
Slik sporer du konkurrenters AI-omtale på ChatGPT, Perplexity & AI-søk
Lær hvordan du sporer omtale av konkurrenter i AI-søkemotorer. Overvåk ChatGPT, Perplexity, Claude og Google AI-synlighet med andel av stemme-målinger.
11 min lesing
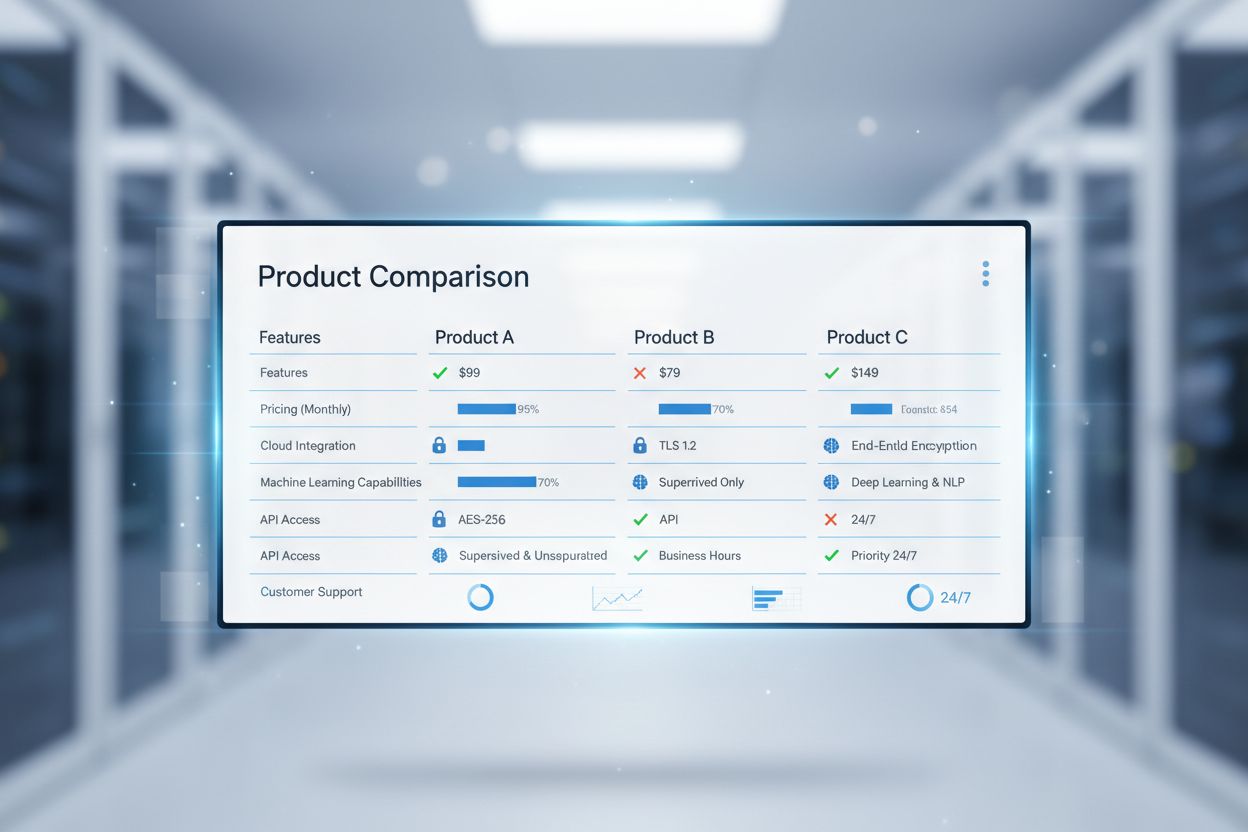
Lær hvordan KI-systemer rangerer konkurrent-sammenligninger og hvorfor merkevaren din kan mangle i ‘vs’-spørringer. Oppdag strategier for å dominere KI-sammenligningssynlighet.
KI-systemer håndterer nå omtrent 80 % av forbrukersøk etter produktanbefalinger, noe som fundamentalt endrer hvordan kjøpsbeslutninger tas. Når brukere stiller “X vs Y”-spørsmål til ChatGPT, Gemini eller Perplexity, deltar de i øyeblikk med høy kjøpsintensjon som direkte påvirker kjøpsatferd—men disse interaksjonene fungerer annerledes enn tradisjonelle søkemotorspørringer. I motsetning til Google, hvor nøkkelordstetthet og lenkeautoritet dominerer, syntetiserer KI-systemer informasjon fra flere kilder og lager fortellende sammenligninger som enten kan løfte eller begrave merkevaren din. For SaaS- og B2B-selskaper representerer dette både en kritisk synlighetsutfordring og en enestående mulighet: merkevarens tilstedeværelse i disse KI-genererte sammenligningene avgjør direkte om potensielle kunder i det hele tatt vurderer deg som et alternativ. Innsatsen er høyere enn noen gang fordi KI-sammenligningsresultater oppleves som autoritative og helhetlige, og gjør dem til den nye slagmarken for markedsandeler.
