
Semantische Query Matching
Ontdek hoe semantische query matching AI-systemen in staat stelt gebruikersintentie te begrijpen en relevante resultaten te leveren voorbij zoekwoordmatching. V...
5 min lezen
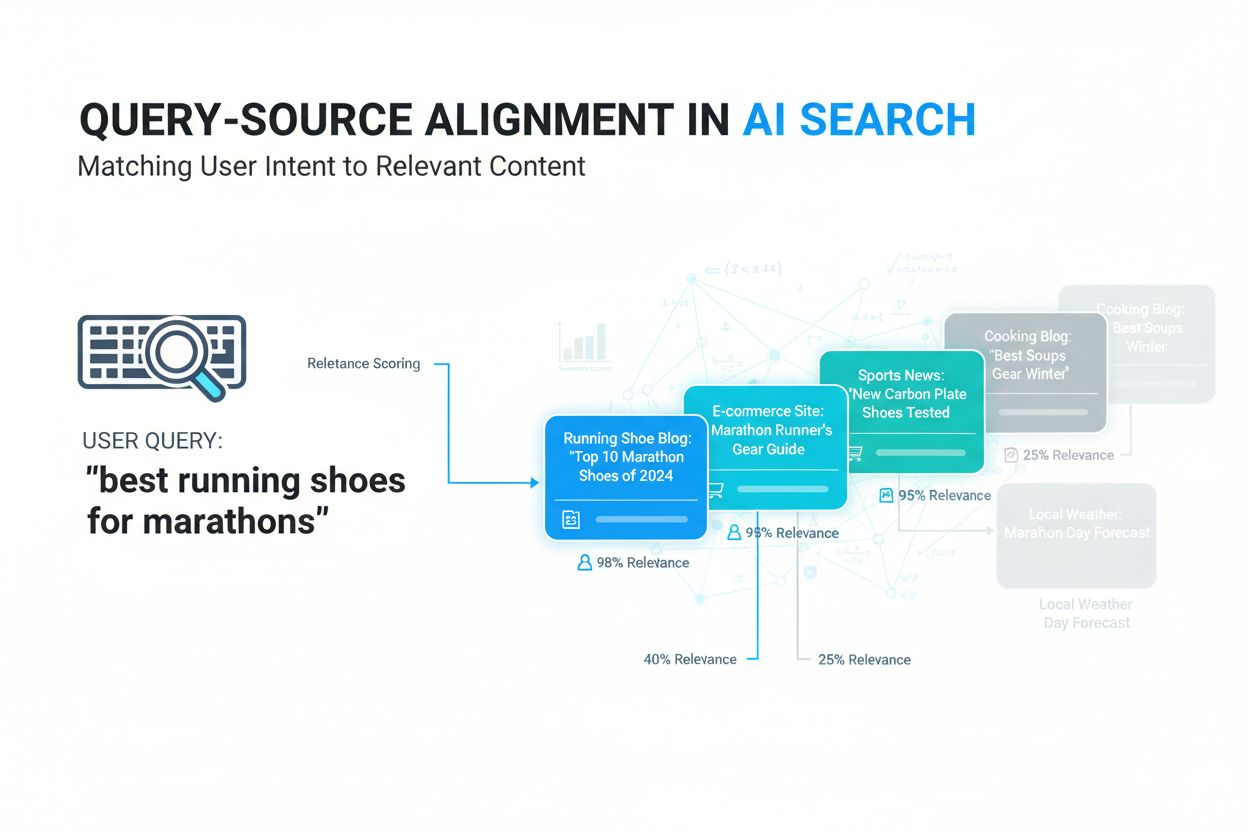
Query-source alignment is het proces waarbij gebruikerszoekopdrachten worden gekoppeld aan de meest relevante informatiebronnen op basis van semantische betekenis en contextuele relevantie. Het gebruikt AI en machine learning om de intentie achter zoekopdrachten te begrijpen en deze te verbinden met bronnen die daadwerkelijk voldoen aan de informatiebehoefte van de gebruiker, in plaats van te vertrouwen op eenvoudige zoekwoordovereenkomsten. Deze technologie is fundamenteel voor moderne AI-zoeksystemen zoals Google AI Overviews, ChatGPT en Perplexity. Effectieve alignment zorgt ervoor dat AI-systemen nauwkeurige, relevante resultaten leveren die de tevredenheid van de gebruiker en de zichtbaarheid van content verbeteren.
