Hvordan bestemmer AI-modeller hva de skal sitere i AI-svar
Lær hvordan AI-modeller som ChatGPT, Perplexity og Gemini velger hvilke kilder de skal sitere. Forstå siteringsmekanismer, rangeringsfaktorer og optimaliserings...
11 min lesing
Lær hvordan AI-modeller genererer svar og plasserer siteringer. Oppdag hvor innholdet ditt vises i ChatGPT, Perplexity og Google AI-responser, og hvordan du optimaliserer for AI-synlighet.
AI-genererte svar har blitt den primære metoden for informasjonsinnhenting for millioner av brukere og endrer fundamentalt hvordan informasjon flyter på internett. Ifølge fersk forskning hoppet AI-adopsjonen blant forskere til 84 % i 2025, med 62 % som spesifikt bruker AI-verktøy til forsknings- og publiseringsoppgaver—en dramatisk økning fra kun 57 % samlet AI-bruk i 2024. Likevel er de fleste innholdsskapere uvitende om at plasseringen av siteringer i slike AI-genererte svar ikke er tilfeldig; den følger en sofistikert teknisk arkitektur som bestemmer hvilke kilder som får synlighet og hvilke som forblir usynlige. Å forstå hvor og hvorfor siteringer oppstår er nå essensielt for alle som ønsker å opprettholde synlighet i et AI-drevet oppdagelseslandskap.
Skillet mellom modell-native syntese og Retrieval-Augmented Generation (RAG) former fundamentalt hvordan siteringer vises i AI-responser. Modell-native syntese baseres utelukkende på kunnskap kodet under trening, mens RAG dynamisk henter eksterne kilder for å forankre svarene i oppdatert informasjon. Denne forskjellen har stor betydning for siteringsplassering og synlighet.
| Egenskap | Modell-native syntese | RAG |
|---|---|---|
| Definisjon | Svar generert kun fra treningsdata | Svar forankret i sanntids-hentede kilder |
| Hastighet | Raskere (ingen henting av kilder) | Tregere (krever henting av kilder) |
| Nøyaktighet | Utsatt for hallusinasjoner og utdatert info | Høyere nøyaktighet med aktuelle kilder |
| Siteringsmulighet | Begrensede eller ingen siteringer | Rike, sporbare siteringer |
