
Sonar-algoritme in Perplexity: Realtime zoekmodel uitgelegd
Ontdek hoe het Sonar-algoritme van Perplexity realtime AI-zoekopdrachten aandrijft met kosteneffectieve modellen. Verken de varianten Sonar, Sonar Pro en Sonar ...
9 min lezen
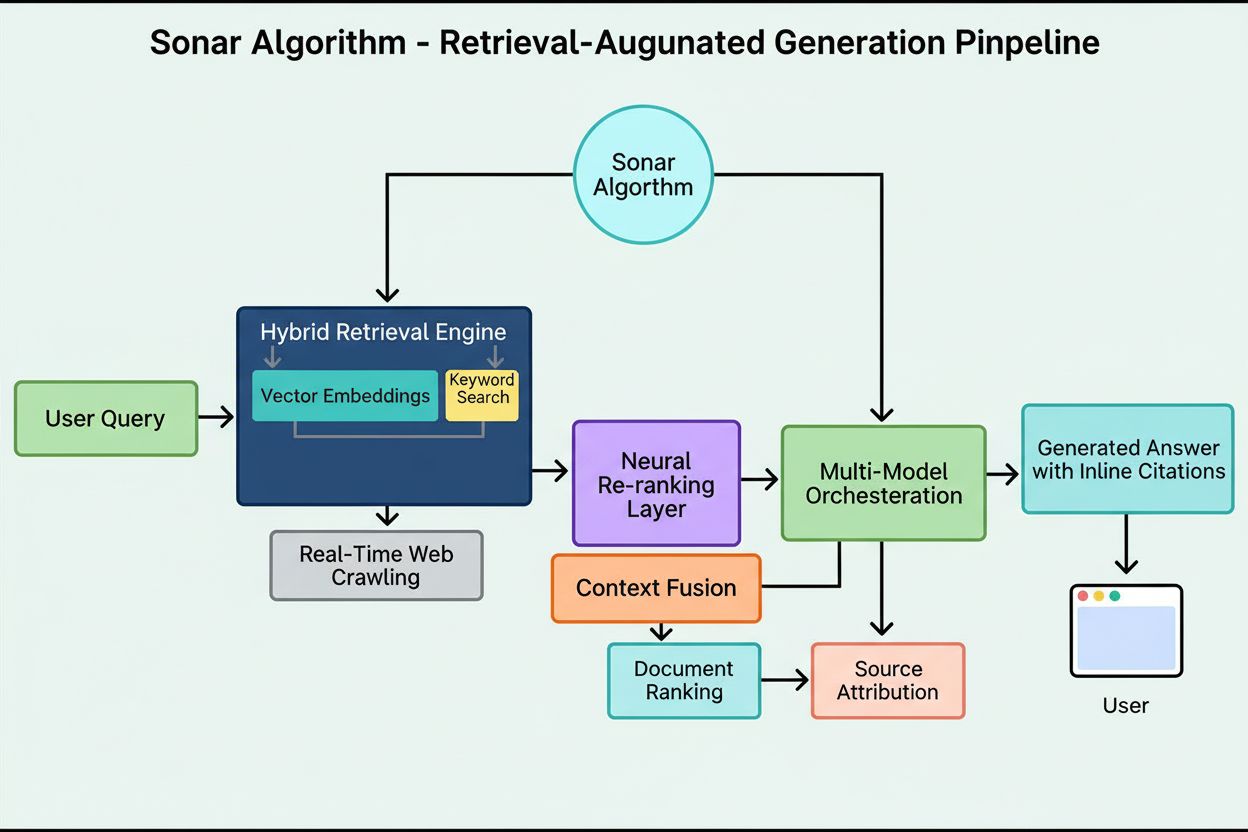
Het Sonar-algoritme is het eigen retrieval-augmented generation (RAG) rankingsysteem van Perplexity dat hybride semantisch en trefwoord zoeken combineert met neurale her-rangschikking om webbronnen in realtime AI-gegenereerde antwoorden op te halen, te rangschikken en te citeren. Het geeft prioriteit aan actualiteit van content, semantische relevantie en citeerbaarheid om onderbouwde, brongebaseerde antwoorden te leveren en hallucinaties te minimaliseren.
Het Sonar-algoritme is het eigen retrieval-augmented generation (RAG) rankingsysteem van Perplexity dat hybride semantisch en trefwoord zoeken combineert met neurale her-rangschikking om webbronnen in realtime AI-gegenereerde antwoorden op te halen, te rangschikken en te citeren. Het geeft prioriteit aan actualiteit van content, semantische relevantie en citeerbaarheid om onderbouwde, brongebaseerde antwoorden te leveren en hallucinaties te minimaliseren.
