
AI Crawler Referansekort: Alle Bots på et Blikk
Fullstendig referanseguide for AI-crawlere og roboter. Identifiser GPTBot, ClaudeBot, Google-Extended og 20+ andre AI-crawlere med brukeragenter, crawl-frekvens...
14 min lesing

Lær hvordan du blokkerer eller tillater AI-crawlere som GPTBot og ClaudeBot ved hjelp av robots.txt, blokkering på servernivå og avanserte beskyttelsesmetoder. Komplett teknisk guide med eksempler.
Det digitale landskapet har fundamentalt endret seg fra tradisjonell søkemotoroptimalisering til å håndtere en helt ny kategori automatiserte besøkende: AI-crawlere. I motsetning til konvensjonelle søkeboter som sender trafikk tilbake til nettstedet ditt via søkeresultater, konsumerer AI-treningscrawlere innholdet ditt for å bygge store språkmodeller uten nødvendigvis å gi henvisningstrafikk tilbake. Dette skillet har store konsekvenser for utgivere, innholdsskapere og virksomheter som er avhengige av netttrafikk som inntektskilde. Innsatsen er høy—kontroll over hvilke AI-systemer som får tilgang til innholdet ditt påvirker direkte ditt konkurransefortrinn, datavern og bunnlinje.
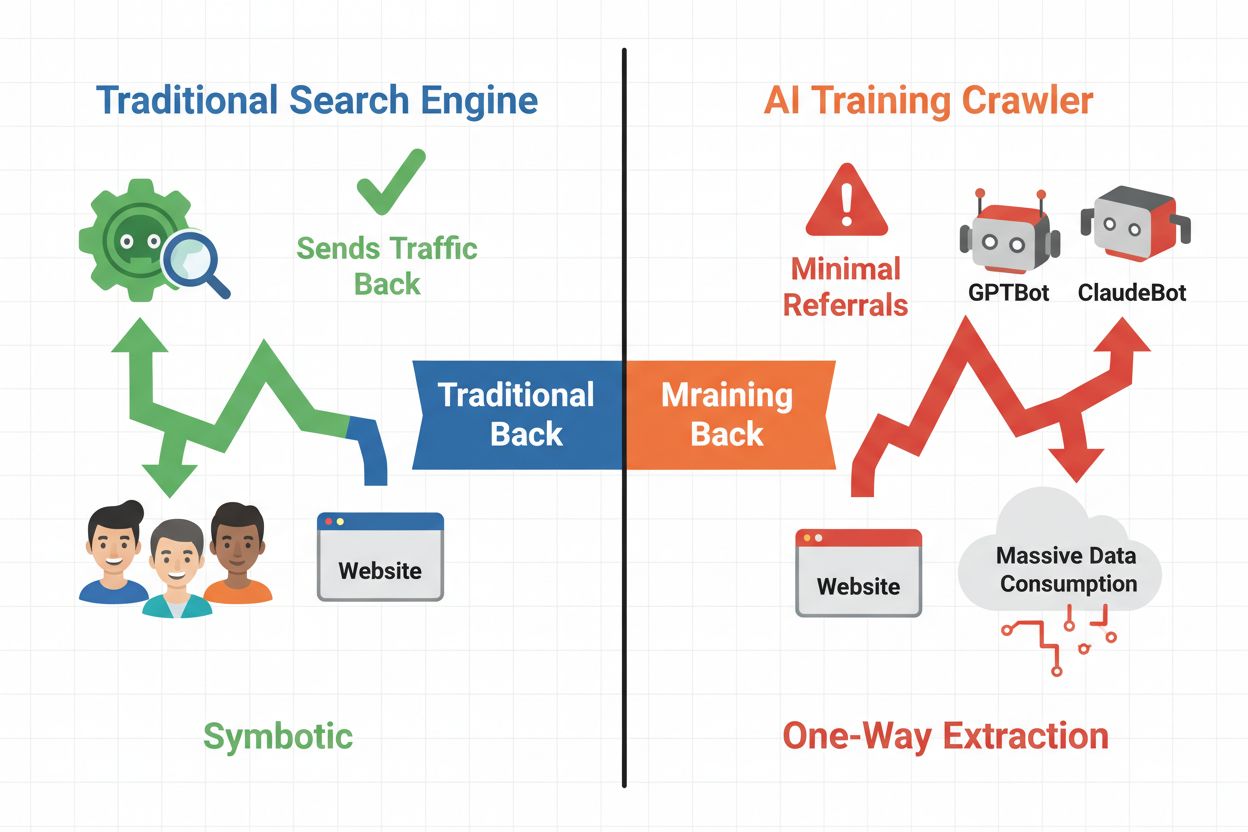
AI-crawlere deles inn i tre distinkte kategorier, hver med ulike formål og trafikkpåvirkning. Treningscrawlere brukes av AI-selskaper til å bygge og forbedre språkmodellene sine, og opererer vanligvis i stor skala med minimal returtrafikk. Søke- og siteringscrawlere indekserer innhold for AI-drevne søkemotorer og siteringssystemer, og gir ofte noe henvisningstrafikk tilbake til utgivere. Brukerutløste crawlere henter innhold på forespørsel når brukere samhandler med AI-applikasjoner, og utgjør et mindre, men voksende segment. Å forstå disse kategoriene hjelper deg med å ta informerte beslutninger om hvilke crawlere du skal tillate eller blokkere basert på forretningsmodellen din.
