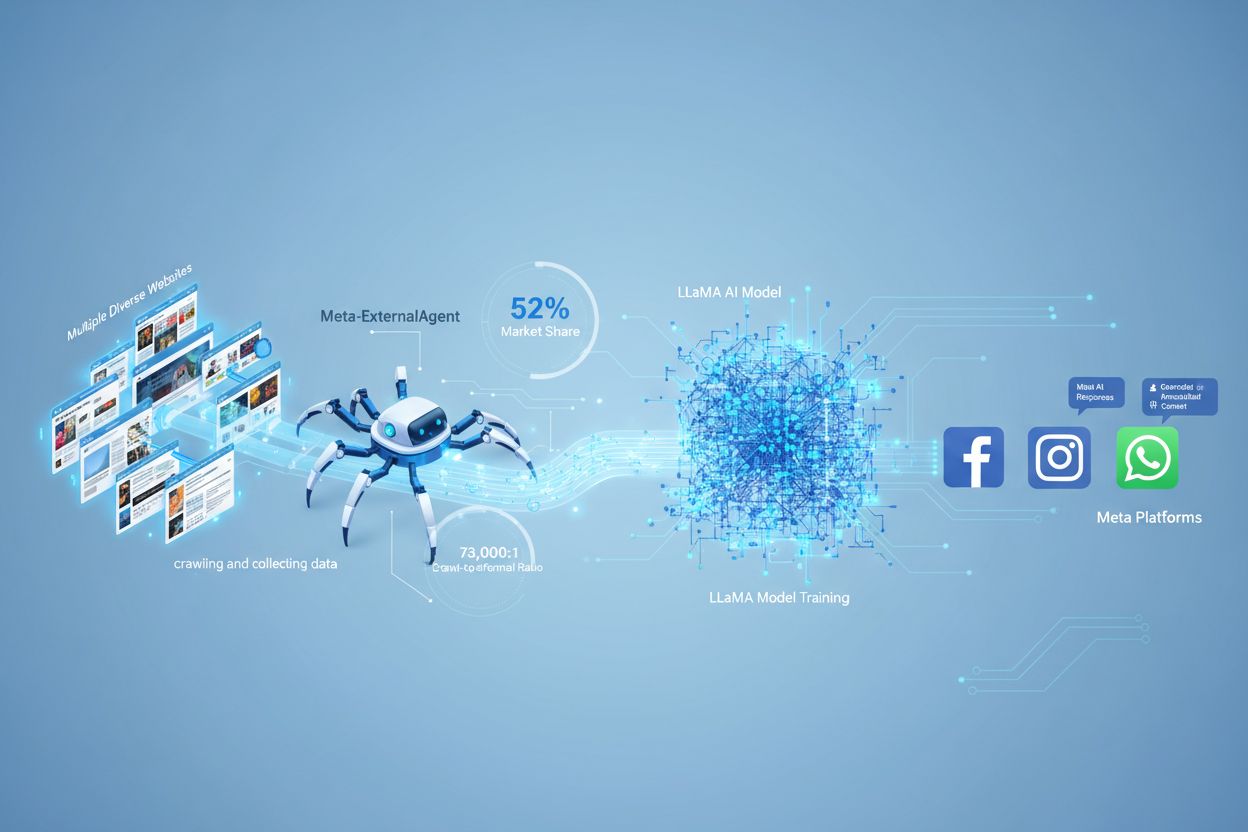
Meta-ExternalAgent functioneert als een geautomatiseerde bot die systematisch websites over het internet crawlt om tekst en content te verzamelen voor AI-training. De crawler verstuurt HTTP-verzoeken naar webservers, identificeert zich met een unieke User-Agent-header en downloadt paginacontent voor verwerking. Zodra de content is verzameld, analyseren en tokeniseren de systemen van Meta de tekst en zetten deze om in trainingsdata waarmee zij hun grote taalmodellen verbeteren. De crawler respecteert het robots.txt-bestand op vrijwillige basis, maar dit is een erecode en geen wettelijk vereiste. Volgens data van Cloudflare is Meta-ExternalAgent verantwoordelijk voor ongeveer 52% van al het AI-crawlerverkeer op het internet, waarmee het tot de meest agressieve dataverzamelingsoperaties in de AI-industrie behoort. De crawler werkt continu; sommige uitgevers melden crawl-frequenties die suggereren dat Meta volledige dekking van webcontent belangrijker vindt dan selectieve, gerichte verzameling.