Sonar-algoritme is het eigen retrieval-augmented generation (RAG) rankingsysteem van Perplexity dat haar antwoordmachine aandrijft door hybride semantisch en trefwoord zoeken, neurale her-rangschikking en realtime citatiegeneratie te combineren. In tegenstelling tot traditionele zoekmachines die pagina’s rangschikken voor weergave in een resultatenlijst, rangschikt Sonar contentfragmenten voor synthese tot één, uniform antwoord met inline citaties naar brondocumenten. Het algoritme geeft prioriteit aan actualiteit van content, semantische relevantie en citeerbaarheid om onderbouwde, brongebaseerde antwoorden te leveren en hallucinaties te minimaliseren. Sonar betekent een fundamentele verschuiving in hoe AI-systemen informatie ophalen en rangschikken—van linkgebaseerde autoriteitssignalen naar antwoordgerichte nutmetrics, waarbij de nadruk ligt op de vraag of content direct aan de gebruikersintentie voldoet en netjes geciteerd kan worden in gesynthetiseerde antwoorden. Dit onderscheid is essentieel om te begrijpen hoe zichtbaarheid in AI-antwoordmachines verschilt van traditionele SEO, want Sonar beoordeelt content niet op de mogelijkheid om te scoren in een lijst, maar op het vermogen om uitgelicht, gesynthetiseerd en toegeschreven te worden binnen een AI-gegenereerd antwoord.
De opkomst van het Sonar-algoritme weerspiegelt een bredere verschuiving in de industrie naar retrieval-augmented generation als dominante architectuur voor AI-antwoordmachines. Toen Perplexity eind 2022 werd gelanceerd, signaleerde het bedrijf een belangrijke leemte in het AI-landschap: hoewel ChatGPT krachtige conversatiecapaciteiten bood, ontbrak het aan realtime informatie en bronvermelding, wat leidde tot hallucinaties en verouderde antwoorden. Het oprichtersteam van Perplexity, dat aanvankelijk werkte aan een databasequery-vertaaltool, koos er volledig voor om een antwoordmachine te bouwen die live websearch met LLM-synthese kon combineren. Deze strategische beslissing heeft de architectuur van Sonar vanaf het begin gevormd—het algoritme werd niet ontworpen om pagina’s te rangschikken voor menselijke browse-ervaring, maar om contentfragmenten op te halen en te rangschikken voor machinesynthese en citatie. In de afgelopen twee jaar is Sonar uitgegroeid tot een van de meest geavanceerde rankingsystemen in het AI-ecosysteem, waarbij Perplexity’s Sonar-modellen de plaatsen 1 tot en met 4 bezetten in de Search Arena Evaluation, en daarmee concurrerende modellen van Google en OpenAI ruim overtreffen. Het algoritme verwerkt nu meer dan 400 miljoen zoekopdrachten per maand, indexeert meer dan 200 miljard unieke URL’s en behoudt realtime actualiteit met tienduizenden indexupdates per seconde. Deze schaal en verfijning onderstrepen het belang van Sonar als bepalend rankingsysteem in het AI-zoektijdperk.
Het rankingsysteem van Sonar werkt via een minutieus georganiseerde vijf-fasen retrieval-augmented generation-pijplijn die gebruikersvragen omzet in onderbouwde, geciteerde antwoorden. De eerste fase, Query Intent Parsing, gebruikt een LLM om verder te gaan dan simpele trefwoordenmatching en semantisch te begrijpen wat de gebruiker werkelijk vraagt, inclusief context, nuance en onderliggende intentie. De tweede fase, Live Web Retrieval, stuurt de geparste zoekopdracht naar Perplexity’s enorme gedistribueerde index op basis van Vespa AI, die het web in realtime doorzoekt naar relevante pagina’s en documenten. Dit retrievalsysteem combineert dense retrieval (vectorzoektocht met semantische embeddings) en sparse retrieval (lexicaal/trefwoord-gebaseerd zoeken), en voegt de resultaten samen tot ongeveer 50 diverse kandidaatdocumenten. De derde fase, Snippet Extraction en Contextualisatie, stuurt geen volledige paginatekst naar het generatieve model; in plaats daarvan extraheren algoritmes de meest relevante fragmenten, alinea’s of chunks die direct op de vraag betrekking hebben, en bundelen die tot een gefocust contextvenster. De vierde fase, Gesynthetiseerde Antwoordgeneratie met Citatie, voert deze samengestelde context door naar een gekozen LLM (van Perplexity’s eigen Sonar-familie of externe modellen zoals GPT-4 of Claude), die een natuurlijk geformuleerd antwoord genereert op basis van uitsluitend opgehaalde informatie. Cruciaal is dat inline citaties iedere bewering koppelen aan brondocumenten, waardoor transparantie ontstaat en verificatie mogelijk is. De vijfde fase, Conversational Refinement, behoudt de conversatiecontext over meerdere rondes, zodat vervolgvragen antwoorden kunnen verfijnen via iteratieve websearches. Het leidende principe van deze pijplijn—“je mag niets zeggen dat je niet hebt opgehaald”—garandeert dat door Sonar aangedreven antwoorden gebaseerd zijn op verifieerbare bronnen, waardoor hallucinaties fundamenteel worden teruggedrongen in vergelijking met modellen die uitsluitend op trainingsdata leunen.
