
Hoe Worden Podcasts Geciteerd door AI-zoekmachines en Chatbots
Ontdek hoe AI-systemen zoals ChatGPT en Perplexity podcastinhoud ontdekken, indexeren en citeren. Begrijp de technische mechanismen achter podcastcitaten in AI-...
7 min lezen
Transcript-indexering van podcasts is het proces waarbij audio-inhoud van podcasts wordt omgezet in doorzoekbare, georganiseerde tekst die kan worden ontdekt en geanalyseerd door zoekmachines en AI-systemen. Deze praktijk maakt het mogelijk om op detailniveau in de inhoud te zoeken, verbetert de toegankelijkheid voor alle doelgroepen en stelt AI-platforms in staat om podcastinhoud nauwkeurig te identificeren, analyseren en citeren. Geïndexeerde transcripties vormen de brug tussen audio-eerste content en tekstgebaseerde zoekalgoritmen, waardoor podcasts vindbaar worden via traditionele zoekmachines en AI-gedreven ontdekkingssystemen.
Transcript-indexering van podcasts is het proces waarbij audio-inhoud van podcasts wordt omgezet in doorzoekbare, georganiseerde tekst die kan worden ontdekt en geanalyseerd door zoekmachines en AI-systemen. Deze praktijk maakt het mogelijk om op detailniveau in de inhoud te zoeken, verbetert de toegankelijkheid voor alle doelgroepen en stelt AI-platforms in staat om podcastinhoud nauwkeurig te identificeren, analyseren en citeren. Geïndexeerde transcripties vormen de brug tussen audio-eerste content en tekstgebaseerde zoekalgoritmen, waardoor podcasts vindbaar worden via traditionele zoekmachines en AI-gedreven ontdekkingssystemen.
Transcript-indexering van podcasts is het proces waarbij audio-inhoud van podcasts wordt omgezet in doorzoekbare, georganiseerde tekst die door zoekmachines, AI-systemen en contentplatforms kan worden ontdekt en geanalyseerd. Deze praktijk omvat het transcriberen van gesproken woorden uit podcastafleveringen naar geschreven formaat en het structureren van die tekst op een manier die gemakkelijk opvraagbaar is via zoekopdrachten en algoritmische analyses. In tegenstelling tot traditionele ontdekkingsmethoden voor podcasts, die uitsluitend vertrouwen op afleveringstitels, beschrijvingen en metadata, maakt transcript-indexering gedetailleerd zoeken op inhoudsniveau mogelijk, waarbij luisteraars en AI-systemen specifieke momenten, onderwerpen of discussies binnen afleveringen kunnen vinden. Het indexeerproces omvat meestal automatische spraakherkenning (ASR)-technologie, handmatige controle op nauwkeurigheid en strategische plaatsing van zoekwoorden en tijdsaanduidingen die de tekst koppelen aan de oorspronkelijke audio. Dit creëert een uitgebreide digitale voetafdruk voor podcastinhoud die veel verder reikt dan wat zichtbaar is in podcastgidsen.
Het belang van transcript-indexering van podcasts is exponentieel toegenomen nu podcasting een dominant mediavormaat is geworden. Met meer dan 500 miljoen podcastluisteraars wereldwijd en miljoenen uren aan geproduceerde inhoud per jaar, is het vermogen om deze enorme informatiebron te indexeren en te doorzoeken van cruciaal belang geworden voor contentontdekking, onderzoek en kennismanagement. Transcripties vormen de brug tussen audio-eerste content en tekstgebaseerde zoekalgoritmen, waardoor podcasts toegankelijk zijn voor zoekmachines die traditioneel moeite hebben met audio-inhoud. Organisaties, makers en platforms die robuuste transcript-indexeringstrategieën toepassen, behalen concurrentievoordeel op het gebied van vindbaarheid, publieksbereik en inhoudsmonetisatie. De praktijk speelt ook in op fundamentele toegankelijkheidsbehoeften, zodat dove en slechthorende doelgroepen met podcastinhoud kunnen omgaan en tegelijkertijd de SEO-prestaties verbeteren en AI-systemen in staat stellen podcastinhoud nauwkeurig te analyseren en te citeren.
