
Query Refinement
Query refinement is het iteratieve proces van het optimaliseren van zoekopdrachten voor betere resultaten in AI-zoekmachines. Leer hoe het werkt bij ChatGPT, Pe...
14 min lezen
Query-reformulering is het proces waarbij AI-systemen gebruikersvragen interpreteren, herstructureren en verrijken om de nauwkeurigheid en relevantie van informatieopvraging te verbeteren. Het transformeert eenvoudige of dubbelzinnige gebruikersinvoer in meer gedetailleerde, contextueel verrijkte versies die aansluiten bij het begrip van het AI-systeem, waardoor preciezere en completere antwoorden mogelijk worden.
Query-reformulering is het proces waarbij AI-systemen gebruikersvragen interpreteren, herstructureren en verrijken om de nauwkeurigheid en relevantie van informatieopvraging te verbeteren. Het transformeert eenvoudige of dubbelzinnige gebruikersinvoer in meer gedetailleerde, contextueel verrijkte versies die aansluiten bij het begrip van het AI-systeem, waardoor preciezere en completere antwoorden mogelijk worden.
Query-reformulering is het proces waarbij de oorspronkelijke zoekopdracht van een gebruiker wordt getransformeerd, uitgebreid of herschreven om deze beter af te stemmen op de mogelijkheden van het onderliggende informatieopvragsysteem en de daadwerkelijke intentie van de gebruiker. In de context van kunstmatige intelligentie en natuurlijke taalverwerking (NLP) overbrugt query-reformulering de cruciale kloof tussen hoe gebruikers hun informatiebehoefte van nature uitdrukken en hoe AI-systemen die verzoeken interpreteren en verwerken. Deze techniek is essentieel in moderne AI-systemen omdat gebruikers vaak vragen onnauwkeurig