| Crawler Type | Purpose | Traffic Impact | Eksempler |
|---|---|---|---|
| Training | Bygge/forbedre LLM-er | Minimal til ingen | GPTBot, ClaudeBot, Bytespider |
| Search/Citation | Indeksering for AI-søk & siteringer | Moderat henvisningstrafikk | Googlebot-Extended, Perplexity |
| User-triggered | Hente på forespørsel for brukere | Lav, men konsistent | ChatGPT-plugins, Claude browsing |
AI-crawler-økosystemet inkluderer crawlere fra verdens største teknologiselskaper, hver med forskjellige brukeragenter og formål. OpenAIs GPTBot (user agent: GPTBot/1.0) crawler for å trene ChatGPT og andre modeller, mens Anthropics ClaudeBot (user agent: Claude-Web/1.0) har lignende formål for Claude. Googles Googlebot-Extended (user agent: Mozilla/5.0 ... Googlebot-Extended) indekserer innhold for AI Overviews og Bard, mens Metas Meta-ExternalFetcher crawler for deres AI-initiativ. Andre sentrale aktører inkluderer:
Hver crawler opererer i ulik skala og respekterer blokkeringsdirektiver i varierende grad.
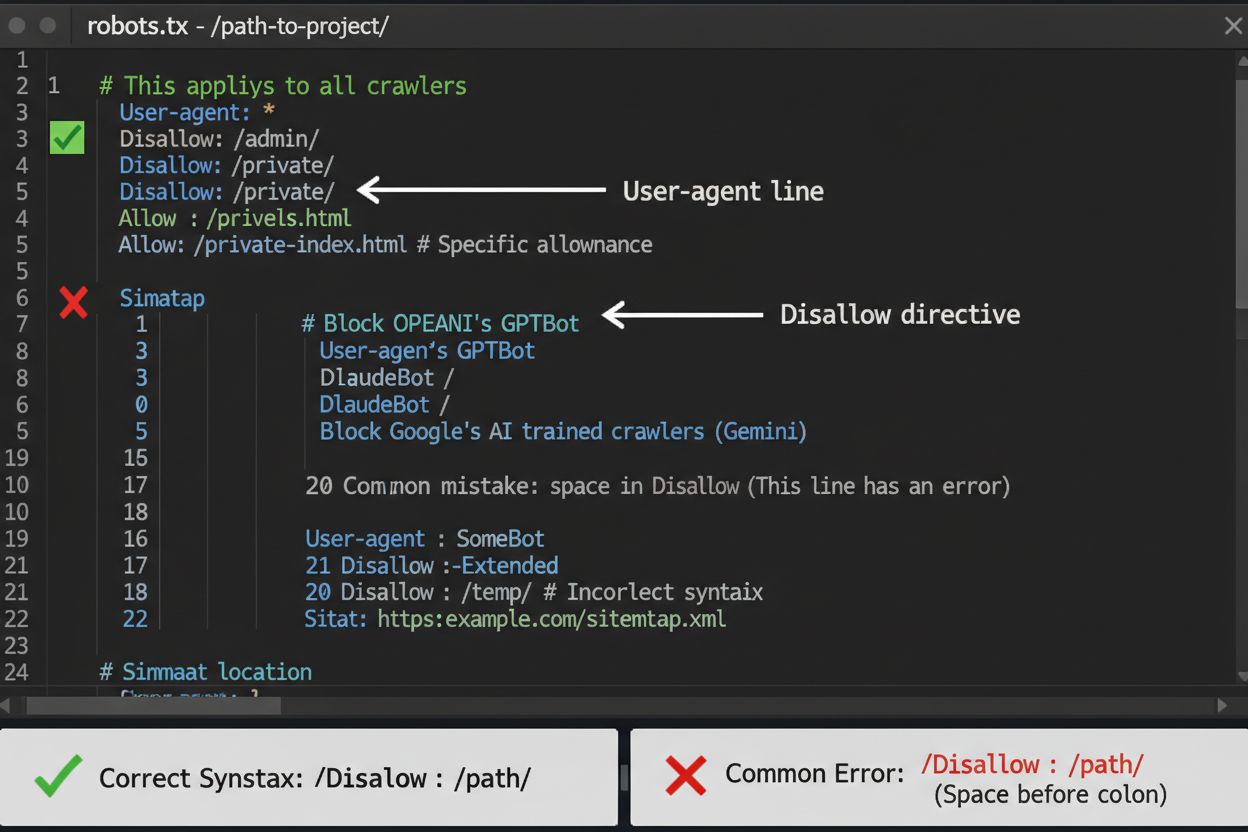
robots.txt-filen er ditt første forsvarslinje for å kontrollere AI-crawler-tilgang, men det er viktig å forstå at den er veiledende og ikke juridisk håndhevbar. Plassert i roten av domenet ditt (f.eks. dittnettsted.com/robots.txt), bruker denne filen enkel syntaks for å instruere crawlere om hvilke områder de skal unngå. For å blokkere alle AI-crawlere fullstendig, legg til følgende regler:
User-agent: GPTBot
Disallow: /
User-agent: Claude-Web
Disallow: /
User-agent: Googlebot-Extended
Disallow: /
User-agent: Meta-ExternalFetcher
Disallow: /
User-agent: Amazonbot
Disallow: /
User-agent: Bytespider
Disallow: /
User-agent: Applebot-Extended
Disallow: /
User-agent: CCBot
Disallow: /