| Bruksområder | Generell kunnskap, kreative oppgaver | Nyheter, forskning, faktasjekk, proprietær data |
RAG-baserte systemer som Perplexity og Googles AI Overviews produserer naturlig flere siteringer fordi de må referere til hentedataene, mens modell-native tilnærminger som tradisjonelle ChatGPT-svar ofte siterer sjeldnere. Å vite hvilken tilnærming en plattform bruker hjelper innholdsskapere forutsi siteringssannsynlighet og optimalisere deretter.
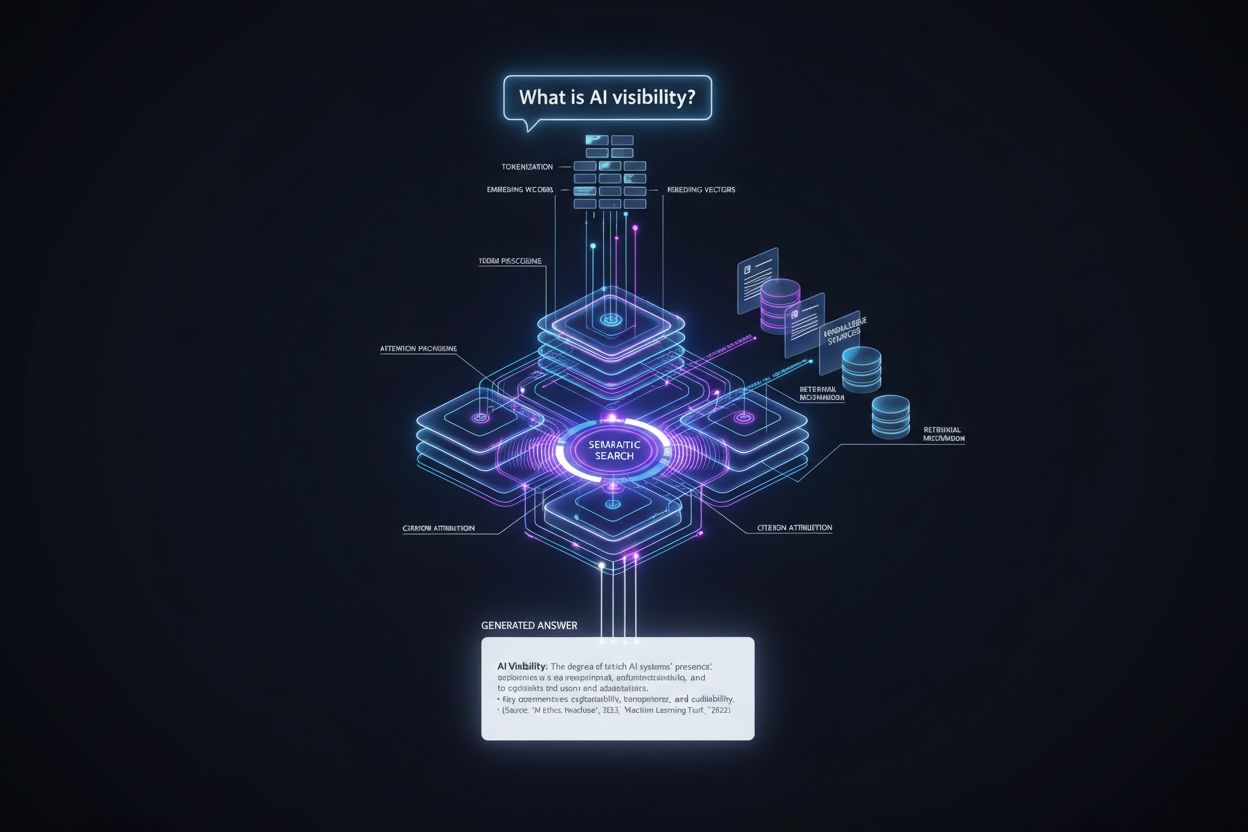
Veien fra brukerforespørsel til sitert svar følger en presis teknisk rørledning som avgjør siteringsplassering i flere steg. Slik foregår prosessen:
Forespørselsprosessering: Brukerens spørsmål tokeniseres—deles opp i enheter modellen forstår—og analyseres for intensjon, entiteter og semantisk betydning gjennom embedding-vektorer.
Informasjonshenting: Systemet søker i sin kunnskapsbase (treningsdata, indekserte dokumenter eller sanntidskilder) ved hjelp av semantisk søk, matcher meningen i forespørselen fremfor eksakte nøkkelord, og returnerer kandidatkilder rangert etter relevans.
Kontekstmontering: Hentet informasjon organiseres i et kontekstvindu—tekstmengden modellen kan prosessere samtidig—med de mest relevante kildene plassert fremst for å påvirke oppmerksomhetsmekanismer.
Token-generering: Modellen genererer svaret én token om gangen, bruker selvoppmerksomhetsmekanismer for å avgjøre hvilke tidligere tokens og kildeinformasjon som skal påvirke hver nye token, og skaper sammenhengende, kontekstuelt forankrede svar.
Siteringstilskrivelse: Etter hvert som tokens genereres, sporer modellen hvilke kildedokumenter som påvirket bestemte påstander, tildeler troverdighets-score og avgjør om eksplisitte siteringer bør inkluderes basert på sikkerhetsnivå og plattformkrav.
Levere ut svaret: Det endelige svaret formateres i henhold til plattformens spesifikasjoner—inline-siteringer, fotnoter, kildepaneler eller hover-over-lenker—og leveres til brukeren med metadata om kildeautoritet og relevans.