formuleren, domeinspecifieke terminologie inconsistent gebruiken of nalaten contextuele informatie te geven die de nauwkeurigheid van opvraging zou verbeteren. Query-reformulering opereert op het snijvlak van informatieopvraging, semantisch begrip en machine learning, waardoor systemen relevantere resultaten kunnen genereren door vragen vanuit meerdere invalshoeken opnieuw te interpreteren—of dit nu gebeurt via synoniemexpansie, contextuele verrijking of structurele reorganisatie. Door vragen intelligent te reformuleren kunnen AI-systemen de antwoordkwaliteit drastisch verbeteren, ambiguïteit verminderen en ervoor zorgen dat opgehaalde informatie beter aansluit bij de gebruikersintentie.
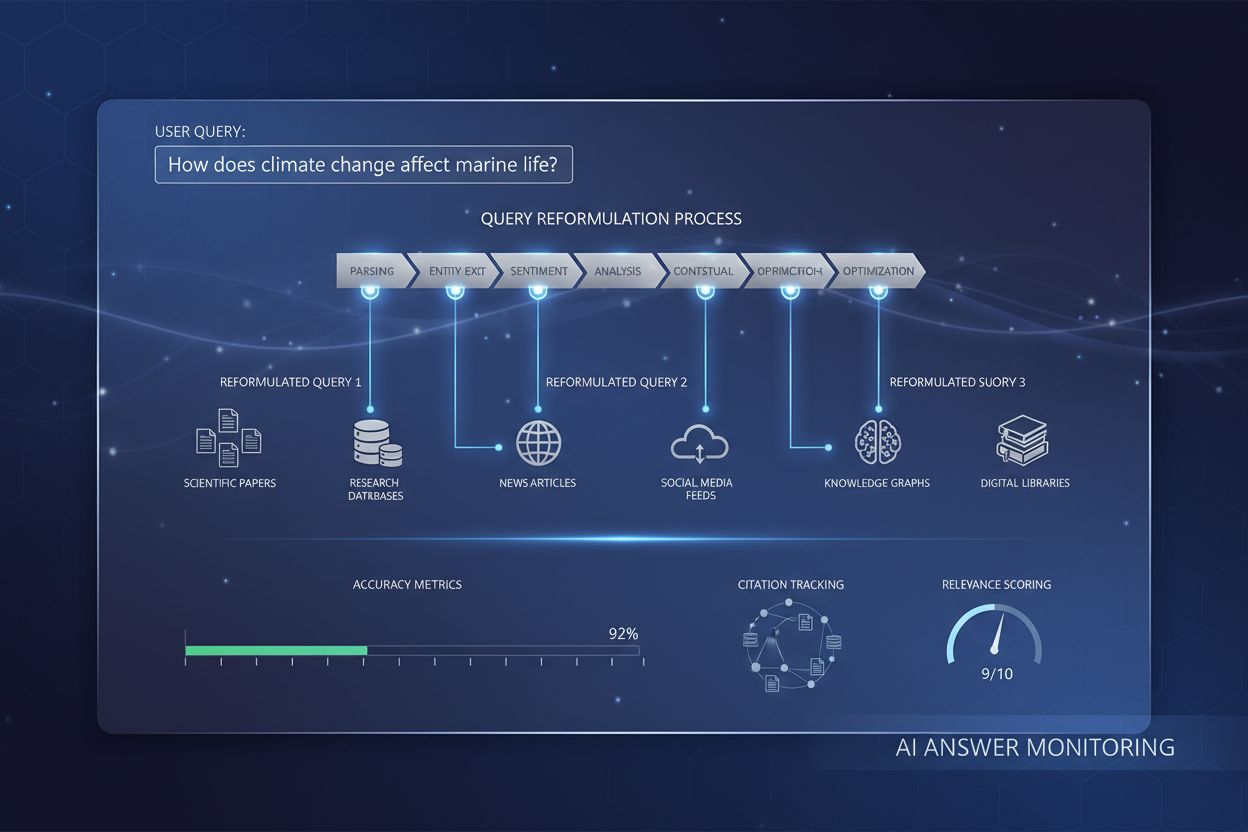
Query-reformuleringssystemen werken doorgaans via vijf onderling verbonden componenten die samenwerken om ruwe gebruikersinvoer om te zetten naar geoptimaliseerde zoekopdrachten. Invoerparsing breekt de oorspronkelijke vraag op in onderdelen, waarbij sleutelwoorden, zinnen en structurele elementen worden geïdentificeerd. Entiteitsextractie herkent benoemde entiteiten (personen, plaatsen, organisaties, producten) en domeinspecifieke concepten met semantisch gewicht. Sentimentanalyse bewaart de emotionele toon of waarderende houding van de oorspronkelijke vraag, zodat gereformuleerde versies het perspectief van de gebruiker behouden. Contextuele analyse verwerkt sessiegeschiedenis, gebruikersprofielinformatie en domeinkennis om de vraag te verrijken met impliciete betekenis. Vraaggeneratie zet stellende uitspraken of fragmenten om in goed gevormde vragen die opvragsystemen effectiever kunnen verwerken.
