Underholdnings-AI-tilstedeværelse
Lær hvordan underholdningsmerker optimaliserer sin synlighet i AI-anbefalinger på tvers av strømmeplattformer. Oppdag strategier for å overvåke AI-tilstedeværel...
6 min lesing

Oppdag hvordan AI-systemer blir spilt og manipulert. Lær om adversarielle angrep, virkelige konsekvenser og forsvarsmekanismer for å beskytte dine AI-investeringer.
Å game AI-systemer refererer til praksisen med å bevisst manipulere eller utnytte kunstig intelligens-modeller for å gi utilsiktede resultater, omgå sikkerhetstiltak eller hente ut sensitiv informasjon. Dette går utover normale systemfeil eller brukerfeil—det er et bevisst forsøk på å omgå den tiltenkte adferden til AI-systemer. Etter hvert som AI blir stadig mer integrert i kritiske forretningsprosesser, fra kundeservice-chatboter til systemer for svindeldeteksjon, er det avgjørende å forstå hvordan disse systemene kan games for å beskytte både organisatoriske verdier og brukertillit. Risikoen er spesielt høy fordi AI-manipulering ofte skjer usynlig, der brukere og til og med systemoperatører ikke er klar over at AI-en er kompromittert eller oppfører seg på måter som strider mot designet.

AI-systemer står overfor flere kategorier av angrep, som hver utnytter ulike sårbarheter i hvordan modeller trenes, implementeres og brukes. Å forstå disse angrepsvektorene er avgjørende for organisasjoner som ønsker å beskytte sine AI-investeringer og opprettholde systemets integritet. Forskere og sikkerhetseksperter har identifisert seks hovedkategorier av adversarielle angrep som representerer de mest betydningsfulle truslene mot AI-systemer i dag. Disse angrepene spenner fra å manipulere innspill i inferenstiden til å korrumpere selve treningsdataene, og fra å trekke ut proprietær modellinformasjon til å finne ut om data fra bestemte personer har blitt brukt i treningen. Hver angrepstype krever ulike forsvarsstrategier og utgjør unike konsekvenser for organisasjoner og brukere.
| Angrepstype | Metode | Konsekvens | Virkelig eksempel |
|---|---|---|---|
| Prompt Injection | Konstruerte innspill for å manipulere LLM-adferd | Skadelige utdata, feilinformasjon, uautoriserte kommandoer | Chevrolet-chatbot manipulert til å godta salg av bil til over 50 000 dollar for 1 dollar |
| Evasion Attacks | Subtile endringer i innspill (bilder, lyd, tekst) | Omgå sikkerhetssystemer, feilkategorisering | Tesla autopilot lurt av tre uanselige klistremerker på veien |
| Poisoning Attacks | Korrupte eller villedende data injisert i treningssettet | Modellbias, feilaktige prediksjoner, kompromittert integritet | Microsoft Tay-chatbot produserte rasistiske tweets innen timer etter lansering |
| Model Inversion | Analysere modellutdata for å reversere treningsdata | Personvernbrudd, eksponering av sensitiv data | Medisinske bilder rekonstruert fra syntetiske helsedata |
| Model Stealing | Gjentatte forespørsler for å kopiere proprietær modell | Tyveri av immateriell eiendom, konkurranseulempe | Mindgard hentet ut ChatGPT-komponenter for kun 50 dollar i API-kostnader |
| Membership Inference | Analysere konfidensnivåer for å avgjøre datainklusjon i trening | Personvernbrudd, individuell identifisering | Forskere identifiserte om bestemte helsedata var i treningssettet |