Når du ber et LLM om å sammenligne to produkter, henter ikke systemet bare frem eksisterende sammenligningssider—det tolker den semantiske hensikten bak spørringen, identifiserer relevante entiteter og kartlegger relasjoner mellom dem for å konstruere et nytt svar. LLM-er viser sterk preferanse for strukturert data og tydelige posisjoneringsutsagn fremfor fortellende innhold, noe som betyr at en godt formatert sammenligningstabell med eksplisitte funksjonsutrop vil vektlegges mer enn et 2 000-ords blogginnlegg begravd i prosa. Systemet utfører entitetsgjenkjenning og relasjonskartlegging for å forstå ikke bare hvilke produkter som finnes, men hvordan de forholder seg til hverandre på dimensjoner som pris, brukstilfeller og målgrupper. Siteringsmønstre er svært viktig: LLM-er sporer hvilke kilder de henter informasjon fra og vektlegger kilder med høyere troverdighet og konsistens mer. Dette er fundamentalt forskjellig fra hvordan mennesker leser sammenligningssider—mens en person skummer gjennom hele siden, trekker et KI-system ut spesifikke påstander, validerer dem mot andre kilder og flagger inkonsistenser. Tydelig posisjonering og differensiering betyr mye mer enn nøkkelordstetthet, fordi KI ser etter semantisk klarhet og verifiserbare påstander, ikke nøkkelordstreff.
Bak hver KI-sammenligning ligger det et rangeringsalgoritme som bestemmer hvilket produkt som posisjoneres som “best” for spesifikke brukstilfeller—og å forstå disse systemene er avgjørende for strategisk posisjonering. Forskere har identifisert fire hovedtilnærminger som LLM-er og sammenligningsplattformer bruker: Elo-rangeringssystemet (lånt fra sjakk), Bradley-Terry-modellen (utviklet for kontrollerte datasett), Glicko-systemet (en videreutvikling av Elo for store, ujevne datasett), og Markov Chain-tilnærminger (for balanserte, sannsynlighetsbaserte sammenligninger). Hvert system har distinkte styrker og svakheter innen tre kritiske dimensjoner: transitivitet (om A>B og B>C pålitelig betyr A>C), prediksjonspresisjon og hyperparameterfølsomhet.
| Algoritme | Best for | Transitivitet | Prediksjonspresisjon | Hyperparameterfølsomhet |
|---|---|---|---|---|
| Elo | Store, ujevne datasett | Moderat | Høy | Svært høy |
| Bradley-Terry | Små, kontrollerte datasett | Utmerket | Høy | Ingen |
| Glicko | Store, ujevne datasett | God | Høy | Moderat |
| Markov Chain | Balanserte datasett | God | Moderat | Høy |
Elo-systemet er svært godt egnet for å håndtere store, ubalanserte datasett (som millioner av bruker-sammenligninger), men er ekstremt følsomt for innstillinger og kan produsere ikke-transitive resultater. Bradley-Terry gir perfekt transitivitet og ingen hyperparameter-kompleksitet, og er ideell for kontrollerte produktsammenligninger med et fast antall konkurrenter og konsistente evalueringskriterier. Glicko balanserer styrkene fra begge tilnærminger, og gir god transitivitet og prediksjonspresisjon med moderat følsomhet for innstillinger. Markov Chain-metoder fungerer best når du har balansert, direkte sammenligningsdata, og kan akseptere moderat prediksjonspresisjon mot sannsynlighetsinnsikt. Å forstå hvilken algoritme et KI-system bruker—eller hvilken konkurrentene dine optimaliserer for—avdekker strategiske muligheter for posisjonering.