| Aspect | Traditionele zoekmachine (Google) | Sonar-algoritme (Perplexity) | ChatGPT ranking | Gemini ranking | Claude ranking |
|---|---|---|---|---|---|
| Primaire eenheid | Gerangschikte lijst met links | Eén gesynthetiseerd antwoord met citaties | Consensus-gebaseerde entiteitsvermeldingen | E-E-A-T-uitgelijnde content | Neutrale, feitgebaseerde bronnen |
| Retrieval-focus | Trefwoorden, links, ML-signalen | Hybride semantisch + trefwoord zoeken | Trainingsdata + web browsing | Kennisgraaf-integratie | Constitutionele veiligheidsfilters |
| Actualiteit-prioriteit | Query-deserves-freshness (QDF) | Realtime webophaling, 37% boost binnen 48 uur | Lagere prioriteit, afhankelijk van trainingsdata | Gemiddeld, geïntegreerd met Google Search | Lagere prioriteit, focus op stabiliteit |
| Rankingsignalen | Backlinks, domeinautoriteit, CTR | Actualiteit, semantische relevantie, citeerbaarheid, autoriteitsversterking | Entiteitsherkenning, consensusvermeldingen | E-E-A-T, conversatie-afstemming, gestructureerde data | Transparantie, verifieerbare citaties, neutraliteit |
| Citatiemechanisme | URL-fragmenten in resultaten | Inline citaties met bronlinks | Impliciet, vaak geen citatie | AI Overviews met bronvermelding | Expliciete bronvermelding |
| Contentdiversiteit | Meerdere resultaten over sites | Selectie van enkele bronnen voor synthese | Gesynthetiseerd uit meerdere bronnen | Meerdere bronnen in overzicht | Gebalanceerde, neutrale bronnen |
| Personalisatie | Subtiel, meestal impliciet | Expliciete focusmodi (Web, Academisch, Finance, Schrijven, Sociaal) | Impliciet op basis van conversatie | Impliciet op basis van vraagtype | Minimaal, nadruk op consistentie |
| PDF-afhandeling | Standaard indexatie | 22% citatievoordeel t.o.v. HTML | Standaard indexatie | Standaard indexatie | Standaard indexatie |
| Schema-markup impact | FAQ-schema in featured snippets | FAQ-schema verhoogt citaties 41%, versnelt tijd-tot-citatie met 6 uur | Minimaal direct effect | Gemiddeld effect op kennisgraaf | Minimaal direct effect |
| Latency-optimalisatie | Milliseconden voor ranking | Sub-seconde retrieval + generatie | Seconden voor synthese | Seconden voor synthese | Seconden voor synthese |
De technische basis van het Sonar-algoritme berust op een hybride retrieval engine die meerdere zoekstrategieën combineert om zowel recall als precisie te maximaliseren. Dense retrieval (vectorzoektocht) gebruikt semantische embeddings om de conceptuele betekenis achter zoekopdrachten te begrijpen en contextueel vergelijkbare documenten te vinden, zelfs zonder exacte trefwoordovereenkomst. Deze aanpak maakt gebruik van transformer-embeddings die zoekopdrachten en documenten in hoog-dimensionale vectorruimtes plaatsen, waar semantisch vergelijkbare content bij elkaar clustert. Sparse retrieval (lexicaal zoeken) vult dense retrieval aan door precisie te bieden bij zeldzame termen, productnamen, interne bedrijfsidentificaties en specifieke entiteiten waarbij semantische ambiguïteit ongewenst is. Het systeem gebruikt rankingfuncties zoals BM25 voor exacte overeenkomsten op deze kritische termen. Beide retrieval-methoden worden samengevoegd en ontdubbeld tot ongeveer 50 diverse kandidaatdocumenten, wat domeinoverfitting voorkomt en brede dekking garandeert over meerdere gezaghebbende bronnen. Na de initiële retrieval gebruikt Sonar’s neurale her-rangschikkinglaag geavanceerde machine learning-modellen (zoals DeBERTa-v3 cross-encoders) om kandidaten te beoordelen op basis van een rijk feature-set waaronder lexicale relevantiescores, vectorsimilariteit, documentautoriteit, actualiteitssignalen, gebruikersengagement en metadata. Deze meerfasige rankingarchitectuur stelt Sonar in staat resultaten progressief te verfijnen binnen strakke latency-eisen, zodat de uiteindelijke rangschikking de hoogste kwaliteit en relevantie vertegenwoordigt voor synthese. De complete retrieval-infrastructuur is gebouwd op Vespa AI, een gedistribueerd zoekplatform dat web-scale indexering (200+ miljard URL’s), realtime updates (tienduizenden per seconde) en fijnmazige contentbegrip via documentchunking aankan. Deze architectuurkeuze stelt Perplexity’s relatief kleine engineeringteam in staat zich te focussen op onderscheidende componenten—RAG-orchestratie, Sonar-model-finetuning en inferentieoptimalisatie—in plaats van distributed search opnieuw te moeten uitvinden.