Hvis du foretrekker selektiv blokkering—tillater søkecrawlere mens du blokkerer treningscrawlere—bruk denne tilnærmingen:
User-agent: GPTBot
Disallow: /
User-agent: Claude-Web
Disallow: /
User-agent: Bytespider
Disallow: /
User-agent: Googlebot-Extended
Disallow: /news/
Allow: /
En vanlig feil er å bruke for brede regler som Disallow: * som kan forvirre tolker, eller å glemme å spesifisere enkelte crawlere når du kun ønsker å blokkere noen. Store selskaper som OpenAI, Anthropic og Google respekterer vanligvis robots.txt-direktiver, selv om noen crawlere som Perplexity har blitt dokumentert å ignorere disse reglene helt.
Når robots.txt alene ikke er tilstrekkelig, finnes det flere sterkere beskyttelsesmetoder for å kontrollere AI-crawler-tilgang. IP-basert blokkering innebærer å identifisere IP-områder for AI-crawlere og blokkere dem på brannmur- eller servernivå—dette er svært effektivt, men krever vedlikehold ettersom IP-områder endres. Blokkering på servernivå via .htaccess-filer (Apache) eller Nginx-konfigurasjonsfiler gir mer granulær kontroll og er vanskeligere å omgå enn robots.txt. For Apache-servere, implementer denne blokkeringsregelen:
<IfModule mod_rewrite.c>
RewriteEngine On
RewriteCond %{HTTP_USER_AGENT} (GPTBot|Claude-Web|Bytespider|Amazonbot) [NC]
RewriteRule ^.*$ - [F,L]
</IfModule>
Meta-tag-blokkering med <meta name="robots" content="noindex, noimageindex, nofollowbydefault"> hindrer indeksering, men stopper ikke treningscrawlere. Verifisering av forespørselsheader sjekker om crawlere faktisk kommer fra deres påståtte kilder ved å verifisere reversert DNS og SSL-sertifikater. Bruk blokkering på servernivå når du trenger absolutt sikkerhet for at crawlere ikke får tilgang til innholdet ditt, og kombiner flere metoder for maksimal beskyttelse.