| Naam crawler | User-Agent-string | Primair doel | Lancering | Gegevensgebruik |
|---|---|---|---|---|
| Meta-ExternalAgent | meta-externalagent/1.1 | AI-modeltraining (LLaMA, Meta AI) | juli 2024 | Trainingsdata voor generatieve AI |
| facebookexternalhit | facebookexternalhit/1.1 | Linkvoorbeelden en social sharing | ~2010 | Open Graph-metadata, thumbnails |
| Facebot | facebot/1.0 | Inhoudsverificatie Facebook-app | ~2015 | Contentvalidatie voor mobiele apps |
| Applebot | Applebot/0.1 | Apple Siri en zoekindexering | ~2015 | Zoekindexering en spraakassistent |
| Googlebot | Googlebot/2.1 | Google Search-indexering | ~1998 | Zoekmachine-indexering |
Meta-ExternalAgent is een kritisch aandachtspunt voor contentmakers en uitgevers, omdat het op ongekende schaal opereert en minimale transparantie biedt over hoe content wordt gebruikt. Volgens onderzoek van Cloudflare is Meta-ExternalAgent verantwoordelijk voor 52% van al het AI-crawlerverkeer, veel meer dan concurrenten als OpenAI’s GPTBot en Google’s AI-crawlers. Deze dominantie betekent dat Meta meer trainingsdata verzamelt dan enig ander AI-bedrijf, terwijl uitgevers geen compensatie of naamsvermelding ontvangen wanneer hun content wordt gebruikt om Meta’s AI-modellen te trainen. De 73.000:1 crawl-to-referral ratio laat zien dat Meta enorme hoeveelheden content onttrekt en vrijwel geen verkeer terugstuurt naar de bronwebsites — een fundamentele onbalans in de waarde-uitwisseling. Ondanks deze zorgen blokkeert slechts 2% van de websites Meta-ExternalAgent actief, tegenover 25% die GPTBot blokkeert, wat suggereert dat veel uitgevers zich niet bewust zijn van de aanwezigheid of gevolgen van de crawler. Nu Meta $40 miljard investeert in AI-infrastructuur, zal de inzet op agressieve dataverzameling waarschijnlijk toenemen, waardoor het essentieel is voor uitgevers om hun relatie met deze crawler te begrijpen en actief te beheren.
Uitgevers kunnen toegang van Meta-ExternalAgent beheren via het robots.txt-bestand, maar het is belangrijk te beseffen dat deze methode op vrijwillige basis werkt en niet juridisch afdwingbaar is. Om Meta-ExternalAgent te blokkeren voegt u de volgende regel toe aan uw robots.txt:
User-agent: meta-externalagent
Disallow: /
Wilt u de crawler wel toestaan maar beperken tot specifieke mappen, gebruik dan:
User-agent: meta-externalagent
Disallow: /private/
Disallow: /admin/
Allow: /public/
Sommige uitgevers melden echter dat Meta-ExternalAgent hun sites blijft crawlen, ook na een robots.txt-blokkade, wat suggereert dat Meta deze richtlijnen niet altijd naleeft. Voor uitgebreidere bescherming kunnen uitgevers blokkering op basis van HTTP-headers implementeren of CDN-regels gebruiken om verzoeken met de User-Agent-string van Meta-ExternalAgent te identificeren en af te wijzen. Ook kunnen uitgevers hun serverlogs controleren op de User-Agent-string meta-externalagent/1.1 om te verifiëren of de crawler hun content bezoekt. Tools zoals AmICited.com helpen uitgevers om te volgen of hun content wordt geciteerd of gebruikt in Meta AI-antwoorden, en bieden zo inzicht in het gebruik van hun werk door de AI-systemen van Meta.

Wanneer gebruikers communiceren met Meta AI-chatbots op Facebook, Instagram of WhatsApp, zijn de gegenereerde antwoorden deels gebaseerd op content die door Meta-ExternalAgent is verzameld. Meta AI-antwoorden bevatten echter meestal geen zichtbare bronvermeldingen of naamsvermelding, waardoor gebruikers niet weten welke uitgeverscontent heeft bijgedragen aan het antwoord. Dit gebrek aan transparantie vormt een aanzienlijke uitdaging voor contentmakers die willen weten welke waarde hun werk levert aan de AI-systemen van Meta. In tegenstelling tot sommige concurrenten die citaties opnemen in AI-antwoorden, kiest Meta voor gebruikerservaring boven bronvermelding van uitgevers. Het ontbreken van zichtbare bronvermelding betekent ook dat uitgevers niet eenvoudig kunnen nagaan hoe vaak hun content invloed heeft op Meta AI-antwoorden, waardoor het lastig is om de zakelijke impact van het gebruik van hun content voor AI-training te beoordelen. Dit gebrek aan inzicht is een van de belangrijkste redenen waarom monitoringoplossingen steeds belangrijker worden voor uitgevers die hun rol in het AI-ecosysteem willen begrijpen.