Query-source alignment is het proces waarbij gebruikerszoekopdrachten worden gekoppeld aan de meest relevante informatiebronnen op basis van semantische betekenis en contextuele relevantie. Het gebruikt AI en machine learning om de intentie achter zoekopdrachten te begrijpen en deze te verbinden met bronnen die daadwerkelijk voldoen aan de informatiebehoefte van de gebruiker, in plaats van te vertrouwen op eenvoudige zoekwoordovereenkomsten. Deze technologie is fundamenteel voor moderne AI-zoeksystemen zoals Google AI Overviews, ChatGPT en Perplexity. Effectieve alignment zorgt ervoor dat AI-systemen nauwkeurige, relevante resultaten leveren die de tevredenheid van de gebruiker en de zichtbaarheid van content verbeteren.
Query-source alignment verwijst naar het proces waarbij gebruikerszoekopdrachten worden gekoppeld aan de meest relevante informatiebronnen op basis van semantische betekenis en contextuele relevantie, in plaats van simpele overlap van zoekwoorden. In de kern pakt dit concept een fundamentele uitdaging in informatieopvraging aan: ervoor zorgen dat wanneer gebruikers naar informatie zoeken, de resultaten die ze ontvangen niet alleen technisch gerelateerd zijn aan hun zoektermen, maar daadwerkelijk inspelen op hun onderliggende informatiebehoefte.
Traditioneel vertrouwden zoeksystemen op zoekwoordmatching—het vinden van documenten die exact de ingevoerde woorden of zinnen bevatten. Hoewel deze aanpak eenvoudig is, leidde dit vaak tot irrelevante resultaten omdat het context, intentie en de diepere betekenis achter zoekopdrachten negeerde. Query-source alignment lost dit probleem op door semantische matchingtechnieken toe te passen die de conceptuele relatie begrijpen tussen waar gebruikers om vragen en wat informatiebronnen bevatten. Dit betekent dat een zoekopdracht naar “voertuigonderhoud” effectief artikelen over “auto-onderhoud” of “onderhoud van auto’s” kan opleveren, zelfs zonder exacte zoekwoordovereenkomsten.
In de context van moderne AI-zoeksystemen is query-source alignment steeds belangrijker geworden, aangezien kunstmatige intelligentie een steeds geavanceerder begrip van taalnuances en gebruikersintentie mogelijk maakt. In plaats van zoekopdrachten te behandelen als louter verzamelingen woorden, analyseren door AI aangestuurde alignment-systemen de semantische inhoud van zowel de gebruikersvraag als de beschikbare bronnen en creëren ze betekenisvolle verbindingen op basis van relevantie in plaats van oppervlakkige gelijkenis.
Dit onderscheid is van groot belang omdat het direct van invloed is op de kwaliteit van de zoekresultaten en de tevredenheid van gebruikers. Effectieve query-source alignment zorgt ervoor dat informatiesystemen resultaten teruggeven die echt antwoord geven op gebruikersvragen, irrelevante ruis in zoekresultaten verminderen en gebruikers helpen informatie te ontdekken die ze mogelijk niet zouden vinden via traditionele zoekwoordgebaseerde methoden. Naarmate AI-zoektechnologie zich verder ontwikkelt, blijft query-source alignment een hoeksteen voor systemen die gebruikersbehoeften echt begrijpen en beantwoorden.
Het technische proces van query-source alignment omvat verschillende geavanceerde stappen die gebruikerszoekopdrachten omzetten in betekenisvolle verbindingen met relevante bronnen:
Queryverwerking en Tokenisatie – Wanneer een gebruiker een zoekopdracht indient, splitst het systeem deze eerst op in individuele tokens (woorden en zinnen) en analyseert het de grammaticale structuur. Natural language processing-algoritmen identificeren de kernconcepten, entiteiten en intentie achter de zoekopdracht, verwijderen stopwoorden en bepalen de meest betekenisvolle componenten die het alignmentproces sturen.