| Component | Doel | Voorbeeld |
|---|---|---|
| Invoerparsing | Tokeniseert en segmenteert de vraag in betekenisvolle eenheden | “beste Python-bibliotheken” → [“beste”, “Python”, “bibliotheken”] |
| Entiteitsextractie | Herkent benoemde entiteiten en domeinconcepten | “Apple’s nieuwste iPhone” → Entiteit: Apple (bedrijf), iPhone (product) |
| Sentimentanalyse | Behoudt waarderende toon en gebruikersperspectief | “vreselijke klantenservice” → Behoudt negatieve sentiment in reformulering |
| Contextuele analyse | Verwerkt sessiegeschiedenis en domeinkennis | Vorige vraag over “machine learning” informeert huidige vraag “neurale netwerken” |
| Vraaggeneratie | Zet fragmenten om naar gestructureerde vragen | “Python debuggen” → “Hoe debug ik Python-code?” |
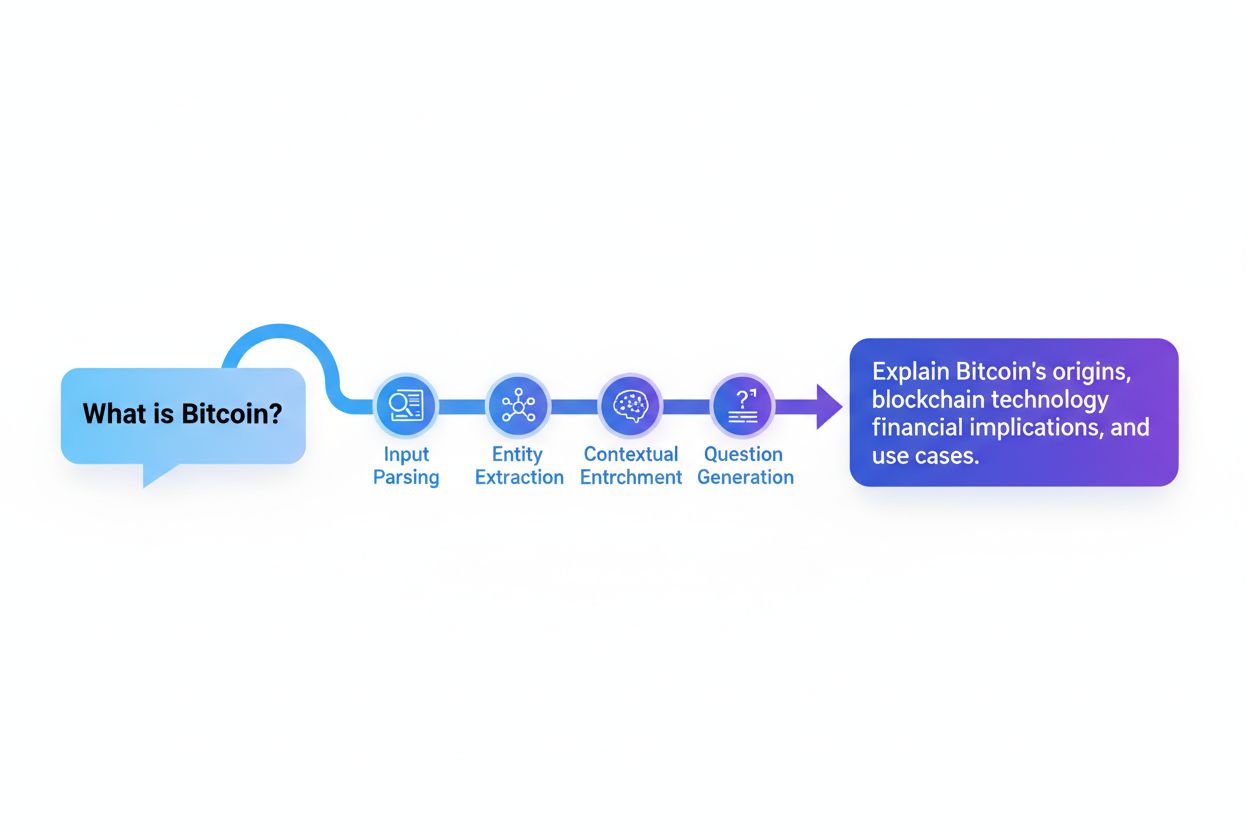
Het query-reformuleringsproces volgt een systematische zes-stappenmethodiek die is ontworpen om de kwaliteit en relevantie van vragen stapsgewijs te verbeteren:
Invoerparsing en normalisatie
Entiteit- en conceptextractie
Sentiment- en intentiebehoud
Contextuele verrijking
Vraagexpansie en synonymengeneratie
Optimalisatie en evaluatie
Query-reformulering gebruikt uiteenlopende technieken, van traditionele lexicale benaderingen tot geavanceerde neurale methoden. Synoniem-gebaseerde expansie maakt gebruik van gevestigde bronnen als WordNet, woordembeddings zoals Word2Vec en GloVe, en contextuele modellen als BERT om semantisch vergelijkbare termen te vinden. Query-relaxatie versoepelt geleidelijk de beperkingen van de vraag om de recall te verhogen wanneer initiële resultaten onvoldoende zijn—bijvoorbeeld door zeldzame termen te verwijderen of datumbereiken te verbreden. Integratie van gebruikersfeedback en sessiecontext stelt systemen in staat te leren van gebruikersinteracties, en reformuleringen te verfijnen op basis van daadwerkelijk relevante resultaten. Transformer-gebaseerde herschrijvers zoals T5 (Text-to-Text Transfer Transformer) en GPT-modellen genereren volledig nieuwe vraagstellingen door patronen te leren uit grote trainingsdatasets van vraagparen. Hybride benaderingen combineren meerdere technieken—bijvoorbeeld door regel-gebaseerde synoniemexpansie toe te passen op termen met hoge zekerheid en neurale modellen op dubbelzinnige zinsdelen. Praktische implementaties gebruiken vaak ensemble-methoden die meerdere reformuleringen genereren en deze rangschikken met geleerde relevantiemodellen. Zo combineren e-commerceplatforms domeinspecifieke synoniemdictionaries met BERT-embeddings om zowel gestandaardiseerde productterminologie als informele gebruikersspraak te verwerken, terwijl medische zoeksystemen gespecialiseerde ontologieën naast transformermodellen inzetten om klinische nauwkeurigheid te waarborgen.