Actualiteit van content is een van Sonar’s krachtigste rankingsignalen, met empirisch onderzoek dat aantoont dat recent bijgewerkte pagina’s aanzienlijk vaker worden geciteerd. In gecontroleerde A/B-tests gedurende 24 weken op 120 URL’s, werden artikelen die binnen de laatste 48 uur waren bijgewerkt 37% vaker geciteerd dan identieke content met oudere tijdstempels. Dit voordeel bleef ongeveer 14% na twee weken, wat betekent dat actualiteit een aanhoudende maar geleidelijk afnemende boost geeft. Het mechanisme achter deze prioriteit zit in Sonar’s ontwerpfilosofie: het algoritme ziet verouderde content als een groter hallucinatierisico, ervan uitgaande dat achterhaalde informatie kan zijn ingehaald door nieuwe ontwikkelingen. Perplexity’s infrastructuur verwerkt tienduizenden indexupdateverzoeken per seconde, waardoor realtime actualiteitssignalen mogelijk zijn. Een ML-model voorspelt of een URL opnieuw geïndexeerd moet worden en plant updates op basis van het belang van de pagina en historische updatefrequentie, zodat waardevolle content agressiever wordt vernieuwd. Zelfs kleine cosmetische aanpassingen resetten de actualiteitsklok, mits het CMS de gewijzigde tijdstempel publiceert. Voor uitgevers betekent dit een strategisch imperatief: hanteer een nieuwsroomritme met wekelijkse of dagelijkse updates, of zie hoe evergreen content langzaam aan zichtbaarheid verliest. De implicatie is groot—in het Sonar-tijdperk is contentvelocity geen ijdelheidsmetric, maar een overlevingsmechanisme. Merken die wekelijkse micro-updates automatiseren, live changelogs toevoegen of continue contentoptimalisatieworkflows onderhouden, zullen een buitenproportioneel deel van de citaties krijgen vergeleken met concurrenten die vertrouwen op statische, zelden bijgewerkte pagina’s.
Sonar geeft prioriteit aan semantische relevantie boven trefwoorddichtheid en beloont content die direct antwoord geeft op gebruikersvragen in natuurlijke, conversatietaal. Het retrievalsysteem van het algoritme gebruikt dichte vectorembeddings om zoekopdrachten op conceptueel niveau te koppelen aan content, wat betekent dat pagina’s met synoniemen, verwante terminologie of contextueel rijke taal hoger kunnen scoren dan met trefwoorden gevulde pagina’s zonder semantische diepgang. Deze verschuiving van trefwoordgecentreerd naar betekenisgecentreerd rangschikken heeft grote gevolgen voor contentstrategie. Content die scoort in Sonar heeft verschillende structurele kenmerken: het begint met een korte, feitelijke samenvatting voordat het in detail treedt, gebruikt beschrijvende H2/H3-koppen en korte alinea’s voor makkelijke passage-extractie, bevat duidelijke citaties en links naar primaire bronnen, en toont zichtbare tijdstempels en versienotities om actualiteit aan te geven. Elke alinea fungeert als een atomair semantisch blok, geoptimaliseerd voor copy-paste-niveau duidelijkheid en LLM-begrip. Tabellen, opsommingen en gelabelde grafieken zijn bijzonder waardevol omdat ze informatie gestructureerd en makkelijk citeerbaar presenteren. Het algoritme beloont ook originele analyses en unieke data boven louter aggregatie, want Sonar’s synthese-engine zoekt naar bronnen met nieuwe invalshoeken, primaire documenten of eigen inzichten die ze onderscheiden van generieke overzichten. Deze focus op semantische rijkdom en antwoordgerichte structuur is een fundamentele breuk met traditionele SEO, waar trefwoordplaatsing en linkautoriteit overheersten. In het Sonar-tijdperk moet content ontworpen zijn voor machinale retrieval en synthese, niet voor menselijke browse-ervaring.