Siteringsplassering varierer dramatisk mellom AI-plattformer, og gir ulike synlighetsmuligheter for innholdsskapere. Slik håndterer de store plattformene siteringer:
ChatGPT: Siteringer vises i et eget “Kilder”-panel under svaret, og brukerne må aktivt klikke for å se dem. Kildene er vanligvis begrenset til 3-5 lenker, og prioriterer domener med høy autoritet.
Perplexity: Siteringer er innebygd overalt i svaret med hevet tall og en omfattende kildeliste nederst. Hver påstand er sporbar, noe som gjør dette til den mest sitat-transparente plattformen.
Google Gemini: Siteringer vises som inline-lenker i selve svaret, med en “Kilder”-seksjon som lister alle refererte materialer. Integrasjon med Googles kunnskapsgraf påvirker hvilke kilder som velges.
Claude: Siteringer presenteres i en fotnotestil med klammehenvisninger, slik at brukeren kan se kildene uten å forlate svaret. Claude vektlegger kilde-mangfold og troverdighet.
DeepSeek: Siteringer vises som inline-hyperkoblinger med minimal visuell forskjell, og reflekterer en mer integrert tilnærming der kildene sømløst veves inn i teksten.
Disse forskjellene betyr at en kilde sitert av Perplexity kan få direkte trafikk, mens samme kilde sitert av ChatGPT kan forbli usynlig med mindre brukeren spesifikt åpner Kilder-panelet. Plattformspesifikke siteringsmønstre påvirker direkte trafikk og synlighet.

Hentingssystemet er der beslutninger om siteringsplassering starter, lenge før svaret genereres. Semantisk søk konverterer både brukerens forespørsel og indekserte dokumenter til vektorrepresentasjoner—numeriske representasjoner som fanger mening snarere enn nøkkelord. Systemet beregner deretter likhetspoeng mellom forespørsels-embedding og dokument-embedding, og identifiserer hvilke kilder som semantisk ligner mest på brukerens hensikt.
Rangeringsalgoritmer omorganiserer så kandidatene basert på flere signaler: relevanspoeng, domeneautoritet, innholdsaktualitet, brukerengasjement og kvalitet på strukturert data. Kildene som rangeres høyest i denne hentingsfasen er mer tilbøyelige til å bli inkludert i kontekstvinduet gitt til genereringsmodellen, og dermed mer sannsynlig å bli sitert. Derfor vil en godt optimalisert, semantisk tydelig artikkel fra et autoritativt domene hentes og siteres oftere enn en dårlig strukturert artikkel fra et nyere domene, selv om begge inneholder korrekt informasjon. Hentingsstadiet forhåndsbestemmer i praksis siteringsutvalget før genereringen starter.
Innholdsstruktur er ikke bare en UX-hensyn—den påvirker direkte om AI-systemer kan trekke ut, forstå og sitere innholdet ditt. AI-modeller er avhengige av formateringssignaler for å identifisere informasjonsgrenser og relasjoner. Her er struktur-elementene som maksimerer siteringssannsynlighet:
Svar-først-struktur: Innled med direkte svar på vanlige spørsmål, slik at AI-systemer raskt kan identifisere og trekke ut relevant informasjon uten å måtte tolke introduksjonsmateriale.
Tydelige overskrifter: Bruk beskrivende H2- og H3-overskrifter som eksplisitt sier hva hvert avsnitt handler om, slik at AI-systemer kan forstå innholdsorganisering og trekke ut relevante biter til spesifikke forespørsler.
Optimal avsnittslengde: Hold avsnittene på 3-5 setninger, slik at AI-systemer lettere kan identifisere distinkte påstander og tilskrive dem til spesifikke kilder uten tvetydighet.
Lister og tabeller: Strukturert data i punktlister og tabeller er lettere å tolke og sitere enn prosa, siden AI-systemer tydelig kan identifisere individuelle påstander og deres grenser.
Entitet-tydelighet: Navngi personer, organisasjoner, produkter og konsepter eksplisitt i stedet for å bruke pronomen, slik at AI-systemer forstår nøyaktig hva hver påstand refererer til og kan sitere presist.