Query-reformulering levert aanzienlijke verbeteringen op voor zowel AI-systeemprestaties als gebruikerservaring:
Verbeterde opvraag-nauwkeurigheid: Gereformuleerde vragen vangen gebruikersintentie preciezer, wat resulteert in beter opgehaalde documenten en relevantere AI-antwoorden. Door vragen uit te breiden met synoniemen en gerelateerde concepten, halen systemen documenten op die mogelijk andere terminologie gebruiken dan het origineel, wat de kans op écht relevante informatie sterk vergroot.
Verhoogde recall en dekking: Vraagexpansie vergroot het aantal relevante opgehaalde documenten door semantische variaties en gerelateerde concepten te onderzoeken. Dit is vooral waardevol in gespecialiseerde domeinen waar terminologie sterk varieert, waardoor gebruikers geen relevante informatie missen door vocabulaireverschillen.
Minder ambiguïteit en meer verduidelijking: Reformuleringsprocessen nemen vaagheid of ambiguïteit weg door context toe te voegen en meerdere interpretaties te genereren. Hierdoor kunnen systemen vragen als “apple” (fruit vs. bedrijf) verwerken door contextspecifieke reformuleringen te genereren die passende resultaten opleveren.
Betere gebruikerservaring en tevredenheid: Gebruikers krijgen sneller relevantere resultaten, waardoor de noodzaak van herhaalde zoekpogingen afneemt. Minder mislukte zoekopdrachten en nauwkeurigere resultaten leiden direct tot meer tevredenheid en minder cognitieve belasting.
Schaalbaarheid en efficiëntie: Reformulering stelt systemen in staat uiteenlopende gebruikerspopulaties te bedienen met verschillende vocabulaire, kennisniveaus en taalkundige achtergronden. Eén reformuleringsengine kan gebruikers in verschillende domeinen en talen ondersteunen, wat de schaalbaarheid van het systeem verbetert zonder evenredige infrastructuuruitbreiding.
Continue verbetering en leren: Query-reformuleringssystemen kunnen getraind worden op gebruikersinteractiedata, waardoor hun strategieën continu verbeteren op basis van welke reformuleringen tot succesvolle resultaten leiden. Dit creëert een positieve feedbackloop waarin prestaties over tijd toenemen naarmate er meer gebruikersdata beschikbaar komt.
Domeinaanpassing en specialisatie: Reformuleringstechnieken kunnen worden afgestemd op specifieke domeinen (medisch, juridisch, technisch) door te trainen op domeinspecifieke vraagparen en domeinontologieën te integreren. Hierdoor kunnen gespecialiseerde systemen domeinterminologie nauwkeuriger verwerken dan generieke benaderingen.