Genereren van Query-Embeddings – De verwerkte zoekopdracht wordt omgezet in een semantische vector—een wiskundige representatie die de betekenis en context van de zoekopdracht vastlegt in een multidimensionale ruimte. Deze embedding wordt gecreëerd met neurale taalmodellen die zijn getraind op enorme tekstdatasets, waardoor het systeem de semantische essentie van de zoekopdracht kan representeren in plaats van alleen de letterlijke woorden.
Vectorisatie van Bronbestanden – Tegelijkertijd worden alle beschikbare bronbestanden in het systeem omgezet in semantische vectoren met hetzelfde embeddingmodel. Zo worden zowel zoekopdrachten als bronnen in dezelfde semantische ruimte gepositioneerd, waardoor directe vergelijking mogelijk wordt. Elke documentvector bevat de algemene betekenis, onderwerpen en relevantiesignalen van het document.
Berekening van Vectorgelijkenis – Het systeem berekent de gelijkenis tussen de queryvector en elke bronvector met behulp van wiskundige afstandsmetingen, meestal cosinusgelijkenis. Deze berekening bepaalt hoe nauw de semantische betekenis van een bron aansluit op die van de zoekopdracht en levert een gelijkenisscore op tussen 0 en 1.
Relevantiebeoordeling en Ranking – Naast semantische gelijkenis past het systeem aanvullende rankingfactoren toe, zoals domeinautoriteit, actualiteit van de inhoud, gebruikersbetrokkenheid en thematische relevantie. Deze factoren worden gecombineerd met semantische gelijkenisscores tot een allesomvattende relevantiescore, die de positie in de gerangschikte resultaten bepaalt.
Validatie van Contentmatching – Het systeem controleert of de geselecteerde bronnen daadwerkelijk relevante informatie bevatten door specifieke secties van de inhoud te analyseren. Dit voorkomt dat bronnen alleen hoog scoren omdat ze relevante zoekwoorden noemen, en zorgt ervoor dat ze daadwerkelijk inspelen op de informatiebehoefte van de gebruiker met inhoud van hoge kwaliteit.
Eindselectie en Ranking van Bronnen – De hoogst gerangschikte bronnen worden geselecteerd voor presentatie aan de gebruiker of voor citatie in door AI gegenereerde antwoorden. De eindranking weerspiegelt een gecombineerde beoordeling van semantische alignment, autoriteit, relevantie en contentkwaliteit, zodat gebruikers de meest passende bronnen voor hun specifieke zoekopdracht ontvangen.
| Methode/Benadering | Werking | Voordelen | Nadelen | Beste Toepassing |
|---|---|---|---|---|
| Zoekwoordmatching (Traditioneel) | Zoekt naar exacte woorden of zinnen in documenten; rangschikt op frequentie en positie | Eenvoudig te implementeren; snelle verwerking; transparante matchlogica | Negeert context en intentie; levert irrelevante resultaten; werkt niet met synoniemen | Simpele, feitelijke zoekopdrachten; legacy-systemen |
| Semantische Gelijkenis (Vector-gebaseerd) | Zet zoekopdrachten en documenten om in semantische vectoren; berekent gelijkenis met wiskundige afstandsmetingen | Begrijpt betekenis voorbij zoekwoorden; verwerkt synoniemen en context; zeer accuraat | Kost veel rekenkracht; vereist grote trainingsdatasets; minder transparant | Complexe zoekopdrachten; intentiegedreven zoeken; moderne AI-systemen |
| Entiteitsherkenning | Identificeert en classificeert belangrijke entiteiten (personen, plaatsen, organisaties, producten) in zoekopdrachten en content | Betere interpretatie van specifieke onderwerpen; voorkomt verwarring; maakt integratie met kennisgraaf mogelijk | Vereist uitgebreide entiteitendatabases; problemen met nieuwe/niche-entiteiten | Zoekopdrachten over specifieke entiteiten; kennisgebaseerd zoeken |