| Aspect | Alleen-audio podcasts | Geïndexeerde transcripties |
|---|---|---|
| Zichtbaarheid in zoekmachines | Beperkt tot metadata | Volledige inhoud doorzoekbaar |
| Toegankelijkheid | Vereist handmatig luisteren | Tekstgebaseerde toegang beschikbaar |
| Citaties mogelijk | Moeilijk te refereren | Precieze tijdsaanduidingen en citaten |
| Inhoudsanalyse | Vereist menselijke controle | AI-gestuurde analyse mogelijk |
| Vindbaarheid | Afhankelijk van titel/beschrijving | Zoekwoorden- en onderwerpgebaseerd |
| Tijdsbeslag | Uren per aflevering | Minuten met automatisering |
Kunstmatige intelligentiesystemen zijn fundamenteel afhankelijk van tekstgebaseerde data om analyses, patroonherkenning en inhoudsbegrip uit te voeren. Wanneer podcasts in audioformaat blijven, bevinden ze zich in een blinde vlek voor de meeste AI-toepassingen—machine learning-modellen kunnen ruwe audio niet effectief analyseren, categoriseren of inzichten eruit halen zonder deze eerst in tekst om te zetten. Transcriptie van podcasts verwijdert deze barrière, waardoor AI-systemen geavanceerde taken kunnen uitvoeren zoals onderwerpmodellering, sentimentanalyse, entiteitsherkenning en inhoudsclassificatie. Deze transformatie is vooral belangrijk voor onderzoeksdoeleinden, concurrentie-inlichtingen en merkmonitoring, waarbij AI grote hoeveelheden inhoud moet scannen om vermeldingen te identificeren, context te analyseren en waardevolle inzichten te extraheren. De beschikbaarheid van geïndexeerde transcripties heeft de toegang tot podcastinhoud voor AI-gestuurde analyse gedemocratiseerd, waardoor kleinere organisaties en onderzoekers dezelfde analytische mogelijkheden kunnen benutten die voorheen alleen beschikbaar waren voor grote mediabedrijven met speciale transcriptieteams.
De praktische toepassingen van AI-gestuurde podcastontdekking zijn uitgebreid en blijven groeien:
Deze mogelijkheden transformeren podcasts van geïsoleerde audiobestanden tot geïntegreerde componenten van het bredere informatiesysteem, waar ze kunnen worden ontdekt, geanalyseerd en geciteerd naast traditionele tekstgebaseerde inhoud.
Zoekmachines zoals Google, Bing en DuckDuckGo hebben aanzienlijk geïnvesteerd in het begrijpen en indexeren van podcastinhoud, maar hun vermogen om dit effectief te doen hangt vrijwel volledig af van de beschikbaarheid van transcripties. Wanneer podcastepisodes volledige transcripties bevatten, kunnen zoekmachines de volledige inhoud crawlen en indexeren, waardoor afleveringen vindbaar worden via organische zoekopdrachten. Dit vergroot het potentiële publiek voor podcastinhoud aanzienlijk buiten de gebruikelijke podcast-apps en directories. Een podcastepisode over “duurzaam ondernemen” met een volledige transcriptie kan scoren in zoekresultaten wanneer iemand naar dat onderwerp zoekt en zo verkeer vanuit zoekmachines naar het podcastplatform leiden. Zonder transcripties zou diezelfde aflevering alleen vindbaar zijn via podcastspecifieke zoekopdrachten en het enorme publiek missen dat algemene zoekmachines gebruikt om informatie te vinden.