Robuustheid tegen vraagvariatie: Systemen worden veerkrachtig tegen typefouten, grammaticale fouten en omgangstaal door vragen te herformuleren naar gestandaardiseerde vormen. Deze robuustheid is vooral waardevol voor spraakgestuurde interfaces en mobiel zoeken waar de invoerkwaliteit sterk varieert.
Query-reformulering speelt een cruciale rol in de nauwkeurigheid en betrouwbaarheid van AI-gegenereerde antwoorden, waardoor het essentieel is voor AI-antwoordenmonitoringplatforms zoals AmICited.com. Wanneer AI-systemen vragen reformuleren vóór de antwoordgeneratie, is de kwaliteit van die reformuleringen direct bepalend voor het ophalen van de juiste bronmaterialen en het genereren van correcte, goed onderbouwde antwoorden. Slecht gereformuleerde vragen kunnen ertoe leiden dat AI-systemen irrelevante documenten ophalen, waardoor antwoorden niet goed gefundeerd zijn of onjuiste bronnen vermelden. In de context van AI-monitoring en citatiemonitoring is het begrijpen van de wijze waarop vragen worden gereformuleerd cruciaal om te verifiëren dat AI-systemen daadwerkelijk de bedoelde vraag van de gebruiker beantwoorden in plaats van een vervormde interpretatie ervan. AmICited.com volgt hoe AI-systemen vragen reformuleren om te waarborgen dat de geciteerde bronnen in AI-antwoorden daadwerkelijk relevant zijn voor de oorspronkelijke gebruikersvraag, niet alleen voor een verkeerd geïnterpreteerde reformulering. Deze monitoringsmogelijkheid is bijzonder belangrijk omdat query-reformulering voor eindgebruikers onzichtbaar gebeurt—zij zien alleen het uiteindelijke antwoord en de verwijzingen, zonder te weten hoe de onderliggende vraag is getransformeerd. Door patronen in query-reformulering te analyseren, kunnen AI-monitoringplatforms identificeren wanneer AI-systemen antwoorden genereren op basis van gereformuleerde vragen die sterk afwijken van de gebruikersintentie, en potentiële nauwkeurigheidsproblemen signaleren voordat ze gebruikers bereiken. Bovendien helpt inzicht in reformulering platforms te beoordelen of AI-systemen dubbelzinnige vragen adequaat verwerken door meerdere reformuleringen te genereren en informatie daarover te synthetiseren, of dat ze ongegronde aannames doen over de intentie van de gebruiker.