| Contextueel Begrip | Analyseert omringende context, gebruikersgeschiedenis en zoekpatronen om betekenis af te leiden | Begrijpt genuanceerde intentie; personaliseert resultaten; nauwkeuriger bij vage zoekopdrachten | Privacyzorgen rond gebruikersdata; vereist historische data; complexe implementatie | Conversatiezoekopdrachten; gepersonaliseerde aanbevelingen |
| Hybride Benadering | Combineert meerdere methoden (semantische gelijkenis, entiteitsherkenning, contextueel begrip) voor uitgebreide matching | Benut de kracht van verschillende technieken; robuuster en nauwkeuriger; werkt met diverse zoekopdrachten | Complex om te implementeren en te onderhouden; hogere rekenkosten; lastiger te debuggen | Enterprise search; AI-zoekplatforms |
| Kennisgraaf-gebaseerd | Gebruikt verbonden entiteiten en relaties om zoekopdrachten te begrijpen en relevante bronnen te matchen | Legt echte wereldrelaties vast; maakt geavanceerd redeneren mogelijk; ondersteunt complexe zoekopdrachten | Vereist uitgebreide kennisgraafconstructie; onderhoudsintensief; domeinspecifiek | Complexe onderzoeksopdrachten; semantische webtoepassingen |
Query-source alignment is fundamenteel voor de werking van moderne AI-zoeksystemen en de selectie van bronnen voor hun antwoorden:
Google AI Overviews – Gebruikt query-source alignment om de meest relevante bronnen te selecteren bij het genereren van AI-zoekoverzichten. Het systeem analyseert de semantische alignment tussen de zoekopdracht van de gebruiker en beschikbare webpagina’s, waarbij bronnen met sterke semantische relevantie en hoge autoriteit worden voorgetrokken. Onderzoek toont aan dat circa 70% van de bronnen in AI Overviews afkomstig is uit de top 10 organische zoekresultaten, wat aangeeft dat traditionele ranking en semantische alignment samen werken.
ChatGPT met Browsen – Wanneer de browsefunctie van ChatGPT is ingeschakeld, gebruikt het query-source alignment om de meest relevante webpagina’s te vinden voor het beantwoorden van vragen. Het systeem geeft voorrang aan gezaghebbende bronnen met sterke semantische alignment bij de zoekopdracht, zodat gegenereerde antwoorden gebaseerd zijn op betrouwbare, relevante informatie van het web.
Perplexity AI – Past query-source alignment toe om bronnen te selecteren voor conversatie-antwoorden. Het platform toont geciteerde bronnen naast de antwoorden, waardoor het alignmentproces transparant is voor gebruikers. Sterke semantische alignment tussen zoekopdrachten en bronnen zorgt ervoor dat de antwoorden van Perplexity goed onderbouwd en verifieerbaar zijn.
Bing AI Chat – Benut query-source alignment om zoekresultaten te integreren in conversatie-antwoorden. Het systeem matcht gebruikersvragen met relevante Bing-zoekresultaten via semantisch begrip en synthetiseert informatie uit meerdere goed aangesloten bronnen tot samenhangende antwoorden.
Core Sources-concept – AI-systemen identificeren ‘kernbronnen’—URL’s die consequent verschijnen in meerdere antwoorden op gerelateerde zoekopdrachten. Deze bronnen hebben een uitzonderlijk sterke semantische alignment met de queryonderwerpen en worden als zeer gezaghebbend beschouwd. Een kernbron worden binnen je niche is een belangrijk doel voor zichtbaarheid in AI-zoeken.
Semantische Relevantiebeoordeling – AI-platforms kennen relevantiescores toe op basis van hoe goed de broninhoud semantisch aansluit bij de zoekintentie. Bronnen met hogere semantische alignment worden eerder geselecteerd, geciteerd en prominent weergegeven in AI-antwoorden.