Schema markup: Implementer strukturert data (Schema.org) for å gi eksplisitt metadata om innholdstype, forfatter, publiseringsdato og påstander, og gi AI-systemer flere signaler for evaluering og sitering.
Innhold som følger disse strukturelle prinsippene siteres 2-3 ganger oftere enn dårlig strukturert innhold, uavhengig av kvalitet, fordi det rett og slett er lettere for AI-systemer å trekke ut og tilskrive.
Når kilder er hentet og satt sammen i kontekstvinduet, evaluerer modellen hver kilde gjennom flere troverdighets-linser før den avgjør om den skal siteres. Kildetroverdighet vurderes gjennom domeneautoritet (målt på lenkeprofiler, domenealder og merkevarekjennskap), forfatterekspertise (oppdaget gjennom bylines, forfatterbioer og kompetansesignaler), og tematisk relevans (om kildens hovedfokus samsvarer med forespørselen).
Relevanspoeng måler hvor direkte kilden besvarer den spesifikke forespørselen, hvor eksakte svar scorer høyere enn perifere opplysninger. Aktualitetsfaktorer påvirker om nylige kilder foretrekkes over eldre—kritisk for nyheter, forskning og raskt utviklende temaer. Autoritetssignaler inkluderer siteringer fra andre autoritative kilder, omtaler i akademiske databaser og tilstedeværelse i kunnskapsgrafer. Metadata-påvirkning kommer fra tittel-tag, metabeskrivelse og strukturert data som eksplisitt kommuniserer innholdets formål og troverdighet. Til slutt gir strukturert data (Schema.org markup) eksplisitte troverdighets-signaler modellen kan tolke direkte, som forfatteropplysninger, publiseringsdato, vurderinger og faktasjekk-status. Kilder med omfattende schema markup siteres mer pålitelig fordi modellen har eksplisitt, maskinlesbar bekreftelse på påstandene.
AI-plattformer bruker ulike siteringsstiler som påvirker hvor synlige siteringene dine er for brukerne. Her er de vanligste mønstrene:
Inline-siteringer (Perplexity-stil):
“Ifølge fersk forskning hoppet AI-adopsjonen blant forskere til 84 % i 2025[1], med 62 % som spesifikt bruker AI-verktøy til forskningsoppgaver[2].”
Siteringer på slutten av avsnitt (Claude-stil):
“AI-adopsjonen blant forskere hoppet til 84 % i 2025, med 62 % som spesifikt bruker AI-verktøy til forskningsoppgaver. [Kilde: Wiley Research Report, 2025]”
Fotnotestil-siteringer (Akademisk tilnærming):
“AI-adopsjonen blant forskere hoppet til 84 % i 2025¹, med 62 % som spesifikt bruker AI-verktøy til forskningsoppgaver².”
Kildelister (ChatGPT-stil):
Svartekst uten inline-siteringer, etterfulgt av en separat “Kilder”-seksjon med 3-5 lenker.
Hover-over-siteringer (Fremvoksende mønster):
Understreket tekst som viser kildeinformasjon når brukeren holder musen over, og minimerer visuell støy samtidig som sporbarhet opprettholdes.
Hver stil skaper ulike brukerhandlinger: inline-siteringer gir umiddelbare klikk, kildelister krever bevisst handling fra brukeren, og hover-over-siteringer balanserer synlighet med estetikk. Siteringssannsynligheten for innholdet ditt varierer mellom plattformer, så flerplattform-overvåkning er viktig.
Å forstå mekanikkene bak siteringsplassering gir direkte målbare forretningsresultater. Trafikkimplikasjoner er umiddelbare: kilder sitert inline av Perplexity får 3-5 ganger mer henvisningstrafikk enn kilder som kun vises i ChatGPTs Kilder-panel, fordi brukerne oftere klikker på inline-siteringer underveis i lesingen. Forholdet mellom synlighet og klikkrate er ikke lineært—det å bli sitert er kun verdifullt hvis brukerne faktisk klikker på siteringen, noe som avhenger av plassering, plattform og kontekst.