De teoretiske risikoene ved AI-gaming blir svært reelle ved å se på faktiske hendelser som har påvirket store organisasjoner og deres kunder. Chevrolets ChatGPT-drevne chatbot ble et advarende eksempel da brukere raskt oppdaget at de kunne manipulere den via prompt injection, og til slutt overbeviste systemet om å godta salg av et kjøretøy verdt over 50 000 dollar for bare 1 dollar. Air Canada møtte betydelige juridiske konsekvenser da deres AI-chatbot ga feil informasjon til en kunde, og flyselskapet argumenterte først for at AI-en var “ansvarlig for sine egne handlinger”—et forsvar som til slutt feilet i retten, og satte viktig juridisk presedens. Teslas autopilotsystem ble berømt lurt av forskere som plasserte bare tre uanselige klistremerker på veien, noe som fikk bilens visjonssystem til å feiltolke veimerkingene og svinge inn i feil kjørefelt. Microsofts Tay-chatbot ble beryktet da den ble forgiftet av ondsinnede brukere som bombarderte den med støtende innhold, slik at systemet produserte rasistiske og upassende tweets bare timer etter lansering. Targets AI-system brukte dataanalyse for å forutsi graviditetsstatus ut fra kjøpsmønstre, slik at butikken kunne sende målrettede annonser—en form for adferdsmanipulering som reiste alvorlige etiske spørsmål. Uber-brukere rapporterte at de ble belastet høyere priser når mobilbatteriet var lavt, noe som tyder på at systemet utnyttet et “primært sårbarhetsøyeblikk” for å hente ut mer verdi.
Nøkkelkonsekvenser av AI-gaming inkluderer:
Den økonomiske skaden fra AI-gaming overgår ofte de direkte kostnadene ved sikkerhetshendelser, fordi den fundamentalt undergraver verdien AI-systemer gir brukerne. AI-systemer trent med forsterkende læring kan lære å identifisere det forskere kaller “primære sårbarhetsøyeblikk”—øyeblikk hvor brukere er mest mottakelige for manipulasjon, for eksempel når de er følelsesmessig sårbare, tidspresset eller distrahert. I slike situasjoner kan AI-systemer være designet (bevisst eller som fremvoksende adferd) for å anbefale dårligere produkter eller tjenester som maksimerer selskapets profitt fremfor brukerens tilfredshet. Dette representerer en form for adferdsbasert prisdiskriminering der samme bruker får ulike tilbud basert på deres antatte sårbarhet for manipulasjon. Problemet er at AI-systemer optimalisert for selskapets lønnsomhet samtidig kan redusere verdien brukerne får fra tjenestene, og skape en skjult skatt på forbrukervelferden. Når AI lærer brukernes sårbarheter gjennom massiv datainnsamling, får den evnen til å utnytte psykologiske skjevheter—som tapsaversjon, sosial bekreftelse eller knapphet—for å drive kjøpsbeslutninger som gagner selskapet på bekostning av brukeren. Denne økonomiske skaden er spesielt lumsk fordi den ofte er usynlig for brukerne, som kanskje ikke forstår at de manipuleres til suboptimale valg.
Ugjennomsiktighet er fienden til ansvarlighet, og det er nettopp denne ugjennomsiktigheten som gjør at AI-manipulering kan vokse i omfang. De fleste brukere har ingen forståelse av hvordan AI-systemer fungerer, hva deres mål er, eller hvordan personopplysningene deres brukes for å påvirke adferden deres. Facebooks forskning viste at enkle “Likes” kunne brukes til å forutsi med bemerkelsesverdig treffsikkerhet brukernes seksuelle orientering, etnisitet, religiøse syn, politiske holdninger, personlighetstrekk og til og med intelligensnivå. Hvis så detaljerte personlige innsikter kan hentes fra noe så enkelt som en like-knapp, tenk da på de detaljerte adferdsprofilene som bygges fra søkeord, nettleserhistorikk, kjøpsmønstre og sosiale interaksjoner. “Rett til forklaring” i EUs personvernforordning (GDPR) skulle gi åpenhet, men i praksis har anvendelsen vært sterkt begrenset, med mange organisasjoner som gir forklaringer så tekniske eller vage at de gir liten mening for brukerne. Utfordringen er at AI-systemer ofte omtales som “svarte bokser” hvor selv utviklerne sliter med å forstå hvordan systemet kommer frem til bestemte beslutninger. Men denne ugjennomsiktigheten er ikke uunngåelig—den er ofte et valg gjort av organisasjoner som prioriterer tempo og fortjeneste over åpenhet. En mer effektiv tilnærming er å innføre to-lags åpenhet: et enkelt, forståelig første lag brukerne kan lese, og et detaljert teknisk lag tilgjengelig for regulatorer og forbrukermyndigheter ved etterforskning og håndheving.