Multi-Query Alignment – Bij het genereren van antwoorden breken AI-systemen gebruikersvragen vaak op in meerdere subvragen (fan-out queries). Query-source alignment wordt toegepast op elke subquery, en bronnen die goed aansluiten bij meerdere gerelateerde vragen krijgen voorrang, waardoor antwoorden vollediger en beter onderbouwd zijn.
AmICited Monitoring – AmICited volgt query-source alignment door te monitoren welke van jouw pagina’s als bron worden geselecteerd voor specifieke zoekopdrachten op AI-platforms. Het platform toont je semantische alignmentscores, kernbronstatus en kansen om alignment met waardevolle zoekopdrachten in je niche te verbeteren.
Autoriteit en Semantisch Evenwicht – Hoewel domeinautoriteit belangrijk blijft, blijkt uit onderzoek dat semantische alignment steeds belangrijker wordt. Bronnen met sterke semantische alignment maar gemiddelde autoriteit kunnen hoger scoren dan bronnen met veel autoriteit maar zwakke alignment, wat aantoont dat betekenis net zo belangrijk is als reputatie.
Realtime Alignmenttracking – Moderne AI-monitoringplatforms volgen hoe query-source alignment verandert in de tijd naarmate content wordt bijgewerkt en nieuwe bronnen verschijnen. Dit stelt marketeers in staat om te zien welke contentupdates alignment verbeteren en welke zoekopdrachten de beste kansen bieden op zichtbaarheid.
Inzicht in en optimalisatie van query-source alignment is essentieel geworden voor contentmakers, marketeers en merken in het tijdperk van AI-zoeken:
Merkcitatie Tracking – Query-source alignment bepaalt rechtstreeks of jouw merk en content worden geciteerd in door AI gegenereerde antwoorden. Platforms zoals AmICited monitoren deze alignment en tonen voor welke zoekopdrachten jouw content wordt gebruikt in AI-antwoorden en hoe vaak jouw merk wordt genoemd op AI-platforms.
Semantische Relevantie en Ontdekking – Sterke semantische alignment met gebruikersvragen vergroot de kans dat je content wordt ontdekt en geciteerd door AI-systemen. Dit is vooral belangrijk voor longtail-zoekopdrachten en nicheonderwerpen waar traditionele SEO-concurrentie lager is, maar semantische relevantie cruciaal.
Concurrentievoordeel in AI-zoeken – Naarmate AI-zoeken toeneemt, behalen merken met sterke query-source alignment voor waardevolle zoekopdrachten een significant concurrentievoordeel. Vroege optimalisatie voor semantische alignment positioneert je content om zichtbaarheid te winnen voordat concurrenten hun strategie aanpassen.
Brontracking en Attributie – Inzicht in query-source alignment helpt je te volgen welke pagina’s als bron worden geselecteerd voor bepaalde zoekopdrachten. Deze attributiedata onthult welke content het beste presteert in AI-antwoorden en welke onderwerpen kansen bieden voor verbetering.
Optimalisatie voor AI-antwoorden – In plaats van alleen te optimaliseren voor traditionele zoekranking, moet moderne contentstrategie rekening houden met query-source alignment. Content die goed scoort in traditionele zoekresultaten maar zwakke alignment heeft, wordt mogelijk niet geselecteerd door AI-systemen en mist kansen op zichtbaarheid.
Risicobeheersing en Merkontwikkeling – Door query-source alignment te monitoren krijg je inzicht in hoe je merk wordt weergegeven in AI-antwoorden. Als content van concurrenten beter aansluit bij belangrijke zoekopdrachten, kun je hiaten identificeren en content ontwikkelen die beter voldoet aan de gebruikersintentie.
Contentstrategie Verbetering – Query-source alignmentstatistieken onthullen welke onderwerpen, zoekwoorden en contentvormen het meest resoneren met AI-systemen. Deze data stuurt je contentstrategie, zodat je je richt op onderwerpen waar alignment haalbaar en waardevol is.