Merkevareautoritet forsterkes over tid: kilder som konsekvent siteres av flere AI-plattformer bygger sterkere autoritetssignaler, noe som forbedrer rangering i tradisjonelt søk og øker sannsynligheten for fremtidige AI-siteringer. Dette skaper en positiv spiral der sitert innhold blir mer autoritativt og tiltrekker flere siteringer. Konkurransefortrinn oppstår for merkevarer som optimaliserer for AI-sitering før konkurrentene—tidlige brukere av schema og innholdsstruktur-optimalisering får i dag uforholdsmessig stor andel siteringer. SEO-implikasjoner strekker seg utover AI: innhold optimalisert for AI-sitering presterer typisk bedre i tradisjonelt søk også, fordi de samme struktur- og autoritetssignalene gagner begge systemer. AmICited-verdi blir tydelig: i et AI-drevet oppdagelseslandskap er det å ikke vite om du blir sitert det samme som å ikke vite søkerangeringene dine—det er et kritisk blindområde i synlighetsstrategien.
Å optimalisere for AI-siteringer krever spesifikke, handlingsrettede endringer i hvordan du lager og strukturerer innhold. Her er de mest effektive tiltakene:
Strukturer for utvinnbarhet: Bruk tydelige overskrifter, korte avsnitt og lister for å gjøre innholdet lett for AI å tolke og trekke ut spesifikke påstander uten tvetydighet.
Bruk klare, siterbare fakta: Innled med konkrete statistikker, datoer og navngitte enheter fremfor vage generaliseringer. AI siterer konkrete påstander oftere enn abstrakte utsagn.
Implementer schema markup: Legg til Schema.org-markup for Article, NewsArticle eller ScholarlyArticle, inkludert forfatter, publiseringsdato og påstandsspesifikke metadata som AI-systemer kan tolke direkte.
Oppretthold entitetskonsistens: Bruk samme navn på personer, organisasjoner og konsepter gjennom hele innholdet, og unngå pronomen og forkortelser som skaper tvetydighet for AI.
Siter dine egne kilder: Når du siterer andre kilder i innholdet ditt, signaliserer du til AI-systemer at innholdet er godt undersøkt og troverdig, noe som øker din egen siteringssannsynlighet.
Test med AI-verktøy: Søk jevnlig på dine måltemaer i ChatGPT, Perplexity, Gemini og Claude for å se om innholdet ditt blir sitert og hvordan det presenteres.
Overvåk ytelse: Spor hvilke deler av innholdet ditt som siteres, på hvilke plattformer og i hvilken kontekst, og bruk disse dataene til å forbedre optimaliseringsstrategien.
Innholdsskapere som gjennomfører disse tiltakene ser siteringsraten øke med 40–60 % innen 3–6 måneder, med tilsvarende økning i henvisningstrafikk og merkevareautoritet.
Siteringsovervåking er ikke lenger valgfritt—det er essensiell infrastruktur for å forstå din synlighet i det AI-drevne oppdagelseslandskapet. Hvorfor overvåking er viktig er enkelt: du kan ikke optimalisere det du ikke måler, og siteringsmønstre endrer seg i takt med AI-systemenes utvikling og nye plattformer. Hvilke måleparametere du bør følge inkluderer siteringsfrekvens (hvor ofte du siteres), siteringsplassering (inline vs. kildeliste), plattformfordeling (hvilke plattformer siterer deg mest), forespørselskontekst (hvilke temaer utløser dine siteringer) og trafikkattribusjon (hvor mye henvisningstrafikk kommer fra AI-siteringer).
Å identifisere muligheter krever analyse av siteringshull: temaer der konkurrenter siteres, men ikke du, plattformer der du er underrepresentert, og innholdstyper som presterer dårlig. Denne analysen avdekker konkrete optimaliseringsmål—kanskje dine veiledninger ikke siteres fordi de mangler schema markup, eller ditt forskningsinnhold ikke vises i Perplexity fordi det ikke er strukturert for inline-uttrekk.