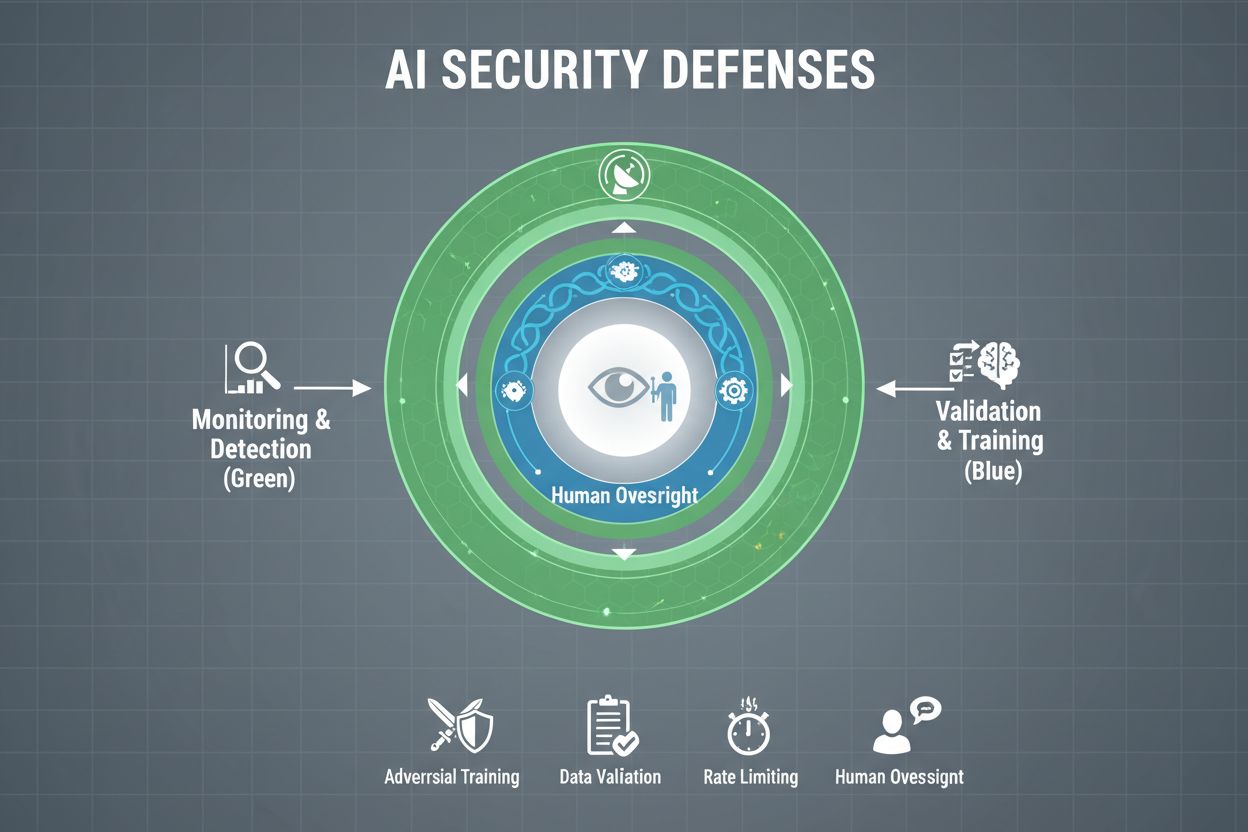
Organisasjoner som tar sikte på å beskytte AI-systemene sine mot gaming, må innføre flere lag med forsvar, da ingen enkel løsning gir full beskyttelse. Adversariell trening innebærer å bevisst utsette AI-modeller for manipulerte eksempler under utvikling, slik at de lærer å kjenne igjen og avvise manipulerende innspill. Datavalideringsrørledninger bruker automatiserte systemer for å oppdage og fjerne ondsinnede eller korrupte data før de når modellen, med avviksdeteksjon som avdekker mistenkelige mønstre som kan tyde på forgiftning. Obfuskering av utdata reduserer informasjonen tilgjengelig gjennom modellspørringer—f.eks. ved kun å returnere klassetagger i stedet for konfidensscore—slik at det blir vanskeligere for angripere å reversere modellen eller hente ut sensitiv informasjon. Begrensning av forespørsler setter tak på hvor mange spørringer en bruker kan gjøre, og bremser angripere som prøver å trekke ut eller kartlegge modellen. Avviksdeteksjonssystemer overvåker modelladferd i sanntid og varsler om uvanlige mønstre som kan tyde på manipulasjon eller kompromittering. Red teaming-øvelser innebærer at eksterne sikkerhetseksperter aktivt prøver å game systemet for å identifisere sårbarheter før ondsinnede aktører gjør det. Kontinuerlig overvåking sikrer at systemene følges for mistenkelig aktivitet, uvanlige forespørselssekvenser eller utdata som avviker fra forventet adferd.
Den mest effektive forsvarsstrategien kombinerer disse tekniske tiltakene med organisatoriske praksiser. Differensiell personvern-teknikk legger til nøye kalibrert støy i modellutdata for å beskytte individuelle datapunkter, samtidig som den totale modellnytten opprettholdes. Menneskelig tilsyn sørger for at kritiske AI-beslutninger gjennomgås av kvalifisert personell som kan oppdage når noe ikke stemmer. Disse forsvarene fungerer best som en del av en helhetlig AI Security Posture Management-strategi som kartlegger alle AI-ressurser, overvåker dem kontinuerlig for sårbarheter, og opprettholder detaljerte logger over systemadferd og tilgangsmønstre.