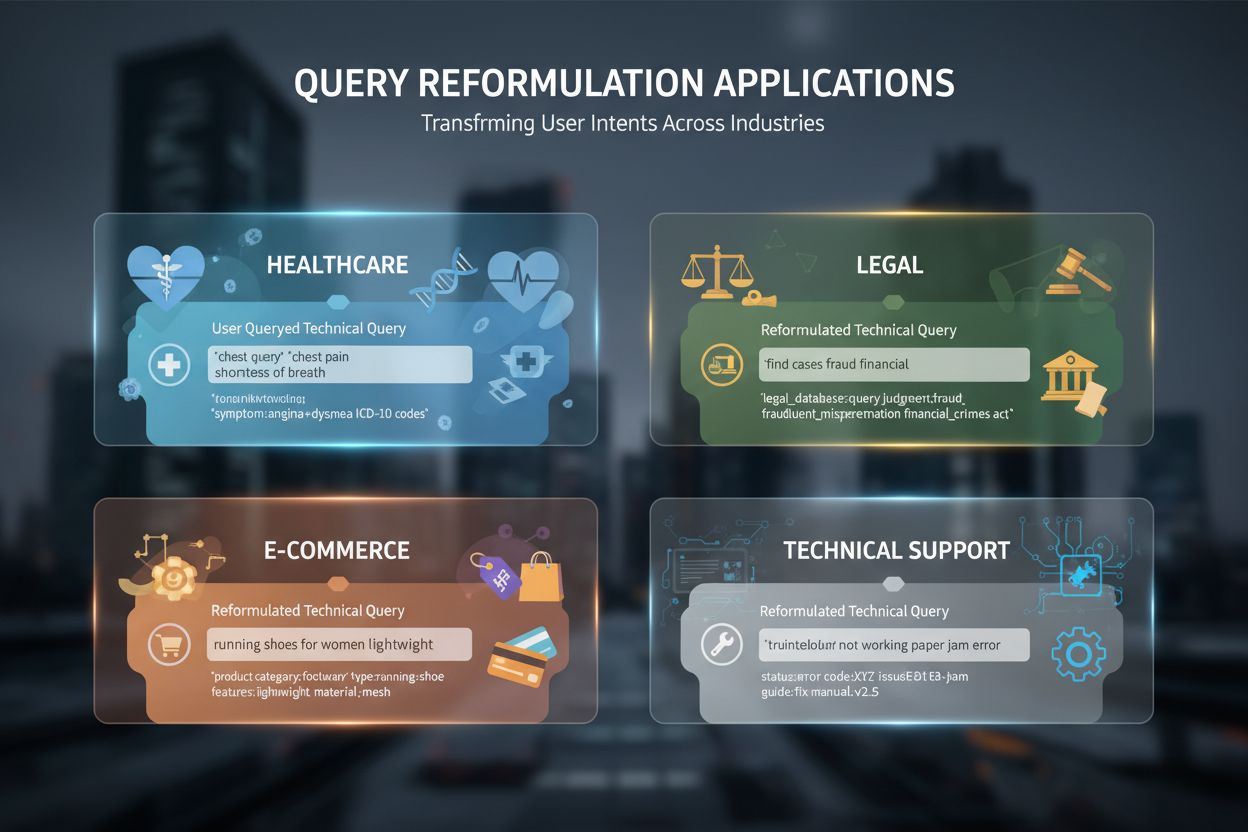
Query-reformulering is onmisbaar geworden in talloze AI-gedreven toepassingen en sectoren. In de gezondheidszorg en medisch onderzoek verwerkt query-reformulering de complexiteit van medische terminologie, waarbij patiënten zoeken op “hartaanval” terwijl de klinische literatuur “myocardinfarct” gebruikt—reformulering overbrugt deze vocabulairekloof en haalt klinisch accurate informatie op. Juridische documentanalyse-systemen gebruiken query-reformulering om de precieze, archaïsche taal van juridische documenten te verwerken en tegelijkertijd moderne zoektermen te ondersteunen, zodat advocaten relevante precedenten kunnen vinden ongeacht hun formulering. Technische supportsystemen reformuleren gebruikersvragen om deze te laten aansluiten bij kennisbankartikelen, waarbij informele probleemomschrijvingen (“mijn computer is traag”) worden omgezet naar technische termen (“systeemprestatieproblemen”) om geschikte handleidingen te vinden. E-commerce zoekoptimalisatie past query-reformulering toe bij productzoekopdrachten, waarbij gebruikers zoeken op “hardloopschoenen” terwijl de catalogus “sportief schoeisel” of specifieke merknamen hanteert, zodat klanten gewenste producten vinden ondanks terminologieverschillen. Conversational AI en chatbots gebruiken query-reformulering om context te behouden in meerstapsgesprekken, waarbij vervolgvragen worden gereformuleerd met impliciete context uit eerdere interacties. Retrieval-Augmented Generation (RAG)-systemen zijn sterk afhankelijk van query-reformulering om ervoor te zorgen dat opgehaalde contextdocumenten werkelijk relevant zijn voor de gebruikersvraag, wat direct de kwaliteit van gegenereerde antwoorden beïnvloedt. Een RAG-systeem dat antwoord geeft op “Hoe optimaliseer ik databasequeries?” kan deze vraag bijvoorbeeld reformuleren tot meerdere varianten als “database query performance tuning”, “SQL-optimalisatietechnieken” en “query-executieplannen” om zo brede context op te halen voordat een gedetailleerd antwoord wordt gegenereerd.