Å bestemme seg for om du skal blokkere AI-crawlere innebærer å veie flere hensyn mot hverandre. Blokkering av treningscrawlere (GPTBot, ClaudeBot, Bytespider) forhindrer at innholdet ditt brukes til trening av AI-modeller og beskytter din intellektuelle eiendom og konkurransefortrinn. Men tillatelse av søkecrawlere (Googlebot-Extended, Perplexity) kan gi henvisningstrafikk og øke synligheten i AI-drevne søkeresultater—en voksende kanal for oppdagelse. Avveiningen blir mer kompleks når man vurderer at noen AI-selskaper har dårlig forhold mellom crawling og henvisning: Anthropics crawlere genererer omtrent 38 000 crawl-forespørsler for hver eneste henvisning, mens forholdet for OpenAI er omtrent 400:1. Serverbelastning og båndbredde er et annet hensyn—AI-crawlere bruker betydelige ressurser, og blokkering kan redusere infrastrukturkostnader. Beslutningen bør tilpasses forretningsmodellen din: nyhetsorganisasjoner og utgivere kan ha nytte av henvisningstrafikk, mens SaaS-selskaper og eiere av proprietært innhold ofte foretrekker blokkering.
Å implementere crawler-blokkering er bare halve jobben—du må verifisere at crawlerne faktisk respekterer direktivene dine. Analyse av serverlogger er ditt viktigste verktøy; undersøk tilgangsloggene dine for brukeragent-strenger og IP-adresser til crawlere som prøver å få tilgang etter blokkering. Bruk grep for å søke i loggene dine:
grep -i "gptbot\|claude-web\|bytespider" /var/log/apache2/access.log | wc -l
Denne kommandoen teller hvor mange ganger disse crawlerne har besøkt nettstedet ditt. Testverktøy som curl kan simulere crawler-forespørsler for å verifisere at blokkeringsreglene dine fungerer korrekt:
curl -A "GPTBot/1.0" https://dittnettsted.com/robots.txt
Overvåk loggene dine ukentlig den første måneden etter implementering av blokkering, deretter kvartalsvis. Hvis du oppdager crawlere som ignorerer robots.txt, gå over til blokkering på servernivå eller kontakt crawler-operatørens abuse-team.
AI-crawler-landskapet endres raskt etter hvert som nye selskaper lanserer AI-produkter og eksisterende crawlere bytter brukeragent-strenger og IP-områder. Kvartalsvis gjennomgang av blokkeringslisten din sikrer at du ikke går glipp av nye crawlere eller ved et uhell blokkerer legitim trafikk. Crawler-økosystemet er fragmentert og desentralisert, noe som gjør det umulig å lage en virkelig permanent blokkeringsliste. Følg med på disse ressursene for oppdateringer:
Sett kalenderpåminnelser for å gjennomgå robots.txt og regler på servernivå hver 90. dag, og abonner på sikkerhetsmailinglister som sporer nye crawler-utrullinger.
Selv om blokkering av AI-crawlere forhindrer dem i å få tilgang til innholdet ditt, adresserer AmICited den komplementære utfordringen: å overvåke om AI-systemer siterer og refererer til merkevaren og innholdet ditt på tvers av utdataene deres. AmICited sporer omtaler av organisasjonen din i AI-genererte svar, og gir deg innsikt i hvordan innholdet ditt påvirker AI-modellers utdata og hvor merkevaren din vises i AI-søkeresultater. Dette gir en helhetlig AI-strategi: du kontrollerer hva crawlere kan få tilgang til gjennom robots.txt og blokkering på servernivå, mens AmICited sørger for at du forstår den nedstrøms effekten innholdet ditt har på AI-systemer. Sammen gir disse verktøyene deg full oversikt og kontroll over tilstedeværelsen din i AI-økosystemet—fra å forhindre uønsket bruk som treningsdata til å måle de faktiske sitatene og referansene innholdet ditt genererer på tvers av AI-plattformer.