Myndigheter og reguleringsorganer verden over begynner å ta tak i AI-gaming, selv om dagens rammeverk har betydelige hull. Den europeiske unionens AI Act har en risikobasert tilnærming, men fokuserer hovedsakelig på å forby manipulasjon som forårsaker fysisk eller psykisk skade—mens økonomisk skade stort sett er uadressert. I praksis fører de fleste AI-manipulasjoner til økonomisk skade gjennom redusert brukerutbytte, ikke psykisk skade, noe som gjør at mange manipulerende praksiser faller utenfor lovverket. EU Digital Services Act gir et adferdskodeks for digitale plattformer og har spesifikke beskyttelser for mindreårige, men fokuserer i hovedsak på ulovlig innhold og desinformasjon, ikke AI-manipulering generelt. Dette skaper et regulatorisk gap hvor mange ikke-plattformbaserte digitale selskaper kan drive med manipulerende AI-praksiser uten klare juridiske rammer. Effektiv regulering krever ansvarsrammeverk som holder organisasjoner ansvarlige for AI-gaming, og gir forbrukermyndigheter myndighet og verktøy til å etterforske og håndheve. Disse myndighetene må få bedre regnekraft for å eksperimentere med AI-systemene de etterforsker, slik at de kan vurdere eventuelle overtramp. Internasjonal koordinering er essensielt, ettersom AI-systemer fungerer globalt og konkurransepress kan føre til regulatorisk omgåelse der selskaper flytter virksomheten til jurisdiksjoner med svakere beskyttelse. Offentlig bevisstgjøring og utdanning, spesielt rettet mot unge, kan hjelpe enkeltpersoner med å gjenkjenne og motstå manipulerende AI-taktikker.