Ondanks de voordelen kent query-reformulering verschillende belangrijke uitdagingen waar professionals zorgvuldig mee om moeten gaan. Computationele complexiteit neemt aanzienlijk toe wanneer meerdere reformuleringen gegenereerd en gerangschikt moeten worden op relevantie—elke variant vereist verwerking, en systemen moeten de kwaliteitswinst afwegen tegen de vereiste responstijd, zeker bij real-time toepassingen. Kwaliteit van trainingsdata is rechtstreeks bepalend voor de effectiviteit: systemen getraind op slechte vraagparen of bevooroordeelde datasets zullen die vooroordelen in hun reformuleringen behouden of zelfs versterken. Risico op over-reformulering ontstaat wanneer zoveel varianten worden gegenereerd dat ze de oorspronkelijke intentie uit het oog verliezen en steeds meer afgeleide resultaten opleveren die eerder verwarren dan verhelderen. Domeinspecifieke aanpassing vergt veel inspanning—reformuleringsmodellen die getraind zijn op algemene webvragen presteren vaak slecht op specialistische domeinen als geneeskunde of recht zonder aanzienlijke hertraining en domeinspecifieke afstemming. Balans tussen precisie en recall vormt een fundamenteel spanningsveld: agressieve vraagexpansie verhoogt recall maar kan de precisie verlagen door irrelevante resultaten op te halen, terwijl conservatieve reformulering precisie behoudt maar relevante documenten mist. Potentiële bias-introductie doet zich voor wanneer systemen maatschappelijke vooroordelen uit de trainingsdata overnemen, wat kan leiden tot discriminatie in zoekresultaten of AI-antwoorden—zo kunnen gereformuleerde “verpleegkundige”-vragen onevenredig vaak vrouw-gerelateerde resultaten opleveren als de data historische genderbias bevatten.
Query-reformulering blijft zich snel ontwikkelen naarmate AI-capaciteiten groeien en nieuwe technieken ontstaan. Vooruitgang in LLM-gebaseerde reformulering maakt steeds geavanceerdere, contextbewuste vraagtransformaties mogelijk, nu grote taalmodellen gebruikersintentie subtieler begrijpen en natuurlijkere, semantisch rijke reformuleringen genereren. Multimodale AI-integratie zal query-reformulering uitbreiden naar beelden, audio en video, waarbij visuele zoekopdrachten worden omgezet naar tekstuele beschrijvingen die opvragsystemen kunnen verwerken. Personalisatie en leren stellen systemen in staat zich aan te passen aan individuele voorkeuren, vocabulaire en zoekpatronen, en steeds persoonlijkere reformuleringen te genereren. Realtime adaptieve reformulering maakt het mogelijk om vragen dynamisch aan te passen op basis van tussentijdse opvraagresultaten, met feedbackloops waarin initiële reformuleringen vervolgverbeteringen sturen. Kennisgraf-integratie stelt reformuleringssystemen in staat om gestructureerde kennis van entiteiten en relaties te benutten, voor semantisch preciezere reformuleringen die gebaseerd zijn op expliciete kennisrepresentaties. Opkomende standaarden voor evaluatie en benchmarking van query-reformulering zullen vergelijking tussen systemen vergemakkelijken en de kwaliteit en consistentie van reformulering in de sector verbeteren.
Query-reformulering is het bredere proces van het transformeren van een zoekopdracht om de opvraging te verbeteren, terwijl query-expansie een specifieke techniek binnen reformulering is die synoniemen en gerelateerde termen toevoegt. Query-expansie richt zich op het verbreden van het zoekbereik, terwijl reformulering meerdere technieken omvat, waaronder parsing, entiteitsextractie, sentimentanalyse en contextuele verrijking om de zoekkwaliteit fundamenteel te verbeteren.
Query-reformulering helpt AI-systemen gebruikersintentie beter te begrijpen door dubbelzinnige termen te verduidelijken, context toe te voegen en meerdere interpretaties van de oorspronkelijke vraag te genereren. Dit leidt tot het ophalen van meer relevante brondocumenten, waardoor de AI meer nauwkeurige, goed onderbouwde antwoorden met correcte verwijzingen kan genereren.