Openbaar gehoste PDF’s vormen een aanzienlijk, vaak onderschat voordeel in Sonar’s rankingsysteem, waarbij empirische tests aantonen dat PDF-versies van content ongeveer 22% vaker worden geciteerd dan HTML-equivalenten. Dit voordeel komt doordat Sonar’s crawler PDF’s gunstig behandelt ten opzichte van HTML-pagina’s. PDF’s missen cookiebanners, JavaScript-rendering, betaalmuren en andere HTML-complicaties die toegang tot content kunnen belemmeren of vertragen. Sonar’s crawler kan PDF’s direct en eenduidig lezen, zonder de ambiguïteit van complexe HTML-structuren. Uitgevers kunnen dit voordeel benutten door PDF’s in publiek toegankelijke mappen te plaatsen, semantische bestandsnamen te kiezen die het onderwerp weergeven, en de PDF als canoniek aan te geven met <link rel="alternate" type="application/pdf">-tags in de HTML-head. Dit creëert wat onderzoekers een “LLM honingval” noemen—een zeer zichtbaar bestand dat door tracking-scripts van concurrenten moeilijk te detecteren of te monitoren is. Voor B2B-bedrijven, SaaS-aanbieders en onderzoeksorganisaties is deze strategie bijzonder krachtig: publicatie van whitepapers, onderzoeksrapporten, casestudies en technische documentatie als PDF kan het aantal Sonar-citaties aanzienlijk verhogen. De sleutel is om de PDF niet als een downloadbare bijzaak te behandelen, maar als een canoniek exemplaar dat net zo veel (of meer) optimalisatie verdient als de HTML-versie. Deze aanpak werkt vooral goed bij enterprise-content, waar PDF’s vaak meer gestructureerde, gezaghebbende informatie bevatten dan webpagina’s.
JSON-LD FAQ-schema markup vergroot de Sonar-citatiefrequentie aanzienlijk, waarbij pagina’s met drie of meer FAQ-blokken 41% vaker worden geciteerd dan controlepagina’s zonder schema. Deze spectaculaire toename weerspiegelt Sonar’s voorkeur voor gestructureerde, chunk-gebaseerde content die aansluit bij zijn retrieval- en syntheselogica. FAQ-schema presenteert discrete, op zichzelf staande Q&A-eenheden die het algoritme eenvoudig kan extraheren, rangschikken en als semantische blokken citeren. In tegenstelling tot traditionele SEO, waar FAQ-schema een ’nice-to-have’ was, ziet Sonar gestructureerde Q&A-markup als een essentiële rankinghefboom. Sonar citeert bovendien vaak FAQ-vragen als anchortekst, waardoor het risico op contextverschuiving afneemt dat optreedt wanneer de LLM willekeurige delen van alinea’s samenvat. Het schema versnelt ook de tijd tot eerste citatie met ongeveer zes uur, wat suggereert dat Sonar’s parser gestructureerde Q&A-blokken vroeg in het rankingproces prioriteert. Voor uitgevers is de optimalisatiestrategie eenvoudig: plaats drie tot vijf gerichte FAQ-blokken onderaan de pagina, met conversatiegerichte vragen die echte gebruikersvragen nabootsen. Vragen dienen longtail-zoekfrases en semantische overeenstemming te hebben met waarschijnlijke Sonar-queries. Elk antwoord moet beknopt, feitelijk en direct zijn, zonder opvul- of marketingtaal. Deze aanpak werkt vooral goed voor SaaS-bedrijven, klinieken en zakelijke dienstverleners, waar FAQ-content van nature aansluit bij gebruikersintentie en de synthese-eisen van Sonar.