Uitgevers kunnen Meta-ExternalAgent-activiteit verifiëren door analyse van serverlogs, waarin de IP-adressen, aanvraagpatronen en frequentie van contenttoegang van de crawler zichtbaar zijn. Door toegangslogs te bekijken, kunnen uitgevers verzoeken identificeren met de User-Agent-string meta-externalagent/1.1 en bepalen welke pagina’s het vaakst gecrawld worden. Geavanceerde monitoringtools kunnen crawlpatronen over de tijd volgen en laten zien of Meta bepaalde contenttypen of secties van een website prioriteert. Uitgevers dienen ook hun bandbreedtegebruik te monitoren, aangezien agressief crawlen door Meta-ExternalAgent aanzienlijke serverresources kan verbruiken, zeker bij grote contentbibliotheken. Daarnaast kunnen uitgevers tools zoals AmICited.com gebruiken om te volgen of hun content verschijnt in Meta AI-antwoorden en citatiepatronen te analyseren over Meta’s platformen. Alerting voor ongebruikelijke crawleractiviteit helpt uitgevers om veranderingen in het dataverzamelgedrag van Meta tijdig te detecteren en proactief te reageren. Regelmatige audits van serverlogs zouden onderdeel moeten zijn van elk AI-crawlerbeheerbeleid, zodat uitgevers zicht houden op hoe hun content wordt benaderd en gebruikt.
De juridische status van Meta-ExternalAgent is omstreden, met lopende rechtszaken van contentmakers, artiesten en uitgevers die het recht van Meta betwisten om hun werk te gebruiken voor AI-training zonder expliciete toestemming of vergoeding. Terwijl Meta stelt dat webcrawlen valt onder het fair use-beginsel, stellen critici dat de schaal en het commerciële karakter van de dataverzameling, gecombineerd met het ontbreken van bronvermelding, neerkomt op auteursrechtschending. Het robots.txt-bestand, hoewel breed gerespecteerd als industriestandaard, heeft geen juridische kracht, waardoor Meta niet wettelijk verplicht is blokkades te respecteren. In diverse jurisdicties wordt regelgeving ontwikkeld rond AI-trainingsdataverzameling, waarbij de AI Act van de Europese Unie en voorgestelde wetgeving elders mogelijk strengere eisen stellen aan bedrijven als Meta. Vanuit ethisch oogpunt draait het om de vraag of contentmakers het recht moeten hebben om te bepalen hoe hun werk commercieel wordt gebruikt voor AI-training, en of het huidige systeem makers voldoende compenseert voor de waarde die hun content oplevert. Uitgevers doen er goed aan op de hoogte te blijven van juridische ontwikkelingen en eventueel juridisch advies in te winnen over hun rechten en plichten rondom AI-crawlertoegang. De balans tussen AI-innovatie en bescherming van makersrechten is nog niet gevonden en blijft onderwerp van juridische en regelgevende discussie.
Het landschap van AI-crawlerbeheer ontwikkelt zich snel nu uitgevers, toezichthouders en AI-bedrijven onderhandelen over de voorwaarden voor dataverzameling en -gebruik. De agressieve inzet van Meta-ExternalAgent duidt erop dat grote technologiebedrijven webcontent zien als essentieel trainingsmateriaal voor concurrerende AI-systemen, en deze trend zal waarschijnlijk versnellen naarmate AI steeds centraler komt te staan in hun strategie. Toekomstige ontwikkelingen kunnen bestaan uit sterkere juridische bescherming voor makers, verplichte licentiemodellen voor AI-trainingsdata en technische standaarden die het voor uitgevers gemakkelijker maken controle en monetisatie over het gebruik van hun content door AI-systemen te houden. De opkomst van tools als AmICited.com weerspiegelt de groeiende vraag naar transparantie en verantwoording in het gebruik van gepubliceerde content door AI, wat suggereert dat monitoring en verificatie standaardpraktijk zullen worden voor contentmakers. Naarmate de AI-industrie volwassen wordt, zullen er waarschijnlijk meer geavanceerde onderhandelingen plaatsvinden tussen makers en AI-bedrijven, mogelijk leidend tot nieuwe verdienmodellen die uitgevers eerlijk compenseren voor hun bijdrage aan AI-training.