De fleste SaaS-selskaper opplever en urovekkende realitet: merkevaren din blir nevnt langt sjeldnere i KI-sammenligninger enn i tradisjonelle søkeresultater, og når den vises, er den ofte posisjonert som et sekundært alternativ. Dette synlighetshullet skyldes flere sammenhengende faktorer. Siteringsmønstre og kildeautoritet er avgjørende—hvis merkevaren din hovedsakelig vises på egne nettsider og noen få anmeldelsessider, mens konkurrentene er nevnt i bransjepublikasjoner, analytikerrapporter og tredjeparts-sammenligninger, vil KI-systemet vektlegge konkurrentene mer. Entitetsklarhet og konsekvent navngiving på alle digitale flater (nettsted, dokumentasjon, sosiale profiler, anmeldelsessider) avgjør om KI gjenkjenner deg som en distinkt enhet verdt å sammenligne. Mange selskaper unnlater å implementere strukturert datamerking som eksplisitt kommuniserer funksjoner, priser og posisjonering til KI-systemene, og tvinger LLM til å utlede dette fra ustrukturert innhold. Tallene er nedslående: forskning viser at KI-genererte søkeresultater gir 91 % færre klikk enn tradisjonelle Google-søk for de samme spørringene, noe som gjør synlighet i KI-sammenligninger enda mer avgjørende enn tradisjonell SEO. Konkurrentene dine bygger sannsynligvis allerede en sterkere KI-tilstedeværelse gjennom strategisk innholdsplassering, implementering av strukturert data og bevisst posisjonering i tredjeparts sammenligningskontekster—og for hver dag du venter, øker gapet.
For å vinne i KI-sammenligningsspørringer må sammenligningssidene dine bygges spesielt for hvordan LLM-er leser og syntetiserer informasjon. Her er de viktigste optimaliseringspraksisene:
Synlighet uten måling er bare håp, derfor er systematisk overvåkning av din KI-sammenligningstilstedeværelse uunnværlig. Start med å etablere en baseline på de store KI-plattformene—ChatGPT, Google Gemini, Perplexity og Claude—ved å kjøre et standardisert prompt-oppsett som dekker kategorilister (“topp 5 prosjektstyringsverktøy”), hode-til-hode-sammenligninger (“Asana vs Monday.com”), begrensningsbaserte spørringer (“beste CRM for ideelle organisasjoner”) og migreringsscenarier (“bytte fra Salesforce til…”). For hvert resultat, følg fire nøkkelparametre: tilstedeværelse (blir du nevnt?), posisjonering (først, i midten eller sist?), nøyaktighet (er påstandene om produktet ditt korrekte?) og bevisbruk (hvilke kilder siterer KI når de beskriver deg?). Etabler en baseline-score for hver spørring og plattform, og følg utviklingen kvartalsvis for å se om synligheten din bedrer seg, står stille eller svekkes sammenlignet med konkurrentene. Verktøy som Ahrefs Brand Radar, Semrush Brand Monitoring og nye KI-spesifikke plattformer som AmICited.com gir automatisert sporing på tvers av flere KI-systemer, og eliminerer behovet for manuell testing. Målet er ikke perfeksjon—det er systematisk synlighet og evnen til å identifisere hull før de blir konkurranseulemper.
KI Share of Voice representerer merkevarens andel av totale omtaler og positiv posisjonering i KI-sammenligningsresultater innenfor din kategori—og blir den viktigste konkurransemålingen. I motsetning til tradisjonell Share of Voice, som måler nøkkelordsomtaler i søkeresultater, fanger KI Share of Voice hvor ofte merkevaren din vises i KI-genererte sammenligninger og hvor gunstig den er posisjonert sammenlignet med konkurrenter. Å identifisere synlighetshull krever konkurranseanalyse langs tre dimensjoner: temahull (hvilke sammenligningsspørringer nevner konkurrenter, men ikke deg?), formathull (vises konkurrenter i tabeller, casestudier eller ekspertoppsummeringer som du mangler?), og aktualitetshull (er konkurrentenes omtaler ferske mens dine er utdaterte?). Siteringsanalyse avslører hvilke kilder KI stoler mest på—hvis konkurrentene konsekvent siteres fra bransjepublikasjoner, mens du bare siteres fra dine egne nettsider, har du et kritisk kildehull. Å bygge bærekraftig KI-synlighet krever at man går forbi raske gevinster som å optimalisere enkeltstående sammenligningssider; i stedet bør du utvikle en innholdsstrategi som systematisk bygger tilstedeværelse på tredjepartskilder, analytikerrapporter og bransjepublikasjoner der KI-systemer naturlig finner og siterer informasjon. Selskapene som vinner denne kampen, er ikke nødvendigvis de med best produkt—men de med den mest strategiske, synlige tilstedeværelsen i kildene KI-systemene stoler på.