Ja, query-reformulering kan dienen als een beveiligingslaag door gebruikersinvoer te standaardiseren en te saniteren voordat deze het hoofd-AI-systeem bereikt. Een gespecialiseerde reformulering-agent kan mogelijk schadelijke invoer detecteren en neutraliseren, verdachte patronen filteren en vragen transformeren naar veilige, gestandaardiseerde formaten die de kwetsbaarheid voor prompt-injectie-aanvallen verminderen.
In Retrieval-Augmented Generation (RAG)-systemen is query-reformulering cruciaal om ervoor te zorgen dat opgehaalde contextdocumenten daadwerkelijk relevant zijn voor de gebruikersvraag. Door vragen in meerdere varianten te reformuleren, kunnen RAG-systemen meer uitgebreide en diverse context ophalen, wat de kwaliteit en nauwkeurigheid van de gegenereerde antwoorden direct verbetert.
Implementatie omvat meestal het selecteren van geschikte technieken voor jouw use case: gebruik synoniem-gebaseerde expansie met BERT of Word2Vec voor semantische overeenkomsten, pas transformermodellen zoals T5 of GPT toe voor neurale reformulering, integreer domeinspecifieke ontologieën voor gespecialiseerde vakgebieden en implementeer feedbackloops om reformuleringen continu te verbeteren op basis van gebruikersinteracties en succesmetingen bij opvraging.
De computationele kosten variëren per techniek: eenvoudige synoniemexpansie is lichtgewicht, terwijl transformer-gebaseerde reformulering aanzienlijke GPU-resources vereist. Het gebruik van kleinere gespecialiseerde modellen voor reformulering en grotere modellen enkel voor de uiteindelijke antwoordgeneratie kan echter de kosten optimaliseren. Veel systemen maken gebruik van caching en batchverwerking om de rekenkosten over meerdere vragen te spreiden.
Query-reformulering heeft direct invloed op de nauwkeurigheid van verwijzingen omdat de gereformuleerde vraag bepaalt welke documenten worden opgehaald en geciteerd. Als de reformulering sterk afwijkt van de oorspronkelijke gebruikersintentie, kan de AI bronnen citeren die relevant zijn voor de reformulering in plaats van voor de originele vraag. AI-monitoringplatforms zoals AmICited volgen deze transformaties om te waarborgen dat verwijzingen daadwerkelijk relevant zijn voor wat gebruikers werkelijk vroegen.
Ja, query-reformulering kan bestaande vooroordelen versterken als trainingsdata maatschappelijke vooringenomenheid weerspiegelen. Bijvoorbeeld, het reformuleren van bepaalde vragen kan onevenredig vaak resultaten opleveren die met bepaalde demografieën geassocieerd zijn. Dit tegengaan vereist zorgvuldige selectie van datasets, mechanismen voor bias-detectie, diverse trainingsvoorbeelden en voortdurende monitoring van reformulatie-uitvoer op eerlijkheid en representativiteit.
Query-reformulering beïnvloedt hoe AI-systemen jouw content begrijpen en citeren. AmICited volgt deze transformaties om te waarborgen dat jouw merk correcte naamsvermelding krijgt in AI-gegenereerde antwoorden.
Query refinement is het iteratieve proces van het optimaliseren van zoekopdrachten voor betere resultaten in AI-zoekmachines. Leer hoe het werkt bij ChatGPT, Pe...
Ontdek hoe query expansion optimalisatie AI-zoekresultaten verbetert door vocabulaireverschillen te overbruggen. Leer technieken, uitdagingen en waarom dit bela...
Ontdek hoe Query Fanout werkt in AI-zoeksystemen. Leer hoe AI enkele vragen uitbreidt naar meerdere subvragen om de nauwkeurigheid van antwoorden en het begrip ...
Cookie Toestemming
We gebruiken cookies om uw browse-ervaring te verbeteren en ons verkeer te analyseren. See our privacy policy.