Concurrentie-informatie – Door query-source alignment in jouw branche te analyseren, zie je welke concurrenten het vaakst worden geciteerd in AI-antwoorden. Deze intelligence toont gaten in je strategie en kansen om zichtbaarheid te winnen.
Langetermijnzichtbaarheid – Query-source alignment is stabieler dan traditionele zoekrangschikking, omdat het gebaseerd is op semantische betekenis in plaats van algoritmische factoren die vaak veranderen. Sterke alignment biedt duurzamere zichtbaarheid in AI-zoeken op de lange termijn.
Meetbare ROI van Contentinvesteringen – Door query-source alignment en zichtbaarheid in AI-antwoorden te volgen, krijg je duidelijke metrics om de ROI van content te meten. Je ziet direct hoe contentinvesteringen leiden tot merkcitatie en verkeer vanuit AI-zoekplatforms.
Optimaliseren voor query-source alignment vereist een strategische benadering die verder gaat dan traditionele SEO. Het doel is om ervoor te zorgen dat jouw content sterk semantisch aansluit bij de zoekopdrachten van je doelgroep, zodat deze sneller door AI-systemen als relevante bron wordt gekozen.
Semantische Optimalisatie Begrijpen – Semantische optimalisatie draait om het diepgaand beantwoorden van specifieke gebruikersintenties en -vragen en niet alleen om ranking op zoekwoorden. Dit vraagt om inzicht in semantische relaties tussen concepten, consistente terminologie en een contentstructuur die betekenis duidelijk communiceert aan zowel mensen als AI-systemen.
Best Practices voor Query-Source Alignment:
Semantisch Zoekwoordonderzoek – Ga verder dan traditioneel zoekwoordonderzoek en identificeer semantische clusters van verwante termen en concepten. Gebruik tools als SEMrush of Ahrefs om niet alleen zoekwoorden met hoog volume te vinden, maar ook semantische variaties en gerelateerde queries die dezelfde intentie aanspreken. Groepeer deze in semantische clusters en creëer uitgebreide content die alle variaties behandelt.
Gebruik Semantische HTML5 Markup – Gebruik semantische HTML5-elementen zoals <article>, <section>, <header>, <nav> en <main> om je content duidelijk te structureren. Deze elementen helpen AI-systemen de organisatie en hiërarchie van je content te begrijpen en verbeteren de semantische interpretatie. Gebruik heading-tags (<h1>, <h2>, enz.) hiërarchisch voor duidelijke onderwerprelaties.
Maak Entiteit-rijke Content – Identificeer belangrijke entiteiten (personen, organisaties, producten, concepten) die relevant zijn voor je onderwerp en benoem deze expliciet in je content. Gebruik consistente terminologie en geef context zodat AI-systemen begrijpen over welke entiteiten je het hebt. Bijvoorbeeld, als je het hebt over “Apple”, geef dan via context aan of je het technologiebedrijf of het fruit bedoelt.
Gebruik Gestructureerde Data (JSON-LD) – Implementeer schema.org-markup met het JSON-LD-formaat om expliciete semantische informatie over je content te geven. Gebruik geschikte schema-types zoals Article, NewsArticle, HowTo, FAQPage of Product afhankelijk van je content. Dit helpt AI-systemen precies te begrijpen waar je content over gaat en hoe het aansluit bij zoekopdrachten.
Optimaliseer voor Variaties in Zoekintentie – Identificeer de verschillende manieren waarop gebruikers dezelfde informatiebehoefte uitdrukken en creëer content die alle variaties behandelt. Gebruikers kunnen bijvoorbeeld zoeken op “hoe los ik een lekkende kraan op”, “kraanreparatiegids” of “oplossingen lekkende kraan”. Maak uitgebreide content die al deze intentievariaties met consistente semantische betekenis behandelt.
Ontwikkel Uitgebreide Topic Coverage – In plaats van veel oppervlakkige artikelen over vergelijkbare onderwerpen, ontwikkel je uitgebreide gidsen die specifieke onderwerpen grondig behandelen. AI-systemen geven de voorkeur aan diepgaande content die volledige antwoorden geeft op gebruikersvragen. Gebruik topic clustering om ervoor te zorgen dat je content alle aspecten van een onderwerp behandelt met sterke semantische relaties tussen secties.