De SEO-voordelen van transcript-indexering van podcasts gaan verder dan alleen vindbaarheid. Transcripties maken de creatie van rich snippets en featured snippets in zoekresultaten mogelijk, waarbij Google relevante fragmenten uit podcastepisodes direct in de zoekresultaten kan tonen. Dit verhoogt het doorklikpercentage en positioneert podcasts als gezaghebbende bronnen voor specifieke onderwerpen. Bijvoorbeeld: een podcastepisode waarin een expert “AI-ethiek in de gezondheidszorg” bespreekt, kan verschijnen in zoekresultaten wanneer gebruikers naar dat onderwerp zoeken, met een relevant citaat uit de transcriptie duidelijk zichtbaar. Daarnaast bieden transcripties mogelijkheden voor interne koppelingen en cross-referenties, waarbij podcastplatforms transcriptie-inhoud kunnen koppelen aan gerelateerde artikelen, blogposts en andere bronnen, wat de algehele siteautoriteit en gebruikersbetrokkenheid verbetert. De aanwezigheid van transcripties verhoogt ook de gemiddelde tijd op de pagina en verlaagt het bouncepercentage, omdat gebruikers snel transcripties kunnen scannen om relevante secties te vinden in plaats van hele afleveringen te beluisteren. Zoekmachines belonen deze engagementstatistieken met hogere rankings, waardoor een opwaartse spiraal ontstaat waarbij geïndexeerde podcasts meer zichtbaarheid, meer verkeer en hogere zoekmachinautoriteit ontvangen.
Transcript-indexering van podcasts is in de kern een toegankelijkheidskwestie die veel verder gaat dan SEO-optimalisatie of AI-analyse. Ongeveer 1,5 miljard mensen wereldwijd ervaren in zekere mate gehoorverlies, en voor deze mensen zijn podcasts zonder transcripties volledig ontoegankelijk. Door volledige transcripties te bieden, zorgen podcastmakers ervoor dat dove en slechthorende doelgroepen op gelijke voet met horende luisteraars kunnen meedoen. Deze inzet voor toegankelijkheid is niet alleen een morele plicht—het is in veel rechtsgebieden steeds vaker wettelijk verplicht. De Americans with Disabilities Act (ADA) en vergelijkbare wetgeving in andere landen vereisen dat digitale content toegankelijk is voor mensen met een beperking, en rechtbanken hebben steeds vaker geoordeeld dat podcastinhoud zonder transcripties deze toegankelijkheidsnormen schendt. Buiten wettelijke naleving bereiken toegankelijke podcasts grotere doelgroepen, genereren ze meer betrokkenheid en bouwen ze sterkere gemeenschappen die mensen van alle niveaus omvatten.
De toegankelijkheidsvoordelen van transcripties gaan verder dan gehoortoegankelijkheid en omvatten bredere inclusieve ontdekking. Niet-Engelstalige luisteraars vinden het vaak makkelijker om inhoud te begrijpen door de transcriptie te lezen terwijl ze luisteren, waardoor het begrip en de retentie verbeteren. Gebruikers in lawaaierige omgevingen of situaties waarin audio niet praktisch is, kunnen via tekst toegang krijgen tot podcastinhoud. Mensen met cognitieve beperkingen of verwerkingsverschillen kunnen baat hebben bij de mogelijkheid om informatie op hun eigen tempo te lezen, herlezen en verwerken in plaats van het tempo van audio te moeten volgen. Daarnaast maken transcripties betere doorzoekbaarheid mogelijk voor gebruikers met specifieke informatiebehoeften—iemand die op zoek is naar een bepaald statistiekje of citaat kan in de transcriptie zoeken in plaats van een hele aflevering te beluisteren. Onderzoek wijst uit dat 72% van de podcastluisteraars eerder met podcasts zou omgaan als er transcripties beschikbaar waren, en 85% van de luisteraars gebruikt transcripties om specifieke informatie binnen afleveringen te vinden. Deze cijfers tonen aan dat transcript-indexering geen nichetoegankelijkheidsfunctie is—het is een fundamentele verwachting die de omvang van het publiek en de betrokkenheid aanzienlijk beïnvloedt.