Nei. Å blokkere AI-treningscrawlere som GPTBot, ClaudeBot og Bytespider påvirker ikke rangeringen din i Google eller Bing. Tradisjonelle søkemotorer bruker andre crawlere (Googlebot, Bingbot) som opererer uavhengig. Blokker kun disse hvis du ønsker å forsvinne helt fra søkeresultatene.
Store crawlere fra OpenAI (GPTBot), Anthropic (ClaudeBot), Google (Google-Extended) og Perplexity (PerplexityBot) oppgir offisielt at de respekterer robots.txt-direktiver. Mindre eller mindre transparente boter kan ignorere konfigurasjonen din, noe som er grunnen til at lagdelte beskyttelsesstrategier finnes.
Det avhenger av strategien din. Blokkering av kun treningscrawlere (GPTBot, ClaudeBot, Bytespider) beskytter innholdet ditt mot modelltrening, samtidig som søkefokuserte crawlere kan hjelpe deg å vises i AI-søkeresultater. Full blokkering fjerner deg helt fra AI-økosystemer.
Gå gjennom konfigurasjonen din minst kvartalsvis. AI-selskaper introduserer jevnlig nye crawlere. Anthropic slo sammen sine 'anthropic-ai' og 'Claude-Web'-boter til 'ClaudeBot', noe som ga den nye boten midlertidig ubegrenset tilgang til nettsteder som ikke hadde oppdatert reglene sine.
Blokkering hindrer crawlere i å få tilgang til innholdet ditt fullstendig, og beskytter det mot treningsdatainnsamling eller indeksering. Å tillate crawlere gir dem tilgang, men kan føre til at innholdet ditt brukes til modelltrening eller vises i AI-søkeresultater med minimal henvisningstrafikk.
Ja, robots.txt er veiledende og ikke juridisk bindende. Velskapte crawlere fra store selskaper respekterer vanligvis robots.txt-direktiver, men noen crawlere ignorerer dem. For sterkere beskyttelse, implementer blokkering på servernivå via .htaccess eller brannmurregler.
Sjekk serverloggene dine for brukeragent-strenger fra blokkerte crawlere. Hvis du ser forespørsler fra crawlere du har blokkert, respekterer de kanskje ikke robots.txt. Bruk testverktøy som Google Search Consoles robots.txt-tester eller curl-kommandoer for å verifisere konfigurasjonen din.
Blokkering av treningscrawlere har vanligvis minimal direkte trafikkpåvirkning siden de uansett gir lite henvisningstrafikk. Blokkering av søkecrawlere kan derimot redusere synligheten i AI-drevne oppdagelsesplattformer. Overvåk analysene dine i 30 dager etter at blokkeringer er implementert for å måle faktisk effekt.
Selv om du kontrollerer tilgang for crawlere med robots.txt, hjelper AmICited deg med å spore hvordan AI-systemer siterer og refererer innholdet ditt på tvers av deres utdata. Få full oversikt over din tilstedeværelse i AI.
Fullstendig referanseguide for AI-crawlere og roboter. Identifiser GPTBot, ClaudeBot, Google-Extended og 20+ andre AI-crawlere med brukeragenter, crawl-frekvens...

Lær hvordan du lar AI-boter som GPTBot, PerplexityBot og ClaudeBot crawle nettstedet ditt. Konfigurer robots.txt, sett opp llms.txt, og optimaliser for AI-synli...

Lær hvordan du tar strategiske beslutninger om blokkering av AI-crawlere. Vurder innholdstype, trafikkilder, inntektsmodeller og konkurranseposisjon med vårt om...
Informasjonskapselsamtykke
Vi bruker informasjonskapsler for å forbedre din surfeopplevelse og analysere vår trafikk. See our privacy policy.