Sonar’s rankingsysteem integreert meerdere signalen in één citatiekader, waarbij onderzoek acht primaire factoren identificeert die bronselectie en citatiefrequentie beïnvloeden. Ten eerste domineert semantische relevantie voor de vraag de retrieval, waarbij het algoritme content prioriteert die de vraag duidelijk in natuurlijke taal beantwoordt. Ten tweede zijn autoriteit en geloofwaardigheid van groot belang; Perplexity’s uitgeverspartnerschappen en algoritmische boosts bevoordelen gevestigde nieuwsorganisaties, academische instellingen en erkende experts. Ten derde krijgt actualiteit uitzonderlijk veel gewicht, zoals besproken, waarbij recente updates tot 37% meer citaties opleveren. Ten vierde worden diversiteit en dekking gewaardeerd, want Sonar prefereert meerdere hoogwaardige bronnen boven enkelvoudige, om hallucinaties te beperken via kruisverificatie. Ten vijfde bepalen modus en scope welke indexen Sonar doorzoekt—focusmodi zoals Academisch, Finance, Schrijven en Sociaal beperken het type bronnen, terwijl bronselectoren (Web, Org Files, Web + Org Files, Geen) bepalen of de retrieval open web, interne documenten of beide gebruikt. Ten zesde zijn citeerbaarheid en toegankelijkheid cruciaal; als PerplexityBot de content kan crawlen en indexeren, is deze makkelijker te citeren, dus robots.txt-compliance en paginalaadsnelheid zijn essentieel. Ten zevende maken aangepaste bronfilters via API het mogelijk om bij bedrijfsuitrol bepaalde domeinen te prefereren of beperken, wat de ranking in whitelisted collecties verandert. Ten achtste beïnvloedt conversatiecontext vervolgvragen, waarbij pagina’s die met veranderende intenties matchen hoger scoren dan generieke verwijzingen. Samen creëren deze factoren een multidimensionaal rankingspectrum waarin succes optimalisatie op meerdere vlakken tegelijk vereist, niet slechts één hefboom zoals backlinks of trefwoorddichtheid.
Het Sonar-algoritme ontwikkelt zich razendsnel dankzij vooruitgang in LLM-inferentie en retrievaltechnologie. De engineeringblog van Perplexity belichtte recent speculatieve decodering, een techniek waarmee tokenlatency wordt gehalveerd door meerdere toekomstige tokens tegelijk te voorspellen. Snellere generatielussen maken het mogelijk om bij elke zoekopdracht actualere retrievalsets te leveren, waardoor het tijdsvenster waarin verouderde pagina’s kunnen scoren verkleint. Een geruchtmakend Sonar-Reasoning-Pro-model overtreft inmiddels Gemini 2.0 Flash en GPT-4o Search in arena-evaluaties, wat suggereert dat de rankingsofisticatie van Sonar verder zal toenemen. Naarmate latency de snelheid van menselijke gedachten benadert, wordt citatieconcurrentie een high-frequency game waarbij contentvelocity de ultieme onderscheidende factor is. Verwacht opkomende infrastructuurinnovaties als “LLM freshness API’s” die tijdstempels automatisch verhogen zoals ad-tech ooit biedprijzen deed, wat nieuwe concurrentiedynamiek rond realtime contentupdates zal creëren. Juridische en ethische kwesties zullen de kop opsteken nu PDF-piraten Sonar’s PDF-voorkeur uitbuiten om autoriteit af te snoepen van afgeschermde e-books en proprietary onderzoek, wat mogelijk leidt tot strengere toegangscontroles of authenticatie-eisen. De bredere implicatie is duidelijk: het Sonar-tijdperk beloont uitgevers die elke alinea behandelen als een atomair, schema-wrapped, getimestamp manifest klaar voor machineconsumptie. Merken die zich blindstaren op eerste pagina Google-rankings maar Sonar-zichtbaarheid negeren, schilderen billboards in een stad waar de bewoners net een VR-bril hebben opgezet. De toekomst is voor wie optimaliseert op “percentage van antwoordvakken met onze URL”, niet op traditionele CTR-metrics.