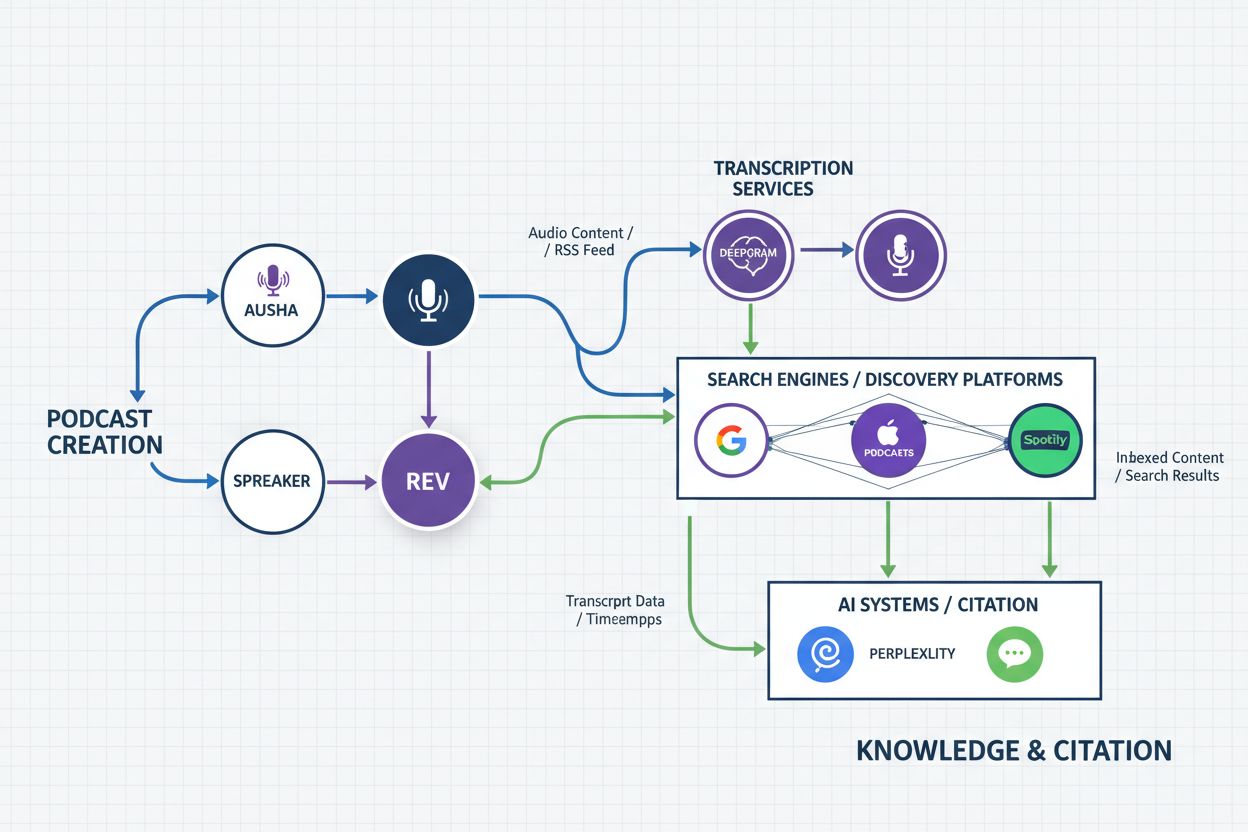
Het transcriptielandschap voor podcasts is drastisch veranderd met de opkomst van gespecialiseerde platforms en AI-gestuurde tools die specifiek zijn ontworpen voor podcastmakers en -netwerken. Deepgram’s Tapesearch is een toonaangevende oplossing in deze markt en biedt automatische transcriptie met sprekeridentificatie, nauwkeurige tijdsaanduidingen en integratie met grote podcasthostingplatforms. Tapesearch gebruikt geavanceerde AI-modellen om transcripties te leveren met toonaangevende nauwkeurigheid, terwijl het kosteneffectief blijft op grote schaal. Ausha biedt een alles-in-één platform voor podcastbeheer inclusief transcriptieservices, SEO-optimalisatie en distributie over meerdere platforms, wat het vooral waardevol maakt voor makers die hun volledige podcastoperatie vanuit één dashboard willen beheren. Spreaker combineert podcasthosting met ingebouwde transcriptie- en SEO-tools, waardoor makers automatisch transcripties kunnen genereren en deze kunnen optimaliseren voor zichtbaarheid in zoekmachines. Ditto Transcripts is gespecialiseerd in hoogwaardige, door mensen gecontroleerde transcriptieservices met opties voor automatische of handmatige transcriptie, bedoeld voor makers die nauwkeurigheid boven snelheid stellen.