AmICited løser overvåkingsutfordringen ved å spore dine siteringer på tvers av ChatGPT, Perplexity, Gemini, Claude og andre store AI-plattformer i sanntid. I stedet for å manuelt søke på temaene dine gjentatte ganger, overvåker AmICited automatisk siteringsmønstre, varsler deg om nye siteringer og gir konkurransebenchmarkingsdata som viser hvordan din siteringsytelse sammenlignes med konkurrentene. For innholdsskapere, markedsførere og SEO-fagfolk forvandler AmICited siteringsovervåking fra en manuell, tidkrevende prosess til et automatisert system som gir handlingsrettede innsikter. I et AI-drevet oppdagelseslandskap er det å ha oversikt over hvor innholdet ditt siteres like essensielt som å kjenne søkerangeringene dine—og AmICited gjør denne synligheten mulig i skala.
Modell-native svar kommer fra mønstre lært under trening, mens RAG henter inn sanntidsdata før det genererer svar. RAG gir vanligvis bedre siteringer fordi det forankrer responsene i spesifikke kilder, noe som gjør det mer transparent og sporbar for brukere og innholdsskapere.
Ulike plattformer bruker ulike arkitekturer. Perplexity og Gemini prioriterer RAG med siteringer, mens ChatGPT standardiserer modell-native generering med mindre nettlesing er aktivert. Valget reflekterer hver plattforms designfilosofi og tilnærming til åpenhet.
Tydelig, godt strukturert innhold med direkte svar, riktige overskrifter og schema markup er lettere for AI-systemer å trekke ut. Innhold som innleder med svar og bruker lister og tabeller, blir oftere sitert fordi det er lettere for AI å tolke og tilskrive.
Schema markup hjelper AI-systemer å forstå innholdsstruktur og enhetsforhold, noe som gjør det enklere å korrekt tilskrive og sitere innholdet ditt. Riktig schema-implementering øker sannsynligheten for sitering og hjelper AI-systemer å verifisere innholdets troverdighet.
Ja. Fokuser på svar-først-struktur, klar formatering, faktuell nøyaktighet, troverdige kilder og riktig schema-implementering. Overvåk siteringene dine og gjør endringer basert på resultatdata for kontinuerlig å forbedre AI-synligheten.
Verktøy som AmICited overvåker dine merkevareomtaler på tvers av ChatGPT, Perplexity, Google AI Overviews og andre plattformer, og viser nøyaktig hvor og hvordan du blir sitert i AI-responser. Dette gir handlingsrettede innsikter for optimalisering.
Selv om AI-siteringer ikke direkte påvirker Googles rangeringer, øker de merkevaresynlighet og autoritetssignaler. Å bli sitert av AI kan generere trafikk og styrke din totale online tilstedeværelse, noe som gir indirekte SEO-fordeler.
De utfyller hverandre. Tradisjonell SEO fokuserer på rangering i søkeresultatene, mens AI-siteringsoptimalisering handler om å vises i AI-genererte svar. Begge er viktige for omfattende synlighet i dagens oppdagelseslandskap.
Forstå nøyaktig hvor merkevaren din vises i AI-genererte svar. Spor siteringer på tvers av ChatGPT, Perplexity, Google AI Overviews og flere med AmICited.
Lær hvordan AI-modeller som ChatGPT, Perplexity og Gemini velger hvilke kilder de skal sitere. Forstå siteringsmekanismer, rangeringsfaktorer og optimaliserings...
Lær hvordan sitasjonsposisjon fungerer på tvers av ChatGPT, Perplexity, Google AI Overviews og andre AI-systemer. Forstå strategier for siteringsplassering og h...
Lær hvordan akademiske siteringer påvirker din synlighet i AI-genererte svar. Oppdag hvorfor siteringer er viktigere enn trafikk for AI-søkemotorer og hvordan d...
Informasjonskapselsamtykke
Vi bruker informasjonskapsler for å forbedre din surfeopplevelse og analysere vår trafikk. See our privacy policy.