Konkurrentenes posisjonering i KI-sammenligninger gir strategisk innsikt som tradisjonell konkurranseanalyse ofte overser. Ved systematisk å overvåke hvordan KI-systemer beskriver konkurrentenes styrker, svakheter og posisjonering, kan du identifisere markedsmuligheter og hull som konkurrentene selv kanskje ikke har optimalisert for. Omvendt-ingeniør konkurrentenes strategier ved å analysere hvilke kilder de oftest vises i, hvilke påstander de fremhever og hvilke brukstilfeller de prioriterer—dette avslører innholdsstrategien og markedsfokus. Bruk verktøy som Ahrefs Brand Radar for å spore hvilke domener som nevner konkurrentene dine oftest, og analyser om de samme domenene nevner deg; dette gapet er ubenyttede synlighetsmuligheter. Sammenligningsdata avslører også posisjoneringsmuligheter: hvis konkurrenter konsekvent hevder “best for enterprise”, men du ser kundevitnesbyrd og brukstilfeller som viser at du er like sterk der, har du et budskapsgap verdt å adressere. Den mest sofistikerte konkurranseinnsikten kommer fra å analysere mønstre på tvers av flere KI-systemer—hvis en konkurrent dominerer i ChatGPT-sammenligninger, men knapt vises i Perplexity-resultater, sier det noe om innholdsdistribusjon og kildeautoritet. Ved å behandle KI-sammenligningsdata som en strategisk kilde til innsikt, ikke bare en synlighetsmåling, gjør du reaktiv overvåkning om til et proaktivt konkurransefortrinn.
KI-systemer oppdaterer sine sammenligningsrangeringer kontinuerlig ettersom ny informasjon indekseres og brukerinteraksjoner behandles. Hyppigheten varierer imidlertid mellom plattformer—ChatGPT oppdaterer treningsdataene sine periodisk, mens Perplexity og andre sanntidssystemer oppdaterer resultatene ved hver spørring. For merkevaren din betyr dette at endringer i synlighet kan skje innen få dager etter publisering av nytt sammenligningsinnhold eller ved å få siteringer fra autoritative kilder.
Tradisjonelle søkerangeringer prioriterer nøkkelordstetthet, lenker og domeneautoritet. KI-sammenligningssynlighet, derimot, vektlegger klarhet i strukturert data, entitetsgjenkjenning, troverdighet i siteringer og posisjoneringskonsistens på tvers av flere kilder. En side kan rangere som #1 i Google, men knapt vises i KI-sammenligninger hvis den mangler klar struktur og verifiserbare påstander.
Ja, absolutt. Ved å implementere strukturert datamerking (Schema.org), opprettholde konsekvent navngiving på alle flater, publisere tydelige posisjoneringsutsagn og oppnå siteringer fra autoritative tredjepartskilder, påvirker du direkte hvordan KI-systemer forstår og beskriver produktet ditt. Nøkkelen er å gjøre informasjonen din maskinlesbar og troverdig.
Kjør et standardisert prompt-oppsett på tvers av de store KI-plattformene (ChatGPT, Gemini, Perplexity, Claude) med sammenligningsspørsmål relevante for din kategori. Følg med på om du blir nevnt, hvordan du blir posisjonert, og hvilke kilder KI siterer. Verktøy som AmICited.com automatiserer denne overvåkningen, og gir kvartalsvise synlighetsrapporter og konkurransebenchmarking.
De raskeste gevinstene kommer fra: (1) implementere strukturert datamerking på eksisterende sammenligningssider, (2) sikre konsekvent navngiving og posisjonering på alle digitale flater, (3) oppnå siteringer fra bransjepublikasjoner og analytikerrapporter, og (4) lage sammenligningsinnhold spesielt optimalisert for KI-lesbarhet. De fleste selskaper ser målbare forbedringer innen 4-6 uker.
Strukturert data (JSON-LD schema markup) gjør informasjonen din maskinlesbar, og eliminerer KIs behov for å utlede fakta fra ustrukturert prosa. Dette forbedrer nøyaktighet og siteringsfrekvens dramatisk. Produkter med korrekt schema markup vises i KI-sammenligninger 2–3 ganger oftere enn de uten, og beskrives mer presist.
Selv om kjerneprinsippene for optimalisering er like, har hver plattform særegne egenskaper. ChatGPT verdsetter omfattende, godt dokumentert innhold. Perplexity prioriterer sanntidsinformasjon med siteringer. Google Gemini vektlegger strukturert data og entitetsklarhet. Fokuser på universelle beste praksiser: klar struktur, troverdige siteringer og konsekvent posisjonering, fremfor plattformspesifikk optimalisering.