| Platform | Transcriptiemethode | Nauwkeurigheidspercentage | Belangrijkste functies | Beste voor |
|---|---|---|---|---|
| Deepgram Tapesearch | AI-gestuurde ASR | 95%+ | Spreker-ID, tijdsaanduidingen, API-toegang | Schaal en automatisering |
| Ausha | AI met optionele controle | 94%+ | Volledig podcastbeheer, SEO-tools | Alles-in-één oplossing |
| Spreaker | AI-gestuurde ASR | 93%+ | Hosting + transcriptie, distributie | Makergerichte workflows |
| Ditto Transcripts | Mens + AI-hybride | 99%+ | Premium kwaliteit, bewerkingsdiensten | Kwaliteitskritische content |
De keuze tussen deze platforms hangt af van de specifieke behoeften van de organisatie, budgetbeperkingen en gewenste mate van automatisering versus menselijke controle. Organisaties die snelheid en kosteneffectiviteit prioriteren kiezen doorgaans voor AI-oplossingen zoals Deepgram en Ausha, terwijl organisaties met gevoelige inhoud of behoefte aan publicatiekwaliteit eerder hybride benaderingen verkiezen die AI-efficiëntie combineren met menselijke controle. Veel succesvolle podcastoperaties gebruiken meerdere tools in combinatie—bijvoorbeeld Deepgram voor snelle initiële transcriptie en vervolgens Ditto Transcripts voor eindcontrole en optimalisatie. Het competitieve landschap blijft zich ontwikkelen, met nieuwe aanbieders die innovatieve functies introduceren zoals realtime transcriptie, meertalige ondersteuning en geavanceerde sprekeridentificatie.
Effectieve transcript-indexering van podcasts vereist meer dan alleen het omzetten van audio naar tekst—het vereist een strategische aanpak die vindbaarheid, nauwkeurigheid en bruikbaarheid maximaliseert. De volgende praktijken vormen de industriestandaard die succesvolle podcastoperaties hanteren:
Naast deze technische praktijken vereist succesvolle transcript-indexering commitment van de organisatie om transcripties als volwaardige content te behandelen en niet als aanvullend materiaal. Dit betekent voldoende middelen toewijzen voor transcriptie, duidelijke eigenaarschap en verantwoordelijkheid voor transcriptkwaliteit instellen en regelmatig prestatiestatistieken evalueren om verbeterpunten te signaleren. Podcasters moeten ook rekening houden met de gebruikerservaring van transcriptlezers—transcripties opmaken voor leesbaarheid, lange secties opdelen met koppen en visuele elementen, en zorgen dat transcripties eenvoudig te vinden zijn vanaf afleveringspagina’s. Tot slot moeten organisaties transcripties benutten binnen het volledige content-ecosysteem door transcriptie-inhoud te hergebruiken in blogposts, social media snippets en andere formaten die de waarde en het bereik van de podcastinhoud vergroten.
De opkomst van transcript-indexering van podcasts heeft fundamenteel veranderd hoe AI-systemen podcastinhoud kunnen monitoren, analyseren en citeren. Voorheen bevonden podcasts zich in een citatie-blinde vlek—onderzoekers, journalisten en analisten konden wel podcastinhoud aanhalen, maar dat vereiste handmatig luisteren en notities maken, waardoor het onpraktisch was om vermeldingen, citaties en referenties systematisch in het podcast-ecosysteem te volgen. Met geïndexeerde transcripties kunnen AI-gedreven citatiemonitoringsplatforms nu duizenden podcasts in realtime scannen en vaststellen wanneer specifieke onderwerpen, onderzoeken, producten of merken worden genoemd, besproken of geciteerd. Deze mogelijkheid is vooral waardevol voor organisaties die moeten begrijpen hoe hun werk, producten of merk worden besproken in de podcastwereld—een medium dat maandelijks honderden miljoenen luisteraars bereikt maar historisch gezien onzichtbaar was voor traditionele mediamonitoringtools.