Houd Terminologie Consistent – Gebruik consistente taal en termen in je content en op je website. Introduceer je een concept met een bepaalde term, gebruik deze dan consequent in plaats van te wisselen naar synoniemen. Deze consistentie helpt AI-systemen te herkennen dat je steeds over hetzelfde concept spreekt.
Bouw Duidelijke Contenthiërarchieën – Structureer je content met duidelijke hiërarchieën die laten zien hoe concepten zich tot elkaar verhouden. Gebruik headings, bulletpoints en genummerde lijsten om relaties tussen ideeën aan te geven. Deze structuur helpt AI-systemen de semantische organisatie van je content te begrijpen.
Optimaliseer Meta-descripties en Titels – Schrijf meta-descripties en paginatitels die duidelijk het semantische karakter van je pagina communiceren. Deze elementen worden vaak door AI-systemen gebruikt om de inhoud te begrijpen, dus zorg dat ze het hoofdonderwerp en de belangrijkste concepten van de pagina accuraat weergeven. Verwerk relevante entiteiten en concepten.
Monitor Semantische Alignmentscores – Gebruik AI-monitoringplatforms zoals AmICited om je semantische alignmentscores voor belangrijke zoekopdrachten te volgen. Volg hoe je alignment verandert na contentupdates en zie welke aanpassingen verbetering opleveren. Richt je op zoekopdrachten waar de alignment het sterkst is en breid content in die gebieden uit.
Praktijkvoorbeelden per branche:
E-commerce – Een webshop die hardloopschoenen verkoopt kan optimaliseren voor query-source alignment door uitgebreide gidsen te maken over “marathonschoenen”, “beste hardloopschoenen voor verschillende voettypes” en “vergelijking schoentechnologie”. Door semantische variaties van gebruikersintentie te behandelen en consistente terminologie over schoeneigenschappen te gebruiken, vergroot de winkel de kans om als bron te worden geselecteerd in AI-antwoorden over hardloopschoenen.
Zorgsector – Een medische praktijk kan query-source alignment verbeteren door gedetailleerde content te maken over specifieke aandoeningen, behandelingen en zorgverleners. Met correcte medische terminologie, entiteitsherkenning voor aandoeningen en behandelingen, en gestructureerde data markup kunnen AI-systemen de semantische inhoud beter begrijpen en matchen met relevante gezondheidsvragen.
Technologie – Een softwarebedrijf kan alignment optimaliseren door uitgebreide documentatie en handleidingen te maken die semantische variaties van gebruikersproblemen behandelen. Door consistente terminologie voor functies, duidelijke concepthiërarchieën en gestructureerde data te gebruiken, herkennen AI-systemen de content als relevante bron voor technologievragen.
Traditionele zoekwoordmatching zoekt simpelweg naar exacte woorden of zinnen in documenten, terwijl query-source alignment semantisch begrip gebruikt om de betekenis en intentie achter zoekopdrachten te matchen. Dit betekent dat een zoekopdracht naar 'voertuigonderhoud' ook artikelen over 'auto-onderhoud' kan opleveren, zelfs zonder exacte zoekwoordovereenkomsten. Query-source alignment levert relevantere resultaten op omdat het context en gebruikersintentie begrijpt, en niet alleen oppervlakkige woordgelijkheid.
AI-zoekplatforms gebruiken query-source alignment om de meest relevante bronnen te selecteren die ze citeren in hun gegenereerde antwoorden. Het systeem analyseert zowel de semantische betekenis van de gebruikersvraag als de inhoud van beschikbare bronnen en rangschikt deze op relevantie, autoriteit en semantische alignment. Hierdoor zijn AI-antwoorden gebaseerd op hoogwaardige, relevante bronnen die daadwerkelijk inspelen op de informatiebehoefte van de gebruiker.