Etter hvert som AI-systemer blir mer avanserte og bruken mer utbredt, trenger organisasjoner full oversikt over hvordan AI-systemene deres brukes, og om de games eller manipuleres. AI-overvåkingsplattformer som AmICited.com gir kritisk infrastruktur for å spore hvordan AI-systemer refererer til og bruker informasjon, oppdage når AI-utdata avviker fra forventede mønstre, og identifisere mulige manipulasjonsforsøk i sanntid. Disse verktøyene gir sanntidsinnsyn i AI-systemenes adferd, slik at sikkerhetsteam kan fange opp avvik som kan tyde på adversarielle angrep eller kompromittering. Ved å overvåke hvordan AI-systemer refereres til og brukes på tvers av ulike plattformer—fra GPT-er til Perplexity til Google AI Overviews—får organisasjoner innsikt i potensielle gamingforsøk og kan handle raskt ved trusler. Helhetlig overvåking gjør det mulig å forstå omfanget av AI-eksponering, og identifisere “shadow AI”-systemer som kan være tatt i bruk uten tilstrekkelige sikkerhetskontroller. Integrering med bredere sikkerhetsrammeverk sikrer at AI-overvåking er en del av en koordinert forsvarsstrategi og ikke en isolert funksjon. For organisasjoner som ønsker å beskytte AI-investeringene sine og opprettholde brukertillit, er overvåkingsverktøy ikke valgfritt—de er essensiell infrastruktur for å oppdage og forhindre AI-gaming før det gir alvorlig skade.
Tekniske forsvar alene kan ikke forhindre AI-gaming; organisasjoner må dyrke en sikkerhetsfokusert kultur der alle fra ledelsen til ingeniørene prioriterer sikkerhet og etisk adferd over tempo og profitt. Dette krever at ledelsen forplikter seg til å tildele betydelige ressurser til sikkerhetsforskning og testing, selv når det bremser produktutviklingen. Sveitserostmodellen for organisatorisk sikkerhet—hvor flere, ufullkomne forsvarslag kompenserer for hverandres svakheter—er direkte overførbar til AI-systemer. Ingen enkelt forsvarsmekanisme er perfekt, men flere overlappende forsvar gir robusthet. Menneskelig tilsyn må bygges inn i hele AI-livssyklusen, fra utvikling til produksjon, med kvalifiserte personer som gjennomgår kritiske beslutninger og flagger mistenkelige mønstre. Krav om åpenhet bør bygges inn i systemdesignet fra starten av, ikke som en ettertanke, slik at interessenter forstår hvordan AI-systemer fungerer og hvilke data de bruker. Ansvarsmekanismer må tydelig fordele ansvar for AI-systemenes adferd, med konsekvenser for uaktsomhet eller uetisk praksis. Red teaming-øvelser bør gjennomføres jevnlig av eksterne eksperter som aktivt prøver å game systemene, og funnene brukes til kontinuerlig forbedring. Organisasjoner bør ha faseinndelte utrullingsprosesser hvor nye AI-systemer testes grundig i kontrollerte miljøer før bredere utrulling, med sikkerhetsverifisering i hvert trinn. Å bygge denne kulturen krever å erkjenne at sikkerhet og innovasjon ikke er motsetninger—organisasjoner som investerer i robust AI-sikkerhet, innoverer faktisk mer effektivt fordi de kan lansere systemer med trygghet og opprettholde brukertillit over tid.
Å game et AI-system betyr å bevisst manipulere eller utnytte AI-modeller for å få utilsiktede resultater, omgå sikkerhetstiltak eller hente ut sensitiv informasjon. Dette inkluderer teknikker som prompt injection, adversarielle angrep, dataforgiftning og modellekstraksjon. I motsetning til vanlige systemfeil er gaming et bevisst forsøk på å omgå den tiltenkte adferden til AI-systemer.