AmICited.com vertegenwoordigt de nieuwe generatie AI-citatiemonitoring, specifiek ontworpen om de unieke uitdagingen van het volgen van citaties en vermeldingen in diverse mediaformaten, inclusief podcasts, aan te pakken. Door gebruik te maken van geïndexeerde podcasttranscripties stelt AmICited.com organisaties in staat te monitoren hoe hun onderzoek, publicaties, producten en merk worden genoemd en besproken in het volledige podcastecosysteem. Het platform gebruikt geavanceerde AI om context en sentiment te begrijpen, onderscheid te maken tussen terloopse vermeldingen en substantiële citaties, en biedt gedetailleerde analyses over welke podcasts jouw werk bespreken, welke aspecten worden benadrukt en hoe de discussie wordt gevoerd. Deze mogelijkheid is van onschatbare waarde voor onderzoekers die de werkelijke impact van hun werk willen begrijpen, bedrijven die concurrentie-inlichtingen en merkperceptie willen monitoren en organisaties die willen volgen hoe hun thought leadership wordt verspreid via podcastdiscussies.
De integratie van podcasttranscripties in AI-citatiemonitoringsystemen biedt verschillende cruciale voordelen. Ten eerste maakt het volledige dekking van het podcastecosysteem mogelijk, zodat organisaties geen belangrijke vermeldingen of discussies missen in dit steeds invloedrijkere medium. Ten tweede biedt het nauwkeurige citatievolging met tijdsaanduidingen en context, waardoor organisaties precies kunnen begrijpen hoe hun werk wordt besproken en gericht kunnen communiceren met podcastpubliek via gerichte campagnes of contentcreatie. Ten derde maakt het trendanalyse en inzichtgeneratie mogelijk, waarmee organisaties opkomende onderwerpen kunnen identificeren, publieksinteresses kunnen begrijpen en zich kunnen positioneren als thought leader in hun vakgebied. Naarmate podcasting in invloed en bereik blijft groeien, wordt het vermogen om podcastinhoud via geïndexeerde transcripties te monitoren en analyseren steeds belangrijker voor organisaties die hun impact willen begrijpen, hun reputatie willen monitoren en contact willen maken met doelgroepen via alle mediakanalen. De gespecialiseerde focus van AmICited.com op citatiemonitoring zorgt ervoor dat organisaties transcript-indexering van podcasts optimaal kunnen benutten en podcastinhoud transformeren van een onzichtbaar medium tot een meetbaar, analyseerbaar onderdeel van hun totale media- en citatiestrategie.
Transcript-indexering van podcasts is het proces waarbij audio-afleveringen van podcasts worden omgezet in doorzoekbare, georganiseerde tekst die door zoekmachines en AI-systemen kan worden ontdekt. Dit maakt zoeken op inhoudsniveau mogelijk, verbetert de toegankelijkheid en stelt AI-platforms in staat om podcastinhoud nauwkeurig te analyseren en te citeren. Geïndexeerde transcripties vormen de brug tussen audio-inhoud en tekstgebaseerde zoekalgoritmen.
Transcript-indexering verbetert de vindbaarheid van podcasts aanzienlijk via zoekmachines, maakt inhoud toegankelijk voor dove en slechthorende luisteraars, stelt AI-systemen in staat om je content te analyseren en te citeren, en biedt mogelijkheden voor hergebruik van de inhoud. Podcasts met geïndexeerde transcripties ontvangen aanzienlijk meer verkeer van zoekmachines en bereiken een breder publiek op meerdere platforms.