Het Sonar-algoritme betekent een fundamentele herziening van hoe rankingsystemen content beoordelen en prioriteren in het tijdperk van AI-gestuurde antwoordmachines. Door hybride retrieval, neurale her-rangschikking, realtime actualiteitssignalen en strikte citatievereisten te combineren, heeft Sonar een rankingmilieu gecreëerd waarin traditionele SEO-signalen als backlinks en trefwoorddichtheid veel minder zwaar wegen dan semantische relevantie, actualiteit van content en citeerbaarheid. De nadruk van het algoritme op onderbouwing van antwoorden met verifieerbare bronnen pakt een van de grootste uitdagingen van generatieve AI aan—hallucinatie—door strikt af te dwingen dat LLM’s niets mogen claimen wat niet is opgehaald. Voor uitgevers en merken is inzicht in Sonar’s rankingfactoren niet langer optioneel; het is essentieel voor zichtbaarheid in een steeds meer door AI gemedieerd informatielandschap. De verschuiving van linkgebaseerde autoriteit naar antwoordgerichte nutmetrics vereist een fundamenteel andere contentstrategie, van trefwoordoptimalisatie naar semantische rijkdom, van statische pagina’s naar continu bijgewerkte assets, en van mensgerichte vormgeving naar machineleesbare structuur. Naarmate Perplexity marktaandeel wint en concurrerende AI-antwoordmachines vergelijkbare RAG-architecturen invoeren, zal de invloed van Sonar alleen maar groeien. De winnende merken van deze nieuwe tijd zijn zij die Sonar niet als bedreiging voor traditionele SEO zien, maar als een aanvullend rankingsysteem dat een eigen optimalisatiestrategie vereist. Door content te behandelen als atomair, getimestamp en schema-gealigneerd, geoptimaliseerd voor machinale retrieval en synthese, kunnen uitgevers hun plek veiligstellen in de AI-antwoordvakken die steeds vaker bepalen hoe gebruikers informatie online ontdekken en consumeren.
Het **Sonar-algoritme** is het eigen rankingsysteem van Perplexity dat haar antwoordmachine aandrijft en fundamenteel verschilt van traditionele zoekmachines zoals Google. Waar Google pagina's rangschikt voor vertoning in een lijst met blauwe links, rangschikt Sonar inhoudsfragmenten voor synthese tot één, uniform antwoord met inline citaties. Sonar gebruikt retrieval-augmented generation (RAG), waarbij hybride zoeken (vector-embeddings plus trefwoordovereenkomst), neurale her-rangschikking en realtime webophaling worden gecombineerd om antwoorden te onderbouwen met verifieerbare bronnen. Deze benadering geeft prioriteit aan semantische relevantie en actualiteit van content boven traditionele SEO-signalen zoals backlinks, waardoor het een uniek rankingsparadigma is dat is geoptimaliseerd voor AI-gegenereerde synthese in plaats van linkgebaseerde autoriteit.
Sonar implementeert een **hybride retrieval engine** die twee complementaire zoekstrategieën combineert: dense retrieval (vectorzoektocht met semantische embeddings) en sparse retrieval (lexicaal/trefwoord-gebaseerd zoeken met BM25). Dense retrieval vangt conceptuele betekenis en context, waardoor het systeem semantisch vergelijkbare content kan vinden, zelfs zonder exacte trefwoordovereenkomst. Sparse retrieval biedt precisie voor zeldzame termen, productnamen en specifieke identificaties waarbij semantische ambiguïteit ongewenst is. Deze twee retrieval-methoden worden samengevoegd en ontdubbeld om ongeveer 50 diverse kandidaatdocumenten te produceren, waardoor domeinoverfitting wordt voorkomen en brede dekking wordt gewaarborgd. Deze hybride aanpak overtreft enkelvoudige methoden zowel qua recall als relevantie.
De primaire rankingfactoren voor Sonar zijn: (1) **Actualiteit van content** – recent bijgewerkte of gepubliceerde pagina's krijgen 37% meer citaties binnen 48 uur na de update; (2) **Semantische relevantie** – content moet rechtstreeks de vraag beantwoorden in natuurlijke taal, waarbij duidelijkheid belangrijker is dan trefwoorddichtheid; (3) **Autoriteit en geloofwaardigheid** – bronnen van gevestigde uitgevers, academische instellingen en nieuwsorganisaties krijgen een algoritmische boost; (4) **Citeerbaarheid** – content moet gemakkelijk te citeren zijn en gestructureerd met duidelijke koppen, tabellen en alinea's; (5) **Diversiteit** – Sonar geeft de voorkeur aan meerdere hoogwaardige bronnen boven enkelvoudige antwoorden; en (6) **Technische toegankelijkheid** – pagina's moeten door PerplexityBot gecrawld kunnen worden en snel laden voor on-demand browsen.
**Actualiteit is een van Sonar's belangrijkste rankingsignalen**, vooral voor tijdgevoelige onderwerpen. Perplexity's infrastructuur verwerkt tienduizenden indexupdateverzoeken per seconde, zodat de index altijd de meest actuele informatie bevat. Een ML-model voorspelt of een URL opnieuw geïndexeerd moet worden en plant updates op basis van het belang van de pagina en de updatefrequentie. Uit empirische tests blijkt dat content die binnen de laatste 48 uur is bijgewerkt 37% meer citaties ontvangt dan identieke content met een oudere tijdstempel, en dit voordeel blijft 14% na twee weken. Zelfs kleine bewerkingen resetten de actualiteitsklok, waardoor continue contentoptimalisatie essentieel is voor zichtbaarheid in door Sonar aangedreven antwoorden.