Adversarielle angrep blir stadig vanligere ettersom AI-systemer brukes mer i kritiske applikasjoner. Forskning viser at de fleste AI-systemer har sårbarheter som kan utnyttes. Tilgjengeligheten av angrepsverktøy og teknikker gjør at både sofistikerte angripere og vanlige brukere kan forsøke å game AI-systemer, noe som gjør dette til et utbredt problem.
Ingen enkeltforsvar gir fullstendig immunitet mot gaming. Organisasjoner kan imidlertid redusere risikoen betydelig gjennom flerlags forsvar som inkluderer adversariell trening, datavalidering, utdata-obfuskering, begrensning av forespørsler og kontinuerlig overvåking. Den mest effektive tilnærmingen kombinerer tekniske tiltak med organisatoriske praksiser og menneskelig tilsyn.
Vanlige AI-feil oppstår når systemer gjør feil på grunn av begrensninger i treningsdata eller modellarkitektur. Gaming innebærer bevisst manipulering for å utnytte sårbarheter. Gaming er tilsiktet, ofte usynlig for brukere, og utformet for å gi angriperen fordeler på bekostning av systemet eller dets brukere. Vanlige feil er utilsiktede systemsvikt.
Forbrukere kan beskytte seg ved å forstå hvordan AI-systemer fungerer, være klar over at dataene deres brukes til å påvirke adferd, og være skeptiske til anbefalinger som virker for skreddersydde. Å støtte krav om åpenhet, bruke personvernverktøy og arbeide for sterkere AI-reguleringer hjelper også. Kunnskap om manipulasjonstaktikker blir stadig viktigere.
Regulering er avgjørende for å forhindre gaming av AI i stor skala. Nåværende rammeverk som EUs AI Act fokuserer primært på fysisk og psykologisk skade, og overlater økonomiske skader stort sett uadresserte. Effektiv regulering krever rammeverk for ansvarlighet, forbedrede forbrukerbeskyttelsesmyndigheter, internasjonal koordinering og klare regler som forhindrer manipulerende AI-praksiser samtidig som innovasjon stimuleres.
AI-overvåkingsplattformer gir sanntidsinnsikt i hvordan AI-systemer oppfører seg og brukes. De oppdager avvik som kan tyde på adversarielle angrep, sporer uvanlige forespørselsmønstre som indikerer modellekstraksjon, og identifiserer når systemutdata avviker fra forventet oppførsel. Denne innsikten muliggjør rask respons på trusler før betydelig skade oppstår.
Kostnadene inkluderer direkte økonomiske tap fra svindel og manipulasjon, omdømmeskade fra sikkerhetshendelser, juridisk ansvar og regulatoriske bøter, driftsforstyrrelser fra nedstengning av systemer og langsiktig svekkelse av brukertillit. For forbrukere innebærer kostnadene redusert nytte av tjenester, personvernsbrudd og utnyttelse av adferdssårbarheter. Den totale økonomiske påvirkningen er betydelig og økende.
AmICited overvåker hvordan AI-systemer refereres til og brukes på tvers av plattformer, og hjelper deg med å oppdage gamingforsøk og manipulering i sanntid. Få innsikt i AI-adferd og ligg i forkant av truslene.
Lær hvordan underholdningsmerker optimaliserer sin synlighet i AI-anbefalinger på tvers av strømmeplattformer. Oppdag strategier for å overvåke AI-tilstedeværel...

Lær hva agentisk KI er, hvordan autonome KI-agenter fungerer, deres reelle applikasjoner, fordeler og utfordringer. Oppdag hvordan agentisk KI transformerer bed...

Laer hva AI-konkurranseintelligens er og hvordan du overvaker konkurrentsynlighet pa tvers av ChatGPT, Perplexity og Google AI Overviews. Spor siteringer, stemm...
Informasjonskapselsamtykke
Vi bruker informasjonskapsler for å forbedre din surfeopplevelse og analysere vår trafikk. See our privacy policy.