Meta-ExternalAgent is de speciale AI-trainingscrawler van Meta, gelanceerd in juli 2024 en te herkennen aan de User-Agent-string meta-externalagent/1.1. Dit verschilt van facebookexternalhit, die linkvoorbeelden genereert voor sociaal delen. Meta-ExternalAgent verzamelt specifiek content voor het trainen van LLaMA-modellen en Meta AI, terwijl facebookexternalhit sinds ongeveer 2010 wordt gebruikt voor sociale functies.
U kunt Meta-ExternalAgent blokkeren door richtlijnen toe te voegen aan uw robots.txt-bestand. Voeg 'User-agent: meta-externalagent' toe gevolgd door 'Disallow: /' om deze volledig te blokkeren. Voor uitgebreidere bescherming kunt u serverniveau-blokkades implementeren via .htaccess (Apache) of Nginx-configuratieregels. Houd er echter rekening mee dat robots.txt vrijwillig is en niet juridisch bindend, waardoor sommige uitgevers melden dat er ondanks blokkades toch wordt gecrawld.
Nee, het blokkeren van Meta-ExternalAgent heeft geen invloed op Facebook-linkvoorbeelden. De crawler facebookexternalhit verzorgt de linkvoorbeelden en sociale deelmogelijkheden. U kunt meta-externalagent blokkeren terwijl facebookexternalhit gewoon aantrekkelijke voorbeelden blijft genereren wanneer uw content wordt gedeeld op Meta-platforms.
Meta-ExternalAgent heeft een crawl-to-referral-ratio van ongeveer 73.000:1, wat betekent dat Meta op enorme schaal content verzamelt terwijl er vrijwel geen verkeer teruggaat naar de oorspronkelijke websites. Dit vertegenwoordigt een fundamentele onbalans in vergelijking met traditionele zoekmachines, die content crawlen in ruil voor verwijzingsverkeer.
robots.txt is gebaseerd op vrijwilligheid en is niet juridisch bindend. Hoewel veel crawlers robots.txt-richtlijnen respecteren, hebben sommige uitgevers gemeld dat Meta-ExternalAgent hun sites blijft crawlen ondanks expliciete robots.txt-blokkades. Voor gegarandeerde bescherming implementeert u blokkering op serverniveau via HTTP-headers, CDN-regels of firewallconfiguraties.
Controleer uw servertoegangslogs op verzoeken met de User-Agent-string 'meta-externalagent/1.1'. U kunt ook monitoringtools zoals AmICited.com gebruiken om te volgen of uw content verschijnt in Meta AI-antwoorden. Tools zoals Dark Visitors en Cloudflare Analytics bieden extra inzicht in AI-crawleractiviteit op uw website.
Volgens data van Cloudflare is Meta-ExternalAgent verantwoordelijk voor ongeveer 52% van al het AI-crawlerverkeer op het internet, waardoor het de meest agressieve operatie voor AI-dataverzameling is. Dit ligt ver boven concurrenten zoals OpenAI's GPTBot en Google's AI-crawlers, wat wijst op Meta's dominante positie in het verzamelen van webcontent voor AI-training.
De beslissing hangt af van uw zakelijke prioriteiten. Als Meta AI-verkeer waardevol is voor uw publiek, kunt u het toestaan. Houd er echter rekening mee dat Meta geen compensatie of naamsvermelding biedt voor content die wordt gebruikt voor AI-training. Veel uitgevers kiezen voor selectieve blokkering, zodat AI-training wordt gestopt terwijl de linkvoorbeelden voor sociaal delen behouden blijven.
Volg hoe uw content verschijnt in Meta AI-antwoorden op Facebook, Instagram en WhatsApp. Krijg inzicht in AI-verwijzingen en begrijp de aanwezigheid van uw merk in door AI gegenereerde antwoorden.
Ontdek hoe Meta AI-optimalisatie Facebook- en Instagram-advertenties transformeert met AI-gedreven automatisering, realtime bieden en intelligente doelgroepbepa...
Meta AI is Meta's AI-assistent geïntegreerd in Facebook, Instagram, WhatsApp en Messenger. Ontdek hoe het werkt, zijn mogelijkheden en de rol in AI-monitoring e...

Leer hoe je noai- en noimageai-meta tags implementeert om AI-crawler-toegang tot je website-inhoud te beheren. Complete gids voor AI-toegangscontroleheaders en ...
Cookie Toestemming
We gebruiken cookies om uw browse-ervaring te verbeteren en ons verkeer te analyseren. See our privacy policy.