Query-source alignment bepaalt direct of jouw content wordt geselecteerd als bron in AI-antwoorden. Als jouw content sterk semantisch aansluit bij veelvoorkomende zoekopdrachten in jouw niche, is de kans groter dat deze door AI-systemen wordt geciteerd. Deze zichtbaarheid in AI-antwoorden zorgt voor meer verkeer en opbouw van merkauthoriteit. Begrip van en optimalisatie voor query-source alignment is essentieel om zichtbaar te blijven in het tijdperk van AI-zoeken.
Om te optimaliseren voor query-source alignment, focus je op het creëren van content die diep ingaat op specifieke gebruikersintenties en vragen. Gebruik semantische HTML-markup, implementeer gestructureerde data (JSON-LD), zorg voor duidelijke entiteitsherkenning en hanteer consistente terminologie. Schrijf uitgebreide, oplossingsgerichte content die vragen volledig beantwoordt. Monitor je semantische alignmentscores en volg hoe jouw content presteert in AI-antwoorden met tools zoals AmICited.
Semantische gelijkenis is het kernmechanisme van query-source alignment. Het meet hoe dicht de betekenis van een zoekopdracht aansluit bij de betekenis van de inhoud in bronnen. Dit wordt berekend met vector embeddings—wiskundige representaties van tekst die semantische betekenis vastleggen. Bronnen met hogere semantische gelijkenisscores ten opzichte van de query worden hoger gerangschikt en hebben meer kans om door AI-systemen geselecteerd te worden als relevante bron voor het beantwoorden van gebruikersvragen.
AmICited is een AI-monitoringplatform dat bijhoudt hoe jouw merk en content worden geciteerd op AI-zoekplatforms. Het monitort query-source alignment door te laten zien welke van jouw pagina's als bron worden geselecteerd voor specifieke zoekopdrachten, hoe vaak jouw merk wordt genoemd in AI-antwoorden en hoe jouw semantische alignment zich verhoudt tot concurrenten. Deze data helpt je om je contentstrategie te begrijpen en te optimaliseren voor betere zichtbaarheid in AI-zoeken.
Kernbronnen zijn URL's die consequent verschijnen in meerdere door AI gegenereerde antwoorden voor dezelfde of gerelateerde zoekopdrachten. Deze bronnen hebben een sterke semantische alignment met de query-onderwerpen en worden door AI-systemen als zeer relevant beschouwd. Kernbronnen staan doorgaans hoger in de traditionele zoekresultaten en sluiten beter aan bij de intentie van de zoekopdracht. Een kernbron worden voor relevante nichezoekopdrachten is een belangrijk doel voor contentzichtbaarheid in AI-zoektoepassingen.
Entiteitsherkenning helpt AI-systemen om belangrijke concepten, personen, organisaties en onderwerpen in zowel zoekopdrachten als broninhoud te identificeren en te begrijpen. Door entiteiten te herkennen, kunnen AI-systemen beter begrijpen waar een zoekopdracht daadwerkelijk over gaat en deze matchen met bronnen die dezelfde entiteiten in relevante contexten behandelen. Bijvoorbeeld, herkennen dat 'Apple' verwijst naar het technologiebedrijf in plaats van de vrucht helpt om zoekopdrachten over Apple-producten te koppelen aan relevante tech-bronnen.
Volg hoe jouw content wordt geciteerd op AI-zoekplatforms en optimaliseer voor betere query-source alignment met het AI-monitoringplatform van AmICited.
Ontdek hoe semantische query matching AI-systemen in staat stelt gebruikersintentie te begrijpen en relevante resultaten te leveren voorbij zoekwoordmatching. V...

Ontdek wat query-to-citation mapping is en hoe je bijhoudt welke zoekopdrachten citaties naar jouw merk activeren in AI-gegenereerde antwoorden op ChatGPT, Gemi...

Ontdek wat informatieve zoekintentie betekent voor AI-systemen, hoe AI deze zoekopdrachten herkent en waarom begrip van deze intentie belangrijk is voor zichtba...
Cookie Toestemming
We gebruiken cookies om uw browse-ervaring te verbeteren en ons verkeer te analyseren. See our privacy policy.