De fire viktigste parameterne er: (1) Tilstedeværelse—blir du nevnt i relevante sammenligningsspørringer? (2) Posisjonering—vises du først, i midten, eller sist? (3) Nøyaktighet—er påstandene om produktet ditt korrekte? (4) Bevisbruk—hvilke kilder siterer KI når de beskriver deg? Følg opp dette kvartalsvis for å avdekke trender og konkurransegap.
Følg med på hvordan KI-systemer nevner merkevaren din i konkurrent-sammenligninger på tvers av ChatGPT, Gemini, Perplexity og flere. Få sanntidsinnsikt i din synlighet i KI-søk.
Lær hvordan du sporer omtale av konkurrenter i AI-søkemotorer. Overvåk ChatGPT, Perplexity, Claude og Google AI-synlighet med andel av stemme-målinger.
Lær hvordan du overvåker når konkurrenter dukker opp i ChatGPT, Perplexity, Claude og andre AI-søkemotorer. Oppdag verktøy og strategier for å spore AI-synlighe...
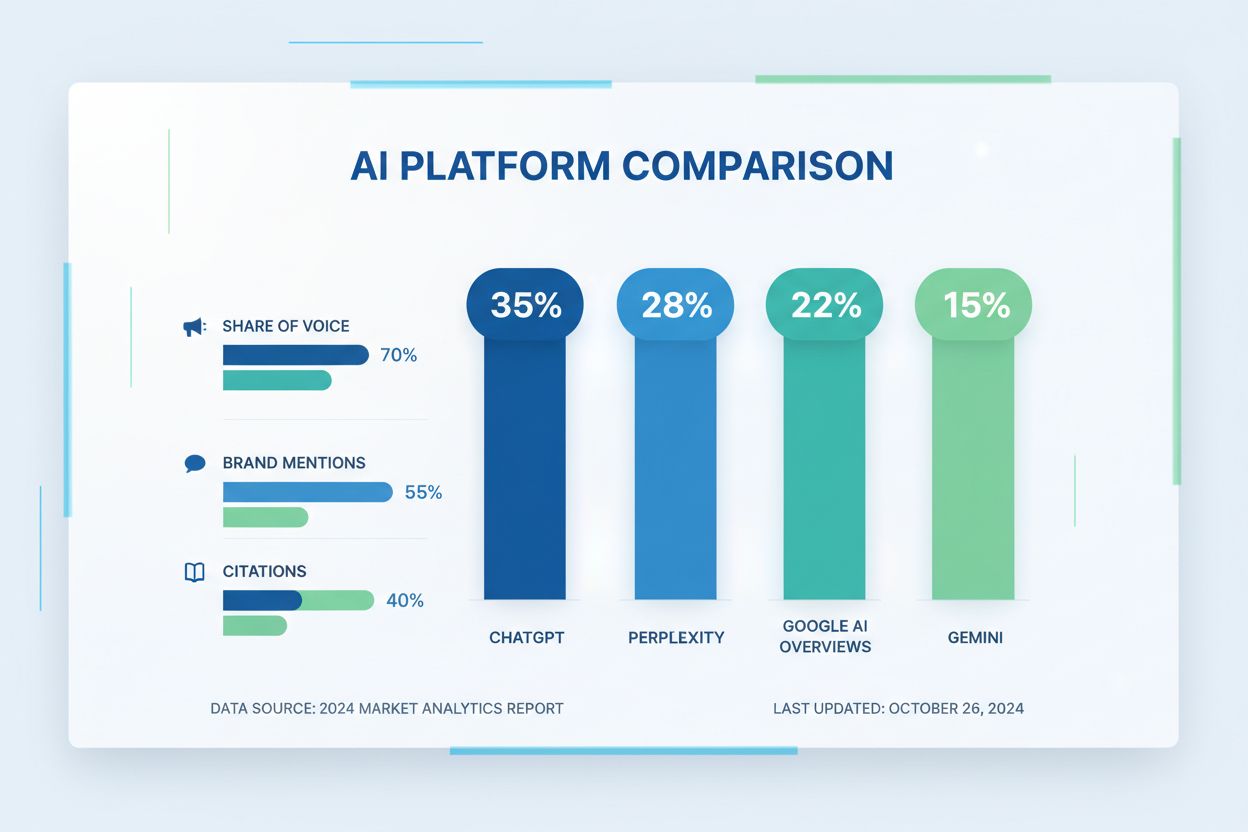
Lær hvordan du analyserer konkurrenters AI-synlighet, identifiserer share of voice-gap og optimaliserer din merkevaretilstedeværelse på tvers av ChatGPT, Perple...
Informasjonskapselsamtykke
Vi bruker informasjonskapsler for å forbedre din surfeopplevelse og analysere vår trafikk. See our privacy policy.