**PDF's vormen een aanzienlijk voordeel in Sonar's rankingsysteem**, en presteren vaak 22% beter dan HTML-versies van dezelfde content qua citatiefrequentie. De crawler van Sonar behandelt PDF's gunstig omdat ze geen cookiebanners, betaalmuren, JavaScript-problemen of andere HTML-complicaties hebben die content kunnen verbergen. Uitgevers kunnen de zichtbaarheid van PDF's optimaliseren door ze in publiek toegankelijke mappen te plaatsen, semantische bestandsnamen te gebruiken en de PDF als canoniek aan te geven met ``-tags in de HTML-head. Dit creëert wat onderzoekers een "LLM honingval" noemen, die door tracking-scripts van concurrenten moeilijk te detecteren is, waardoor PDF's een strategisch voordeel bieden voor Sonar-citaties.
**JSON-LD FAQ-schema verhoogt de Sonar-citatiefrequentie aanzienlijk**, waarbij pagina's met drie of meer FAQ-blokken 41% vaker geciteerd worden dan controlepagina's zonder schema. FAQ-markup sluit perfect aan bij Sonar's chunk-gebaseerde retrievallogica omdat het discrete, op zichzelf staande Q&A-eenheden biedt die het algoritme eenvoudig kan extraheren en citeren. Daarnaast citeert Sonar vaak FAQ-vragen als anchortekst, waardoor het risico op contextverschuiving afneemt dat kan optreden wanneer de LLM willekeurige alinea's samenvat. Het schema versnelt ook de tijd tot de eerste citatie met ongeveer zes uur, wat suggereert dat Sonar's parser gestructureerde Q&A-blokken vroeg in de rangschikkingscascade prioriteert.
Sonar hanteert een **drie-fasen retrieval-augmented generation (RAG) pijplijn** die antwoorden baseert op geverifieerde externe kennis. Fase één haalt relevante documenten op met hybride zoektechnologie; fase twee extraheert en contextualiseert de meest relevante fragmenten; fase drie synthetiseert een antwoord uitsluitend op basis van de aangeleverde context, met de strikte regel: "je mag niets zeggen dat je niet hebt opgehaald." Deze architectuur koppelt retrieval en generatie nauw, zodat elke bewering traceerbaar is naar een bron. Inline citaties linken de gegenereerde tekst terug naar bronbestanden, zodat gebruikers kunnen verifiëren. Deze onderbouwing vermindert hallucinaties aanzienlijk ten opzichte van modellen die uitsluitend op trainingsdata vertrouwen, waardoor Sonar's antwoorden feitelijk betrouwbaarder en geloofwaardiger zijn.
Waar **ChatGPT entiteitsherkenning en consensus** uit zijn trainingsdata prioriteert, **legt Gemini de nadruk op E-E-A-T-signalen en conversatie-afstemming**, en **Claude focust op constitutionele veiligheid en neutraliteit**, **geeft Sonar uniek prioriteit aan realtime actualiteit en semantische diepte**. Sonar's drielaagse machine learning-reranker past strengere kwaliteitsfilters toe dan traditionele zoekmachines en gooit complete resultaten weg als de kwaliteit niet voldoet. In tegenstelling tot ChatGPT's afhankelijkheid van historische trainingsdata, voert Sonar bij elke zoekopdracht live webophaling uit, zodat antwoorden up-to-date zijn. Sonar verschilt ook van Gemini's kennisgraaf-integratie door de nadruk op semantische relevantie op alinea-niveau, en van Claude's neutraliteitsfocus door autoriteitsversterking voor gevestigde uitgevers te accepteren.
Begin met het volgen van hoe AI-chatbots uw merk vermelden op ChatGPT, Perplexity en andere platforms. Krijg bruikbare inzichten om uw AI-aanwezigheid te verbeteren.
Ontdek hoe het Sonar-algoritme van Perplexity realtime AI-zoekopdrachten aandrijft met kosteneffectieve modellen. Verken de varianten Sonar, Sonar Pro en Sonar ...
Surfer SEO is een contentoptimalisatieplatform dat 500+ rankingfactoren analyseert. Ontdek hoe het helpt content te optimaliseren voor Google-rankings en AI-zic...
RankBrain is Google's door AI aangedreven machine learning systeem dat zoekintentie interpreteert en resultaten rangschikt. Leer hoe deze kern ranking factor SE...
Cookie Toestemming
We gebruiken cookies om uw browse-ervaring te verbeteren en ons verkeer te analyseren. See our privacy policy.