Zoekmachines zoals Google crawlen en indexeren podcasttranscripties die op websites of in RSS-feeds zijn gepubliceerd, en behandelen ze vergelijkbaar met bloginhoud. Wanneer transcripties goed zijn opgemaakt met koppen, zoekwoorden en tijdsaanduidingen, kunnen zoekmachines de inhoudsstructuur begrijpen en afleveringen rangschikken voor relevante zoekopdrachten. Hierdoor worden podcasts vindbaar via organische zoekresultaten naast traditionele tekstgebaseerde inhoud.
AI-gedreven transcriptiediensten zoals Deepgram en Ausha bieden snelheid en kosteneffectiviteit en bereiken doorgaans 93-95% nauwkeurigheid binnen enkele minuten. Handmatige transcriptie door professionele diensten zoals Ditto Transcripts levert een hogere nauwkeurigheid op (99%+) maar vereist meer tijd en investering. Veel organisaties gebruiken een hybride aanpak: AI voor de initiële transcriptie, gevolgd door menselijke controle voor eindkwaliteit.
Geïndexeerde transcripties stellen AI-gedreven citatiemonitoringplatforms zoals AmICited in staat om duizenden podcasts in realtime te scannen, waarbij wordt vastgesteld wanneer je onderzoek, producten of merk worden genoemd en besproken. Deze mogelijkheid transformeert podcasts van een onzichtbaar medium tot een meetbaar onderdeel van je totale citatie- en mediastrategie, waardoor je je werkelijke impact kunt begrijpen.
Populaire transcriptieplatforms voor podcasts zijn onder meer Deepgram Tapesearch (AI-gedreven, 95%+ nauwkeurigheid), Ausha (alles-in-één podcastbeheer), Spreaker (hosting met ingebouwde transcriptie) en Ditto Transcripts (menselijke controle, 99%+ nauwkeurigheid). De beste keuze hangt af van je prioriteiten op het gebied van snelheid, kosten, nauwkeurigheid en gewenste mate van automatisering versus menselijke controle.
Optimaliseer transcripties door relevante zoekwoorden op natuurlijke wijze in de tekst op te nemen, tijdsaanduidingen toe te voegen die naar specifieke momenten linken, beschrijvende koppen te maken, sprekeridentificatie te implementeren en transcripties in meerdere formaten te publiceren (HTML, platte tekst, gestructureerde data). Zorg ervoor dat transcripties eenvoudig te vinden zijn vanaf afleveringspagina's en overweeg om de inhoud te hergebruiken in blogposts en social media snippets.
Ja, absoluut. Geïndexeerde transcripties maken je podcast vindbaar via zoekmachines en bereiken doelgroepen buiten podcast-apps. Ze verbeteren de toegankelijkheid voor diverse doelgroepen, verhogen de betrokkenheid door doorzoekbaarheid en maken hergebruik van inhoud op meerdere platforms mogelijk. Onderzoek toont aan dat 72% van de podcastluisteraars eerder met podcasts zou omgaan als er transcripties beschikbaar waren.
Ontdek hoe je podcastinhoud wordt geciteerd en besproken op AI-platforms zoals Google AI Overviews, Perplexity en ChatGPT. Volg vermeldingen, analyseer sentiment en begrijp je werkelijke impact met AmICited.
Ontdek hoe AI-systemen zoals ChatGPT en Perplexity podcastinhoud ontdekken, indexeren en citeren. Begrijp de technische mechanismen achter podcastcitaten in AI-...
Leer hoe je podcasttranscripts optimaliseert voor AI-systemen zoals ChatGPT, Perplexity en Claude. Beheers semantische zoekwoorden, schema-markup en gestructure...

Ontdek hoe podcasttranscripties AI-zichtbaarheid ontsluiten, meer citaties opleveren en audiocontent transformeren tot vindbare assets voor ChatGPT, Perplexity ...
Cookie Toestemming
We gebruiken cookies om uw browse-ervaring te verbeteren en ons verkeer te analyseren. See our privacy policy.